Recognition: 2 theorem links
· Lean TheoremMulti-Scale Wavelet Transformers for Operator Learning of Dynamical Systems
Pith reviewed 2026-05-16 08:18 UTC · model grok-4.3
The pith
Wavelet transformers learn dynamical system operators by preserving high-frequency content across scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
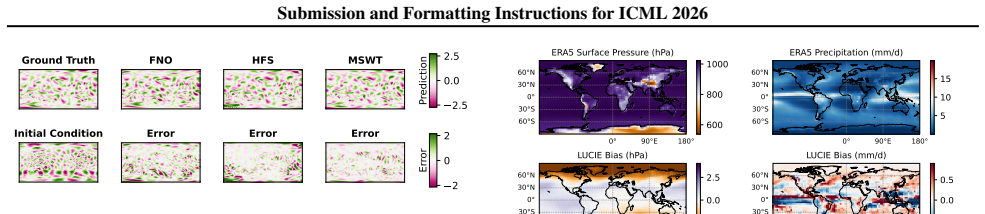
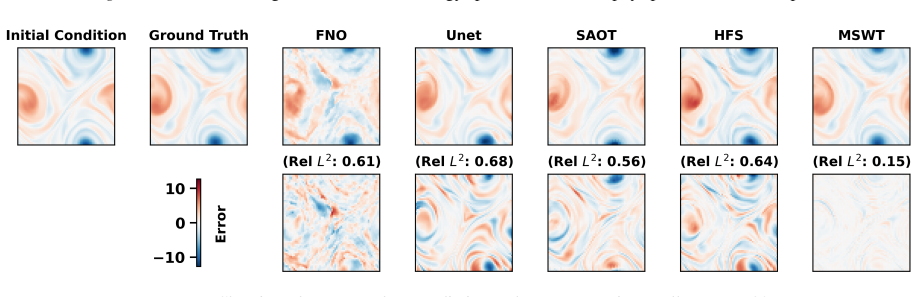
Multi-scale wavelet transformers learn system dynamics directly in a tokenized wavelet domain. The wavelet transform decomposes the state into low- and high-frequency components across scales; a wavelet-preserving downsampling scheme retains the high-frequency coefficients without loss; and wavelet-based attention layers capture dependencies both within and across frequency bands. This architecture yields substantial reductions in prediction error and improved long-horizon spectral fidelity on chaotic dynamical systems, together with lower climatological bias when applied to ERA5 climate reanalysis.
What carries the argument
Multi-scale wavelet transformer that tokenizes the wavelet transform of the input field and performs wavelet-based attention across scales and frequency bands.
If this is right
- Prediction error decreases substantially on standard chaotic test systems.
- Long-horizon spectral fidelity improves, preserving energy at small scales.
- Climatological bias is reduced when the model is trained on ERA5 reanalysis.
- The same architecture can serve as a drop-in surrogate that runs orders of magnitude faster than traditional numerical solvers.
Where Pith is reading between the lines
- The wavelet-domain approach may generalize to other operator-learning tasks that require faithful representation of fine-scale structure, such as turbulence closure modeling.
- Hybrid models that combine MSWT layers with physics-informed constraints could further improve stability without sacrificing speed.
- Similar frequency-aware tokenization might mitigate spectral bias in other sequence or grid-based transformers used for time-series forecasting.
Load-bearing premise
The wavelet-preserving downsampling and wavelet attention retain high-frequency features without introducing artifacts that would destabilize long-horizon dynamics.
What would settle it
A controlled experiment on the Lorenz-96 system showing that MSWT long-horizon predictions have the same or higher error and the same or worse spectral energy decay as a standard Fourier neural operator baseline.
Figures


















read the original abstract
Recent years have seen a surge in data-driven surrogates for dynamical systems that can be orders of magnitude faster than numerical solvers. However, many machine learning-based models such as neural operators exhibit spectral bias, attenuating high-frequency components that often encode small-scale structure. This limitation is particularly damaging in applications such as weather forecasting, where misrepresented high frequencies can induce long-horizon instability. To address this issue, we propose multi-scale wavelet transformers (MSWTs), which learn system dynamics in a tokenized wavelet domain. The wavelet transform explicitly separates low- and high-frequency content across scales. MSWTs leverage a wavelet-preserving downsampling scheme that retains high-frequency features and employ wavelet-based attention to capture dependencies across scales and frequency bands. Experiments on chaotic dynamical systems show substantial error reductions and improved long horizon spectral fidelity. On the ERA5 climate reanalysis, MSWTs further reduce climatological bias, demonstrating their effectiveness in a real-world forecasting setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes multi-scale wavelet transformers (MSWTs) for operator learning on dynamical systems. The architecture tokenizes inputs in the wavelet domain, applies a wavelet-preserving downsampling scheme to retain high-frequency coefficients, and uses wavelet-based attention to model cross-scale dependencies. The central claim is that this construction mitigates the spectral bias of standard neural operators, yielding lower rollout errors and improved long-horizon spectral fidelity on chaotic systems together with reduced climatological bias on ERA5 reanalysis data.
Significance. If the empirical gains are reproducible and attributable to the wavelet construction rather than capacity or training details, the work would offer a concrete architectural route to stable multi-scale forecasting. The emphasis on explicit frequency separation is well-motivated for chaotic and climate applications, and successful validation would strengthen the case for wavelet-domain operators in scientific machine learning.
major comments (3)
- [§3] §3 (Methods): the claim that the wavelet-preserving downsampling retains high-frequency content without phase or amplitude distortion is load-bearing for the long-horizon stability argument, yet no explicit bound, preservation lemma, or controlled ablation isolating the downsampling rule from standard pooling is supplied; without this, the reported spectral-fidelity gains cannot be confidently attributed to the wavelet mechanism rather than model capacity.
- [§4] §4 (Experiments): the abstract asserts 'substantial error reductions' and 'improved long horizon spectral fidelity' on chaotic systems, but the manuscript must include quantitative tables with baseline comparisons (e.g., FNO, DeepONet), error bars, and ablation rows that remove either the wavelet attention or the preserving downsampling; absent these, the central empirical claim remains unverifiable.
- [§4.2] §4.2 (ERA5 results): the reported reduction in climatological bias is presented without a corresponding spectral decomposition or high-frequency error metric; if the bias reduction occurs only in low-frequency bands, it would weaken the paper's claim that high-frequency retention is the operative mechanism.
minor comments (2)
- [§3.1] Clarify the precise wavelet family, decomposition level, and padding strategy in the first paragraph of §3.1; notation for the tokenized coefficients is introduced without an explicit equation reference.
- [Figure 2] Figure 2 caption should state the exact time horizon and frequency band used for the spectral error curves so readers can reproduce the fidelity comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Methods): the claim that the wavelet-preserving downsampling retains high-frequency content without phase or amplitude distortion is load-bearing for the long-horizon stability argument, yet no explicit bound, preservation lemma, or controlled ablation isolating the downsampling rule from standard pooling is supplied; without this, the reported spectral-fidelity gains cannot be confidently attributed to the wavelet mechanism rather than model capacity.
Authors: We appreciate the referee's emphasis on formal justification. The downsampling rule is constructed so that only the approximation coefficients are downsampled while all detail coefficients are retained at their native resolution; because the discrete wavelet transform is a linear isometry (up to the filter norms), this operation introduces neither phase shift nor amplitude scaling beyond the known wavelet filter bounds. We will add a short preservation lemma in the revised §3 that bounds the L2 energy of the retained high-frequency coefficients. We will also insert a controlled ablation in §4 that replaces our downsampling with standard average pooling while keeping all other components fixed, thereby isolating its contribution to spectral fidelity. revision: yes
-
Referee: [§4] §4 (Experiments): the abstract asserts 'substantial error reductions' and 'improved long horizon spectral fidelity' on chaotic systems, but the manuscript must include quantitative tables with baseline comparisons (e.g., FNO, DeepONet), error bars, and ablation rows that remove either the wavelet attention or the preserving downsampling; absent these, the central empirical claim remains unverifiable.
Authors: We agree that the current experimental presentation is insufficiently quantitative. In the revised manuscript we will expand §4 with tables that report rollout MSE (with standard deviations over five independent runs) for MSWT against FNO, DeepONet, and the other baselines on all chaotic-system benchmarks. We will add two ablation rows: (i) MSWT with wavelet attention replaced by standard multi-head attention, and (ii) MSWT with the preserving downsampling replaced by conventional pooling. Both ablations will include the same long-horizon spectral-fidelity metrics already used in the main results. revision: yes
-
Referee: [§4.2] §4.2 (ERA5 results): the reported reduction in climatological bias is presented without a corresponding spectral decomposition or high-frequency error metric; if the bias reduction occurs only in low-frequency bands, it would weaken the paper's claim that high-frequency retention is the operative mechanism.
Authors: We accept this criticism. The revised §4.2 will contain a wavelet-based spectral decomposition of the climatological bias, reporting separate errors for the approximation (low-frequency) and detail (high-frequency) coefficients. We will additionally tabulate a high-frequency-specific metric (mean squared error restricted to the detail sub-bands) to demonstrate that the bias reduction is concentrated in the high-frequency regime, thereby supporting the mechanistic role of high-frequency retention. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The provided abstract and method description introduce MSWTs via wavelet transforms, a wavelet-preserving downsampling scheme, and wavelet-based attention as independent architectural choices to mitigate spectral bias. No equations, definitions, or self-citations are shown that reduce the claimed error reductions or spectral fidelity gains to quantities defined by fitted parameters, self-referential normalizations, or prior author results by construction. The central claims rest on experimental outcomes rather than tautological reductions, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wavelet transforms separate low- and high-frequency content across scales without information loss when paired with appropriate downsampling
invented entities (1)
-
Multi-scale wavelet transformers (MSWTs)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MSWTs leverage a wavelet-preserving downsampling scheme that retains high-frequency features and employ wavelet-based attention to capture dependencies across scales and frequency bands.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The wavelet transform explicitly separates low- and high-frequency content across scales.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bonev, B., Kurth, T., Mahesh, A., Bisson, M., Kossaifi, J., Kashinath, K., Anandkumar, A., Collins, W. D., Pritchard, M. S., and Keller, A. FourCastNet 3: A geometric ap- proach to probabilistic machine-learning weather fore- casting at scale.arXiv preprint arXiv:2507.12144,
-
[2]
Chattopadhyay, A. and Hassanzadeh, P. Long-term insta- bilities of deep learning-based digital twins of the cli- mate system: The cause and a solution.arXiv preprint arXiv:2304.07029,
-
[3]
Gupta, G., Xiao, X., and Bogdan, P
URL https://arxiv.org/abs/2111.13587. Gupta, G., Xiao, X., and Bogdan, P. Multiwavelet-based operator learning for differential equations.Advances in neural information processing systems, 34:24048–24062,
- [4]
-
[5]
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Hor´anyi, A., Mu ˜noz-Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., et al. The ERA5 global reanalysis. Quarterly journal of the royal meteorological society, 146(730):1999–2049,
work page 1999
-
[6]
Koshizuka, T., Fujisawa, M., Tanaka, Y ., and Sato, I
doi: 10.1038/s41467-024-49411-w. Koshizuka, T., Fujisawa, M., Tanaka, Y ., and Sato, I. Un- derstanding the expressivity and trainability of Fourier 9 Submission and Formatting Instructions for ICML 2026 neural operator: A mean-field perspective. InAdvances in Neural Information Processing Systems, volume 37, pp. 11021–11060,
-
[8]
URL https://arxiv.org/abs/2202.11214. Qin, S., Lyu, F., Peng, W., Geng, D., Wang, J., Gao, N., Liu, X., and Wang, L. L. Toward a better understanding of Fourier neural operators: Analysis and improvement from a spectral perspective.CoRR,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Rahman, M. A., Ross, Z. E., and Azizzadenesheli, K. U-NO: U-shaped neural operators.arXiv preprint arXiv:2204.11127,
-
[10]
H., Sankaran, S., Wang, H., Pap- pas, G
10 Submission and Formatting Instructions for ICML 2026 Wang, S., Seidman, J. H., Sankaran, S., Wang, H., Pap- pas, G. J., and Perdikaris, P. CViT: Continuous vision transformer for operator learning. InThe Thirteenth Inter- national Conference on Learning Representations,
work page 2026
-
[11]
11 Submission and Formatting Instructions for ICML 2026 A. Wavelet transforms In the following, we provide a brief overview on wavelet transforms. We will focus on the real-valued case, which is more applicable to our setting, though wavelets are more generally defined in terms of complex-valued functions. More details about wavelet transforms can be foun...
work page 2026
-
[12]
14 Submission and Formatting Instructions for ICML 2026 Table 4.Hyperparameter settings and parameter counts for baselines and MSWT. Model Setting # params (M) FNON layers=5, n hidden=64,truncation mode=1616.8 Unet Nlayers=4, n hidden=[16,32,64,256] 12.5 WNO Nlayers=4, n hidden=96,multiscale levels=3 14.5 SAOT Nlayers=5, n hidden=384 14.0 HFS Nlayers=5, n...
-
[13]
17 Submission and Formatting Instructions for ICML 2026 Figure 14.Shallow water equation, kinetic energy spectrum and enstrophy spectrum, rollout step =41 Figure 15.Shallow water equation, prediction and error comparison, rollout step =81 Figure 16.Shallow water equation, kinetic energy spectrum and enstrophy spectrum, rollout step =81 18 Submission and F...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.