Parameter-Efficient Conditioning for Material Generalization in Graph-Based Simulators
Pith reviewed 2026-05-17 23:35 UTC · model grok-4.3
The pith
Targeting early message-passing layers lets graph simulators adapt to new materials with minimal data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that material-property sensitivity is concentrated in the early message-passing layers of a pretrained graph network simulator. Applying a parameter-efficient Feature-wise Linear Modulation (FiLM) conditioning mechanism to these layers allows the model to generalize to unseen, interpolated, and moderately extrapolated material parameters. Training exclusively on as few as twelve short simulation trajectories from new materials yields accurate long-term rollouts and matches the performance of full-network fine-tuning, while also enabling successful recovery of unknown cohesion values from trajectory data.
What carries the argument
Feature-wise Linear Modulation (FiLM) conditioning applied specifically to the first few (1-5) message-passing layers, where sensitivity to material properties is concentrated.
If this is right
- Accurate long-term rollouts for friction angles up to 2.5 degrees and cohesion values up to 0.25 kPa beyond the training range.
- Comparable test performance from fine-tuning only the first few layers versus the entire network.
- Five-fold reduction in required training trajectories relative to a multi-task learning baseline.
- Successful identification of unknown cohesion parameters from observed trajectory data in inverse problems.
Where Pith is reading between the lines
- The same early-layer concentration of sensitivity could appear in simulators for fluids or deformable solids whenever their governing relations remain local.
- The efficiency gain may support online updating of simulators when material conditions change during physical experiments.
- Combining the conditioning scheme with optimization routines could speed up iterative material design workflows.
Load-bearing premise
Sensitivity to material properties is concentrated in the early message-passing layers because constitutive models act locally on particle interactions.
What would settle it
A direct comparison showing that fine-tuning only the first one to five layers produces markedly worse long-term rollout accuracy on new material parameters than fine-tuning the full network.
Figures













read the original abstract
Graph network-based simulators (GNS) have demonstrated strong potential for learning particle-based physics (such as fluids, deformable solids, and granular flows) while generalizing to unseen geometries due to their inherent inductive biases. However, existing models are typically trained for a single material type and fail to generalize across distinct constitutive behaviors, limiting their applicability in real-world engineering settings. Using granular flows as a running example, we propose a parameter-efficient conditioning mechanism that makes the GNS model adaptive to material parameters. We identify that sensitivity to material properties is concentrated in the early message-passing (MP) layers, a finding we link to the local nature of constitutive models (e.g., Mohr-Coulomb) and their effects on information propagation. We empirically validate this by showing that fine-tuning only the first few (1-5) of 10 MP layers of a pretrained model achieves comparable test performance as compared to fine-tuning the entire network. Building on this insight, we propose a parameter-efficient Feature-wise Linear Modulation (FiLM) conditioning mechanism designed to specifically target these early layers. This approach produces accurate long-term rollouts on unseen, interpolated, or moderately extrapolated values (e.g., up to 2.5 degrees for friction angle and 0.25 kPa for cohesion) when trained exclusively on as few as 12 short simulation trajectories from new materials, representing a 5-fold data reduction compared to a baseline multi-task learning method. Finally, we validate the model's utility by applying it to an inverse problem, successfully identifying unknown cohesion parameters from trajectory data. This approach enables the use of GNS in inverse design and closed-loop control tasks where material properties are treated as design variables.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a parameter-efficient FiLM conditioning mechanism for graph network simulators (GNS) to enable generalization across material parameters in granular flow simulations. It reports that material sensitivity concentrates in the early message-passing layers of a 10-layer network, validates this via fine-tuning experiments showing that adapting only the first 1-5 layers yields comparable test performance to full-network fine-tuning, and demonstrates that FiLM targeting of these layers produces accurate long-term rollouts on unseen, interpolated, or moderately extrapolated material values (e.g., up to 2.5° friction angle, 0.25 kPa cohesion) using as few as 12 short trajectories—a 5-fold data reduction relative to a multi-task baseline. The approach is additionally applied to an inverse problem for recovering unknown cohesion from trajectory data.
Significance. If the quantitative performance claims hold under detailed scrutiny, the work offers a practical route to adapting pretrained particle-based simulators to new constitutive behaviors with minimal data and compute, which would be valuable for engineering tasks involving material variability such as inverse design and closed-loop control. The hypothesized connection between early-layer sensitivity and the locality of constitutive models (e.g., Mohr-Coulomb) is a plausible architectural insight, though its generality remains to be established.
major comments (2)
- [§4] §4 (empirical validation of layer sensitivity): The central claim that material sensitivity is concentrated in the first 1-5 message-passing layers rests on the fine-tuning performance comparison, yet the manuscript provides no supporting layer-wise analyses such as gradient magnitude norms, activation sensitivity maps, or information-flow metrics across the full network. Without these, it is difficult to rule out that the observed concentration is specific to the chosen architecture, particle count, or pretraining distribution rather than a general consequence of constitutive-model locality.
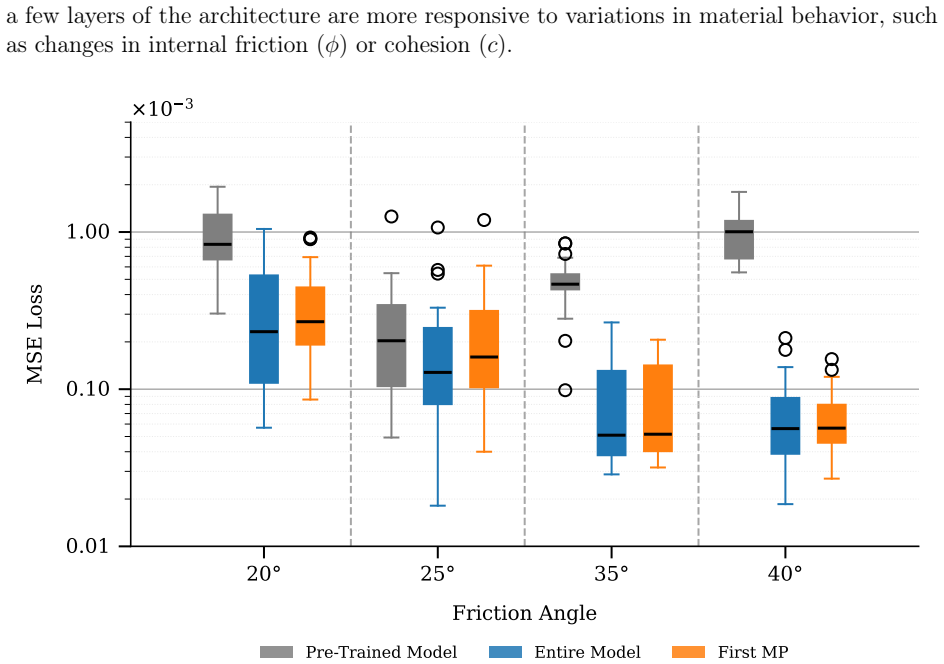
- [§5] §5 (results on data-efficient generalization): The abstract and results claim comparable test performance, accurate long-term rollouts, and a 5-fold data reduction with only 12 trajectories, but report no quantitative metrics (e.g., MSE or rollout error values), error bars, exact baseline numbers, statistical tests, or rollout horizon statistics. This absence makes it impossible to assess the strength of the generalization claims for interpolated and extrapolated material parameters.
minor comments (2)
- [Methods] The description of the FiLM conditioning implementation would benefit from an explicit equation or pseudocode block showing how the modulation parameters are generated and applied to the early layers.
- [Figures/Tables] Table or figure captions could more clearly state the exact number of trajectories, rollout length, and error metric used for each reported comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments in detail below and indicate the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (empirical validation of layer sensitivity): The central claim that material sensitivity is concentrated in the first 1-5 message-passing layers rests on the fine-tuning performance comparison, yet the manuscript provides no supporting layer-wise analyses such as gradient magnitude norms, activation sensitivity maps, or information-flow metrics across the full network. Without these, it is difficult to rule out that the observed concentration is specific to the chosen architecture, particle count, or pretraining distribution rather than a general consequence of constitutive-model locality.
Authors: We agree that additional supporting analyses would strengthen the interpretation of our fine-tuning results. The fine-tuning experiments demonstrate that adapting only the early layers achieves comparable performance, which is the key practical finding. To address the concern about potential specificity, in the revised manuscript we will add layer-wise gradient magnitude norms computed during fine-tuning on new materials. This will provide quantitative evidence that gradients are larger in early layers for material parameter changes. We note that while this supports the locality hypothesis for the GNS architecture and granular flow setting, establishing full generality across all possible models and domains would require broader experiments beyond the scope of this work. revision: yes
-
Referee: [§5] §5 (results on data-efficient generalization): The abstract and results claim comparable test performance, accurate long-term rollouts, and a 5-fold data reduction with only 12 trajectories, but report no quantitative metrics (e.g., MSE or rollout error values), error bars, exact baseline numbers, statistical tests, or rollout horizon statistics. This absence makes it impossible to assess the strength of the generalization claims for interpolated and extrapolated material parameters.
Authors: We acknowledge that the original manuscript could benefit from more explicit quantitative reporting. The claims are supported by the experimental results presented in the figures and tables, but we will revise the text to include specific numerical values for MSE on test sets, average rollout errors over specified horizons (e.g., 100 steps), standard deviations from repeated trials, and direct comparisons to the multi-task baseline. We will also report the exact number of trajectories used and include statistical tests where relevant to quantify the significance of the 5-fold reduction. These additions will make the generalization performance for interpolated and extrapolated parameters clearer. revision: yes
Circularity Check
No significant circularity; empirical sensitivity finding and FiLM design are independently validated against baselines
full rationale
The paper's core chain consists of an empirical observation (fine-tuning the first 1-5 of 10 MP layers yields comparable test performance to full-network fine-tuning) that is directly measured on held-out trajectories, followed by an interpretive link to constitutive model locality and the subsequent design of a targeted FiLM conditioner. This is then tested for data efficiency (12 trajectories) and inverse-problem utility against a multi-task baseline. No equations reduce a claimed prediction to a quantity defined by the same fitted parameters, no self-citation chain supplies a load-bearing uniqueness theorem, and no ansatz is smuggled via prior author work. The derivation remains self-contained against external benchmarks and does not collapse by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of early layers to condition
axioms (1)
- domain assumption Material sensitivity concentrates in early message-passing layers because constitutive models act locally
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify that sensitivity to material properties is concentrated in the early message-passing (MP) layers, a finding we link to the local nature of constitutive models (e.g., Mohr-Coulomb) and their effects on information propagation.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FiLM(h|γ, β) = γ ⊙ h + β ... conditioning on both the material properties and the evolving particle state
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Point Cloud Sequence Encoding for Material-conditioned Graph Network Simulators
PEACH uses a novel spatio-temporal point cloud sequence encoder plus auxiliary supervision to enable zero-shot adaptation of graph network simulators to unseen physical properties, outperforming mesh-based baselines i...
Reference graph
Works this paper leans on
-
[1]
A. Sanchez-Gonzalez, N. Heess, J. T. Springenberg, J. Merel, M. Riedmiller, R. Hadsell, P. Battaglia, Graph networks as learnable physics engines for inference and control, in: International conference on machine learning, PMLR, 2018, pp. 4470–4479
work page 2018
-
[2]
A. Sanchez-Gonzalez, J. Godwin, T. Pfaff, R. Ying, J. Leskovec, P. Battaglia, Learn- ing to simulate complex physics with graph networks, in: International conference on machine learning, PMLR, 2020, pp. 8459–8468
work page 2020
-
[3]
Y. Choi, K. Kumar, Graph neural network-based surrogate model for granular flows, Computers and Geotechnics 166 (2024) 106015
work page 2024
-
[4]
Q. Hernández, A. Badías, F. Chinesta, E. Cueto, Thermodynamics-informed graph neural networks, IEEE Transactions on Artificial Intelligence 5 (3) (2022) 967–976
work page 2022
-
[5]
P. W. Battaglia, J. B. Hamrick, V. Bapst, A. Sanchez-Gonzalez, V. Zambaldi, M. Ma- linowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner, et al., Relational inductive biases, deep learning, and graph networks, arXiv preprint arXiv:1806.01261 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
S. Jegelka, Theory of graph neural networks: Representation and learning, in: The International Congress of Mathematicians, 2022, pp. 1–23
work page 2022
- [7]
-
[8]
Y. Zhao, H. Li, H. Zhou, H. R. Attar, T. Pfaff, N. Li, A review of graph neural network applications in mechanics-related domains, Artificial Intelligence Review 57 (11) (2024) 315
work page 2024
-
[9]
L. Yuan, H. S. Park, E. Lejeune, Towards out of distribution generalization for problems in mechanics, Computer Methods in Applied Mechanics and Engineering 400 (2022) 115569
work page 2022
-
[10]
Y. Choi, J. Macedo, C. Liu, Differentiable graph neural network simulator for forward and inverse modeling of multi-layered slope system with multiple material properties, arXiv preprint arXiv:2504.15938 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [11]
- [12]
- [13]
-
[14]
D. Buterez, J. P. Janet, S. J. Kiddle, D. Oglic, P. Lió, Transfer learning with graph neural networks for improved molecular property prediction in the multi-fidelity setting, Nature communications 15 (1) (2024) 1517
work page 2024
-
[15]
J. Falk, L. Bonati, P. Novelli, M. Parrinello, M. Pontil, Transfer learning for atomistic simulations using gnns and kernel mean embeddings, Advances in Neural Information Processing Systems 36 (2023) 29783–29797
work page 2023
- [16]
- [17]
-
[18]
M. Forgione, A. Muni, D. Piga, M. Gallieri, On the adaptation of recurrent neural networks for system identification, Automatica 155 (2023) 111092
work page 2023
-
[19]
B. Wang, Y. Deng, P. Kry, U. Ascher, H. Huang, B. Chen, Learning elastic constitutive material and damping models, in: Computer Graphics Forum, Vol. 39, Wiley Online Library, 2020, pp. 81–91
work page 2020
-
[20]
P. Ma, P. Y. Chen, B. Deng, J. B. Tenenbaum, T. Du, C. Gan, W. Matusik, Learning neural constitutive laws from motion observations for generalizable pde dynamics, in: International Conference on Machine Learning, PMLR, 2023, pp. 23279–23300
work page 2023
-
[21]
R. Lourenço, P. Georgieva, E. Cueto, A. Andrade-Campos, An indirect training ap- proach for implicit constitutive modelling using recurrent neural networks and the vir- tual fields method, Computer Methods in Applied Mechanics and Engineering 425 (2024) 116961
work page 2024
-
[22]
B. Moya, A. Badías, D. González, F. Chinesta, E. Cueto, A thermodynamics-informed active learning approach to perception and reasoning about fluids, Computational Me- chanics 72 (3) (2023) 577–591
work page 2023
-
[23]
J. N. Heidenreich, D. Mohr, Recurrent neural network plasticity models: Unveiling their common core through multi-task learning, Computer Methods in Applied Mechanics and Engineering 426 (2024) 116991. doi:10.1016/j.cma.2024.116991. URLhttps://www.sciencedirect.com/science/article/pii/S0045782524002470
-
[24]
M. Kirchmeyer, Y. Yin, J. Donà, N. Baskiotis, A. Rakotomamonjy, P. Gallinari, Gener- alizing to new physical systems via context-informed dynamics model, in: International Conference on Machine Learning, PMLR, 2022, pp. 11283–11301
work page 2022
-
[25]
S. Li, X. Han, J. Bai, Adaptergnn: Parameter-efficient fine-tuning improves generaliza- tion in gnns, in: Proceedings of the AAAI conference on artificial intelligence, Vol. 38, 2024, pp. 13600–13608. 24
work page 2024
-
[26]
C. Wang, S. Hu, G. Tan, W. Jia, Elora: Low-rank adaptation for equivariant gnns, in: Forty-second International Conference on Machine Learning
-
[27]
S. Niu, J. Wu, Y. Zhang, Y. Chen, S. Zheng, P. Zhao, M. Tan, Efficient test-time model adaptation without forgetting, in: International conference on machine learning, PMLR, 2022, pp. 16888–16905
work page 2022
- [28]
-
[29]
V. Dumoulin, E. Perez, N. Schucher, F. Strub, H. d. Vries, A. Courville, Y. Bengio, Feature-wise transformations, Distill (2018). doi:10.23915/distill.00011. URLhttps://distill.pub/2018/feature-wise-transformations
-
[30]
S. Zhao, H. Chen, J. Zhao, A physical-information-flow-constrained temporal graph neural network-based simulator for granular materials, Computer Methods in Applied Mechanics and Engineering 433 (2025) 117536
work page 2025
-
[31]
Settles, Active learning literature survey, Tech
B. Settles, Active learning literature survey, Tech. rep., University of Wisconsin- Madison (2009)
work page 2009
-
[32]
K. Kumar, J. Salmond, S. Kularathna, C. Wilkes, E. Tjung, G. Biscontin, K. Soga, Scalable and modular material point method for large-scale simulations (09 2019). doi:10.48550/arXiv.1909.13380
-
[33]
K. Kumar, Y. Choi, Granular column collapse with graph neural network-based simu- lator (2023). doi:10.17603/ds2-gvvw-gt60. URLhttps://doi.org/10.17603/ds2-gvvw-gt60
- [34]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.