TS-Haystack: A Multi-Task Retrieval Benchmark for Long-Context Time-Series Reasoning
Pith reviewed 2026-05-15 21:39 UTC · model grok-4.3
The pith
Existing time-series language models lose accuracy as contexts lengthen to a full day, yet an agentic system with classifier tools recovers performance on nine of ten tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
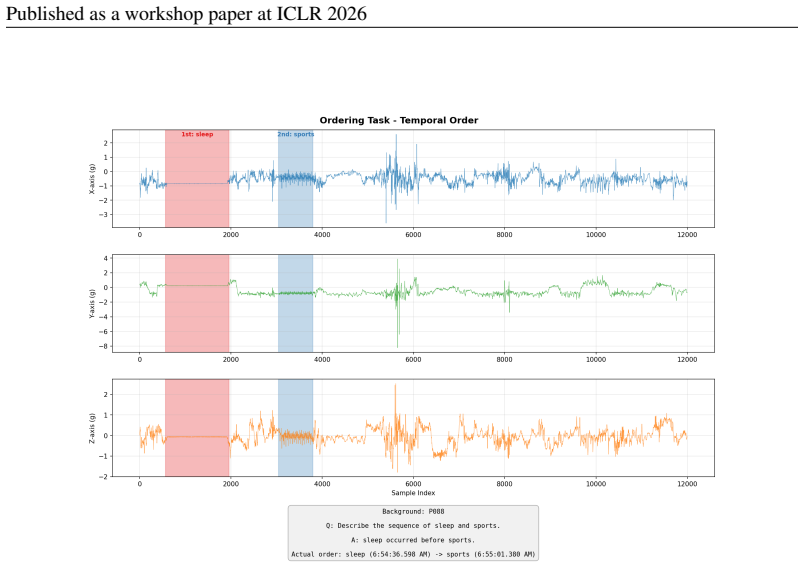
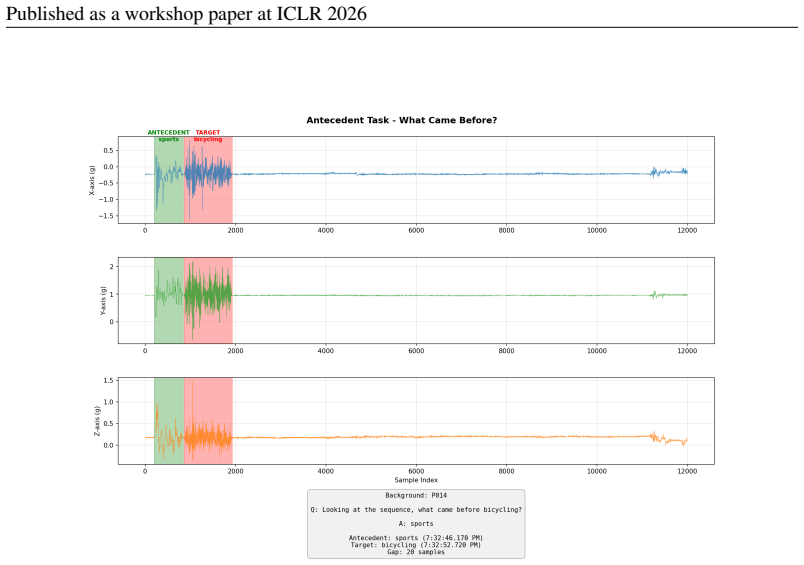
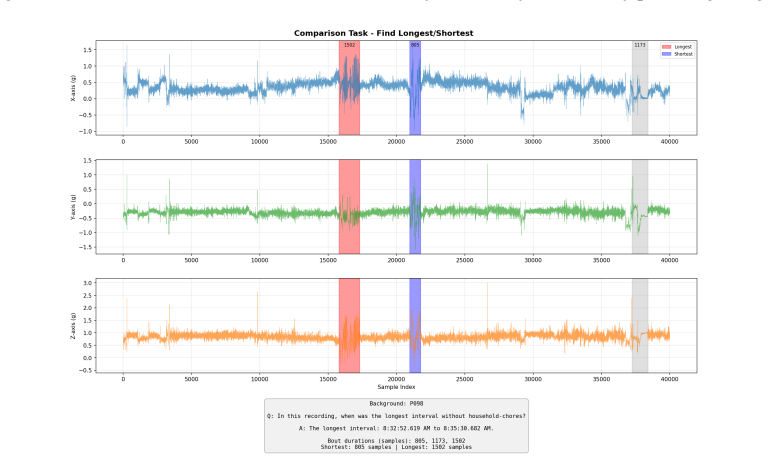
TS-Haystack shows that TSLMs suffer severe long-context degradation: accuracy declines with context length from 100 seconds to 24 hours, direct-tokenization models encounter memory limits beyond 100 seconds on high-rate signals, and time-interval-grounded tasks approach near-zero accuracy; an agentic retrieval framework that employs specialized time-series classifier tools matches or outperforms existing TSLMs on 9 of 10 tasks.
What carries the argument
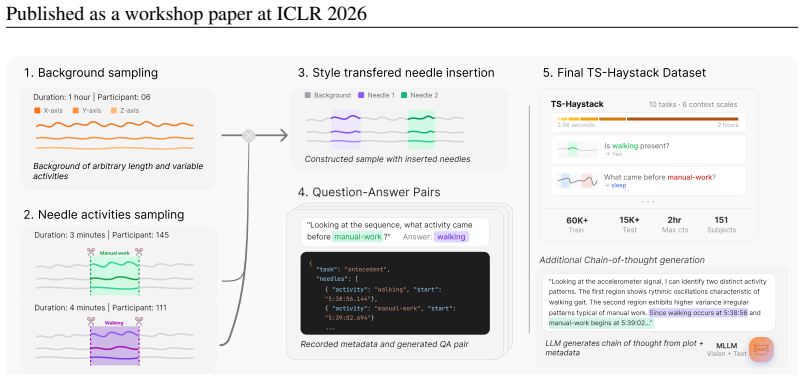
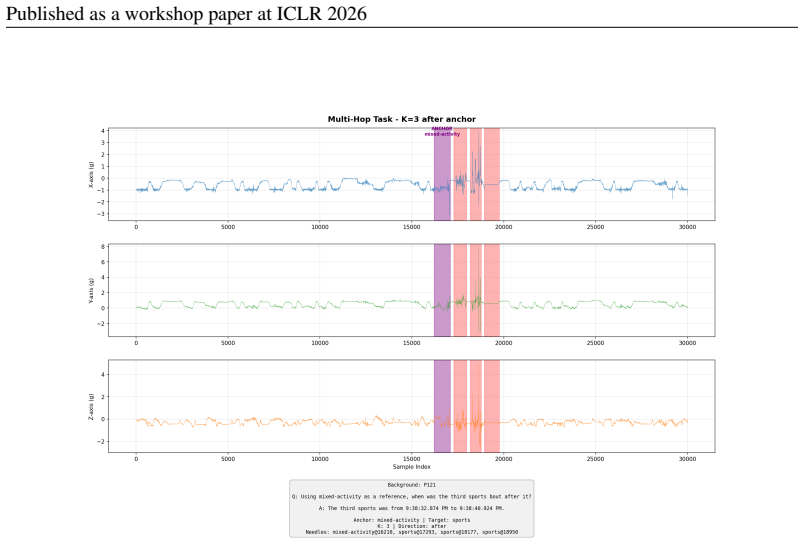
The TS-Haystack benchmark of ten event-grounded QA tasks over variable-length time series, paired with an agentic retrieval framework that invokes specialized time-series classifier tools to locate relevant segments before reasoning.
If this is right
- Direct tokenization of long time series will remain impractical for many applications due to memory exhaustion and accuracy collapse.
- Retrieval-first agentic designs provide a practical path to scale temporal reasoning without loading entire histories.
- Tasks that hinge on exact time intervals or anomaly localization are the most sensitive to context growth.
- Benchmarking must expand beyond short contexts to expose these limits in future TSLM development.
- Tool use focused on time-series classification can substitute for end-to-end long-context modeling in several domains.
Where Pith is reading between the lines
- Continuous monitoring systems in medicine or infrastructure may shift toward retrieval agents rather than monolithic models.
- Training regimes that interleave retrieval and reasoning steps could reduce the need for ever-larger context windows.
- The same length-based degradation may surface in other sequential data types, pointing to a broader architectural pattern.
- Adding tasks with irregular sampling rates or missing values would test whether the current performance gap persists.
Load-bearing premise
The ten tasks capture the essential difficulties of real-world long time-series reasoning and that observed accuracy drops are caused primarily by context length rather than task construction or data traits.
What would settle it
A direct TSLM that maintains high accuracy on the same tasks when context lengths are doubled, or an agentic system that loses its advantage on a fresh collection of long time-series tasks with comparable event density.
Figures







read the original abstract
Time Series Language Models (TSLMs) promise reasoning over real-world temporal data, but their ability to retrieve and reason over long time-series remains largely untested. We introduce TS-Haystack, a multi-domain retrieval benchmark with ten event-grounded question-answering tasks over contexts from 100 seconds to 24 hours, spanning direct retrieval, temporal reasoning, multi-step reasoning, and contextual anomaly detection. Existing TSLMs exhibit severe long-context degradation: accuracy declines with context length, direct-tokenization models run out of memory beyond 100 seconds on high-rate signals, and time-interval-grounded tasks collapse toward near-zero accuracy when increasing the time-series lengths, aligning with existing literature on text and multi-modal long context retrieval. An agentic retrieval framework using specialized time-series classifier tools matches or outperforms SoTA TSLMs on 9 of 10 tasks, highlighting agentic retrieval as a promising approach for long-context TSLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TS-Haystack, a multi-domain retrieval benchmark with ten event-grounded QA tasks over time-series contexts ranging from 100 seconds to 24 hours. It evaluates existing TSLMs on direct retrieval, temporal reasoning, multi-step reasoning, and anomaly detection, reporting severe accuracy degradation with increasing context length, out-of-memory failures for direct-tokenization models beyond 100 seconds on high-rate signals, and near-zero performance on time-interval tasks at longer scales. The authors further present an agentic retrieval framework using specialized time-series classifier tools that matches or outperforms SoTA TSLMs on 9 of 10 tasks.
Significance. If the performance drops can be rigorously attributed to context length rather than task scaling artifacts, the benchmark would usefully document limitations of current TSLMs and motivate agentic retrieval as a practical alternative for long-context time-series reasoning. The work supplies a concrete, multi-task evaluation suite that could serve as a standard testbed, though its impact depends on the strength of the length-isolation controls.
major comments (2)
- [Benchmark construction and experimental setup] The central attribution of accuracy decline to context length (abstract and experimental results) lacks evidence of controls that hold event density, anomaly statistics, or question difficulty fixed while varying context length from 100 s to 24 h. Without such isolation, the observed collapse on time-interval tasks could arise from intrinsic increases in task hardness rather than model limitations, directly undermining the claim that degradation is length-driven.
- [Results section] Reported results supply no error bars, statistical significance tests, or data-exclusion rules, leaving the directional claims only partially verifiable and preventing assessment of whether differences between TSLMs and the agentic framework are reliable.
minor comments (2)
- [§3] Full task definitions, exact question templates, and precise rules for context sampling across lengths should be moved to the main text or a clearly referenced appendix for reproducibility.
- [Notation and task definitions] Notation for time intervals and event grounding is introduced without a consolidated table; a single reference table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and describe the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [Benchmark construction and experimental setup] The central attribution of accuracy decline to context length (abstract and experimental results) lacks evidence of controls that hold event density, anomaly statistics, or question difficulty fixed while varying context length from 100 s to 24 h. Without such isolation, the observed collapse on time-interval tasks could arise from intrinsic increases in task hardness rather than model limitations, directly undermining the claim that degradation is length-driven.
Authors: We agree that rigorous isolation of context length from potential changes in task difficulty is essential. The benchmark construction samples a fixed number of events from the same underlying distributions and pads with background segments drawn from the same source distribution, which was intended to keep event density and anomaly statistics constant; however, we did not explicitly quantify or report difficulty metrics (e.g., question complexity or event-rate statistics) across lengths in the original submission. In the revised manuscript we will add a dedicated subsection detailing these construction choices, report event-density and difficulty statistics for every context length, and include controlled experiments on a subset of tasks in which longer contexts are subsampled to match the event statistics of shorter ones. These additions will allow readers to assess whether the observed degradation is length-driven. revision: yes
-
Referee: [Results section] Reported results supply no error bars, statistical significance tests, or data-exclusion rules, leaving the directional claims only partially verifiable and preventing assessment of whether differences between TSLMs and the agentic framework are reliable.
Authors: We acknowledge that the original results section omitted error bars, statistical tests, and explicit data-exclusion criteria. In the revised version we will recompute all reported accuracies with standard error bars over multiple random seeds or runs, add paired statistical significance tests (e.g., t-tests or Wilcoxon tests) for all model comparisons, and include a clear statement of data-exclusion rules (e.g., filtering criteria for invalid time-series segments or malformed questions). These changes will make the reliability of the directional claims directly verifiable. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivations or fitted parameters
full rationale
The paper introduces the TS-Haystack benchmark and reports direct empirical measurements of TSLM performance across context lengths on ten event-grounded tasks. No mathematical derivations, equations, parameter fittings, or self-citation chains are present that reduce any claim to the paper's own inputs by construction. Accuracy degradation and agentic framework comparisons are presented as observed results from the benchmark rather than quantities defined in terms of prior fitted values or self-referential premises. The evaluation is self-contained against external model baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yifu Cai, Arjun Choudhry, Xing Hu, and Artur Dubrawski
doi: 10.1145/2499621. Yifu Cai, Arjun Choudhry, Xing Hu, and Artur Dubrawski. Timeseriesexam: A time series under- standing exam.arXiv preprint arXiv:2410.14752,
-
[2]
Aaron Grattafiori et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models
URLhttps://arxiv.org/abs/2310.01728. Greg Kamradt. Needle in a haystack - pressure testing LLMs. https://github.com/ gkamradt/LLMTest_NeedleInAHaystack,
work page internal anchor Pith review arXiv
-
[5]
Patrick Langer, Thomas Kaar, Max Rosenblattl, Maxwell A
Patrick Langer et al. OpenTSLM: Time-series language models for reasoning over multivariate medical text- and time-series data.arXiv preprint arXiv:2510.02410,
-
[6]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
6 Published as a workshop paper at ICLR 2026 Hengyi Wang, Haizhou Shi, Shiwei Tan, Weiyi Qin, Wenyuan Wang, Tunyu Zhang, Akshay Namber, Tanuja Yu, and Hao Liu. Multimodal needle in a haystack: Benchmarking long-context capability of multimodal large language models.arXiv preprint arXiv:2406.11230,
-
[8]
Matthew Willetts, Sven Hollowell, Louis Aslett, Chris Holmes, and Aiden Doherty
URLhttps://arxiv.org/abs/2506.20093. Matthew Willetts, Sven Hollowell, Louis Aslett, Chris Holmes, and Aiden Doherty. Statistical machine learning of sleep and physical activity phenotypes from sensor data in 96,220 UK Biobank participants.Scientific Reports, 8(1):7961,
-
[9]
doi: 10.1038/s41598-018-26174-1. A CLASSIFICATIONEXPERIMENTDETAILS A.1 EXPERIMENTALSETUP Model architecture.We use the Flamingo variant of OpenTSLM (Langer et al.,
-
[10]
Random” indicates uniform subsampling to the budget cap; “full
into train (100), validation (25) and test (26) splits at random. We adopt a curriculum learning approach, training sequentially from shorter to longer contexts. For each context length, we use a maximum sample budget: 80,000 training, 15,000 validation, and 15,000 test samples (see Tables 3 and 4 for the relationship between available and sampled data). ...
work page 2026
-
[11]
releases the first open-source foundation models for general-purpose time series analysis, pre-trained on the Time Series Pile, a large multi-domain collection of public time series. Their benchmark evaluates five tasks: forecasting, classification, anomaly detection, and imputation, with emphasis on limited supervision settings. 9 Published as a workshop...
work page 2026
-
[12]
Their TSQA dataset comprises approximately 200k question-answer pairs across diverse domains
is more closely aligned with our objective, unifying forecasting, imputation, anomaly detection, classification, and open-ended reasoning under a question-answering framework. Their TSQA dataset comprises approximately 200k question-answer pairs across diverse domains. However, Time-MQA does not specifically probelong-context retrieval, the ability to loc...
work page 2023
-
[13]
adapts the paradigm to multimodal retrieval, stress- testing models’ ability to locate target sub-images within large visual contexts. To our knowledge, TS-Haystack is the first benchmark to apply the needle-in-a-haystack methodology to continuous time series data, where the challenge is compounded by the absence of discrete token boundaries and the need ...
work page 2024
-
[14]
Chain-of-thought annotations.For each sample, we generate chain-of-thought (CoT) rationales using ChatGPT 4.1 mini (OpenAI, 2023), conditioned on image plots of the accelerometer data along with rich metadata including activity timelines, bout boundaries, and signal statistics. These annotations support training and evaluation of reasoning capabilities be...
work page 2023
-
[15]
Results.The classifier achieves an AUC of 0.499 and 0.490 respectively for different context lengths, close to random chance (0.50). This confirms that our mean-shift normalization combined with cosine blending produces insertions that are statistically undetectable, even to a gradient-boosted ensemble operating on raw signal features. The protocol succes...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.