Recognition: 2 theorem links
· Lean TheoremSCOPE: Structured Prototype-Guided Adaptation for EEG Foundation Models with Limited Labels
Pith reviewed 2026-05-15 21:25 UTC · model grok-4.3
The pith
SCOPE adapts EEG foundation models to new tasks with few labeled subjects by adding cohort-level external supervision and a prototype-conditioned adapter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCOPE first constructs cohort-level external supervision to provide persistent guidance and further derives confidence-aware pseudo-labels to select reliable unlabeled samples for adaptation. Building on the constructed external supervision, SCOPE introduces ProAdapter, a lightweight prototype-conditioned adapter that modulates frozen EFMs to preserve pretrained representations.
What carries the argument
ProAdapter, a lightweight prototype-conditioned adapter that modulates frozen EFMs to preserve pretrained representations while incorporating the constructed external supervision.
Load-bearing premise
Cohort-level external supervision and confidence-aware pseudo-labels can be built reliably enough to block the three failure modes without injecting new biases when labels are scarce.
What would settle it
If SCOPE fails to outperform standard fine-tuning or other adapters on a held-out EEG task using only 5 percent labeled subjects, the central claim would be falsified.
Figures







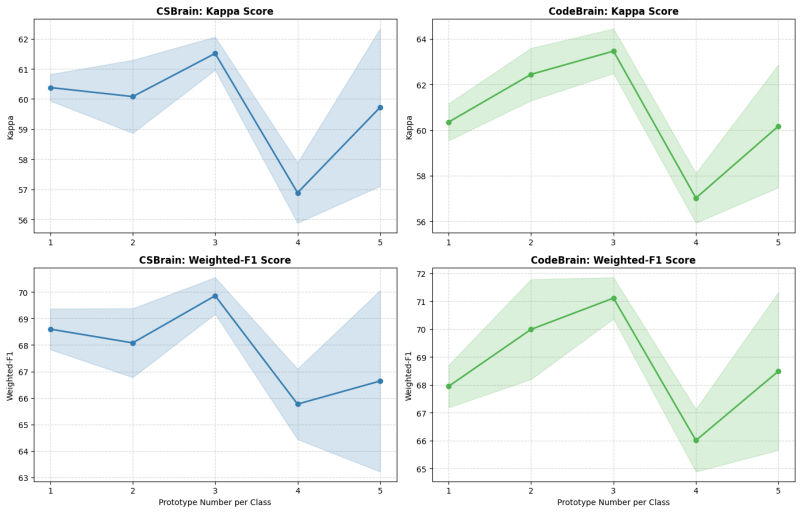
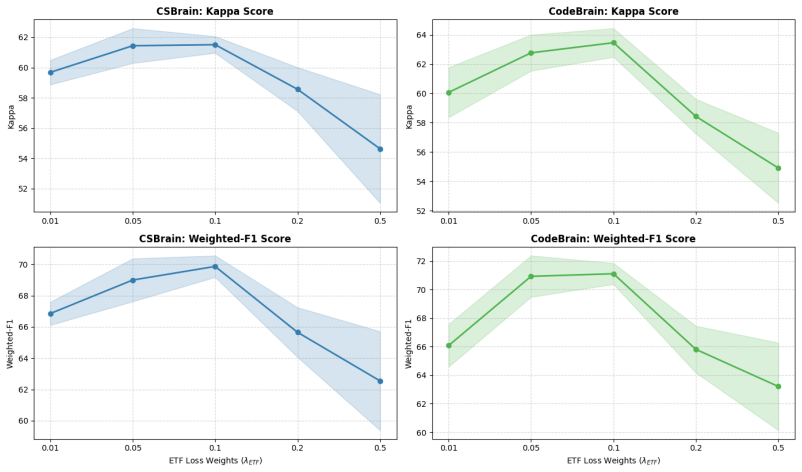


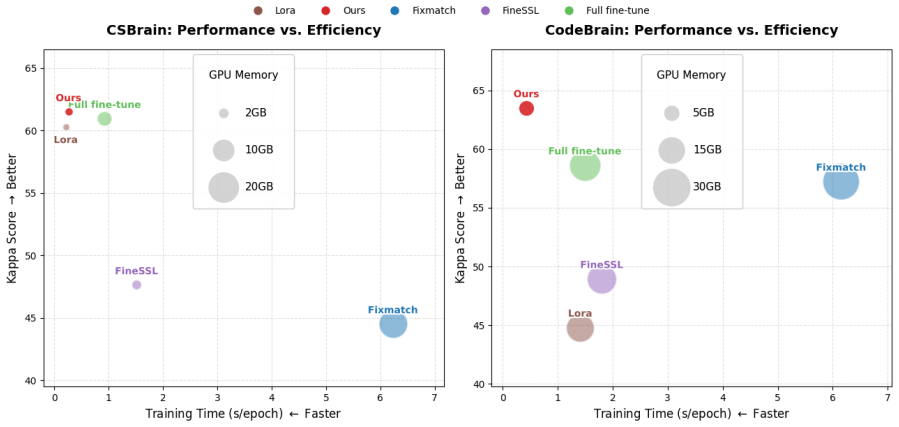


read the original abstract
Electroencephalography (EEG) foundation models (EFMs) have shown strong potential for transferable representation learning, yet their adaptation in realistic settings remains challenging when only a few labeled subjects are available. We show that this challenge stems from a structural mismatch between noisy, limited supervision and the highly plastic parameter space of EFMs, reflected in three key failure modes: overconfident miscalibration, prediction collapse, and representation drift caused by unconstrained parameter updates. To address these challenges, we propose SCOPE, a Structured COnfidence-aware Prototype-guided framework for label-limited EFM adaptation. SCOPE first constructs cohort-level external supervision to provide persistent guidance and further derives confidence-aware pseudo-labels to select reliable unlabeled samples for adaptation. Building on the constructed external supervision, SCOPE introduces ProAdapter, a lightweight prototype-conditioned adapter that modulates frozen EFMs to preserve pretrained representations. Experiments across 50 label-limited adaptation settings, covering 6 EEG tasks, 5 EFM backbones, and 5%-50% training labeled-subject ratios, show that SCOPE consistently achieves strong performance and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SCOPE, a Structured COnfidence-aware Prototype-guided framework for adapting EEG foundation models (EFMs) in label-limited settings. It identifies three failure modes—overconfident miscalibration, prediction collapse, and representation drift arising from the mismatch between noisy limited supervision and plastic EFM parameters—and addresses them via cohort-level external supervision, confidence-aware pseudo-label selection, and a lightweight ProAdapter module that modulates frozen backbones. Experiments across 50 settings (6 EEG tasks, 5 backbones, 5%-50% labeled-subject ratios) claim consistent gains in performance and efficiency.
Significance. If the empirical results and failure-mode mitigation hold under rigorous controls, SCOPE would provide a practical, generalizable recipe for deploying EFMs in realistic low-label regimes common to EEG applications, while preserving pretrained representations. The breadth of the evaluation (50 settings) is a strength if ablations confirm that gains derive from the proposed components rather than dataset artifacts.
major comments (2)
- [§3.2] §3.2 (cohort-level supervision construction): At 5% labeled-subject ratios the external supervision is derived from very few subjects and the model's own predictions; the manuscript does not demonstrate that the confidence threshold is cross-validated on held-out labeled data, leaving open the possibility that systematic errors are reinforced rather than corrected, which directly undermines the claim that the three failure modes are prevented.
- [§4.3] §4.3 (ProAdapter modulation): The prototype-conditioned adapter operates on potentially biased prototypes constructed from the same limited cohort; without an ablation that isolates the effect of prototype quality (e.g., oracle vs. estimated prototypes) at the lowest label ratios, it is unclear whether observed gains reflect genuine mitigation of representation drift or dataset-specific fitting.
minor comments (2)
- [§3.3] The notation and update rule for ProAdapter would benefit from an explicit equation or pseudocode block to clarify how the prototype conditioning is injected into the frozen backbone.
- [Figure 2] Figure 2 (overview diagram) could more clearly distinguish the flow of cohort supervision from the pseudo-label selection step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of robustness in low-label regimes, and we have revised the paper to address them directly by adding the requested validation and ablation analyses. Below we respond point by point.
read point-by-point responses
-
Referee: [§3.2] §3.2 (cohort-level supervision construction): At 5% labeled-subject ratios the external supervision is derived from very few subjects and the model's own predictions; the manuscript does not demonstrate that the confidence threshold is cross-validated on held-out labeled data, leaving open the possibility that systematic errors are reinforced rather than corrected, which directly undermines the claim that the three failure modes are prevented.
Authors: We agree that explicit validation of the confidence threshold is necessary to rule out error reinforcement. In the revised manuscript we have added a cross-validation procedure that selects the threshold on a small held-out subset of the available labeled subjects at each ratio (including 5%). We further report pseudo-label accuracy and calibration metrics before versus after selection, showing that the cohort-level aggregation and threshold reduce overconfident miscalibration rather than amplifying it. While the absolute number of subjects remains small at 5%, the multi-task results across six EEG tasks indicate that the external supervision still provides net stabilization of the three failure modes. revision: yes
-
Referee: [§4.3] §4.3 (ProAdapter modulation): The prototype-conditioned adapter operates on potentially biased prototypes constructed from the same limited cohort; without an ablation that isolates the effect of prototype quality (e.g., oracle vs. estimated prototypes) at the lowest label ratios, it is unclear whether observed gains reflect genuine mitigation of representation drift or dataset-specific fitting.
Authors: We acknowledge the value of isolating prototype quality. The revised manuscript now includes an oracle-versus-estimated prototype ablation at the 5% and 10% label ratios. Oracle prototypes (computed from the full labeled set) yield additional gains, yet the estimated prototypes still deliver consistent improvements over all baselines in both performance and representation stability metrics. These results indicate that ProAdapter mitigates representation drift even when prototypes are constructed from the limited cohort, rather than merely fitting dataset artifacts. revision: yes
Circularity Check
No significant circularity; method combines existing components with empirical validation
full rationale
The paper introduces SCOPE as a framework that constructs cohort-level supervision and confidence-aware pseudo-labels, then applies a prototype-conditioned adapter (ProAdapter) to modulate frozen EFMs. No equations, derivations, or parameter-fitting steps are described that reduce predictions or results to the inputs by construction. The approach reuses standard ideas (prototypes, pseudo-labeling, adapters) in a new combination for EEG adaptation, with performance claims resting on experiments across 50 settings rather than self-referential definitions or self-citation chains. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ProAdapter
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 3.1 ... simplex equiangular tight frame condition w̃_k^T w̃_k' = -1/(K-1)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_ETF = ||W̃^T W̃ - (K/(K-1)I - 1/(K-1)11^T)||_F^2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aasm scoring manual updates for 2017 (version 2.4),
Richard B Berry, Rita Brooks, Charlene Gamaldo, Susan M Harding, Robin M Lloyd, Stuart F Quan, Matthew T Troester, and Bradley V Vaughn. Aasm scoring manual updates for 2017 (version 2.4),
work page 2017
-
[2]
Zhisheng Chen, Yingwei Zhang, Qizhen Lan, Tianyu Liu, Huacan Wang, Yi Ding, Ziyu Jia, Ronghao Chen, Kun Wang, and Xinliang Zhou. Uni-ntfm: A unified foundation model for eeg signal representation learning.arXiv preprint arXiv:2509.24222,
-
[3]
Maeeg: Masked auto-encoder for eeg representation learning
Hsiang-Yun Sherry Chien, Hanlin Goh, Christopher Michael Sandino, and Joseph Yitan Cheng. Maeeg: Masked auto-encoder for eeg representation learning. InNeurIPS 2022 Workshop on Learning from Time Series for Health,
work page 2022
-
[4]
Subject-aware contrastive learning for eeg foundation models
Antonis Karantonis, Konstantinos Barmpas, Dimitrios Adamos, Nikolaos Laskaris, Stefanos Zafeiriou, and Yannis Panagakis. Subject-aware contrastive learning for eeg foundation models. InNeurIPS 2025 Workshop on Learning from Time Series for Health,
work page 2025
-
[5]
Na Lee, Konstantinos Barmpas, Yannis Panagakis, Dimitrios Adamos, Nikolaos Laskaris, and Stefanos Zafeiriou. Are large brainwave foundation models capable yet? insights from fine-tuning.arXiv preprint arXiv:2507.01196,
-
[6]
Echo: Toward contextual seq2seq paradigms in large eeg models.arXiv preprint arXiv:2509.22556,
Chenyu Liu, Yuqiu Deng, Tianyu Liu, Jinan Zhou, Xinliang Zhou, Ziyu Jia, and Yi Ding. Echo: Toward contextual seq2seq paradigms in large eeg models.arXiv preprint arXiv:2509.22556,
-
[7]
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning.Advances in Neural Information Processing Systems, 35:1950–1965,
work page 1950
-
[8]
UniMind: Unleashing the Power of LLMs for Unified Multi-Task Brain Decoding
Weiheng Lu, Chunfeng Song, Jiamin Wu, Pengyu Zhu, Yuchen Zhou, Weijian Mai, Qihao Zheng, and Wanli Ouyang. Unimind: Unleashing the power of llms for unified multi-task brain decoding.arXiv preprint arXiv:2506.18962,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
St-usleepnet: A spatial-temporal coupling prominence network for multi-channel sleep staging
Jingying Ma, Qika Lin, Ziyu Jia, and Mengling Feng. St-usleepnet: A spatial-temporal coupling prominence network for multi-channel sleep staging. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 4182–4190, 2025a. Jingying Ma, Jinwei Wang, Lanlan Lu, Yexiang Sun, Mengling Feng, Feifei Zhang, Peng Shen, Zhi...
-
[10]
URLhttps://doi.org/10.18653/v1/2021.acl-long.47
doi: 10.18653/V1/2021.ACL-LONG.47. URLhttps://doi.org/10.18653/v1/2021.acl-long.47. Navid Mohammadi Foumani, Geoffrey Mackellar, Soheila Ghane, Saad Irtza, Nam Nguyen, and Mahsa Salehi. Eeg2rep: enhancing self-supervised eeg representation through informative masked inputs. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mi...
-
[11]
Cbramod: A criss-cross brain foundation model for eeg decoding
Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Haiteng Jiang, Shijian Li, Tao Li, and Gang Pan. Cbramod: A criss-cross brain foundation model for eeg decoding. InThe Thirteenth International Conference on Learning Representations, 2025a. Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Shijian Li, and Gang Pan. Eegmamba: An eeg foundation model with...
-
[12]
Benchmarking ERP Analysis: Manual Features, Deep Learning, and Foundation Models
Yihe Wang, Zhiqiao Kang, Bohan Chen, Yu Zhang, and Xiang Zhang. Benchmarking erp analysis: Manual features, deep learning, and foundation models.arXiv preprint arXiv:2601.00573, 2026b. Weining Weng, Yang Gu, Shuai Guo, Yuan Ma, Zhaohua Yang, Yuchen Liu, and Yiqiang Chen. Self-supervised learning for electroencephalogram: A systematic survey.ACM Computing ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yucheng Xing, Ling Huang, Jingying Ma, Ruping Hong, Jiangdong Qiu, Pei Liu, Kai He, Huazhu Fu, and Mengling Feng. Dpsurv: Dual-prototype evidential fusion for uncertainty-aware and interpretable whole-slide image survival prediction.arXiv preprint arXiv:2510.00053,
-
[14]
Billion-scale semi-supervised learning for image classification
15 I Zeki Yalniz, Hervé Jégou, Kan Chen, Manohar Paluri, and Dhruv Mahajan. Billion-scale semi-supervised learning for image classification.arXiv preprint arXiv:1905.00546,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[15]
Shihao Yang, Xiying Huang, Danilo Bernardo, Jun-En Ding, Andrew Michael, Jingmei Yang, Patrick Kwan, Ashish Raj, and Feng Liu. Foundation and large-scale ai models in neuroscience: A comprehensive review.arXiv preprint arXiv:2510.16658,
-
[16]
Zhizhang Yuan, Fanqi Shen, Meng Li, Yuguo Yu, Chenhao Tan, and Yang Yang. Brainwave: A brain signal foundation model for clinical applications.arXiv preprint arXiv:2402.10251,
-
[17]
Pan Zhang, Bo Zhang, Ting Zhang, Dong Chen, Yong Wang, and Fang Wen. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12414–12424, 2021b. Ping Zhang, Zheda Mai, Quang-Huy Nguyen, and Wei-Lun Chao. Revisitin...
-
[18]
Songchi Zhou, Ge Song, Haoqi Sun, Deyun Zhang, Yue Leng, M Brandon Westover, and Shenda Hong. Continuous sleep depth index annotation with deep learning yields novel digital biomarkers for sleep health.npj Digital Medicine, 8(1):203, 2025a. Xinliang Zhou, Chenyu Liu, Zhisheng Chen, Kun Wang, Yi Ding, Ziyu Jia, and Qingsong Wen. Brain foundation models: A ...
-
[19]
brings a multi-channel self-supervised learning framework for iEEG Signals. Besides, Brant-X [Zhang et al., 2024] and Brainwave [Yuan et al., 2024] attempt to unify the representation of iEEG and other medical time series in deep learning. These models are widely used for the detection of certain diseases, such as seizures [Tu et al., 2024, Shoeibi et al....
work page 2024
-
[20]
brings a new direction, they design a neural-language connector was designed to bridge the modality gap between neural signals and large language models. Neuro-GPT Cui et al. [2024], ECHO Liu et al. [2025], and Uni-NTFM [Chen et al., 2025] improved the common backbone transformer of LLM models to better integrate with the characteristics of EEG data. Self...
work page 2024
-
[21]
have improved the coupling methods between EEG and different modalities. B.2 Semi-supervised Learning Semi-supervised learning (SSL) aims to leverage abundant unlabeled data together with limited labeled samples, and has become a promising paradigm for learning under data-scarce settings Zhu [2005], Van Engelen and Hoos [2020]. In the deep learning era, a...
work page 2005
-
[22]
are representative approaches. These methods typically rely on lightweight backbone models and exploit consistency regularization and pseudo-labeling to achieve strong empirical performance. With the emergence of foundation models, SSL faces new challenges. Foundation models usually contain a large number of parameters, making full fine-tuning computation...
work page 2025
-
[23]
proposed further improvements for the interpretability of deep learning models on EEG images. In addition, prototype learning usually requires the assistance of rules to better train on EEG data [Al-Hussaini et al., 2019, Zhou et al., 2024]. Niknazar and Mednick
work page 2019
-
[24]
built an EEG expert system to assist with prototype learning. Overall, prototype-based learning provides a structured way to capture essential class-level information in representation space, offering an intuitive mechanism for relating inputs to semantic targets. B.4 Dempster–Shafer theory Decision making under uncertainty remains a fundamental challenge...
work page 1992
-
[25]
To ensure a realistic assessment of cross-subject generalization, all datasets are evaluated under strict subject-wise splits, where labeled and unlabeled training subjects, validation subjects, and test subjects are mutually exclusive. C.1 Sleep Staging The subset1 of ISRUC-Sleep dataset [Khalighi et al., 2016] is used for the sleep staging task. It cons...
work page 2016
-
[26]
Each hidden layer is followed by an ELU activation and dropout for regularization. C.3 Workload Assessment Mental Arithmetic The Mental Arithmetic dataset [Zyma et al., 2019] supports the task of mental stress detection using EEG signals. It contains recordings from 36 subjects under two distinct cognitive conditions: resting and active engagement in ment...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.