Recognition: no theorem link
Early Classification of Time Series in Non-Stationary Cost Regimes
Pith reviewed 2026-05-16 08:27 UTC · model grok-4.3
The pith
Adapting early time series classifiers with online learning handles changing decision costs effectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
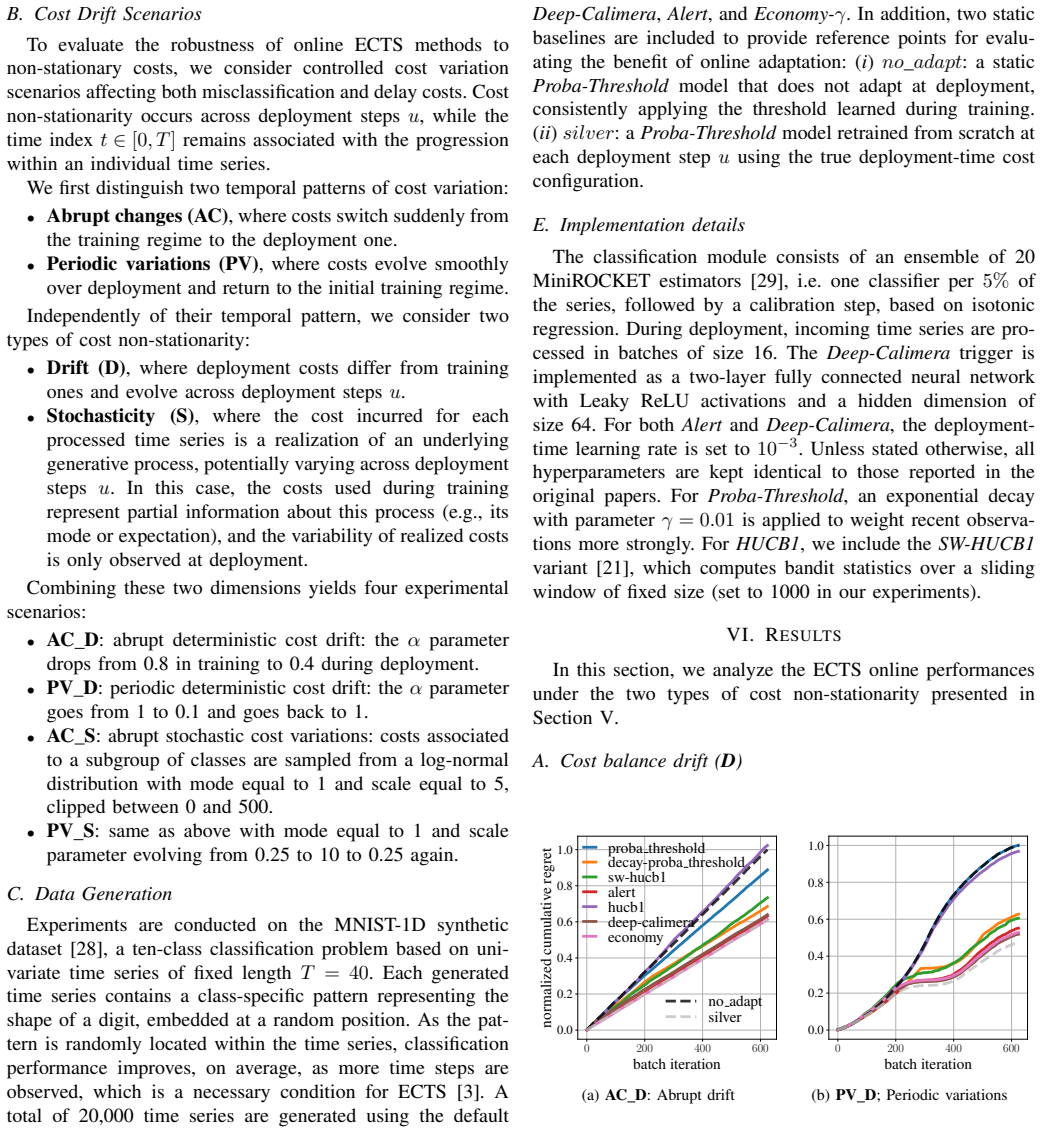
Early classification of time series can be made robust to non-stationary costs by using online learning to update only the triggering model in separable methods, with RL-based approaches providing strong and stable performance across varying cost regimes.
What carries the argument
Separable ECTS methods that fix the classifier and update only the triggering model via online adaptations such as bandit or RL strategies.
If this is right
- ECTS methods can be deployed without full retraining when costs drift.
- RL-based online updates outperform other adaptations in stability.
- Controlled synthetic experiments validate robustness under cost drift and stochastic costs.
- Keeping the classifier fixed reduces computational overhead during deployment.
Where Pith is reading between the lines
- Real-world streaming applications with unpredictable cost shifts could benefit from similar online triggering updates.
- Combining these adaptations with classifier retraining at longer intervals might further improve results.
- Testing on real datasets with observed cost drifts would strengthen the evidence beyond synthetic controls.
Load-bearing premise
That updating only the triggering model while keeping the classifier fixed is enough to handle cost non-stationarity in practice.
What would settle it
An experiment where RL-based online methods fail to improve or maintain accuracy compared to static ECTS under real or more varied cost drift scenarios would falsify the robustness claim.
Figures

read the original abstract
Early Classification of Time Series (ECTS) addresses decision-making problems in which predictions must be made as early as possible while maintaining high accuracy. Most existing ECTS methods assume that the time-dependent decision costs governing the learning objective are known, fixed, and correctly specified. In practice, however, these costs are often uncertain and may change over time, leading to mismatches between training-time and deployment-time objectives. In this paper, we study ECTS under two practically relevant forms of cost non-stationarity: drift in the balance between misclassification and decision delay costs, and stochastic realizations of decision costs that deviate from the nominal training-time model. To address these challenges, we revisit representative ECTS approaches and adapt them to an online learning setting. Focusing on separable methods, we update only the triggering model during deployment, while keeping the classifier fixed. We propose several online adaptations and baselines, including bandit-based and RL-based approaches, and conduct controlled experiments on synthetic data to systematically evaluate robustness under cost non-stationarity. Our results demonstrate that online learning can effectively improve the robustness of ECTS methods to cost drift, with RL-based strategies exhibiting strong and stable performance across varying cost regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies Early Classification of Time Series (ECTS) under cost non-stationarity, specifically drift in the misclassification-vs-delay cost balance and stochastic cost realizations. It adapts representative separable ECTS methods to an online setting by updating only the triggering model (keeping the classifier fixed), proposes bandit- and RL-based online strategies, and evaluates them via controlled experiments on synthetic data. The central claim is that these online adaptations, particularly RL-based ones, improve robustness to cost drift compared to static baselines.
Significance. If the empirical findings hold under broader conditions, the work provides a useful proof-of-concept that online learning can mitigate objective mismatch in ECTS without retraining the full model. The focus on separable methods and the use of standard bandit/RL techniques applied to the triggering decision is a clear strength, as is the systematic variation of cost regimes in the synthetic setup. However, the exclusive reliance on synthetic data with explicitly injected drifts limits immediate practical significance and leaves open whether the reported gains persist under real-world cost non-stationarity or when feature-cost correlations violate the separation assumption.
major comments (3)
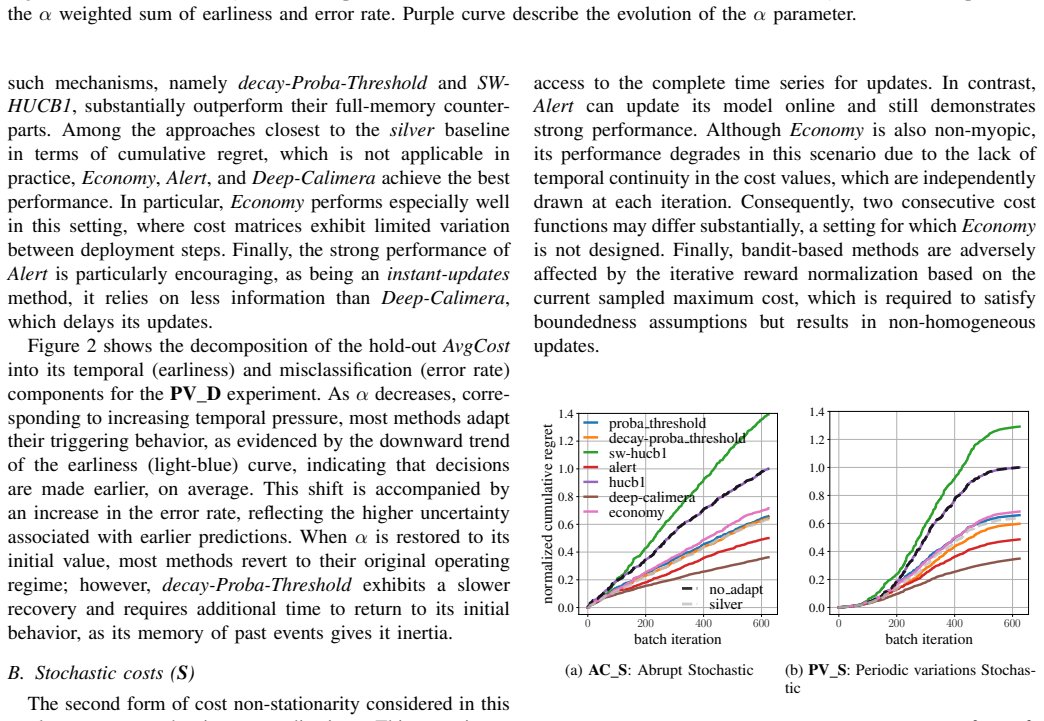
- [Experiments] Experiments section: All reported results use synthetic data generated under explicit drift and stochasticity rules; no real-world datasets exhibiting natural cost non-stationarity (e.g., medical or industrial logs) are evaluated, and no sensitivity analysis is shown for drift processes that deviate from the generative model (different autocorrelation, non-stationary variance, or feature-cost correlation). This directly undercuts the robustness claim for practical deployment.
- [Method] Method description (online adaptation paragraph): The design freezes the classifier and updates only the triggering model; this separation is load-bearing for the proposed approach, yet the paper provides no analysis or counterexample showing what happens when costs and class-conditional distributions shift jointly, which is a realistic failure mode for the claimed robustness.
- [Results] Results (RL vs. bandit comparison): The abstract states that RL-based strategies exhibit 'strong and stable performance,' but without reported effect sizes, confidence intervals, or statistical tests against the bandit baselines and static ECTS methods, it is impossible to judge whether the advantage is practically meaningful or merely an artifact of the synthetic regime.
minor comments (2)
- [Abstract] Abstract: The phrase 'controlled experiments on synthetic data' should be expanded to briefly note the specific drift models used, to set reader expectations.
- [Notation] Notation: Ensure consistent use of symbols for the triggering threshold and cost parameters across the method and experiment sections.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment point-by-point below, indicating where we agree and what revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: All reported results use synthetic data generated under explicit drift and stochasticity rules; no real-world datasets exhibiting natural cost non-stationarity (e.g., medical or industrial logs) are evaluated, and no sensitivity analysis is shown for drift processes that deviate from the generative model (different autocorrelation, non-stationary variance, or feature-cost correlation). This directly undercuts the robustness claim for practical deployment.
Authors: We agree that real-world datasets would strengthen practical claims. Our choice of synthetic data was deliberate to enable precise control and systematic variation of drift parameters (e.g., drift speed, stochasticity level), which is infeasible when the true non-stationarity process is unknown. This design isolates the impact of cost non-stationarity on triggering decisions. In revision we will add an explicit Limitations subsection discussing the synthetic setting and will include additional sensitivity experiments varying autocorrelation and feature-cost correlation within the existing generative framework. revision: partial
-
Referee: [Method] Method description (online adaptation paragraph): The design freezes the classifier and updates only the triggering model; this separation is load-bearing for the proposed approach, yet the paper provides no analysis or counterexample showing what happens when costs and class-conditional distributions shift jointly, which is a realistic failure mode for the claimed robustness.
Authors: The separability assumption is indeed central, as it permits lightweight online updates without retraining the full model. We will add a short theoretical paragraph and a targeted counterexample experiment in the revised manuscript that demonstrates performance degradation under joint distribution-cost shifts, thereby clarifying the boundary conditions of the approach. revision: yes
-
Referee: [Results] Results (RL vs. bandit comparison): The abstract states that RL-based strategies exhibit 'strong and stable performance,' but without reported effect sizes, confidence intervals, or statistical tests against the bandit baselines and static ECTS methods, it is impossible to judge whether the advantage is practically meaningful or merely an artifact of the synthetic regime.
Authors: We agree that quantitative support is required. The revised manuscript will report Cohen's d effect sizes, 95% confidence intervals, and results of paired statistical tests (Wilcoxon signed-rank with Bonferroni correction) comparing RL-based methods against both bandit baselines and static ECTS across all cost regimes. revision: yes
Circularity Check
No significant circularity; standard RL adaptations applied without reduction to inputs
full rationale
The paper adapts existing ECTS methods to online learning by updating only the triggering model while keeping the classifier fixed, proposing bandit-based and RL-based approaches drawn from standard techniques. No equations, derivations, or self-citations are shown that reduce any result to fitted parameters by construction or rely on self-referential premises. The central claim of improved robustness under cost non-stationarity is therefore self-contained as an application of established methods to the ECTS setting, with experiments on synthetic data serving as evaluation rather than a circular fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing ECTS methods assume known, fixed, and correctly specified time-dependent decision costs
Reference graph
Works this paper leans on
-
[1]
Approaches and applications of early classification of time series: A review,
A. Gupta, H. P. Gupta, B. Biswas, and T. Dutta, “Approaches and applications of early classification of time series: A review,”IEEE Transactions on Artificial Intelligence, vol. 1, no. 1, pp. 47–61, 2020
work page 2020
-
[2]
A framework to evaluate early time-series classification algorithms
C. Akasiadis, E. Kladis, P.-F. Kamberi, E. Michelioudakis, E. Alevizos, and A. Artikis, “A framework to evaluate early time-series classification algorithms.” inEDBT, 2024, pp. 623–635
work page 2024
-
[3]
Early classifica- tion of time series: A survey and benchmark,
A. Renault, A. Bondu, A. Cornu ´ejols, and V . Lemaire, “Early classifica- tion of time series: A survey and benchmark,”Transactions on Machine Learning Research
-
[4]
Open challenges for ma- chine learning based early decision-making research,
A. Bondu, Y . Achenchabe, A. Bifet, F. Cl ´erot, A. Cornu ´ejols, J. Gama, G. H ´ebrail, V . Lemaire, and P.-F. Marteau, “Open challenges for ma- chine learning based early decision-making research,”ACM SIGKDD Explorations Newsletter, vol. 24, no. 2, pp. 12–31, 2022
work page 2022
-
[5]
L. M. Fleuren, T. L. T. Klausch, C. L. Zwager, L. J. Schoonmade, T. Guo, L. F. Roggeveen, E. L. Swart, A. R. J. Girbes, P. Thoral, A. Ercoleet al., “Machine learning for the prediction of sepsis: A systematic review and meta-analysis of diagnostic test accuracy,”Intensive Care Medicine, vol. 46, no. 3, pp. 383–400, 2020
work page 2020
-
[6]
Calimera: A new early time series classification method,
J. M. Bilski and A. Jastrzebska, “Calimera: A new early time series classification method,”Information Processing & Management, vol. 60, no. 5, p. 103465, 2023
work page 2023
-
[7]
Deep rein- forcement learning based triggering function for early classifiers of time series,
A. Renault, A. Bondu, A. Cornu ´ejols, and V . Lemaire, “Deep rein- forcement learning based triggering function for early classifiers of time series,”arXiv preprint arXiv:2502.06584, 2025
-
[8]
Early classification of time series: Cost-based optimization criterion and algorithms,
Y . Achenchabe, A. Bondu, A. Cornu ´ejols, and A. Dachraoui, “Early classification of time series: Cost-based optimization criterion and algorithms,”Machine Learning, vol. 110, no. 6, pp. 1481–1504, 2021
work page 2021
-
[9]
Early classification of time series as a non myopic sequential decision making problem,
A. Dachraoui, A. Bondu, and A. Cornu ´ejols, “Early classification of time series as a non myopic sequential decision making problem,” in Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2015, Porto, Portugal, September 7-11, 2015, Proceedings, Part I 15. Springer, 2015, pp. 433–447
work page 2015
-
[10]
The foundations of cost-sensitive learning,
C. Elkan, “The foundations of cost-sensitive learning,” inInternational joint conference on artificial intelligence, vol. 17, no. 1. Lawrence Erlbaum Associates Ltd, 2001, pp. 973–978
work page 2001
-
[11]
Thresholding for making classifiers cost- sensitive,
V . S. Sheng and C. X. Ling, “Thresholding for making classifiers cost- sensitive,” inAaai, vol. 6, 2006, pp. 476–481
work page 2006
-
[12]
Cost-sensitive ensemble learning: a unifying framework,
G. Petrides and W. Verbeke, “Cost-sensitive ensemble learning: a unifying framework,”Data Mining and Knowledge Discovery, vol. 36, no. 1, pp. 1–28, 2022
work page 2022
-
[13]
Cost-sensitive online classification,
J. Wang, P. Zhao, and S. C. Hoi, “Cost-sensitive online classification,” IEEE Transactions on Knowledge and Data Engineering, vol. 26, no. 10, pp. 2425–2438, 2013
work page 2013
-
[14]
Concept drift detection through resampling,
M. Harel, S. Mannor, R. El-Yaniv, and K. Crammer, “Concept drift detection through resampling,” inInternational conference on machine learning. PMLR, 2014, pp. 1009–1017
work page 2014
-
[15]
Learning under concept drift: A review,
J. Lu, A. Liu, F. Dong, F. Gu, J. Gama, and G. Zhang, “Learning under concept drift: A review,”IEEE transactions on knowledge and data engineering, vol. 31, no. 12, pp. 2346–2363, 2018
work page 2018
-
[16]
An overview on concept drift learning,
A. S. Iwashita and J. P. Papa, “An overview on concept drift learning,” IEEE access, vol. 7, pp. 1532–1547, 2018
work page 2018
-
[17]
A new on-line learning method for coping with recurring concepts: The adacc system,
G. Jaber, A. Cornu ´ejols, and P. Tarroux, “A new on-line learning method for coping with recurring concepts: The adacc system,” inInternational conference on neural information processing. Springer, 2013, pp. 595– 604
work page 2013
-
[18]
Reinforcement learning algo- rithm for non-stationary environments,
S. Padakandla, P. KJ, and S. Bhatnagar, “Reinforcement learning algo- rithm for non-stationary environments,”Applied Intelligence, vol. 50, no. 11, pp. 3590–3606, 2020
work page 2020
-
[19]
Robust reinforcement learning,
J. Morimoto and K. Doya, “Robust reinforcement learning,”Neural computation, vol. 17, no. 2, pp. 335–359, 2005
work page 2005
-
[20]
Robust reinforcement learning: A review of foundations and recent advances,
J. Moos, K. Hansel, H. Abdulsamad, S. Stark, D. Clever, and J. Peters, “Robust reinforcement learning: A review of foundations and recent advances,”Machine Learning and Knowledge Extraction, vol. 4, no. 1, pp. 276–315, 2022
work page 2022
-
[21]
On Upper-Confidence Bound Policies for Non-Stationary Bandit Problems
A. Garivier and E. Moulines, “On upper-confidence bound policies for non-stationary bandit problems,”arXiv preprint arXiv:0805.3415, 2008
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[22]
Stochastic multi-armed-bandit problem with non-stationary rewards,
O. Besbes, Y . Gur, and A. Zeevi, “Stochastic multi-armed-bandit problem with non-stationary rewards,”Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[23]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press, 2018
work page 2018
-
[24]
Beyond greedy exits: Improved early exit decisions for risk control and reliability,
D. J. Bajpai and M. K. Hanawal, “Beyond greedy exits: Improved early exit decisions for risk control and reliability,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[25]
Finite-time analysis of the multiarmed bandit problem,
P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,”Machine learning, vol. 47, no. 2, pp. 235– 256, 2002
work page 2002
-
[26]
Multi-armed bandit problems with history,
P. Shivaswamy and T. Joachims, “Multi-armed bandit problems with history,” inArtificial intelligence and statistics. PMLR, 2012, pp. 1046– 1054
work page 2012
-
[27]
Issues in evaluation of stream learning algorithms,
J. a. Gama, R. Sebasti ˜ao, and P. P. Rodrigues, “Issues in evaluation of stream learning algorithms,” inSIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’09. Association for Computing Machinery, 2009, p. 329–338
work page 2009
-
[28]
Scaling down deep learning with mnist- 1d,
S. Greydanus and D. Kobak, “Scaling down deep learning with mnist- 1d,”arXiv preprint arXiv:2011.14439, 2020
-
[29]
Minirocket: A very fast (almost) deterministic transform for time series classification,
A. Dempster, D. F. Schmidt, and G. I. Webb, “Minirocket: A very fast (almost) deterministic transform for time series classification,” inProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, 2021, pp. 248–257
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.