Recognition: 2 theorem links
· Lean TheoremEmergent Manifold Separability during Reasoning in Large Language Models
Pith reviewed 2026-05-15 20:10 UTC · model grok-4.3
The pith
Reasoning in large language models produces a transient geometric pulse that untangles concept manifolds into linearly separable subspaces immediately before each computational step and then rapidly compresses them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
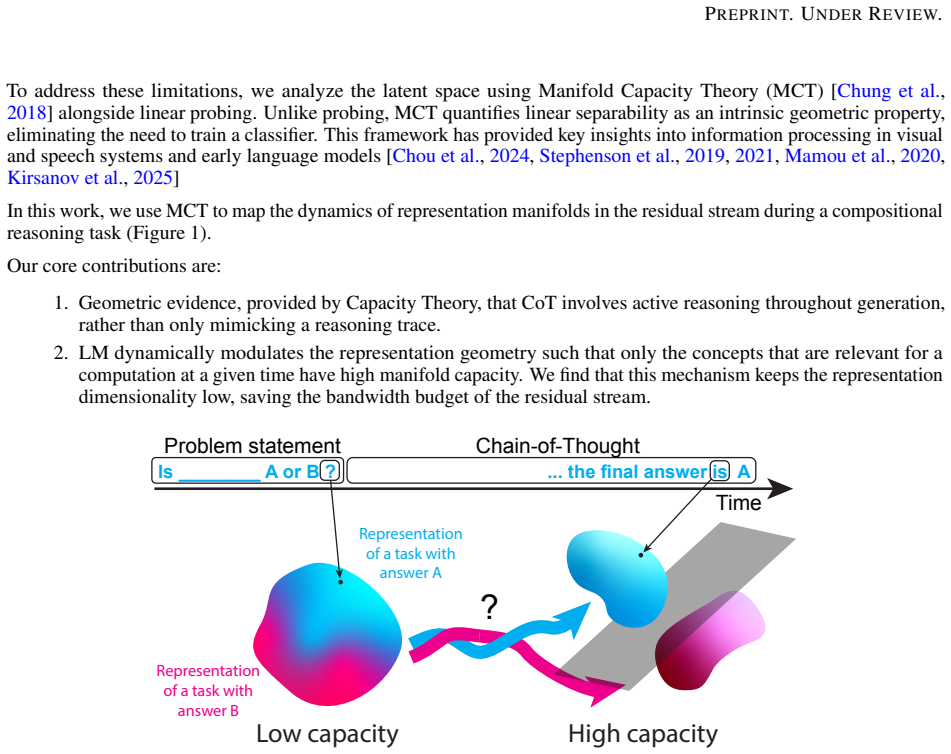
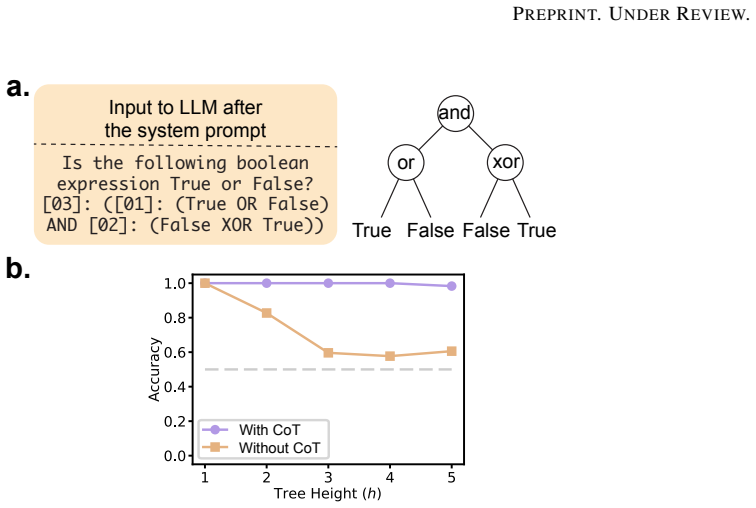
On two compositional reasoning tasks and across several open-weight models, the latent representations exhibit a transient geometric pulse: concept manifolds are untangled into linearly separable subspaces immediately prior to each computational step and rapidly compressed thereafter. This behavior diverges from standard linear probe accuracy, which remains high long after computation, indicating a distinction between information that is merely retrievable and information that is geometrically prepared for processing. The authors interpret the pattern as Dynamic Manifold Management, a mechanism in which the model dynamically modulates representational capacity to optimize residual-streamband
What carries the argument
Manifold Capacity Theory (MCT), which quantifies the linear separability of latent representations without requiring trained probes.
If this is right
- The model uses a temporary increase in representational capacity to prepare information for processing at precise moments in the chain.
- Geometric compression after each step helps maintain bandwidth efficiency in the residual stream across multiple reasoning operations.
- Information remains linearly decodable after compression, yet the model no longer treats it as immediately processable.
- This dynamic occurs consistently on both synthetic Boolean trees and natural-language eligibility tasks.
Where Pith is reading between the lines
- Similar pulses might appear in other sequential decision tasks such as planning or multi-step arithmetic.
- Architectural modifications that strengthen or weaken this pulse could be tested as a way to improve or degrade reasoning performance.
- The distinction between retrievable and geometrically prepared representations may help explain why some prompts succeed or fail at eliciting correct chains of thought.
Load-bearing premise
The observed changes in manifold geometry are caused by the specific computational demands of reasoning rather than by token generation, layer normalization, or other general architectural operations.
What would settle it
If the same transient pulse of linear separability appears at comparable rates during non-reasoning token generation tasks or random sequences that lack compositional structure, the claim that the pulse is tied to reasoning steps would be falsified.
Figures




read the original abstract
Chain-of-Thought (CoT) prompting significantly improves reasoning in Large Language Models, yet the temporal dynamics of the underlying representation geometry remain poorly understood. We investigate these dynamics by applying Manifold Capacity Theory (MCT) to two compositional reasoning tasks: a controlled Boolean logic tree that supports deep mechanistic analysis, and a natural-language eligibility task in which the model has to extract attributes from prose, compare them to thresholds, and compose the local decisions through a fixed evaluation tree. MCT lets us quantify the linear separability of latent representations without the confounding factors of probe training. On both tasks, and across several open-weight models, reasoning manifests as a transient geometric pulse: concept manifolds are untangled into linearly separable subspaces immediately prior to computation and rapidly compressed thereafter. This behavior diverges from standard linear probe accuracy, which remains high long after computation, suggesting a fundamental distinction between information that is merely retrievable and information that is geometrically prepared for processing. We interpret this phenomenon as Dynamic Manifold Management, a mechanism where the model dynamically modulates representational capacity to optimize the bandwidth of the residual stream throughout the reasoning chain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Chain-of-Thought reasoning in LLMs produces a transient geometric pulse, measured via Manifold Capacity Theory (MCT), in which concept manifolds become linearly separable immediately prior to computation and are then rapidly compressed; this trajectory is observed on a Boolean logic tree and a natural-language eligibility task across open-weight models and diverges from the sustained high accuracy of linear probes, which the authors interpret as evidence for Dynamic Manifold Management that optimizes residual-stream bandwidth.
Significance. If the reported pulse is shown to be reasoning-specific rather than a generic generation artifact, the work would supply a geometric account of why CoT improves performance and would distinguish information that is merely retrievable from information that is geometrically prepared for processing. The use of MCT to obtain a probe-independent separability metric is a methodological strength that avoids training-related confounds.
major comments (2)
- [Experimental setup and results] The central claim that the separability pulse is specifically tied to the computational steps of reasoning (rather than autoregressive token generation or layer-wise updates) requires matched-length non-reasoning control sequences and position-matched baselines; the experimental description supplies no indication of such controls, leaving open the possibility that the observed MCT trajectory is a generic property of any sufficiently long generation sequence.
- [Discussion and interpretation] The interpretive label 'Dynamic Manifold Management' is not derived from fitted MCT parameters or self-referential equations; the manuscript must clarify how the pulse is quantitatively distinguished from alternative explanations such as residual-stream normalization or token-position effects before the mechanism can be treated as a distinct phenomenon.
minor comments (1)
- [Abstract and results] The abstract states that the behavior 'diverges from standard linear probe accuracy' but supplies no quantitative comparison (timing offset, magnitude difference, or statistical test); this detail should be added to the results section with error bars.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important controls and interpretive clarifications needed to strengthen the claims. We address each point below and will revise the manuscript to incorporate the suggested experiments and distinctions.
read point-by-point responses
-
Referee: [Experimental setup and results] The central claim that the separability pulse is specifically tied to the computational steps of reasoning (rather than autoregressive token generation or layer-wise updates) requires matched-length non-reasoning control sequences and position-matched baselines; the experimental description supplies no indication of such controls, leaving open the possibility that the observed MCT trajectory is a generic property of any sufficiently long generation sequence.
Authors: We agree that matched controls are essential to establish specificity. While the original experiments align the pulse timing with explicit computational steps in the Boolean logic tree (e.g., at layers where AND/OR operations occur) and show divergence from sustained probe accuracy, we did not include explicit non-reasoning controls of matched length. In the revision we will add: (i) matched-length non-reasoning sequences such as repetitive token generation and simple copying tasks, and (ii) position-matched baselines by extracting MCT metrics at equivalent token positions in non-reasoning prompts. These controls will be reported alongside the existing results to isolate reasoning-specific effects. revision: yes
-
Referee: [Discussion and interpretation] The interpretive label 'Dynamic Manifold Management' is not derived from fitted MCT parameters or self-referential equations; the manuscript must clarify how the pulse is quantitatively distinguished from alternative explanations such as residual-stream normalization or token-position effects before the mechanism can be treated as a distinct phenomenon.
Authors: We acknowledge that 'Dynamic Manifold Management' is a descriptive label rather than a formally derived model. In the revised discussion we will: (i) report MCT separability metrics computed before and after explicit residual-stream normalization to rule out normalization artifacts, (ii) include position-controlled analyses by shuffling token order or comparing across fixed positions in sequences of varying length, and (iii) demonstrate that pulse onset aligns with the timing of specific computational operations in the reasoning tree (rather than uniform layer-wise updates). These quantitative comparisons will be added to distinguish the phenomenon from the listed alternatives. revision: yes
Circularity Check
No significant circularity; central claim is empirical measurement
full rationale
The paper applies Manifold Capacity Theory (MCT) as an external tool to quantify linear separability of latent representations on two reasoning tasks, reporting an observed transient pulse in manifold geometry as a direct empirical result across models. The interpretive label 'Dynamic Manifold Management' is introduced post-hoc to describe the measured behavior and does not appear as a fitted parameter, self-referential equation, or quantity derived by construction from the inputs. No load-bearing steps in the provided abstract or described chain reduce to self-citation, ansatz smuggling, or renaming of known results; the derivation remains self-contained as an observation rather than a tautological prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manifold Capacity Theory quantifies linear separability of latent representations without confounding effects from probe training
invented entities (1)
-
Dynamic Manifold Management
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
reasoning manifests as a transient geometric pulse: concept manifolds are untangled into linearly separable subspaces immediately prior to computation and rapidly compressed thereafter
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Manifold Capacity Theory (MCT) ... quantifies the linear separability of latent representations without the confounding factors of probe training
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anum Afzal, Florian Matthes, Gal Chechik, and Yftah Ziser. Knowing before saying: Llm representations encode information about chain-of-thought success before completion.arXiv preprint arXiv:2505.24362,
-
[2]
The internal state of an llm knows when it’s lying.arXiv preprint arXiv:2304.13734,
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying.arXiv preprint arXiv:2304.13734,
-
[3]
Discovering Latent Knowledge in Language Models Without Supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.arXiv preprint arXiv:2212.03827,
work page internal anchor Pith review arXiv
-
[4]
Unveiling the key factors for distilling chain-of-thought reasoning
Xinghao Chen, Zhijing Sun, Guo Wenjin, Miaoran Zhang, Yanjun Chen, Yirong Sun, Hui Su, Yijie Pan, Dietrich Klakow, Wenjie Li, and Xiaoyu Shen. Unveiling the key factors for distilling chain-of-thought reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 15094–15119. Association for Computational Linguistics, July
work page 2025
-
[5]
doi: 10.18653/v1/2025.findings-acl.782. Chi-Ning Chou, Royoung Kim, Luke A Arend, Yao-Yuan Yang, Brett D Mensh, Won Mok Shim, Matthew G Perich, and SueYeon Chung. Geometry linked to untangling efficiency reveals structure and computation in neural populations. bioRxiv, pages 2024–02,
-
[6]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.arXiv preprint arXiv:2209.10652,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Language models represent space and time.arXiv preprint arXiv:2310.02207,
Wes Gurnee and Max Tegmark. Language models represent space and time.arXiv preprint arXiv:2310.02207,
-
[8]
Designing and interpreting probes with control tasks.arXiv preprint arXiv:1909.03368,
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks.arXiv preprint arXiv:1909.03368,
-
[9]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long and Short Papers), pages 4129–4138. Association for Computational Linguistics, June
work page 2019
-
[10]
Artem Kirsanov, Chi-Ning Chou, Kyunghyun Cho, and SueYeon Chung. The geometry of prompting: Unveiling distinct mechanisms of task adaptation in language models.arXiv preprint arXiv:2502.08009,
-
[11]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil˙e Lukoši¯ut˙e, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Max...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Alexander H. Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouaul, et al. Ministral 3.arXiv preprint arXiv:2601.08584,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representa- tions of true/false datasets.arXiv preprint arXiv:2310.06824,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The intrinsic dimension of images and its impact on learning.arXiv preprint arXiv:2104.08894,
Phillip Pope, Chen Zhu, Ahmed Abdelkader, Micah Goldblum, and Tom Goldstein. The intrinsic dimension of images and its impact on learning.arXiv preprint arXiv:2104.08894,
-
[16]
Cory Stephenson, Suchismita Padhy, Abhinav Ganesh, Yue Hui, Hanlin Tang, and SueYeon Chung. On the geometry of generalization and memorization in deep neural networks.arXiv preprint arXiv:2105.14602,
-
[17]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting.arXiv preprint arXiv:2305.04388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
No Training Required: Exploring Random Encoders for Sentence Classification
John Wieting and Douwe Kiela. No training required: Exploring random encoders for sentence classification.arXiv preprint arXiv:1901.10444,
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[19]
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Reasoning models know when they’re right: Probing hidden states for self-verification.arXiv preprint arXiv:2504.05419,
-
[20]
12 PREPRINT. UNDERREVIEW. Kelly W Zhang and Samuel R Bowman. Language modeling teaches you more syntax than translation does: Lessons learned through auxiliary task analysis.arXiv preprint arXiv:1809.10040,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.