Recognition: no theorem link
LooseRoPE: Content-aware Attention Manipulation for Semantic Harmonization
Pith reviewed 2026-05-16 16:03 UTC · model grok-4.3
The pith
Relaxing rotational positional encodings in diffusion models allows continuous control over the trade-off between preserving pasted object identity and harmonizing it with the new scene.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LooseRoPE is a saliency-guided modulation of rotational positional encoding that loosens the positional constraints to continuously control the attention field of view. By relaxing RoPE, the method steers the model's focus between faithful preservation of the input image and coherent harmonization of the inserted object.
What carries the argument
LooseRoPE: saliency-guided modulation of RoPE that loosens positional constraints to control the attention field of view for balancing preservation and harmonization.
Load-bearing premise
Attention maps in diffusion-based editing models inherently determine whether image regions are preserved or modified for coherence.
What would settle it
If varying the degree of RoPE relaxation shows no measurable change in the visual balance between object identity and scene harmonization across multiple edited images, the method's effectiveness would be disproven.
Figures






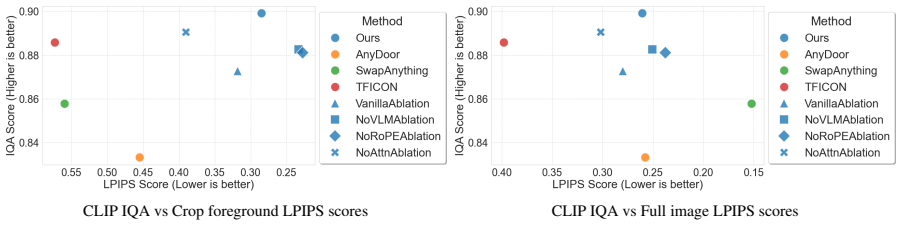








read the original abstract
Recent diffusion-based image editing methods commonly rely on text or high-level instructions to guide the generation process, offering intuitive but coarse control. In contrast, we focus on explicit, prompt-free editing, where the user directly specifies the modification by cropping and pasting an object or sub-object into a chosen location within an image. This operation affords precise spatial and visual control, yet it introduces a fundamental challenge: preserving the identity of the pasted object while harmonizing it with its new context. We observe that attention maps in diffusion-based editing models inherently govern whether image regions are preserved or adapted for coherence. Building on this insight, we introduce LooseRoPE, a saliency-guided modulation of rotational positional encoding (RoPE) that loosens the positional constraints to continuously control the attention field of view. By relaxing RoPE in this manner, our method smoothly steers the model's focus between faithful preservation of the input image and coherent harmonization of the inserted object, enabling a balanced trade-off between identity retention and contextual blending. Our approach provides a flexible and intuitive framework for image editing, achieving seamless compositional results without textual descriptions or complex user input.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LooseRoPE, a saliency-guided modulation of rotational positional encoding (RoPE) in diffusion-based models for prompt-free image editing. Users crop and paste an object into a target image; the method relaxes positional constraints in a content-aware manner to steer attention between preserving the pasted object's identity and harmonizing it with the surrounding context, achieving a controllable trade-off without textual prompts.
Significance. If validated, the approach would provide a lightweight, continuous control mechanism over attention fields in existing diffusion pipelines, enabling more precise compositional editing than coarse text-based methods. The targeted modulation of an established positional encoding (rather than a new architecture) is a practical strength, but the absence of any reported metrics leaves the practical utility unconfirmed.
major comments (2)
- [Abstract] Abstract: The central claim that saliency-guided RoPE relaxation 'smoothly steers the model's focus' and 'enables a balanced trade-off' is presented without any quantitative results, ablation studies, or validation details. The soundness of the method therefore rests entirely on an unshown empirical demonstration.
- [Abstract] Abstract: The key assumption that 'attention maps in diffusion-based editing models inherently govern whether image regions are preserved or adapted' is stated as an observation but is not supported by any cited prior work, derivation, or experiment within the provided text; this assumption is load-bearing for the entire modulation strategy.
minor comments (1)
- [Abstract] The abstract introduces the method but does not define the looseness parameter or the saliency computation; these should be formalized early with equations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to better support the claims made in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that saliency-guided RoPE relaxation 'smoothly steers the model's focus' and 'enables a balanced trade-off' is presented without any quantitative results, ablation studies, or validation details. The soundness of the method therefore rests entirely on an unshown empirical demonstration.
Authors: The full manuscript contains qualitative experiments (Section 4 and supplementary material) that demonstrate the continuous trade-off via visual results across different relaxation strengths. We agree the abstract overstates the empirical support and will revise it to reference the experiments explicitly while moderating the language to reflect the qualitative nature of the validation. Quantitative metrics are not reported because harmonization quality is inherently perceptual and context-dependent; we can add a user study or standard metrics (e.g., LPIPS, CLIP similarity) in revision if the referee recommends specific ones. revision: yes
-
Referee: [Abstract] Abstract: The key assumption that 'attention maps in diffusion-based editing models inherently govern whether image regions are preserved or adapted' is stated as an observation but is not supported by any cited prior work, derivation, or experiment within the provided text; this assumption is load-bearing for the entire modulation strategy.
Authors: This observation follows from prior analyses of cross-attention and self-attention behavior in diffusion-based editing (e.g., works on attention visualization for object insertion and inpainting). We will add relevant citations and a short explanatory paragraph with attention-map examples in the introduction or method section to ground the assumption. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is the introduction of LooseRoPE as a saliency-guided modulation of existing RoPE to control attention field of view, directly motivated by the stated observation that attention maps govern preservation versus adaptation in diffusion editing. This is presented as an explicit, continuous mechanism without any derivation that reduces by construction to fitted inputs, self-citations, or renamed empirical patterns. No load-bearing steps invoke uniqueness theorems from the same authors, smuggle ansatzes via citation, or rename known results; the logic remains a targeted engineering modulation rather than a closed self-referential loop. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- looseness parameter
axioms (1)
- domain assumption Attention maps in diffusion models govern region preservation or adaptation
Reference graph
Works this paper leans on
-
[1]
Multidiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation.arXiv preprint arXiv:2302.08113, 2023. 3
-
[2]
Flux, https://github.com/black-forest- labs/flux, 2024
Black Forest Labs. Flux, https://github.com/black-forest- labs/flux, 2024. 3
work page 2024
-
[3]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. In- structpix2pix: Learning to follow image editing instructions,
-
[4]
Training-free layout control with cross-attention guidance.arXiv preprint arXiv:2304.03373, 2023
Minghao Chen, Iro Laina, and Andrea Vedaldi. Training-free layout control with cross-attention guidance.arXiv preprint arXiv:2304.03373, 2023. 3
-
[5]
Anydoor: Zero-shot object-level im- age customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level im- age customization. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 6593–6602, 2024. 2, 3, 6, 7
work page 2024
-
[6]
Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. Ilvr: Conditioning method for denoising diffusion probabilistic models.arXiv preprint arXiv:2108.02938, 2021. 3
-
[7]
Dovenet: Deep image harmonization via domain verification
Wenyan Cong, Jianfu Zhang, Li Niu, Liu Liu, Zhixin Ling, Weiyuan Li, and Liqing Zhang. Dovenet: Deep image harmonization via domain verification. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8394–8403, 2020. 2
work page 2020
-
[8]
Xiaodong Cun and Chi-Man Pun. Improving the harmony of the composite image by spatial-separated attention mod- ule.IEEE Transactions on Image Processing, 29:4759– 4771, 2020. 2
work page 2020
-
[9]
Be yourself: Bounded attention for multi-subject text-to-image generation
Omer Dahary, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. Be yourself: Bounded attention for multi-subject text-to-image generation. InEuropean Conference on Com- puter Vision, pages 432–448. Springer, 2024. 3
work page 2024
-
[10]
Be decisive: Noise-induced layouts for multi-subject generation
Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aber- man, and Daniel Cohen-Or. Be decisive: Noise-induced layouts for multi-subject generation. InProceedings of the Special Interest Group on Computer Graphics and Interac- tive Techniques Conference Conference Papers, pages 1–12,
-
[11]
Bermano, Gal Chechik, and Daniel Cohen-Or
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image gen- eration using textual inversion, 2022. 3
work page 2022
-
[12]
Google DeepMind. Introducing Gemini 2.5 Flash Im- age, our state-of-the-art image generation and editing model.https://developers.googleblog.com/ en/introducing- gemini- 2- 5- flash- image/,
-
[13]
Accessed: 2025-11-13. 6, 7
work page 2025
-
[14]
Swapanything: Enabling arbitrary object swapping in personalized image editing.ECCV, 2024
Jing Gu, Nanxuan Zhao, Wei Xiong, Qing Liu, Zhifei Zhang, He Zhang, Jianming Zhang, HyunJoon Jung, Yilin Wang, and Xin Eric Wang. Swapanything: Enabling arbitrary object swapping in personalized image editing.ECCV, 2024. 3, 6, 7
work page 2024
-
[15]
Cross-domain compositing with pretrained dif- fusion models.arXiv preprint arXiv:2302.10167, 2023
Roy Hachnochi, Mingrui Zhao, Nadav Orzech, Rinon Gal, Ali Mahdavi-Amiri, Daniel Cohen-Or, and Amit Haim Bermano. Cross-domain compositing with pretrained dif- fusion models.arXiv preprint arXiv:2302.10167, 2023. 3, 6
-
[16]
Rotary position embedding for vision transformer
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. Rotary position embedding for vision transformer. In European Conference on Computer Vision, pages 289–305. Springer, 2024. 3
work page 2024
-
[17]
Prompt-to-prompt image editing with cross attention control, 2022
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control, 2022. 1
work page 2022
-
[18]
Denoising diffu- sion probabilistic models, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models, 2020. 1
work page 2020
-
[19]
Image generation from contextually- contradictory prompts.arXiv preprint arXiv:2506.01929,
Saar Huberman, Or Patashnik, Omer Dahary, Ron Mokady, and Daniel Cohen-Or. Image generation from contextually- contradictory prompts.arXiv preprint arXiv:2506.01929,
-
[20]
Ssh: A self-supervised framework for image harmonization
Yifan Jiang, He Zhang, Jianming Zhang, Yilin Wang, Zhe Lin, Kalyan Sunkavalli, Simon Chen, Sohrab Amirghodsi, Sarah Kong, and Zhangyang Wang. Ssh: A self-supervised framework for image harmonization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4832–4841, 2021. 2, 6
work page 2021
-
[21]
Multi-concept customization of text-to-image diffusion, 2023
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion, 2023. 3
work page 2023
-
[22]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas M¨uller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context i...
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models.arXiv preprint arXiv:2301.12597, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Gligen: Open-set grounded text-to-image generation
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22511–22521, 2023. 3
work page 2023
-
[25]
Tf-icon: Diffusion-based training-free cross-domain image composi- tion
Shilin Lu, Yanzhu Liu, and Adams Wai-Kin Kong. Tf-icon: Diffusion-based training-free cross-domain image composi- tion. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 2294–2305, 2023. 2, 3, 6, 7
work page 2023
-
[26]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.arXiv preprint arXiv:2302.08453, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[27]
One-step image translation with text-to-image models.arXiv preprint arXiv:2403.12036, 2024
Gaurav Parmar, Taesung Park, Srinivasa Narasimhan, and Jun-Yan Zhu. One-step image translation with text-to-image models.arXiv preprint arXiv:2403.12036, 2024. 3
-
[28]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- 9 national conference on computer vision, pages 4195–4205,
-
[29]
Patrick P ´erez, Michel Gangnet, and Andrew Blake. Poisson image editing. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 577–582. 2023. 2
work page 2023
-
[30]
Relightful harmonization: Lighting-aware portrait background replacement
Mengwei Ren, Wei Xiong, Jae Shin Yoon, Zhixin Shu, Jianming Zhang, HyunJoon Jung, Guido Gerig, and He Zhang. Relightful harmonization: Lighting-aware portrait background replacement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6452–6462, 2024. 2
work page 2024
-
[31]
High-resolution image syn- thesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models, 2022. 1
work page 2022
-
[32]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation, 2023
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation, 2023. 3, 1, 6
work page 2023
-
[33]
In- stancegen: Image generation with instance-level instruc- tions
Etai Sella, Yanir Kleiman, and Hadar Averbuch-Elor. In- stancegen: Image generation with instance-level instruc- tions. InProceedings of the Special Interest Group on Com- puter Graphics and Interactive Techniques Conference Con- ference Papers, pages 1–10, 2025. 3
work page 2025
-
[34]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 7
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[35]
Score-based generative modeling through stochastic differential equa- tions
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions. InInternational Conference on Learning Represen- tations, 2020. 1
work page 2020
-
[36]
Object- stitch: Object compositing with diffusion model
Yizhi Song, Zhifei Zhang, Zhe Lin, Scott Cohen, Brian Price, Jianming Zhang, Soo Ye Kim, and Daniel Aliaga. Object- stitch: Object compositing with diffusion model. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18310–18319, 2023. 2, 1
work page 2023
-
[37]
Imprint: Generative object compositing by learning identity-preserving representation
Yizhi Song, Zhifei Zhang, Zhe Lin, Scott Cohen, Brian Price, Jianming Zhang, Soo Ye Kim, He Zhang, Wei Xiong, and Daniel Aliaga. Imprint: Generative object compositing by learning identity-preserving representation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 8048–8058, 2024. 2
work page 2024
-
[38]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[39]
Ominicontrol: Minimal and univer- sal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and univer- sal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14940–14950, 2025. 2, 3
work page 2025
-
[40]
Yi-Hsuan Tsai, Xiaohui Shen, Zhe Lin, Kalyan Sunkavalli, Xin Lu, and Ming-Hsuan Yang. Deep image harmonization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3789–3797, 2017. 2
work page 2017
-
[41]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. InPro- ceedings of the AAAI conference on artificial intelligence, pages 2555–2563, 2023. 6
work page 2023
-
[42]
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. Ms-diffusion: Multi-subject zero-shot im- age personalization with layout guidance.arXiv preprint arXiv:2406.07209, 2024. 2
-
[43]
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation.arXiv preprint arXiv:2302.13848, 2023. 3
-
[44]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2.https://github. com/facebookresearch/detectron2, 2019. 4
work page 2019
-
[46]
Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models, 2023
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models, 2023. 3
work page 2023
-
[47]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023. 3
work page 2023
-
[48]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 6 10 LooseRoPE: Content-aware Attention Manipulation for Semantic Harmonization Supplementary Materia...
work page 2018
-
[49]
Method 3 3.1. Preliminaries . . . . . . . . . . . . . . . . . 3 3.2. LooseRoPE . . . . . . . . . . . . . . . . . . 3
- [50]
-
[51]
Additional Qualitative Results
Additional Results and Discussions 1 6.1. Additional Qualitative Results . . . . . . . . 1 6.2. Additional Quantitative Evaluation . . . . . 1 6.3. Attention Locality and Harmonization Out- comes . . . . . . . . . . . . . . . . . . . . 4 6.4. Limitations . . . . . . . . . . . . . . . . . . 4
-
[52]
Implementation Details 5 7.1. LooseRoPE . . . . . . . . . . . . . . . . . . 5 7.2. Experiments . . . . . . . . . . . . . . . . . 6 7.2.1 . Baselines . . . . . . . . . . . . . . . 6 7.2.2 . Metrics . . . . . . . . . . . . . . . . 7 7.3. Benchmark . . . . . . . . . . . . . . . . . . 8
-
[53]
Additional Results and Discussions 6.1. Additional Qualitative Results In Figure 9 we present additional LooseRoPE outputs, com- pared against the outputs of our base model FLUX Kontext when given the same base prompt:“blend the cropped ob- jects into the image in a convincing manner without chang- ing the style of the image”, and the input images present...
-
[54]
Implementation Details 7.1. LooseRoPE Base Model.We base our method on the black-forest-labs/FLUX.1-Kontext-dev image editing diffusion model, specifically using the distribution available on HuggingFace at this URL. For all experiments and results presented in this paper we use a crudely edited image and the base prompt:“blend the cropped objects into th...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.