Recognition: 2 theorem links
· Lean TheoremMacrOData: New Benchmarks of Thousands of Datasets for Tabular Outlier Detection
Pith reviewed 2026-05-16 06:06 UTC · model grok-4.3
The pith
MacrOData supplies 2,446 tabular datasets for statistically robust outlier detection tests
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
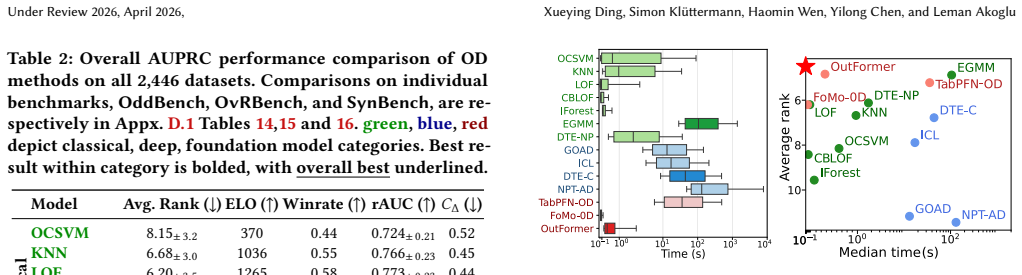
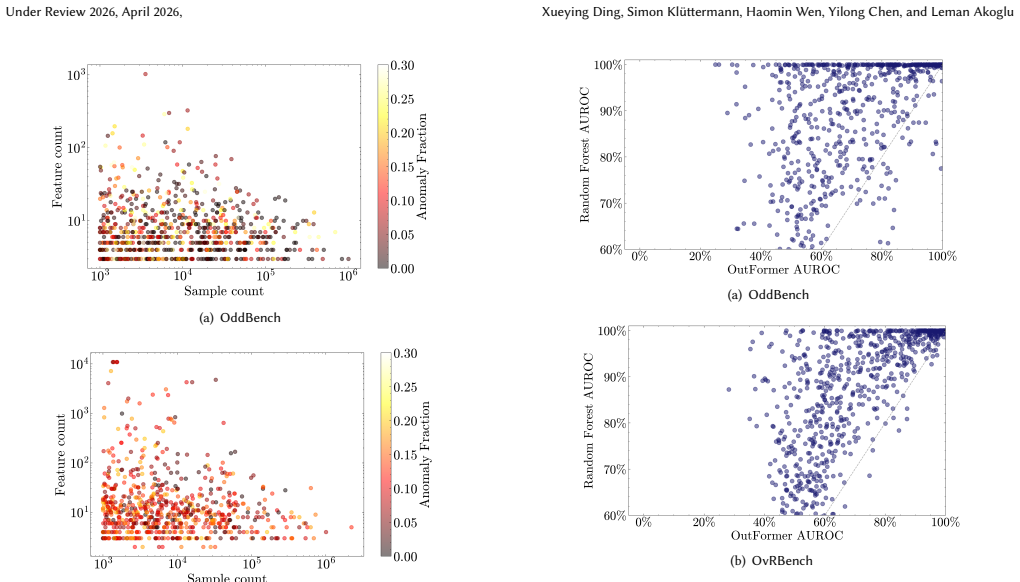
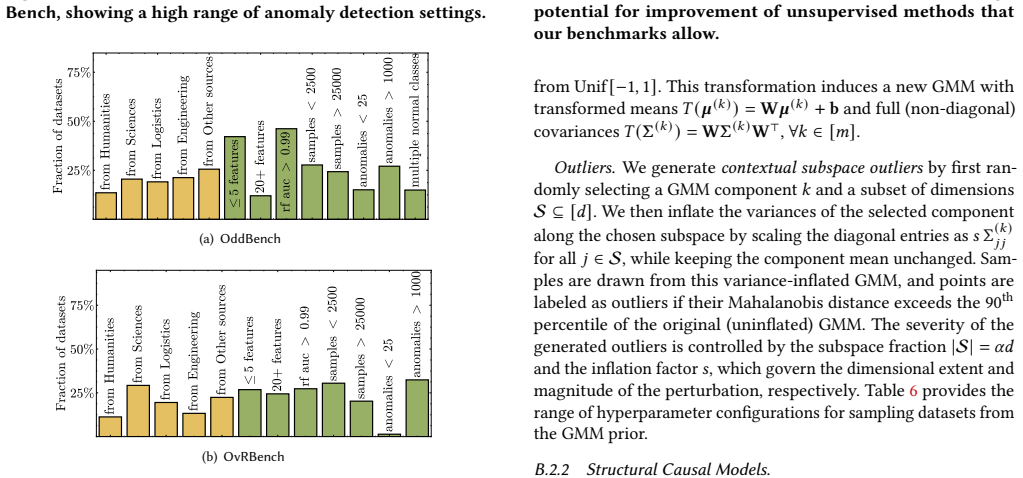
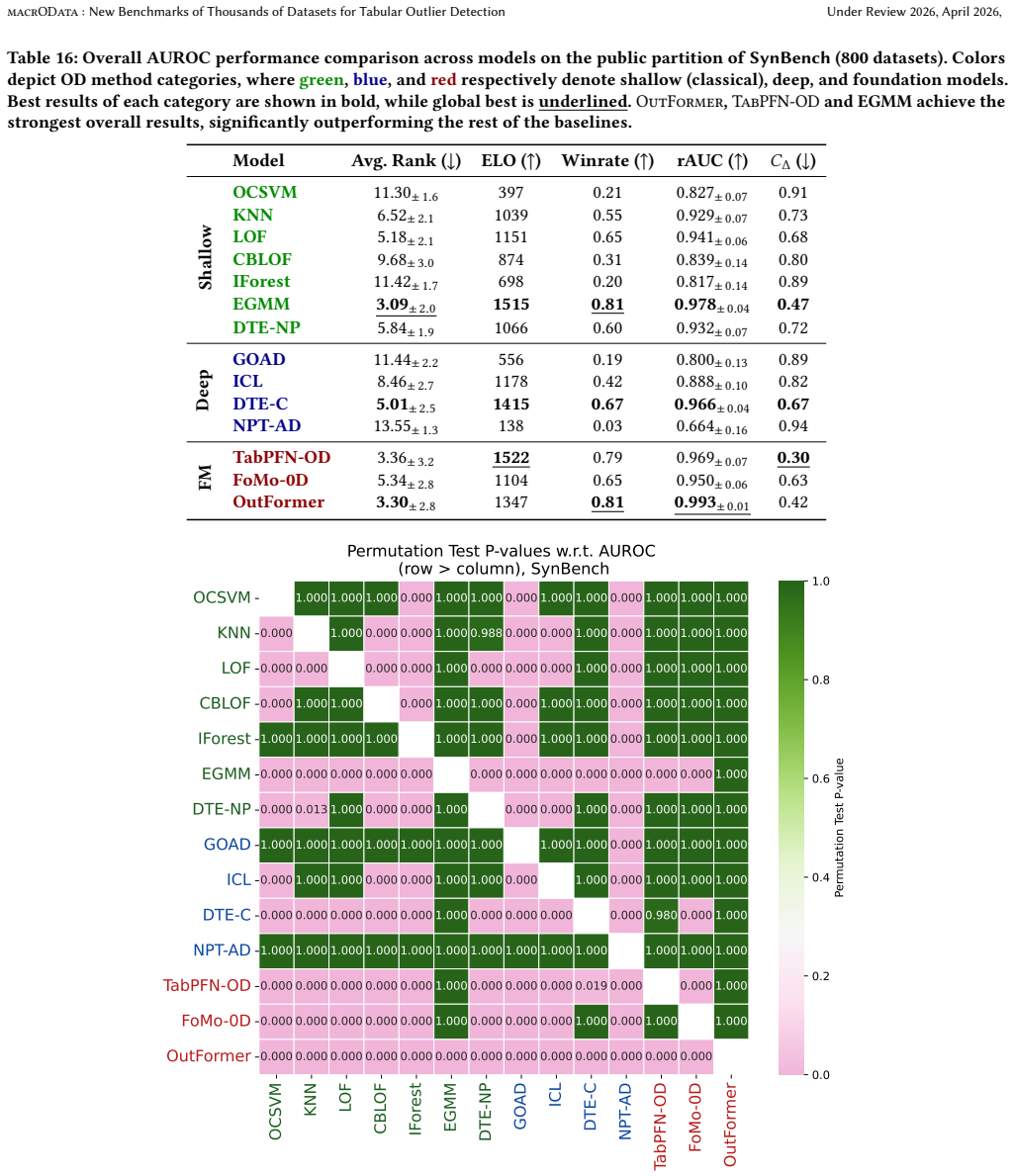
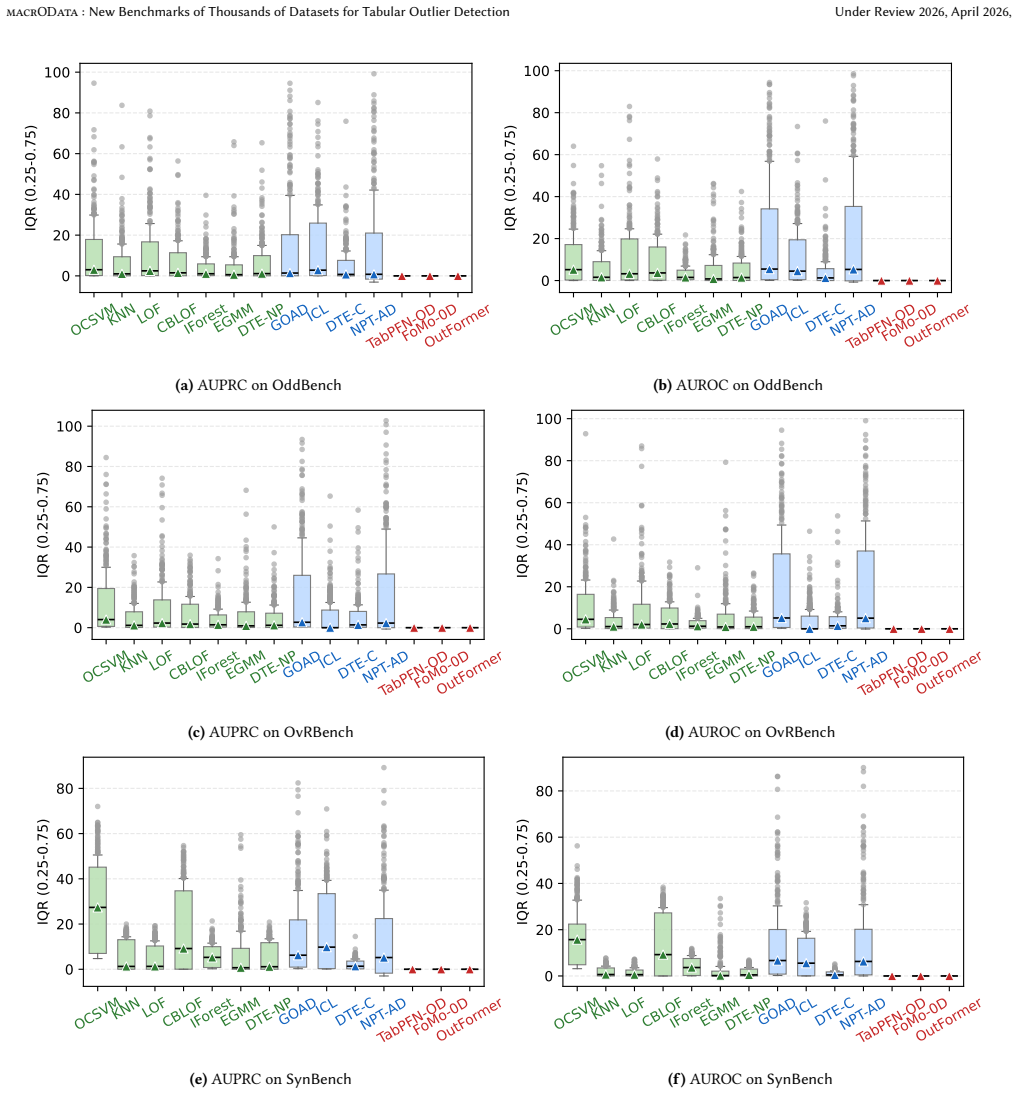
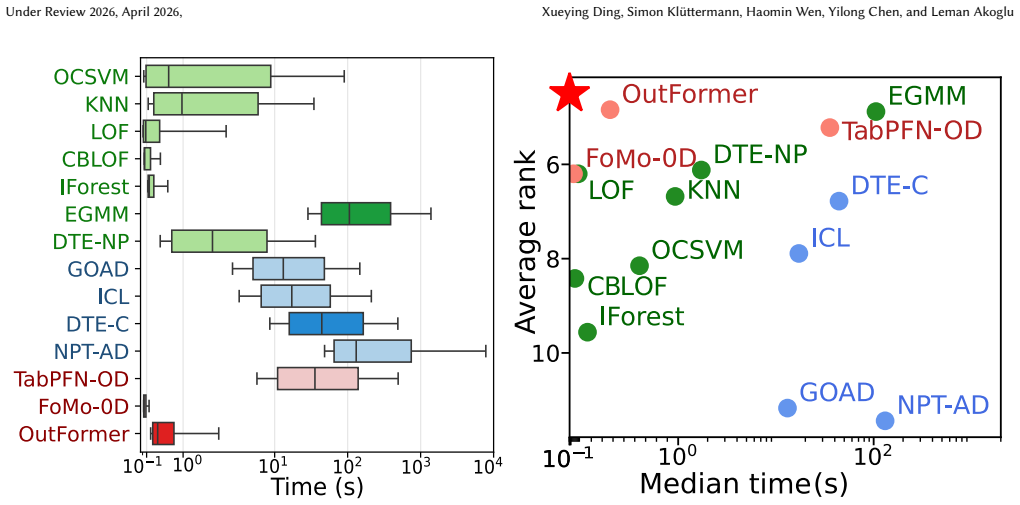
The authors establish that a benchmark of 2,446 datasets, split into OddBench for semantic anomalies, OvrBench for statistical outliers, and SynBench for synthetic cases, supplies the diversity and volume needed to conduct statistically robust evaluations of outlier detection methods on tabular data, complete with train/test splits, metadata annotations, and a held-out leaderboard partition.
What carries the argument
MacrOData benchmark suite, which curates and partitions thousands of tabular datasets into standardized splits with semantic annotations to support comprehensive method comparison
If this is right
- Evaluations gain statistical power from the large number of datasets spanning varied data characteristics
- Experiments reveal performance differences among classical, deep, and foundation-model methods across hyperparameter ranges
- Semantic metadata allows analysis of which methods perform best on specific anomaly types
- Standardized splits and a public leaderboard with held-out labels enable ongoing, reproducible progress tracking
- Practical guidelines for method choice emerge from the aggregated results across all three benchmark components
Where Pith is reading between the lines
- The increased scale may push research toward methods that maintain performance across many data priors rather than overfitting to small benchmark sets
- Future curation efforts could test whether adding time-series or graph-structured tabular data follows similar scaling benefits
- Practitioners could use the released performance tables to select methods for specific application domains such as fraud or sensor monitoring
- The availability of public and private partitions may reduce overfitting to leaderboard scores in future method papers
Load-bearing premise
The real-world datasets selected for OddBench and OvrBench contain cleanly identifiable outliers free of systematic selection bias or label noise that would favor some detection methods over others.
What would settle it
Re-auditing labels on a random sample of datasets from OddBench and OvrBench and finding substantial mislabeling rates or selection biases that alter relative method rankings would show the benchmark does not support fair comparisons.
Figures















read the original abstract
Quality benchmarks are essential for fairly and accurately tracking scientific progress and enabling practitioners to make informed methodological choices. Outlier detection (OD) on tabular data underpins numerous real-world applications, yet existing OD benchmarks remain limited. The prominent OD benchmark AdBench is the de facto standard in the literature, yet comprises only 57 datasets. In addition to other shortcomings discussed in this work, its small scale severely restricts diversity and statistical power. We introduce MacrOData, a large-scale benchmark suite for tabular OD comprising three carefully curated components: OddBench, with 790 datasets containing real-world semantic anomalies; OvrBench, with 856 datasets featuring real-world statistical outliers; and SynBench, with 800 synthetically generated datasets spanning diverse data priors and outlier archetypes. Owing to its scale and diversity, MacrOData enables comprehensive and statistically robust evaluation of tabular OD methods. Our benchmarks further satisfy several key desiderata: We provide standardized train/test splits for all datasets, public/private benchmark partitions with held-out test labels for the latter reserved toward an online leaderboard, and annotate our datasets with semantic metadata. We conduct extensive experiments across all benchmarks, evaluating a broad range of OD methods comprising classical, deep, and foundation models, over diverse hyperparameter configurations. We report detailed empirical findings, practical guidelines, as well as individual performances as references for future research. All benchmarks containing 2,446 datasets combined are open-sourced, along with a publicly accessible leaderboard hosted at https://huggingface.co/MacrOData-CMU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
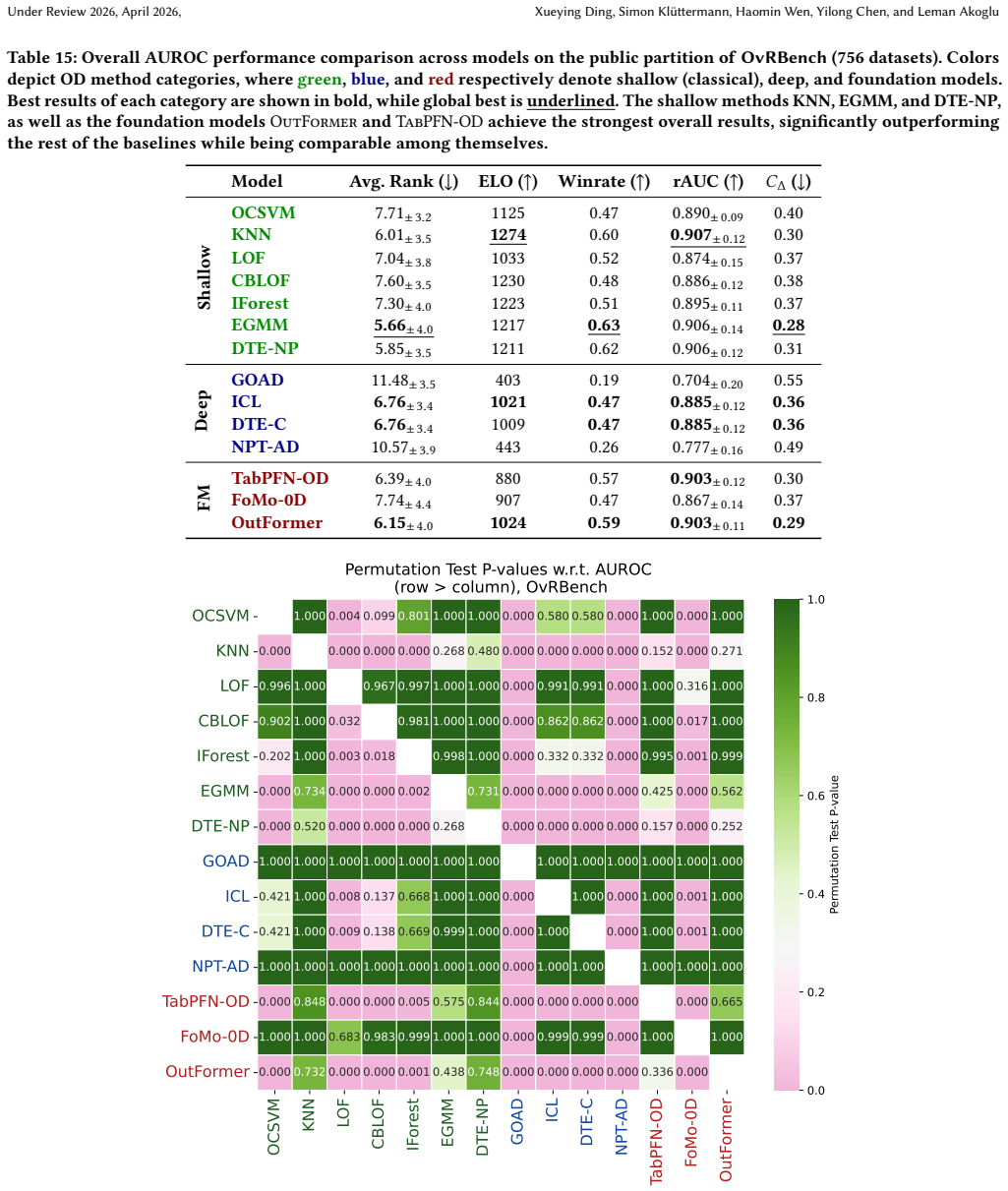
Summary. The paper introduces MacrOData, a large-scale benchmark suite for tabular outlier detection comprising OddBench (790 real-world semantic anomaly datasets), OvrBench (856 real-world statistical outlier datasets), and SynBench (800 synthetically generated datasets). It addresses limitations of prior benchmarks such as AdBench by providing standardized train/test splits, public/private partitions with held-out labels, semantic metadata annotations, and extensive experiments evaluating classical, deep, and foundation-model OD methods across diverse hyperparameter settings, along with empirical findings and practical guidelines. All 2,446 datasets are open-sourced with a public leaderboard.
Significance. If the curation and labeling of the real-world components prove reliable, MacrOData would represent a substantial advance by scaling tabular OD evaluation far beyond the 57 datasets in AdBench, enabling statistically robust comparisons, diversity across data priors, and reproducible research via the open release and leaderboard. The provision of standardized splits and metadata is a concrete strength that supports extensibility.
major comments (2)
- [§3] §3 (dataset curation): The description of OddBench and OvrBench as 'carefully curated' real-world semantic anomalies and statistical outliers provides no quantitative validation of label quality, such as inter-annotator agreement, source-label consistency checks, or audits for selection bias and label noise. This is load-bearing because all downstream empirical comparisons, performance rankings, and practical guidelines rest on the assumption that the ground-truth outliers are clean and representative.
- [§4] §4 (experimental protocol): The paper reports results over 'diverse hyperparameter configurations' for a broad range of OD methods, but does not specify the exact search spaces, number of trials per method, or controls for computational budget; without these details it is unclear whether the reported rankings are robust to hyperparameter choice or could shift under different tuning regimes.
minor comments (2)
- [Abstract] The abstract states 2,446 datasets in total; confirm whether this figure accounts for any overlaps or deduplication steps between OddBench, OvrBench, and SynBench.
- Figure captions and table headers should explicitly state the number of datasets and methods included in each panel to improve readability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for recognizing the potential of MacrOData to advance tabular outlier detection research. We address each major comment below and outline the corresponding revisions.
read point-by-point responses
-
Referee: [§3] §3 (dataset curation): The description of OddBench and OvrBench as 'carefully curated' real-world semantic anomalies and statistical outliers provides no quantitative validation of label quality, such as inter-annotator agreement, source-label consistency checks, or audits for selection bias and label noise. This is load-bearing because all downstream empirical comparisons, performance rankings, and practical guidelines rest on the assumption that the ground-truth outliers are clean and representative.
Authors: We agree that quantitative validation of label quality is essential. The curation process for OddBench and OvrBench selected datasets exclusively from public repositories where outlier labels were supplied by the original authors, followed by manual verification against dataset documentation to confirm consistency. Inter-annotator agreement metrics are not applicable because we did not introduce new labels. In the revised manuscript we will expand §3 with an explicit description of the source-label consistency checks performed, any detectable label noise rates, and a dedicated discussion of selection biases together with the mitigation steps taken during dataset inclusion. These additions will be supported by summary statistics on label provenance where available. revision: partial
-
Referee: [§4] §4 (experimental protocol): The paper reports results over 'diverse hyperparameter configurations' for a broad range of OD methods, but does not specify the exact search spaces, number of trials per method, or controls for computational budget; without these details it is unclear whether the reported rankings are robust to hyperparameter choice or could shift under different tuning regimes.
Authors: We agree that precise specification of the hyperparameter protocol is required for assessing result robustness. The experiments employed random search over method-specific ranges with a fixed trial budget per method to maintain computational tractability across 2,446 datasets. In the revised manuscript we will add a dedicated subsection (and supplementary tables) that enumerate the exact search spaces for every method, the number of trials executed (50 per method), and the computational budget controls applied (maximum wall-clock time and memory limits per run). This information will allow readers to evaluate sensitivity to alternative tuning regimes. revision: yes
Circularity Check
No circularity in benchmark dataset release
full rationale
The paper introduces MacrOData as a collection of 2446 curated datasets (OddBench, OvrBench, SynBench) plus evaluation protocols and a leaderboard. No derivation chain, equations, or predictions exist that could reduce to inputs by construction. Curation relies on external data sources and standard splits rather than fitted parameters or self-referential definitions. Self-citations, if present, are not load-bearing for any core claim. The contribution is empirical resource release and comparative evaluation, which is self-contained against external benchmarks and contains no self-definitional, fitted-input, or uniqueness-imported steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- Dataset inclusion and labeling criteria
axioms (1)
- domain assumption Real tabular datasets contain identifiable outliers that can be labeled consistently
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce MacrOData, a large-scale benchmark suite for tabular OD comprising three carefully curated components: OddBench, with 790 datasets containing real-world semantic anomalies; OvRBench, with 856 datasets featuring real-world statistical outliers; and SynBench, with 800 synthetically generated datasets spanning diverse data priors and outlier archetypes.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We conduct extensive experiments across all benchmarks, evaluating a broad range of OD methods comprising classical, deep, and foundation models, over diverse hyperparameter configurations.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Charu C. Aggarwal and Saket Sathe. 2015. Theoretical foundations and algorithms for outlier ensembles.Acm sigkdd explorations newsletter17, 1 (2015), 24–47
work page 2015
-
[3]
Leman Akoglu. 2021. Anomaly mining: Past, present and future. InProceedings of the 30th ACM International Conference on Information & Knowledge Management. 1–2
work page 2021
-
[4]
Lion Bergman and Yedid Hoshen. 2020. Classification-Based Anomaly Detection for General Data. InInternational Conference on Learning Representations
work page 2020
- [5]
-
[6]
Stephan Bongers, Patrick Forré, Jonas Peters, and Joris M Mooij. 2021. Founda- tions of structural causal models with cycles and latent variables.The Annals of Statistics49, 5 (2021), 2885–2915
work page 2021
-
[7]
Leo Breiman. 2001. Random Forests.Mach. Learn.45, 1 (Oct. 2001), 5–32. doi:10. 1023/A:1010933404324
work page 2001
-
[8]
Breunig, Hans-Peter Kriegel, Raymond T
Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng, and Jörg Sander. 2000. LOF: identifying density-based local outliers. InProceedings of the 2000 ACM SIGMOD International Conference on Management of Data(Dallas, Texas, USA) (SIGMOD ’00). Association for Computing Machinery, New York, NY, USA, 93–104. doi:10.1145/342009.335388
-
[9]
Guilherme O Campos, Arthur Zimek, Jörg Sander, Ricardo JGB Campello, Barbora Micenková, Erich Schubert, Ira Assent, and Michael E Houle. 2016. On the evaluation of unsupervised outlier detection: measures, datasets, and an empirical study.Data mining and knowledge discovery30 (2016), 891–927
work page 2016
-
[10]
Miguel A. Carreira-Perpinan. 2002. Mode-finding for mixtures of Gaussian distributions.IEEE Transactions on Pattern Analysis and Machine Intelligence22, 11 (2002), 1318–1323
work page 2002
-
[11]
Raghavendra Chalapathy and Sanjay Chawla. 2019. Deep learning for anomaly detection: A survey.arXiv preprint arXiv:1901.03407(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[12]
Aaron Clauset, Cosma Rohilla Shalizi, and Mark EJ Newman. 2009. Power-law distributions in empirical data.SIAM review51, 4 (2009), 661–703
work page 2009
- [13]
-
[14]
Xueying Ding, Lingxiao Zhao, and Leman Akoglu. 2022. Hyperparameter sensi- tivity in deep outlier detection: Analysis and a scalable hyper-ensemble solution. Advances in Neural Information Processing Systems35 (2022), 9603–9616
work page 2022
-
[15]
Xueying Ding, Yue Zhao, and Leman Akoglu. 2024. Fast Unsupervised Deep Outlier Model Selection with Hypernetworks.ACM SIGKDD(2024)
work page 2024
-
[16]
Rémi Domingues, Maurizio Filippone, Pietro Michiardi, and Jihane Zouaoui
-
[17]
A comparative evaluation of outlier detection algorithms: Experiments and analyses.Pattern recognition74 (2018), 406–421
work page 2018
- [18]
-
[19]
Arpad E. Elo. 1967. The Proposed USCF Rating System, Its Development, Theory, and Applications.Chess Life22 (1967), 242–247
work page 1967
-
[20]
Andrew Emmott, Shubhomoy Das, Thomas Dietterich, Alan Fern, and Weng- Keen Wong. 2015. A meta-analysis of the anomaly detection problem.arXiv preprint arXiv:1503.01158(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[21]
Andrew F Emmott, Shubhomoy Das, Thomas Dietterich, Alan Fern, and Weng- Keen Wong. 2013. Systematic construction of anomaly detection benchmarks from real data. InProceedings of the ACM SIGKDD workshop on outlier detection and description. 16–21
work page 2013
- [22]
- [23]
-
[24]
Pieter Gijsbers, Erin LeDell, Janek Thomas, Sébastien Poirier, Bernd Bischl, and Joaquin Vanschoren. 2019. An open source AutoML benchmark.arXiv preprint arXiv:1907.00909(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Michael Glodek, Martin Schels, and Friedhelm Schwenker. 2013. Ensemble Gaussian mixture models for probability density estimation.Comput. Stat.28, 1 (Feb. 2013), 127–138. doi:10.1007/s00180-012-0374-5
-
[26]
Markus Goldstein and Seiichi Uchida. 2016. A comparative evaluation of un- supervised anomaly detection algorithms for multivariate data.PloS one11, 4 (2016)
work page 2016
-
[27]
Songqiao Han, Xiyang Hu, Hailiang Huang, Minqi Jiang, and Yue Zhao. 2022. Ad- bench: Anomaly detection benchmark.Advances in Neural Information Processing Systems35 (2022)
work page 2022
-
[28]
Zengyou He, Xiaofei Xu, and Shengchun Deng. 2003. Discovering Cluster-Based Local Outliers.Pattern Recogn. Lett.24, 9–10 (jun 2003), 1641–1650
work page 2003
-
[29]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems33 (2020), 6840–6851
work page 2020
-
[30]
Victoria Hodge and Jim Austin. 2004. A survey of outlier detection methodologies. Artificial intelligence review22, 2 (2004), 85–126
work page 2004
-
[31]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. 2023. TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. InThe Eleventh International Conference on Learning Representations
work page 2023
- [32]
-
[33]
Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. 2008. Isolation Forest. In2008 Eighth IEEE International Conference on Data Mining. 413–422
work page 2008
- [34]
-
[35]
Victor Livernoche, Vineet Jain, Yashar Hezaveh, and Siamak Ravanbakhsh. 2024. On Diffusion Modeling for Anomaly Detection.. InICLR
work page 2024
-
[36]
Martin Q Ma, Yue Zhao, Xiaorong Zhang, and Leman Akoglu. 2023. The need for unsupervised outlier model selection: A review and evaluation of internal evaluation strategies.ACM SIGKDD Explorations Newsletter25, 1 (2023), 19–35
work page 2023
-
[37]
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakrishnan, Micah Goldblum, and Colin White. 2023. When do neural nets outperform boosted trees on tabular data?Advances in Neural Information Processing Systems36 (2023), 76336–76369
work page 2023
-
[38]
2006.An introduction to copulas
Roger B Nelsen. 2006.An introduction to copulas. Springer
work page 2006
-
[39]
Guansong Pang, Chunhua Shen, Longbing Cao, and Anton Van Den Hengel
-
[40]
https://github.com/mala-lab/ADBenchmarks-anomaly- detection-datasets
Deep learning for anomaly detection: A review.ACM computing surveys (CSUR)54, 2 (2021), 1–38. https://github.com/mala-lab/ADBenchmarks-anomaly- detection-datasets
work page 2021
-
[41]
Guansong Pang, Chunhua Shen, and Anton van den Hengel. 2019. Deep Anomaly Detection with Deviation Networks. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Association for Computing Machinery, New York, NY, USA, 353–362. doi:10.1145/3292500. 3330871
-
[42]
2017.Elements of causal inference: foundations and learning algorithms
Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. 2017.Elements of causal inference: foundations and learning algorithms. The MIT press
work page 2017
-
[43]
Sridhar Ramaswamy, Rajeev Rastogi, and Kyuseok Shim. 2000. Efficient algo- rithms for mining outliers from large data sets. InProceedings of the 2000 ACM SIGMOD International Conference on Management of Data. Association for Com- puting Machinery, New York, NY, USA, 427–438. doi:10.1145/342009.335437
-
[44]
Shebuti Rayana and Leman Akoglu. 2016. ODDS Library: Outlier Detection DataSets. https://shebuti.com/outlier-detection-datasets-odds/
work page 2016
-
[45]
Shebuti Rayana, Wen Zhong, and Leman Akoglu. 2016. Sequential ensemble learning for outlier detection: A bias-variance perspective. In2016 IEEE 16th international conference on data mining (ICDM). IEEE, 1167–1172
work page 2016
- [46]
-
[47]
Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Müller, and Marius Kloft. 2018. Deep One- Class Classification. InInternational Conference on Machine Learning. 4393–4402
work page 2018
-
[48]
David Salinas and Nick Erickson. 2024. TabRepo: A Large Scale Repository of Tabular Model Evaluations and its AutoML Applications. InInternational Conference on Automated Machine Learning. PMLR, 19–1
work page 2024
-
[49]
1992.Model Assisted Survey Sampling
Carl-Erik Särndal, Bengt Swensson, and Jan Wretman. 1992.Model Assisted Survey Sampling. Springer-Verlag. doi:10.1007/978-1-4612-4378-6
-
[50]
Bernhard Schölkopf. 2022. Causality for machine learning. InProbabilistic and causal inference: The works of Judea Pearl. 765–804
work page 2022
-
[51]
Bernhard Schölkopf, Robert C Williamson, Alex Smola, John Shawe-Taylor, and John Platt. 1999. Support Vector Method for Novelty Detection. InAdvances in Neural Information Processing Systems, S. Solla, T. Leen, and K. Müller (Eds.), Vol. 12. MIT Press. https://proceedings.neurips.cc/paper_files/paper/1999/file/ 8725fb777f25776ffa9076e44fcfd776-Paper.pdf
work page 1999
-
[52]
Yuchen Shen, Haomin Wen, and Leman Akoglu. 2025. FoMo-0D: A Foundation Model for Zero-shot Tabular Outlier Detection.Transactions on Machine Learning Research(2025). https://openreview.net/forum?id=XCQzwpR9jE
work page 2025
-
[53]
Tom Shenkar and Lior Wolf. 2022. Anomaly Detection for Tabular Data with Inter- nal Contrastive Learning. InInternational Conference on Learning Representations. https://openreview.net/forum?id=_hszZbt46bT
work page 2022
-
[54]
M Sklar. 1959. Fonctions de répartition à n dimensions et leurs marges. InAnnales de l’ISUP, Vol. 8. 229–231
work page 1959
-
[55]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli
-
[56]
In International conference on machine learning
Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning. pmlr, 2256–2265
-
[57]
Georg Steinbuss and Klemens Böhm. 2021. Benchmarking unsupervised outlier detection with realistic synthetic data.ACM Transactions on Knowledge Discovery from Data (TKDD)15, 4 (2021), 1–20. Under Review 2026, April 2026, Xueying Ding, Simon Klüttermann, Haomin Wen, Yilong Chen, and Leman Akoglu
work page 2021
-
[58]
Hugo Thimonier, Fabrice Popineau, Arpad Rimmel, and Bich-Liên Doan. 2024. Beyond Individual Input for Deep Anomaly Detection on Tabular Data. InPro- ceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Kather- ine Heller, Adrian Weller, Nuria Oliver, Jona...
work page 2024
-
[59]
Kai Ming Ting, Sunil Aryal, and Takashi Washio. 2018. Which Outlier Detector Should I use?. In2018 IEEE International Conference on Data Mining (ICDM). 8–8. doi:10.1109/ICDM.2018.00015
-
[60]
Joaquin Vanschoren. 2018. Meta-Learning: A Survey. InAutomated Machine Learning. https://api.semanticscholar.org/CorpusID:52938664
work page 2018
-
[61]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. 2024. Generalized Out- of-Distribution Detection: A Survey.International Journal of Computer Vision 132, 12 (01 Dec 2024), 5635–5662. https://doi.org/10.1007/s11263-024-02117-4
-
[63]
Jaemin Yoo, Tiancheng Zhao, and Leman Akoglu. 2023. Data Augmentation is a Hyperparameter: Cherry-picked Self-Supervision for Unsupervised Anomaly Detection is Creating the Illusion of Success.Trans. Mach. Learn. Res.2023 (2023)
work page 2023
-
[64]
Xiyuan Zhang, Danielle C. Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, and Bernie Wang
-
[65]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
Mitra: Mixed Synthetic Priors for Enhancing Tabular Foundation Models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
- [66]
-
[67]
Yue Zhao, Ryan Rossi, and Leman Akoglu. 2021. Automatic unsupervised outlier model selection.Advances in Neural Information Processing Systems34 (2021), 4489–4502
work page 2021
-
[68]
Yue Zhao, Sean Zhang, and Leman Akoglu. 2022. Toward unsupervised outlier model selection. In2022 IEEE International Conference on Data Mining (ICDM). IEEE, 773–782. macrOData: New Benchmarks of Thousands of Datasets for Tabular Outlier Detection Under Review 2026, April 2026, Appendix A ADBench Analyses A.1 Summary Statistics Table 3: ADBench datasets su...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.