Adaptive Tuning of Parameterized Traffic Controllers via Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-17 00:09 UTC · model grok-4.3
The pith
Multi-agent reinforcement learning lets each local traffic controller adapt its own parameters, matching single-agent performance while gaining resilience to disturbances and failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
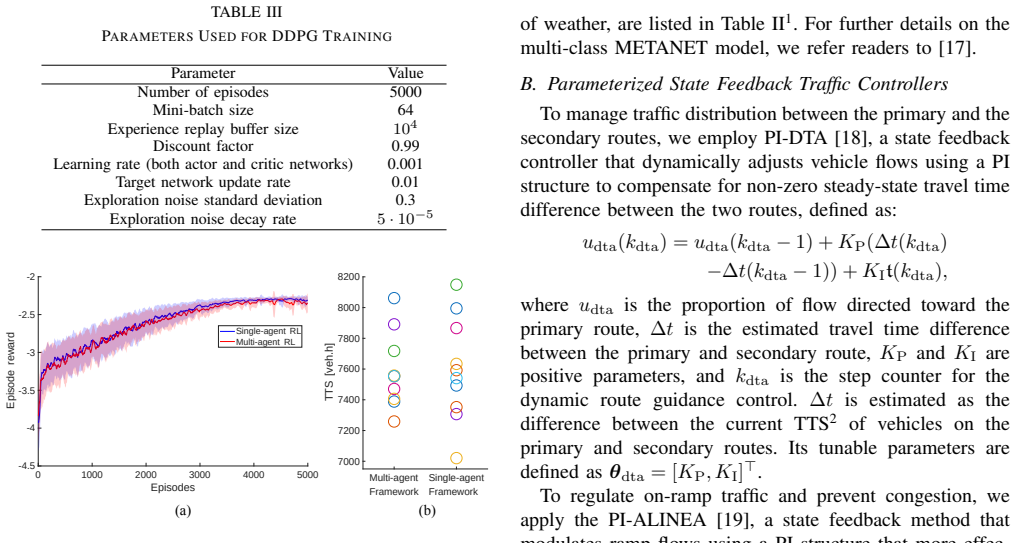
The authors show that a multi-agent reinforcement learning structure, with each agent adaptively tuning the parameters of a local state feedback traffic controller at reduced frequency, combines the reactivity of classical feedback with the adaptability of learning; on a simulated multi-class transportation network the approach outperforms no-control and fixed-parameter baselines, equals single-agent adaptive control, and exhibits markedly greater resilience when disturbances occur.
What carries the argument
Multi-agent reinforcement learning structure in which each agent tunes parameters of a local state feedback controller at lower frequency instead of computing high-frequency inputs.
If this is right
- The multi-agent setup outperforms both no-control and fixed-parameter state feedback controllers under varying traffic conditions.
- Performance matches that of single-agent RL adaptive control while providing greater resilience when disturbances affect parts of the network.
- Lower-frequency parameter tuning improves training efficiency without sacrificing adaptability to time-varying traffic.
- Local controllers continue operating independently during partial system failures, increasing overall robustness.
Where Pith is reading between the lines
- If the simulation-to-reality gap is small, the same tuning agents could be attached to existing ramp-metering or variable-speed-limit hardware already deployed on highways.
- The independent local operation suggests the framework could tolerate intermittent loss of central communication links, a common issue in large urban networks.
- Because parameter updates occur at lower frequency, the approach might combine with slower-timescale route-guidance systems without requiring synchronized high-speed data exchange.
Load-bearing premise
The simulated multi-class transportation network under varying conditions is close enough to real traffic that the measured performance and resilience gains will appear outside the simulator.
What would settle it
Deploy the same multi-agent and single-agent controllers on field data from an instrumented highway segment or in a hardware-in-the-loop traffic testbed and check whether the resilience advantage persists when real sensor noise, communication delays, and unmodeled driver behavior are present.
Figures


read the original abstract
Effective traffic control is essential for mitigating congestion in transportation networks. Conventional traffic management strategies, including route guidance and ramp metering, often rely on state feedback controllers, which are used for their simplicity and reactivity; however, they lack the adaptability required to cope with complex and time-varying traffic dynamics. This paper proposes a multi-agent reinforcement learning (RL) framework in which each agent adaptively tunes the parameters of a state feedback traffic controller, combining the reactivity of state feedback controllers with the adaptability of RL. By tuning parameters at a lower frequency rather than directly determining control inputs at a high frequency, the RL agents achieve improved training efficiency while maintaining adaptability to varying traffic conditions. The multi-agent structure further enhances system robustness, as local controllers can operate independently in the event of partial failures. The proposed framework is evaluated on a simulated multi-class transportation network under varying traffic conditions. Results show that the proposed multi-agent framework outperforms the no-control and fixed-parameter state feedback control cases, while performing on par with the single-agent RL-based adaptive state feedback control, but with much greater resilience to disturbances.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-agent RL framework in which individual agents adaptively tune the parameters of local state-feedback traffic controllers at a reduced frequency. This is intended to retain the reactivity of classical controllers while gaining adaptability from RL, with the multi-agent decomposition providing robustness to partial failures. The approach is evaluated on a simulated multi-class transportation network under varying demand and disturbance conditions; the reported results indicate outperformance relative to no-control and fixed-parameter baselines, parity with a single-agent RL variant, and substantially greater resilience to disturbances.
Significance. If the simulation results prove robust and the underlying traffic model is sufficiently faithful, the method offers a practical middle ground between purely reactive feedback control and high-frequency RL policies. The lower-frequency parameter tuning and decentralized structure could improve training stability and fault tolerance in real-time traffic management systems.
major comments (2)
- [§4] §4 (Simulation Setup and Results): The headline claims of outperformance and markedly greater disturbance resilience rest entirely on a single simulated multi-class network. No quantitative validation of the flow model against field data, no calibration procedure, and no sensitivity analysis to model parameters or disturbance statistics are reported. Without these, it is impossible to determine whether the observed performance deltas are properties of the multi-agent tuning scheme or artifacts of the simulator.
- [§4.3] §4.3 (Disturbance Experiments): The resilience comparison is presented without error bars, statistical significance tests, or details on the number of independent training runs. Given that RL policies are known to exhibit high variance, the claim that the multi-agent version is “much greater” in resilience requires explicit quantification and controls for training stochasticity.
minor comments (2)
- [Abstract] The abstract states performance results but supplies no numerical values, confidence intervals, or table references; readers must reach the results section to obtain any concrete metrics.
- [§3] Notation for the state-feedback controller parameters and the RL action space is introduced without a consolidated table; a single table listing all tunable parameters, their physical meaning, and update frequency would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate revisions made to the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Simulation Setup and Results): The headline claims of outperformance and markedly greater disturbance resilience rest entirely on a single simulated multi-class network. No quantitative validation of the flow model against field data, no calibration procedure, and no sensitivity analysis to model parameters or disturbance statistics are reported. Without these, it is impossible to determine whether the observed performance deltas are properties of the multi-agent tuning scheme or artifacts of the simulator.
Authors: We agree that the evaluation relies on simulation and that additional analyses would strengthen the claims. In the revised manuscript we have expanded §4 with a sensitivity analysis to model parameters and disturbance statistics, plus explicit details on the flow model assumptions and calibration procedure used in the simulator. Quantitative validation against field data is outside the scope of this simulation-focused study. revision: partial
-
Referee: [§4.3] §4.3 (Disturbance Experiments): The resilience comparison is presented without error bars, statistical significance tests, or details on the number of independent training runs. Given that RL policies are known to exhibit high variance, the claim that the multi-agent version is “much greater” in resilience requires explicit quantification and controls for training stochasticity.
Authors: We acknowledge the need for statistical rigor. The revised §4.3 now includes error bars on all resilience plots, reports results averaged over 10 independent training runs with different random seeds, and adds statistical significance tests (paired t-tests) to support the resilience comparisons. revision: yes
- Quantitative validation of the flow model against field data
Circularity Check
No circularity: claims rest on simulation comparisons, not self-referential derivations
full rationale
The paper introduces a multi-agent RL framework for tuning parameters of state-feedback traffic controllers at lower frequency. Central results (outperformance vs. no-control and fixed-parameter baselines, parity with single-agent RL, and improved disturbance resilience) are obtained exclusively via simulation experiments on a multi-class network. No equations, uniqueness theorems, or ansatzes are presented that reduce by construction to fitted inputs or prior self-citations. The derivation chain is absent; performance deltas are measured against external baselines rather than being forced by the method's own definitions or self-referential training loops. This is the expected non-finding for an empirical RL-control paper whose load-bearing step is simulator-based evaluation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-agent reinforcement learning framework in which each agent adaptively tunes the parameters of a state feedback traffic controller
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By tuning parameters at a lower frequency rather than directly determining control inputs at a high frequency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Review of road traffic control strategies,
M. Papageorgiou, C. Diakaki, V . Dinopoulou, A. Kotsialos, and Y . Wang, “Review of road traffic control strategies,”Proceedings of the IEEE, vol. 91, no. 12, pp. 2043–2067, 2003
work page 2043
-
[2]
Freeway ramp metering: An overview,
M. Papageorgiou and A. Kotsialos, “Freeway ramp metering: An overview,”IEEE Transactions on Intelligent Transportation Systems, vol. 3, no. 4, pp. 271–281, 2003
work page 2003
-
[3]
ALINEA: A local feedback control law for on-ramp metering,
M. Papageorgiou, H. Hadj-Salem, J.-M. Blossevilleet al., “ALINEA: A local feedback control law for on-ramp metering,”Transportation Research Record, vol. 1320, no. 1, pp. 58–67, 1991
work page 1991
-
[4]
Y . Wang, E. B. Kosmatopoulos, M. Papageorgiou, and I. Papamichail, “Local ramp metering in the presence of a distant downstream bottle- neck: Theoretical analysis and simulation study,”IEEE Transactions on Intelligent Transportation Systems, vol. 15, no. 5, pp. 2024–2039, 2014
work page 2024
-
[5]
Feed-forward ALINEA: A ramp metering control algorithm for nearby and distant bottlenecks,
J. R. D. Frejo and B. De Schutter, “Feed-forward ALINEA: A ramp metering control algorithm for nearby and distant bottlenecks,”IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 7, pp. 2448–2458, 2018
work page 2018
-
[6]
Efficient freeway MPC by parameterization of ALINEA and a speed-limited area,
G. S. van de Weg, A. Hegyi, S. P. Hoogendoorn, and B. De Schutter, “Efficient freeway MPC by parameterization of ALINEA and a speed-limited area,”IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 1, pp. 16–29, 2018
work page 2018
-
[7]
Grammatical-evolution-based parameterized model predictive control for urban traffic networks,
J. Jeschke, D. Sun, A. Jamshidnejad, and B. De Schutter, “Grammatical-evolution-based parameterized model predictive control for urban traffic networks,”Control Engineering Practice, vol. 132, p. 105431, 2023
work page 2023
-
[8]
D. Sun, A. Jamshidnejad, and B. De Schutter, “A novel framework combining MPC and deep reinforcement learning with application to freeway traffic control,”IEEE Transactions on Intelligent Transporta- tion Systems, vol. 25, no. 7, pp. 6756–6769, 2024
work page 2024
-
[9]
Reinforcement learning with model predictive control for highway ramp metering,
F. Airaldi, B. De Schutter, and A. Dabiri, “Reinforcement learning with model predictive control for highway ramp metering,”IEEE Transactions on Intelligent Transportation Systems, 2025
work page 2025
-
[10]
Reinforcement learn- ing for true adaptive traffic signal control,
B. Abdulhai, R. Pringle, and G. J. Karakoulas, “Reinforcement learn- ing for true adaptive traffic signal control,”Journal of Transportation Engineering, vol. 129, no. 3, pp. 278–285, 2003
work page 2003
-
[11]
Z. Li, P. Liu, C. Xu, H. Duan, and W. Wang, “Reinforcement learning- based variable speed limit control strategy to reduce traffic congestion at freeway recurrent bottlenecks,”IEEE Transactions on Intelligent Transportation Systems, vol. 18, no. 11, pp. 3204–3217, 2017
work page 2017
-
[12]
Multi-agent deep reinforce- ment learning for large-scale traffic signal control,
T. Chu, J. Wang, L. Codec `a, and Z. Li, “Multi-agent deep reinforce- ment learning for large-scale traffic signal control,”IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 3, pp. 1086–1095, 2019
work page 2019
-
[13]
Integrated traffic control for freeway recurrent bottleneck based on deep reinforcement learning,
C. Wang, Y . Xu, J. Zhang, and B. Ran, “Integrated traffic control for freeway recurrent bottleneck based on deep reinforcement learning,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 9, pp. 15 522–15 535, 2022
work page 2022
-
[14]
Adaptive freeway ramp metering and variable speed limit control: a genetic-fuzzy approach,
A. H. Ghods, A. R. Kian, and M. Tabibi, “Adaptive freeway ramp metering and variable speed limit control: a genetic-fuzzy approach,” IEEE Intelligent Transportation Systems Magazine, vol. 1, no. 1, pp. 27–36, 2011
work page 2011
-
[15]
Adaptive ramp metering control for urban freeway using large-scale data,
J. Chen, W. Lin, Z. Yang, J. Li, and P. Cheng, “Adaptive ramp metering control for urban freeway using large-scale data,”IEEE Transactions on Vehicular Technology, vol. 68, no. 10, pp. 9507–9518, 2019
work page 2019
-
[16]
Adaptive parameter- ized control for coordinated traffic management using reinforcement learning,
D. Sun, A. Jamshidnejad, and B. De Schutter, “Adaptive parameter- ized control for coordinated traffic management using reinforcement learning,”IFAC-PapersOnLine, vol. 56, no. 2, pp. 5463–5468, 2023
work page 2023
-
[17]
C. Pasquale, S. Sacone, S. Siri, and B. De Schutter, “A multi-class ramp metering and routing control scheme to reduce congestion and traffic emissions in freeway networks,”IFAC-PapersOnLine, vol. 49, no. 3, pp. 329–334, 2016
work page 2016
-
[18]
Freeway network simulation and dynamic traffic assignment with METANET tools,
Y . Wang, A. Messmer, and M. Papageorgiou, “Freeway network simulation and dynamic traffic assignment with METANET tools,” Transportation Research Record, vol. 1776, no. 1, pp. 178–188, 2001
work page 2001
-
[19]
Local ramp metering in the case of distant downstream bottlenecks,
Y . Wang and M. Papageorgiou, “Local ramp metering in the case of distant downstream bottlenecks,” in2006 IEEE Intelligent Transporta- tion Systems Conference. IEEE, 2006, pp. 426–431
work page 2006
-
[20]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforce- ment learning,”arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.