Recognition: no theorem link
Understanding LoRA as Knowledge Memory: An Empirical Analysis
Pith reviewed 2026-05-15 18:06 UTC · model grok-4.3
The pith
LoRA adapters can function as modular parametric memory for LLMs, with measurable capacity and composability limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoRA can serve as a modular knowledge memory whose capacity, composability, and long-context reasoning performance can be systematically characterized to provide practical operational guidance.
What carries the argument
LoRA adapters treated as parametric knowledge stores, with measurements of their storage capacity, internalization during fine-tuning, and scaling behavior when multiple adapters are merged or used together.
If this is right
- Single LoRA modules exhibit finite and predictable storage capacity that increases with rank and training data volume.
- Multiple LoRA modules can be merged or composed while preserving most of their individual knowledge under controlled conditions.
- LoRA-based memory improves performance on long-context reasoning tasks by reducing dependence on large context windows.
- Clear practical boundaries emerge for choosing LoRA memory over retrieval-augmented or in-context methods.
Where Pith is reading between the lines
- Dynamic knowledge bases could be built by training separate adapters on new data batches and swapping them in at inference time without retraining the base model.
- Hybrid systems that combine a small set of LoRA memories with selective retrieval might achieve both efficiency and accuracy gains not available from either approach alone.
- The same capacity-mapping approach could be applied to other adapter families to compare their suitability as modular memory.
Load-bearing premise
The observed capacity limits, internalization behaviors, and multi-module scaling rules generalize beyond the specific models, datasets, and training regimes tested in the experiments.
What would settle it
A single experiment showing that merging two LoRAs each trained on disjoint factual sets causes more than 20 percent drop in recall accuracy on questions drawn from either set would falsify the claimed composability scaling.
Figures









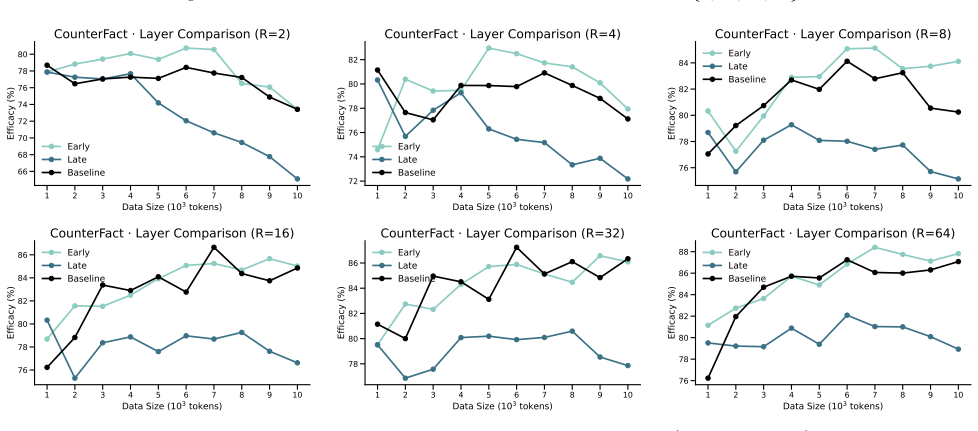
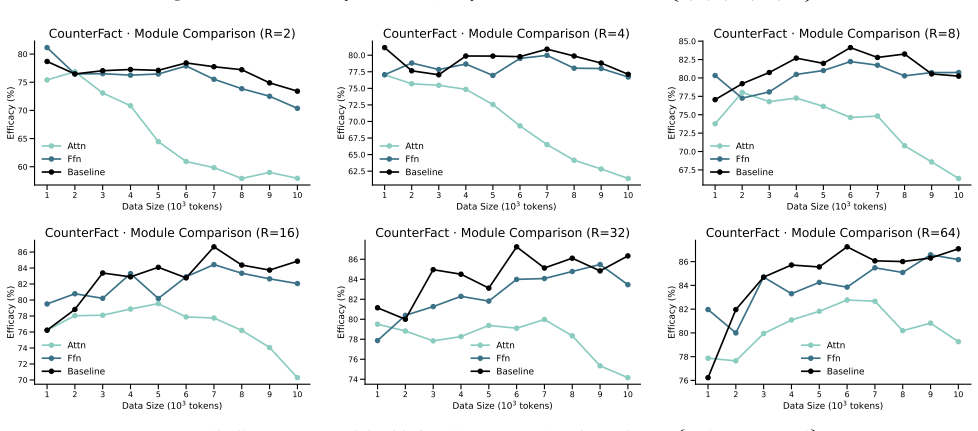

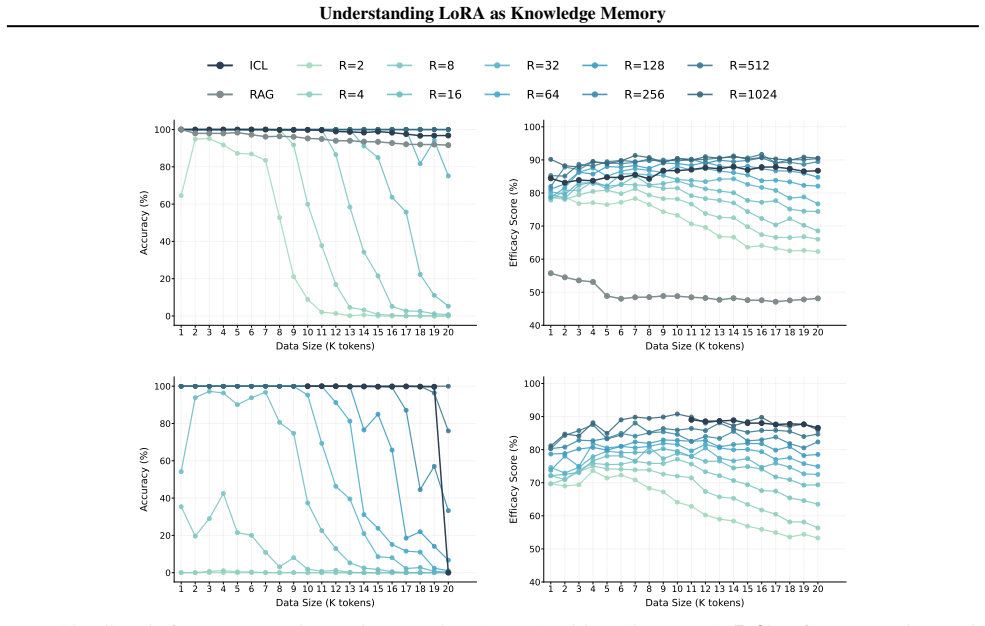

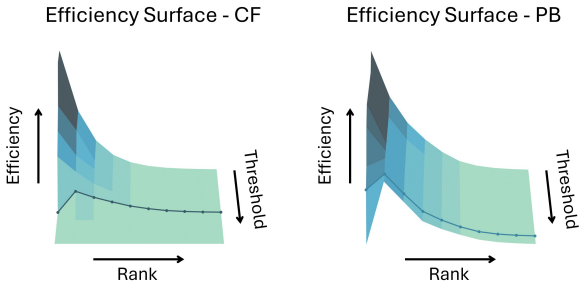

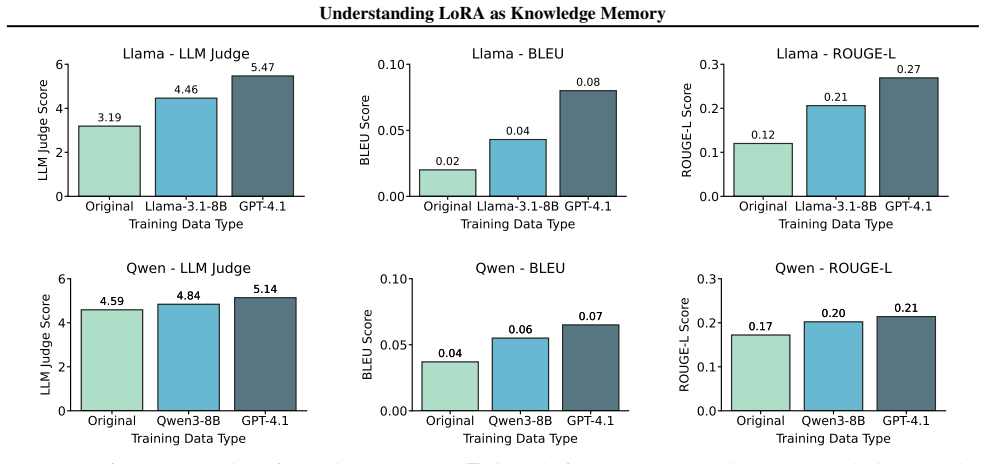




read the original abstract
Continuous knowledge updating for pre-trained large language models (LLMs) is increasingly necessary yet remains challenging. Although inference-time methods like In-Context Learning (ICL) and Retrieval-Augmented Generation (RAG) are popular, they face constraints in context budgets, costs, and retrieval fragmentation. Departing from these context-dependent paradigms, this work investigates a parametric approach using Low-Rank Adaptation (LoRA) as a modular knowledge memory. Although few recent works examine this concept, the fundamental mechanics governing its capacity and composability remain largely unexplored. We bridge this gap through the first systematic empirical study mapping the design space of LoRA-based memory, ranging from characterizing storage capacity and optimizing internalization to scaling multi-module systems and evaluating long-context reasoning. Rather than proposing a single architecture, we provide practical guidance on the operational boundaries of LoRA memory. Overall, our findings position LoRA as the complementary axis of memory alongside RAG and ICL, offering distinct advantages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts the first systematic empirical study of Low-Rank Adaptation (LoRA) as a modular parametric knowledge memory for LLMs. It maps storage capacity, internalization procedures, multi-module composability, and long-context reasoning performance across design choices, with the aim of deriving practical operational boundaries and positioning LoRA as a complementary axis to ICL and RAG for continuous knowledge updating.
Significance. If the reported capacity limits, internalization behaviors, and multi-module scaling rules prove robust, the work supplies concrete operational guidance that could inform deployment decisions for parametric memory, addressing a gap left by context-dependent methods. The purely empirical framing and absence of circular derivations are strengths that keep the contribution focused on falsifiable measurements.
major comments (2)
- The central claim that the study yields transferable practical guidance on capacity, composability, and long-context reasoning rests on the assumption that observed patterns generalize beyond the specific base models, datasets, LoRA ranks, and training regimes tested. The manuscript provides no explicit discussion or ablation of this transferability (e.g., cross-family LLM experiments or out-of-distribution knowledge sets), which directly undermines the operational-guidance conclusion.
- Results sections reporting scaling rules and performance boundaries lack error bars, confidence intervals, or statistical tests for the multi-module and long-context experiments. Without these, it is impossible to determine whether the stated boundaries reflect reliable trends or artifacts of the chosen experimental matrix.
minor comments (2)
- Notation for LoRA rank, module count, and internalization loss is introduced without a consolidated table of symbols, making cross-section comparisons harder than necessary.
- The abstract states that the work is 'the first systematic empirical study,' yet the related-work section does not quantify how prior LoRA memory papers differ in scope; a brief comparison table would strengthen this positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below with clarifications and indicate the specific revisions planned for the manuscript.
read point-by-point responses
-
Referee: The central claim that the study yields transferable practical guidance on capacity, composability, and long-context reasoning rests on the assumption that observed patterns generalize beyond the specific base models, datasets, LoRA ranks, and training regimes tested. The manuscript provides no explicit discussion or ablation of this transferability (e.g., cross-family LLM experiments or out-of-distribution knowledge sets), which directly undermines the operational-guidance conclusion.
Authors: We acknowledge that the experiments are confined to specific base models, datasets, and regimes, as is typical for an initial systematic empirical mapping. To address this directly, we will add a dedicated subsection in the Discussion that explicitly discusses the scope of generalization. This will analyze the consistency of observed patterns (e.g., capacity scaling and composability rules) across the tested conditions and clearly delineate limitations, while recommending future cross-family and out-of-distribution validation. This textual addition strengthens the operational guidance without requiring new experiments. revision: yes
-
Referee: Results sections reporting scaling rules and performance boundaries lack error bars, confidence intervals, or statistical tests for the multi-module and long-context experiments. Without these, it is impossible to determine whether the stated boundaries reflect reliable trends or artifacts of the chosen experimental matrix.
Authors: We agree that the lack of statistical measures reduces the robustness assessment of the reported boundaries. In the revised manuscript, we will incorporate error bars (standard deviation across repeated runs) into the relevant scaling and long-context figures. We will also add statistical significance tests (e.g., paired t-tests with p-values) for key multi-module performance comparisons. These will be computed from our existing experimental data and integrated into the Results sections. revision: yes
Circularity Check
No circularity: purely empirical mapping with no derivation chain
full rationale
The paper conducts a systematic empirical study of LoRA as modular memory, characterizing capacity, composability, and long-context performance through experiments. No mathematical derivations, equations, or predictions are present that could reduce to fitted inputs or self-definitions. Central claims rest on direct experimental observations rather than any load-bearing self-citation, uniqueness theorem, or ansatz smuggled from prior work. The provided guidance is framed as operational boundaries observed in the tested regimes, with no reduction of results to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LoRA adapters can internalize and retrieve factual knowledge when trained on appropriate data
Forward citations
Cited by 1 Pith paper
-
$\delta$-mem: Efficient Online Memory for Large Language Models
δ-mem augments frozen LLMs with an 8x8 online memory state updated by delta-rule learning to generate low-rank attention corrections, delivering 1.10x average gains over the backbone and larger improvements on memory-...
Reference graph
Works this paper leans on
-
[1]
What is the phone number of John Smith?
highlights the importance of data quality and structure for fine-tuning LLMs. Beyond directly training on raw data, studies show that transforming source material into diverse synthetic formats, such as QA pairs, summaries, or rewrites, can improve generalization and robustness. These findings suggest that synthetic augmentation serves as an effective str...
work page 2024
- [2]
- [3]
- [4]
- [5]
- [6]
- [7]
- [8]
- [9]
- [10]
- [11]
- [12]
- [13]
- [14]
- [15]
-
[16]
Efficient and Accurate Explanation Estimation with Distribution Compression https://arxiv.org/abs/2406.18334 C.2. Generation Prompts You are an expert academic assistant tasked with creating a high-quality question-answering dataset from a research paper’s introduction. Your goal is to generate 30 question-and-answer pairs based exclusively on the provide...
-
[17]
**Factual Alignment **: Does the candidate answer state the same facts as the gold answer? It must not contradict the gold answer
-
[18]
**Completeness**: Does the candidate answer include all the key information and nuances present in the gold answer?
-
[19]
score" (an integer from 0-10) and
**Relevance**: Is the answer focused and on-topic? It must not contain irrelevant or hallucinatory information. [SCORING RUBRIC (0-10 SCALE)] - **10**: Perfect. The candidate answer is factually identical to the gold answer, complete, and contains no extraneous information. - **7-9**: Mostly Correct. The answer is factually correct but might omit a minor ...
-
[20]
Trim:This step zeroes out parameters that underwent minimal change during the fine-tuning of each LoRA module. By retaining only the parameters with the largest change in magnitude (e.g., the top-k percentile), this process filters out redundant or less impactful parameters
-
[21]
Elect Sign:This step resolves directional conflicts in parameter updates across different LoRA modules. For a given parameter, some LoRAs may have induced a positive update while others induced a negative one. TIES elects a single, dominant sign based on a majority vote, where the sign corresponding to the greatest total magnitude of updates is chosen as ...
-
[22]
Merge:Finally, only the parameter values that align with the elected sign are averaged. Parameters with conflicting signs are discarded from the merge for that specific weight, thus minimizing negative interference. DARE (Drop And REscale).To address the extreme redundancy in delta parameters, we employ DARE (Yu et al., 2024), which randomly drops a fract...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.