Recognition: 2 theorem links
· Lean TheoremFrom Observations to States: Latent Time Series Forecasting
Pith reviewed 2026-05-16 09:01 UTC · model grok-4.3
The pith
Shifting time series forecasting from observations to learned latent states improves accuracy and representation quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The dominant observation-space forecasting paradigm encourages models to learn disordered latent representations even when point predictions are accurate. LatentTSF instead projects observations through an autoencoder into a latent state space and conducts forecasting entirely within that space, allowing the model to concentrate on structured temporal dynamics rather than fitting noise in the observations.
What carries the argument
An autoencoder that encodes each observation into a latent state, followed by forecasting performed wholly inside the latent space before decoding back to observations.
If this is right
- Forecasting accuracy rises on widely used time series benchmarks.
- Learned representations exhibit greater temporal continuity and structure.
- Models become less prone to shortcut solutions driven by observation noise.
- The approach scales to partially observed data by focusing on latent dynamics.
Where Pith is reading between the lines
- The latent-space shift could extend naturally to long-horizon forecasting where capturing true dynamics matters more than short-term fitting.
- Similar autoencoder-plus-latent-prediction patterns may apply to related sequence tasks such as anomaly detection or reinforcement learning state estimation.
- The mutual-information framing opens the possibility of combining LatentTSF with other information-maximization regularizers.
Load-bearing premise
The autoencoder learns a latent space whose dynamics are simpler and more predictable than the original observation process, and forecasting there transfers back to accurate observations without additional distortion.
What would settle it
Training LatentTSF on a benchmark and finding that both forecasting error and a direct measure of latent temporal disorder remain unchanged or worse than a standard observation-space baseline would falsify the central claim.
Figures




read the original abstract
Deep learning has achieved strong performance in Time Series Forecasting (TSF). However, we identify a critical representation paradox, termed Latent Chaos: models with accurate predictions often learn latent representations that are temporally disordered and lack continuity. We attribute this to the dominant observation-space forecasting paradigm, where minimizing point-wise errors on noisy and partially observed data encourages shortcut solutions instead of the recovery of underlying system dynamics. To address this, we propose Latent Time Series Forecasting (LatentTSF), a paradigm that shifts TSF from observation regression to latent state prediction. LatentTSF employs an AutoEncoder to project each observation into a learned latent state space and performs forecasting entirely in this space, allowing the model to focus on learning structured temporal dynamics. We provide an information-theoretic analysis showing that the latent objectives can be motivated as surrogates for maximizing mutual information between predicted and ground-truth latent states and future observations. Extensive experiments on widely-used benchmarks confirm that LatentTSF effectively mitigates latent chaos, yielding consistent improvements in both forecasting accuracy and representation quality. Our code is available at https://github.com/Muyiiiii/LatentTSF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'latent chaos' phenomenon in deep time-series forecasting models, where accurate observation-space predictions coexist with temporally disordered latent representations. It proposes LatentTSF, which inserts an autoencoder to map observations to a learned latent state space and performs all forecasting inside that space. An information-theoretic argument is offered to motivate the latent objectives as surrogates for maximizing mutual information between predicted latents and future observations. Experiments on standard benchmarks report consistent gains in both forecasting accuracy and representation quality, with code released.
Significance. If the central claim is substantiated, the work offers a principled shift from direct observation regression to latent-state prediction, potentially improving robustness on noisy or partially observed series. The explicit information-theoretic motivation and public code are positive features that would strengthen the contribution if the equivalence between the surrogate objectives and the claimed mutual-information gain is made rigorous.
major comments (2)
- [§4] §4 (information-theoretic analysis): the claim that the latent objectives serve as surrogates for maximizing mutual information between predicted latents and future observations holds only under the assumption that the autoencoder mapping is approximately invertible and preserves dynamical information. The manuscript provides no quantitative bounds on reconstruction distortion or information loss, nor an ablation that isolates reconstruction fidelity from forecasting improvement. This assumption is load-bearing for the central claim that latent forecasting recovers underlying dynamics rather than merely adding implicit regularization.
- [§5] §5 (experiments): the reported gains in representation quality are not accompanied by a controlled comparison that holds the encoder fixed while varying only the forecasting objective. Without this isolation, it remains unclear whether the observed mitigation of latent chaos is attributable to the latent-space forecasting paradigm or to other design choices.
minor comments (2)
- Notation for the latent-state transition model and the reconstruction loss should be introduced with explicit variable definitions before the information-theoretic derivation.
- Figure captions for the latent-trajectory visualizations should state the exact metric used to quantify 'temporal disorder' so that readers can reproduce the comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important points for strengthening the rigor of our information-theoretic analysis and experimental controls. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [§4] §4 (information-theoretic analysis): the claim that the latent objectives serve as surrogates for maximizing mutual information between predicted latents and future observations holds only under the assumption that the autoencoder mapping is approximately invertible and preserves dynamical information. The manuscript provides no quantitative bounds on reconstruction distortion or information loss, nor an ablation that isolates reconstruction fidelity from forecasting improvement. This assumption is load-bearing for the central claim that latent forecasting recovers underlying dynamics rather than merely adding implicit regularization.
Authors: We agree that the information-theoretic motivation relies on approximate invertibility of the autoencoder and that the manuscript lacks explicit quantitative bounds. In the revision we will add (i) empirical bounds on reconstruction distortion (MSE and estimated mutual information between observations and reconstructions) across all benchmarks and (ii) an ablation that sweeps the reconstruction-loss weight while holding the forecasting objective fixed. These additions will quantify information preservation and isolate its contribution from the latent-forecasting gains. revision: yes
-
Referee: [§5] §5 (experiments): the reported gains in representation quality are not accompanied by a controlled comparison that holds the encoder fixed while varying only the forecasting objective. Without this isolation, it remains unclear whether the observed mitigation of latent chaos is attributable to the latent-space forecasting paradigm or to other design choices.
Authors: We acknowledge that the current experiments do not fully isolate the forecasting objective. We will add a controlled study in which the encoder is pre-trained once on reconstruction and then frozen; we then compare (a) latent-space forecasting (LatentTSF) against (b) observation-space forecasting using the identical frozen encoder. This directly tests whether the mitigation of latent chaos arises from the latent-prediction paradigm itself. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper motivates its latent forecasting paradigm via an information-theoretic argument that presents the objectives as surrogates for mutual information maximization between predicted latents and future observations. This analysis functions as conceptual motivation rather than a closed-form derivation that reduces to the fitted parameters by construction. The core modeling shift (autoencoder projection followed by latent-space prediction) is introduced as a new paradigm and supported by empirical results on standard benchmarks, without load-bearing steps that equate predictions to inputs via self-definition, fitted-input renaming, or self-citation chains. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LatentTSF employs an AutoEncoder to project each observation into a learned latent state space and performs forecasting entirely in this space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alemi, A. A., Fischer, I., Dillon, J. V ., and Murphy, K. Deep variational information bottleneck.arXiv preprint arXiv:1612.00410,
-
[2]
Eldele, E., Ragab, M., Chen, Z., Wu, M., and Li, X. Tslanet: Rethinking transformers for time series representation learning.arXiv preprint arXiv:2404.08472,
-
[3]
Ghugare, R., Bharadhwaj, H., Eysenbach, B., Levine, S., and Salakhutdinov, R. Simplifying model-based rl: learn- ing representations, latent-space models, and policies with one objective.arXiv preprint arXiv:2209.08466,
-
[4]
FinTSB: A Comprehensive and Practical Benchmark for Financial Time Series Forecasting
Hu, Y ., Li, Y ., Liu, P., Zhu, Y ., Li, N., Dai, T., Xia, S.-t., Cheng, D., and Jiang, C. Fintsb: A comprehensive and practical benchmark for financial time series forecasting. arXiv preprint arXiv:2502.18834, 2025a. Hu, Y ., Yang, J., Zhou, T., Liu, P., Tang, Y ., Jin, R., and Sun, L. Bridging past and future: Distribution-aware alignment for time serie...
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[5]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Patch-wise structural loss for time series forecasting.arXiv preprint arXiv:2503.00877,
Kudrat, D., Xie, Z., Sun, Y ., Jia, T., and Hu, Q. Patch-wise structural loss for time series forecasting.arXiv preprint arXiv:2503.00877,
-
[7]
Li, Y ., Yang, X., Yang, X., Xu, M., Wang, X., Liu, W., and Bian, J. R&d-agent-quant: A multi-agent framework for data-centric factors and model joint optimization.arXiv preprint arXiv:2505.15155,
-
[8]
Liu, P., Wu, B., Hu, Y ., Li, N., Dai, T., Bao, J., and Xia, S.-t. Timebridge: Non-stationarity matters for long-term time series forecasting.arXiv preprint arXiv:2410.04442,
-
[9]
iTransformer: Inverted Transformers Are Effective for Time Series Forecasting
Liu, Y ., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., and Long, M. itransformer: Inverted transformers are effective for time series forecasting.arXiv preprint arXiv:2310.06625,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nie, Y . A time series is worth 64words: Long-term forecast- ing with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Si, H., Pei, C., Li, J., Pei, D., and Xie, G. Cmos: Rethinking time series prediction through the lens of chunk-wise spatial correlations.arXiv preprint arXiv:2505.19090,
- [13]
-
[14]
Fredf: Learning to forecast in the frequency domain.arXiv preprint arXiv:2402.02399, 2024a
Wang, H., Pan, L., Chen, Z., Yang, D., Zhang, S., Yang, Y ., Liu, X., Li, H., and Tao, D. Fredf: Learning to forecast in the frequency domain.arXiv preprint arXiv:2402.02399, 2024a. Wang, H., Pan, L., Chen, Z., Chen, X., Dai, Q., Wang, L., Li, H., and Lin, Z. Time-o1: Time-series forecasting needs transformed label alignment. InThe Thirty-ninth Annual Con...
-
[15]
Wu, H., Hu, T., Liu, Y ., Zhou, H., Wang, J., and Long, M. Timesnet: Temporal 2d-variation modeling for general time series analysis.arXiv preprint arXiv:2210.02186,
-
[16]
10 From Observations to States: Latent Time Series Forecasting Yang, J., Hu, Y ., Zhang, K., Niu, L., Yu, P. S., and Ding, K. Revisiting multivariate time series forecasting with missing values.arXiv preprint arXiv:2509.23494, 2025a. Yang, J., Zhang, K., Zhang, G., Yu, P. S., and Ding, K. Glocal information bottleneck for time series imputation. arXiv pre...
-
[17]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., and Xie, S. Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
log qθ(ZY |bZY ) qθ(ZY |bZY ) # , =H(Z Y ) +E[logq θ(ZY |bZY )] +E
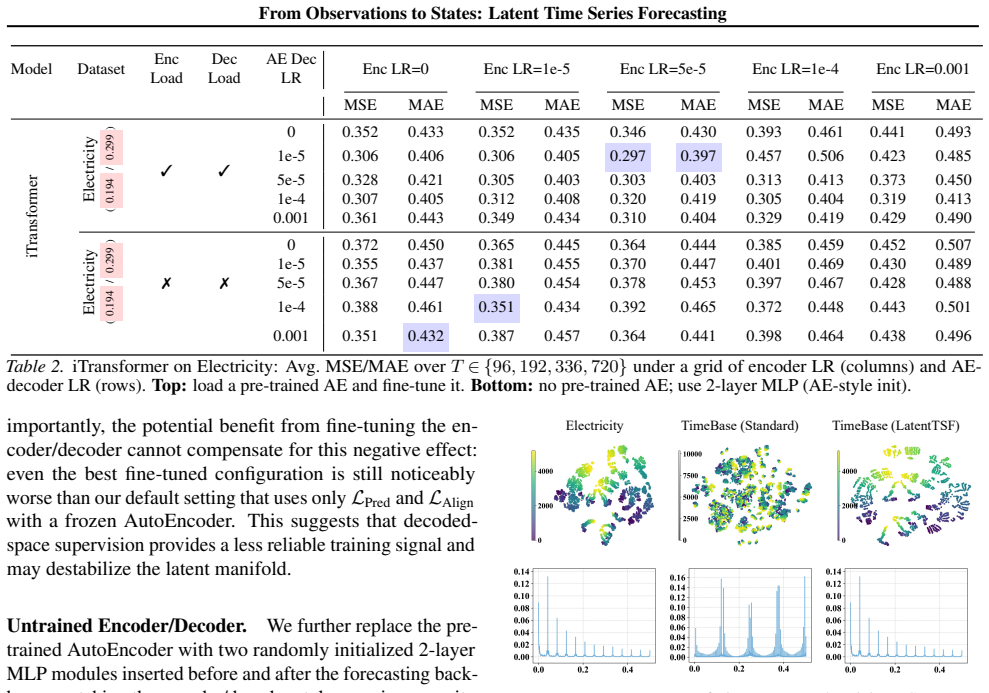
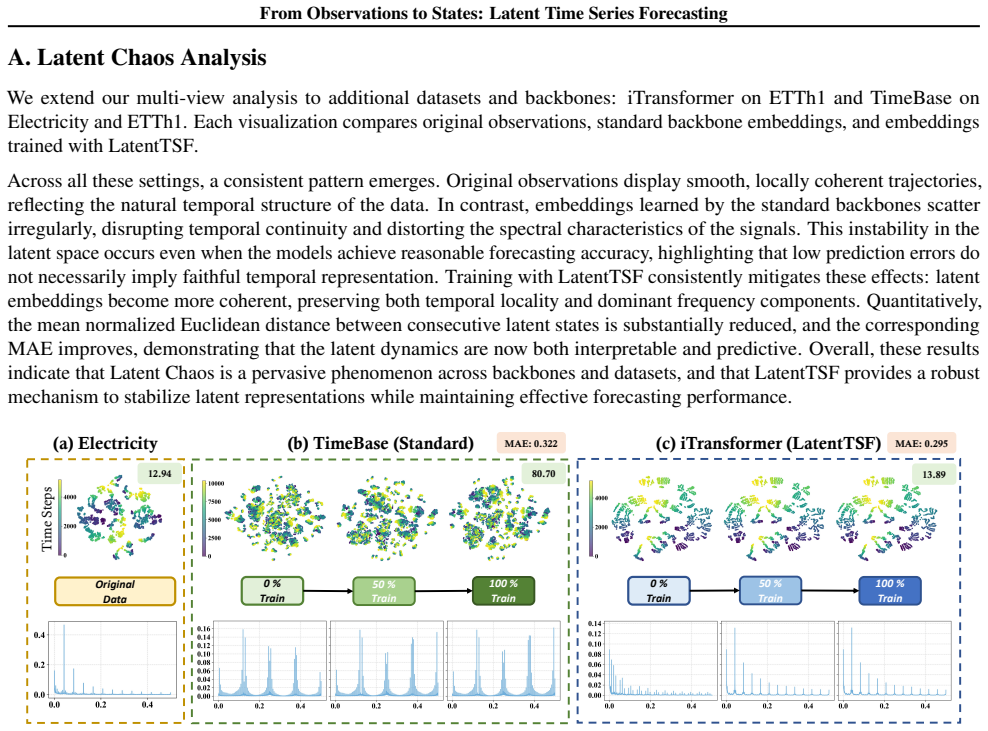
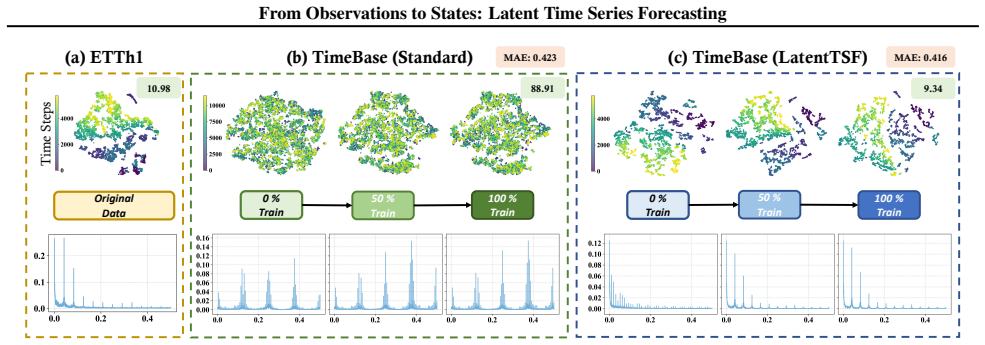
11 From Observations to States: Latent Time Series Forecasting A. Latent Chaos Analysis We extend our multi-view analysis to additional datasets and backbones: iTransformer on ETTh1 and TimeBase on Electricity and ETTh1. Each visualization compares original observations, standard backbone embeddings, and embeddings trained with LatentTSF. Across all these...
work page 2019
-
[19]
log p(Y,bZY ) p(Y)p(bZY ) # , =E
and the fixed scaling factor 1 2σ2 , maximizing E[logp(Z Y |bZY )] is equivalent to minimizing the squared error objective: LPred ∝E h ∥ZY −bZY ∥2 F i .(24) In other words, LPred can be viewed as maximizing a conditional log-likelihood term, which encouragesbZY to be maximally informative aboutZ Y . B.2.L Align as an Objective for MaximizingI(Y; bZY ). We...
work page 2018
-
[20]
and BYOL (Grill et al., 2020), we hypothesize that the alignment of positive pairs is the primary driver for feature consistency in our specific forecasting setup (Hu et al., 2025b). Thus, we adopt a simplified objective that maximizes the cosine similarity between predicted and ground-truth representations: LAlign def =−E h sθ(Y,bZY ) i .(30) Minimizing ...
work page 2020
-
[21]
encompasses temperature and power load data from electricity transformers in two regions of China, spanning from 2016 to
work page 2016
-
[22]
features hourly electricity consumption records in kilowatt-hours (kWh) for 321 clients. Sourced from the UCL Machine Learning Repository, this dataset covers the period from 2012 to 2014, providing valuable insights into consumer electricity usage patterns. (3) Trafficdataset (Wu et al.,
work page 2012
-
[23]
includes data on hourly road occupancy rates, gathered by 862 detectors across the freeways of the San Francisco Bay area. This dataset, covering the years 2015 to 2016, offers a detailed snapshot of traffic flow and congestion. C.2. Baselines To evaluate the performance of our proposed method, we compare it against a diverse set of state-of-the-art basel...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.