Recognition: 2 theorem links
· Lean TheoremA novel gauge-equivariant neural-network architecture for preconditioners in lattice QCD
Pith reviewed 2026-05-15 18:59 UTC · model grok-4.3
The pith
A gauge-equivariant neural network preconditions the Dirac equation in lattice QCD to mitigate critical slowing down and transfers directly to unseen gauge configurations without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a novel gauge-equivariant neural-network architecture for preconditioning the Dirac equation in the regime where critical slowing down occurs. We study the behavior of this preconditioner as a function of topological charge and lattice volume and show that it mitigates critical slowing down. We also show that this preconditioner transfers to unseen gauge configurations without any retraining, therefore enabling applications not possible with competing methods.
What carries the argument
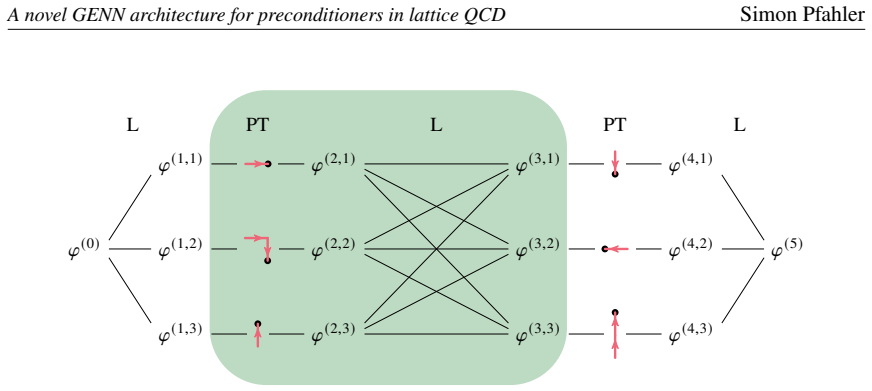
A gauge-equivariant neural-network architecture trained to output a preconditioner for the Dirac operator while preserving gauge symmetry.
If this is right
- The preconditioner reduces the number of solver iterations required in the critical-slowing regime.
- The reduction in iterations persists across changes in topological charge.
- The reduction in iterations persists as lattice volume is increased.
- The same trained network can be applied to new gauge fields without retraining.
Where Pith is reading between the lines
- Similar gauge-equivariant networks could be trained once and reused across entire ensembles, lowering the cost of generating large statistics.
- The transferability suggests that the network captures gauge-field features that are largely independent of the specific Monte Carlo sample.
- The architecture may extend to preconditioning other fermion operators or to theories with different gauge groups.
Load-bearing premise
The neural network can be trained once to produce a preconditioner that stays gauge-equivariant and effective when applied to gauge configurations and lattice parameters different from the training set.
What would settle it
On previously unseen gauge configurations the number of iterations needed to solve the Dirac equation with the neural-network preconditioner equals or exceeds the iteration count obtained with standard methods, or the iteration count grows with lattice volume at the same rate as without the preconditioner.
Figures




read the original abstract
Lattice QCD simulations are computationally expensive, with the solution of the Dirac equation being the major computational bottleneck of many calculations. We introduce a novel gauge-equivariant neural-network architecture for preconditioning the Dirac equation in the regime where critical slowing down occurs. We study the behavior of this preconditioner as a function of topological charge and lattice volume and show that it mitigates critical slowing down. We also show that this preconditioner transfers to unseen gauge configurations without any retraining, therefore enabling applications not possible with competing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a novel gauge-equivariant neural-network architecture for preconditioning the Dirac equation in lattice QCD simulations, focusing on the critical slowing down regime. It reports studies of the preconditioner's behavior as a function of topological charge and lattice volume, claiming mitigation of critical slowing down, and demonstrates that the preconditioner transfers to unseen gauge configurations without retraining.
Significance. If the central claims are substantiated with detailed metrics and verification, the work could represent a meaningful advance in lattice QCD by enabling more efficient Dirac solves across topological sectors and volumes, with the gauge-equivariant design potentially offering advantages over non-equivariant machine-learning approaches in terms of generalization.
major comments (3)
- [Abstract and Results] The abstract and results sections claim transfer to unseen configurations without retraining, but provide no explicit description of how gauge equivariance is enforced in the network layers (e.g., via link-variable convolutions or parallel transports) or verified post-training on gauge-transformed inputs; this is load-bearing for the generalization claim.
- [Results] No quantitative performance metrics are reported for the preconditioned solver (e.g., iteration counts, effective condition numbers of M^{-1}D, or scaling with volume), nor are direct comparisons provided to standard preconditioners such as even-odd or Schwarz methods; without these, the mitigation of critical slowing down cannot be assessed.
- [Methods] The training procedure and loss function are not detailed, including whether any term explicitly penalizes equivariance violations; this leaves open the possibility that reported transfer success is an artifact of the training ensemble rather than a structural property of the architecture.
minor comments (2)
- [Notation] Clarify the precise definition of the preconditioner operator M and its relation to the Dirac operator D, including any approximation or inversion steps.
- [Figures] Ensure all figures include error bars or statistical uncertainties on performance metrics across topological sectors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and add the requested details.
read point-by-point responses
-
Referee: [Abstract and Results] The abstract and results sections claim transfer to unseen configurations without retraining, but provide no explicit description of how gauge equivariance is enforced in the network layers (e.g., via link-variable convolutions or parallel transports) or verified post-training on gauge-transformed inputs; this is load-bearing for the generalization claim.
Authors: We agree the description of gauge-equivariance enforcement was too brief. The architecture uses link-variable convolutions combined with parallel transport operations on the gauge links to ensure exact equivariance by construction. In the revised manuscript we will add an explicit subsection in Methods detailing these operations and include a verification experiment applying random gauge transformations to test inputs and confirming output invariance. revision: yes
-
Referee: [Results] No quantitative performance metrics are reported for the preconditioned solver (e.g., iteration counts, effective condition numbers of M^{-1}D, or scaling with volume), nor are direct comparisons provided to standard preconditioners such as even-odd or Schwarz methods; without these, the mitigation of critical slowing down cannot be assessed.
Authors: The original submission emphasized qualitative behavior and transferability. We will add quantitative results in the revised version, including tables of average iteration counts, effective condition numbers of the preconditioned operator, and volume scaling, together with direct comparisons against even-odd and Schwarz preconditioners on the same ensembles. revision: yes
-
Referee: [Methods] The training procedure and loss function are not detailed, including whether any term explicitly penalizes equivariance violations; this leaves open the possibility that reported transfer success is an artifact of the training ensemble rather than a structural property of the architecture.
Authors: We will expand the Methods section to fully specify the training data, optimizer, batch size, and loss function. Because equivariance is enforced structurally by the network layers, no explicit penalty term for equivariance violation is used; we will state this clearly and provide the exact loss expression to remove any ambiguity. revision: yes
Circularity Check
No circularity: empirical validation of new architecture
full rationale
The paper introduces a novel gauge-equivariant NN architecture for Dirac preconditioning and validates it through direct numerical experiments on lattice QCD ensembles. Claims about mitigating critical slowing down, dependence on topological charge and volume, and transfer to unseen configurations without retraining are supported by performance measurements on held-out data rather than any derivation that reduces to fitted inputs or self-citations. No equations or steps in the provided text exhibit self-definition, fitted-input renaming, or load-bearing self-citation chains; the architecture's equivariance is a stated design choice tested empirically.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a novel gauge-equivariant neural-network architecture for preconditioning the Dirac equation... parallel-transport operator T_p ... filtered cost function C_N = ||M D u_N - u_N||^2
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The defining characteristic of a gauge-equivariant neural network is that its action commutes with gauge transformations... hops H_μ
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Brannick, R.C. Brower, M.A. Clark, J.C. Osborn and C. Rebbi,Adaptive Multigrid Algorithm for Lattice QCD,Physical Review Letters100(2008) 041601
work page 2008
-
[2]
Adaptive multigrid algorithm for the lattice Wilson-Dirac operator
R. Babich, J. Brannick, R.C. Brower, M.A. Clark, T.A. Manteuffel, S.F. McCormick et al., Adaptive multigrid algorithm for the lattice Wilson-Dirac operator,Physical Review Letters 105(2010) 201602 [1005.3043]. 9 A novel GENN architecture for preconditioners in lattice QCDSimon Pfahler
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
A. Frommer, K. Kahl, S. Krieg, B. Leder and M. Rottmann,Adaptive Aggregation-Based Domain Decomposition Multigrid for the Lattice Wilson–Dirac Operator,SIAM Journal on Scientific Computing36(2014) A1581
work page 2014
- [4]
-
[5]
G. Kanwar, M.S. Albergo, D. Boyda, K. Cranmer, D.C. Hackett, S. Racanière et al., Equivariant Flow-Based Sampling for Lattice Gauge Theory,Physical Review Letters125 (2020) 121601
work page 2020
-
[6]
M.S. Albergo, D. Boyda, D.C. Hackett, G. Kanwar, K. Cranmer, S. Racanière et al., Introduction to Normalizing Flows for Lattice Field Theory, Aug., 2021. 10.48550/arXiv.2101.08176
-
[7]
R. Abbott, M.S. Albergo, D. Boyda, K. Cranmer, D.C. Hackett, G. Kanwar et al., Gauge-equivariant flow models for sampling in lattice field theories with pseudofermions, Physical Review D106(2022) 074506
work page 2022
-
[8]
S.Calì,D.C.Hackett,Y.Lin,P.E.ShanahanandB.Xiao,Neural-networkpreconditionersfor solving the Dirac equation in lattice gauge theory,Physical Review D107(2023) 034508
work page 2023
-
[9]
Y. Sun, S. Eswar, Y. Lin, W. Detmold, P. Shanahan, X. Li et al.,Matrix-free Neural Preconditioner for the Dirac Operator in Lattice Gauge Theory, Sept., 2025. 10.48550/arXiv.2509.10378
-
[10]
C. Lehner and T. Wettig,Gauge-equivariant neural networks as preconditioners in lattice QCD,Physical Review D108(2023) 034503
work page 2023
-
[11]
D. Knüttel, C. Lehner and T. Wettig,Gauge-equivariant multigrid neural networks,PoS LATTICE2023(2024) 037
work page 2024
-
[12]
C. Lehner and T. Wettig,Gauge-equivariant pooling layers for preconditioners in lattice QCD,Physical Review D110(2024) 034517
work page 2024
-
[13]
J.W. Pearson and J. Pestana,Preconditioners for Krylov subspace methods: An overview, GAMM-Mitteilungen43(2020) e202000015
work page 2020
-
[14]
P. Hovland and J. Hückelheim,Differentiating Through Linear Solvers, May, 2024. 10.48550/arXiv.2404.17039. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.