Recognition: 2 theorem links
· Lean TheoremAutoregressive Synthesis of Sparse and Semi-Structured Mixed-Type Data
Pith reviewed 2026-05-15 18:10 UTC · model grok-4.3
The pith
ORiGAMi synthesizes sparse semi-structured JSON data directly with an autoregressive transformer instead of flattening records into tables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ORiGAMi is an autoregressive transformer architecture for modeling and synthesizing semi-structured records without flattening. It serializes JSON records into key, value, and structural tokens, encodes token positions by their path in the document tree, and applies grammar and schema constraints to enforce syntactically valid JSON and dataset-consistent structure. Across six datasets ranging from dense tabular benchmarks to large-scale semi-structured collections, ORiGAMi achieves the best score in 17 of 18 benchmark comparisons against VAE, GAN, diffusion, and autoregressive baselines that operate on flattened representations, while maintaining high privacy scores above 96 percent across所有
What carries the argument
An autoregressive transformer that processes sequences of key-value-structural tokens whose positions are encoded by their path through the JSON document tree, guided by grammar and schema constraints to produce valid nested records.
If this is right
- Synthetic data can preserve nested objects, variable-length arrays, and optional keys without introducing flattening artifacts.
- Performance gains appear on fidelity, detection, and utility metrics for both dense tabular and large semi-structured collections.
- Privacy scores remain above 96 percent while fidelity improves, supporting privacy-preserving data sharing.
- Native record modeling becomes a viable alternative to tabular synthesis pipelines for modern data systems.
Where Pith is reading between the lines
- The same tokenization and path-encoding approach could be tested on other hierarchical formats such as XML or protocol buffers without major redesign.
- Models trained on ORiGAMi outputs might show improved accuracy on queries that traverse nested structures compared with flattened alternatives.
- For extremely deep or wide schemas the fixed token vocabulary and path encoding may require scaling adjustments to stay efficient.
- The grammar-constraint mechanism could be combined with existing autoregressive code-generation techniques for structured output tasks.
Load-bearing premise
Serializing JSON into key-value-structural tokens with path positions plus grammar constraints is sufficient to capture all semantically important relationships in the original semi-structured records without additional domain-specific modeling.
What would settle it
A downstream task whose performance drops when trained on ORiGAMi synthetic data but not on data from a flattening baseline, specifically because certain nested relationships or array-length dependencies are missing.
Figures





read the original abstract
Synthetic data generation is an important capability for privacy-preserving data sharing, system benchmarking and test data provisioning. For mixed-type data, existing synthesizers largely target dense, fixed-schema tables, but many modern data systems store and exchange sparse, semi-structured JSON with nested objects, variable-length arrays and optional keys. Applying tabular synthesizers to such data requires flattening records into wide, sparse tables, turning nested structure and arrays into column-layout artifacts. We present ORiGAMi, an autoregressive transformer architecture for modeling and synthesizing semi-structured records without flattening. ORiGAMi serializes JSON records into key, value, and structural tokens, and encodes token positions by their path in the document tree. Grammar and schema constraints enforce syntactically valid JSON and dataset-consistent structure. We evaluate ORiGAMi against VAE, GAN, diffusion, and autoregressive baselines that operate on flattened representations across six datasets ranging from dense tabular benchmarks to large-scale semi-structured collections. Across fidelity, detection, and utility metrics, ORiGAMi achieves the best score in 17 of 18 benchmark comparisons, while maintaining high privacy scores above 96% across all settings. These results establish native record modeling as a strong alternative to tabular synthesis pipelines, preserving structure while achieving state-of-the-art benchmark performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ORiGAMi, an autoregressive transformer for synthesizing sparse semi-structured mixed-type data in JSON format. Records are serialized into key-value-structural tokens with path-based position encodings in the document tree; grammar and schema constraints enforce syntactic validity and dataset consistency. Evaluated against VAE, GAN, diffusion, and autoregressive baselines on flattened representations across six datasets, ORiGAMi reports the best score in 17 of 18 comparisons on fidelity, detection, and utility metrics while maintaining privacy scores above 96%.
Significance. If the empirical superiority holds under proper statistical controls, the work establishes native path-encoded autoregressive modeling as a viable and potentially superior alternative to flattening-based tabular synthesizers for nested and sparse JSON data, with direct relevance to privacy-preserving data sharing in modern systems.
major comments (2)
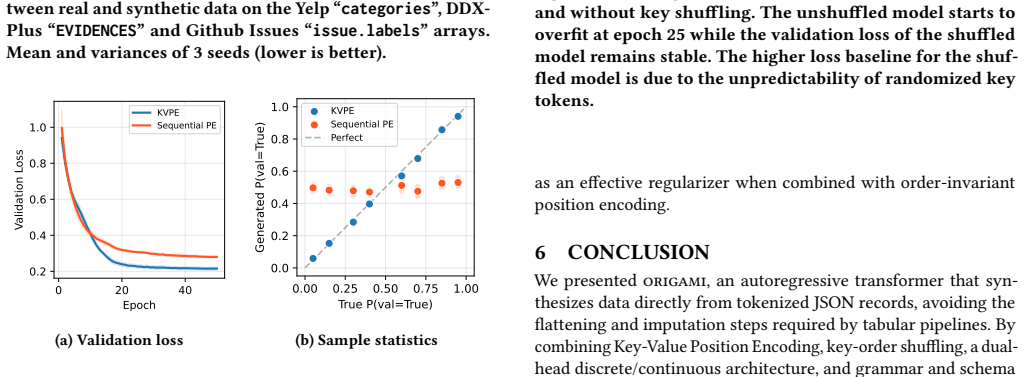
- [§5 (Experimental Evaluation)] §5 (Experimental Evaluation): the central claim of best performance in 17 of 18 benchmark comparisons reports only point estimates with no standard deviations across seeds, no p-values, and no mention of multiple independent runs. Autoregressive transformers on variable-length sequences are known to exhibit high training variance; without these controls the reliability of the reported margins cannot be assessed.
- [§4 (Baselines and Adaptation)] §4 (Baselines and Adaptation): the manuscript provides insufficient detail on how the tabular baselines (VAE, GAN, diffusion, autoregressive) were adapted to semi-structured inputs after flattening, including any specific preprocessing for nested objects, variable-length arrays, and optional keys.
minor comments (2)
- [§3 (Model Architecture)] The path-based position encoding is described at a high level but would benefit from an explicit equation or pseudocode definition to clarify how tree paths are mapped to token positions.
- A summary table listing the six datasets with key characteristics (size, sparsity, nesting depth) would improve readability of the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript accordingly to improve the statistical rigor of the evaluation and the clarity of the baseline adaptations.
read point-by-point responses
-
Referee: §5 (Experimental Evaluation): the central claim of best performance in 17 of 18 benchmark comparisons reports only point estimates with no standard deviations across seeds, no p-values, and no mention of multiple independent runs. Autoregressive transformers on variable-length sequences are known to exhibit high training variance; without these controls the reliability of the reported margins cannot be assessed.
Authors: We agree that point estimates alone are insufficient to establish the reliability of the reported performance margins, particularly for autoregressive models that can exhibit training variance. In the revised manuscript we will rerun all experiments across at least five independent random seeds, report mean and standard deviation for every metric, and include appropriate statistical tests (paired t-tests or Wilcoxon signed-rank tests with Bonferroni correction) to assess whether the observed differences are significant. These additions will be placed in §5 and the corresponding tables/figures will be updated. revision: yes
-
Referee: §4 (Baselines and Adaptation): the manuscript provides insufficient detail on how the tabular baselines (VAE, GAN, diffusion, autoregressive) were adapted to semi-structured inputs after flattening, including any specific preprocessing for nested objects, variable-length arrays, and optional keys.
Authors: We acknowledge that the current description of baseline adaptation is too brief. In the revised §4 we will add a dedicated subsection that explicitly describes the flattening procedure: nested objects are flattened using dot-path column names, variable-length arrays are expanded into multiple columns with a fixed maximum length (with padding and a length indicator column), and optional keys are represented as nullable columns with an explicit missing-value indicator. We will also document any additional preprocessing steps (e.g., type casting, normalization) applied uniformly to all methods to ensure a fair comparison. revision: yes
Circularity Check
No circularity: empirical benchmarks on held-out data with independent baselines
full rationale
The paper introduces ORiGAMi as an autoregressive transformer that serializes JSON into path-encoded tokens with grammar constraints, then reports direct empirical comparisons on six datasets against VAE/GAN/diffusion/autoregressive baselines. No equations, fitted parameters, or self-citations are invoked to derive the 17/18 best-score claim; metrics are computed on held-out test records. The derivation chain consists of model definition followed by standard train/test evaluation, with no reduction of outputs to inputs by construction. This matches the reader's assessment of non-circular empirical evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- transformer hyperparameters
axioms (1)
- domain assumption JSON records can be losslessly serialized into a linear sequence of key, value, and structural tokens whose positions are fully determined by their tree path.
invented entities (1)
-
path-based position encoding for JSON tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Grammar and schema constraints, enforced via a pushdown automaton and a compiled mask table
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Michael A. Alcorn and Anh Nguyen. 2021. The DEformer: An Order-Agnostic Distribution Estimating Transformer. http://arxiv.org/abs/2106.06989
-
[2]
Vadim Borisov, Kathrin Seßler, Tobias Leemann, Martin Pawelczyk, and Gjergji Kasneci. 2023. Language Models are Realistic Tabular Data Generators. In International Conference on Learning Representations (ICLR)
work page 2023
-
[3]
Reutter, Fernando Suárez, and Domagoj Vrgoč
Pierre Bourhis, Juan L. Reutter, Fernando Suárez, and Domagoj Vrgoč. 2017. JSON: Data Model, Query Languages and Schema Specification. InProceedings of the 36th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems (PODS). 123–135. https://doi.org/10.1145/3034786.3056120
-
[4]
Kuntai Cai, Xiaokui Xiao, and Graham Cormode. 2023. PrivLava: Synthesizing Relational Data with Foreign Keys under Differential Privacy. InProceedings of the 2023 International Conference on Management of Data. ACM, 1–25
work page 2023
-
[5]
Michael Carey, Wail Alkowaileet, Nick DiGeronimo, Peeyush Gupta, Sachin Smotra, and Till Westmann. 2025. Towards Principled, Practical Document Database Design.Proceedings of the VLDB Endowment18, 12 (2025), 4804–4816. https://doi.org/10.14778/3750601.3750606
-
[6]
Sonia Cromp, Satya Sai Srinath Namburi GNVV, Mohammed Alkhudhayri, Catherine Cao, Samuel Guo, Nicholas Roberts, and Frederic Sala. 2026. Tabby: A Language Model Architecture for Tabular and Structured Data Synthesis.Trans- actions on Machine Learning Research(2026). https://openreview.net/forum?id= b9FPVnb0Bn
work page 2026
-
[7]
DataCebo, Inc. 2026.Synthetic Data Metrics. DataCebo, Inc. https://docs.sdv. dev/sdmetrics/ Version 0.12.0
work page 2026
-
[8]
Arsene Fansi Tchango, Rishab Goel, Zhi Wen, Julien Martel, and Joumana Ghosn
-
[9]
InAdvances in Neural Information Processing Systems, Vol
DDXPlus: A New Dataset for Automatic Medical Diagnosis. InAdvances in Neural Information Processing Systems, Vol. 35. 31306–31318
-
[10]
Philip Gage. 1994. A new algorithm for data compression.C Users J.12, 2 (Feb. 1994), 23–38
work page 1994
-
[11]
Yunqing Ge et al. 2025. Privacy-Enhanced Database Synthesis for Benchmark Publishing.Proceedings of the VLDB Endowment18, 2 (2025)
work page 2025
-
[12]
Siavash Golkar, Mariel Pettee, Michael Eickenberg, Alberto Bietti, Miles Cranmer, Geraud Krawezik, Francois Lanusse, Michael McCabe, Ruben Ohana, Liam Parker, Bruno Régaldo-Saint Blancard, Tiberiu Tesileanu, Kyunghyun Cho, and Shirley Ho. 2023. xVal: A Continuous Number Encoding for Large Language Models. http://arxiv.org/abs/2310.02989
-
[13]
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Networks. InAdvances in Neural Information Processing Systems, Vol. 27
work page 2014
-
[14]
Dan Hendrycks and Kevin Gimpel. 2016. Gaussian Error Linear Units (GELUs). http://arxiv.org/abs/1606.08415
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[15]
James Jordon, Lukasz Szpruch, Florimond Houssiau, Mirko Bottarelli, Giovanni Cherubin, Carsten Maple, Samuel N. Cohen, and Adrian Weller. 2022. Synthetic Data – What, Why and How? http://arxiv.org/abs/2205.03257
-
[16]
Markelle Kelly, Rachel Longjohn, and Kolby Nottingham. [n.d.]. The UCI Machine Learning Repository. https://archive.ics.uci.edu
-
[17]
Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. InInternational Conference on Learning Representations (ICLR)
work page 2014
-
[18]
Terry Koo, Frederick Liu, and Luheng He. 2024. Automata-Based Constraints for Language Model Decoding. InConference on Language Modeling. https: //openreview.net/forum?id=BDBdblmyzY
work page 2024
-
[19]
Akim Kotelnikov, Dmitry Baranchuk, Ivan Rubachev, and Artem Babenko. 2023. TabDDPM: Modelling Tabular Data with Diffusion Models. InInternational Conference on Machine Learning (ICML). 17564–17579
work page 2023
-
[20]
Qinyi Liu, Mohammad Khalil, Jelena Jovanovic, and Ronas Shakya. 2024. Scaling While Privacy Preserving: A Comprehensive Synthetic Tabular Data Generation and Evaluation in Learning Analytics. InProceedings of the 14th Learning Analyt- ics and Knowledge Conference (LAK). 620–631. https://doi.org/10.1145/3636555. 3636921
-
[21]
Tennison Liu, Zhaozhi Qian, Jeroen Berrevoets, and Mihaela van der Schaar
-
[22]
InInternational Conference on Learning Representations (ICLR)
GOGGLE: Generative Modelling for Tabular Data by Learning Relational Structure. InInternational Conference on Learning Representations (ICLR)
-
[23]
David Lopez-Paz and Maxime Oquab. 2017. Revisiting Classifier Two-Sample Tests. InInternational Conference on Learning Representations (ICLR)
work page 2017
-
[24]
Shubhankar Mohapatra, Jianqiao Zong, Florian Kerschbaum, and Xi He. 2024. Differentially Private Data Generation with Missing Data.Proceedings of the VLDB Endowment17, 8 (2024), 2022–2035
work page 2024
- [25]
-
[26]
Neha Patki, Roy Wedge, and Kalyan Veeramachaneni. 2016. The Synthetic Data Vault. In2016 IEEE International Conference on Data Science and Advanced Analytics (DSAA). 399–410. https://doi.org/10.1109/DSAA.2016.49
-
[27]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cour- napeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research12 (2011), 2825–2830
work page 2011
-
[28]
Reutter, Fernando Suarez, Martín Ugarte, and Domagoj Vrgoč
Felipe Pezoa, Juan L. Reutter, Fernando Suarez, Martín Ugarte, and Domagoj Vrgoč. 2016. Foundations of JSON schema. InProceedings of the 25th international conference on world wide web (WWW). 263–273
work page 2016
-
[29]
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever
-
[30]
https://cdn.openai.com/research-covers/language-unsupervised/language_ understanding_paper.pdf
Improving Language Understanding by Generative Pre-Training. https://cdn.openai.com/research-covers/language-unsupervised/language_ understanding_paper.pdf
-
[31]
Tobias Schmidt, Viktor Leis, Peter Boncz, and Thomas Neumann. 2025. SQLStorm: Taking Database Benchmarking into the LLM Era.Proceedings of the VLDB Endowment18, 11 (2025), 4144–4157. https://doi.org/10.14778/3749646.3749683
-
[32]
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. 2025. TabDiff: a Mixed-type Diffusion Model for Tabular Data Gen- eration. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=swvURjrt8z
work page 2025
- [33]
-
[34]
Aivin V. Solatorio and Olivier Dupriez. 2023. REaLTabFormer: Generating Real- istic Relational and Tabular Data using Transformers. http://arxiv.org/abs/2302. 02041
work page 2023
-
[35]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting.Journal of Machine Learning Research15, 56 (2014), 1929–1958
work page 2014
-
[36]
Michael Stonebraker and Andrew Pavlo. 2024. What Goes Around Comes Around... And Around...ACM Sigmod Record53, 2 (2024), 21–37
work page 2024
-
[37]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu
-
[38]
https://doi.org/10.1016/j.neucom.2023.127063
RoFormer: Enhanced Transformer with Rotary Position Embedding.Neu- rocomputing568 (2024), 127063. https://doi.org/10.1016/j.neucom.2023.127063
- [39]
-
[40]
Benigno Uria, Iain Murray, and Hugo Larochelle. 2014. A Deep and Tractable Density Estimator. InInternational Conference on Machine Learning (ICML). 467– 475
work page 2014
-
[41]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All You Need. InAdvances in Neural Information Processing Systems, Vol. 30. 5998– 6008
work page 2017
-
[42]
2009.Optimal transport: old and new
Cédric Villani et al. 2009.Optimal transport: old and new. Vol. 338. Springer
work page 2009
-
[43]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf. 2023. Efficient Guided Generation for Large Language Models. http://arxiv.org/abs/2307.09702 arXiv:2307.09702 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason R...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni
-
[46]
InAdvances in Neural Information Processing Systems, Vol
Modeling Tabular Data using Conditional GAN. InAdvances in Neural Information Processing Systems, Vol. 32
-
[47]
Jingyi Yang, Peizhi Wu, Gao Cong, Tong Yang, and Jianfei Ruan. 2022. SAM: Database Generation from Query Workloads with Supervised Autoregressive Models. InProceedings of the 2022 International Conference on Management of Data. ACM, 1542–1555
work page 2022
-
[48]
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. 2019. XLNet: Generalized Autoregressive Pretraining for Lan- guage Understanding. InAdvances in Neural Information Processing Systems, Vol. 32
work page 2019
-
[49]
Hellerstein, Sanjay Krishnan, and Ion Stoica
Zongheng Yang, Eric Liang, Amog Kamsetty, Chenggang Wu, Yan Duan, Xi Chen, Pieter Abbeel, Joseph M. Hellerstein, Sanjay Krishnan, and Ion Stoica. 2019. Deep Unsupervised Cardinality Estimation.Proceedings of the VLDB Endowment13, 3 (2019), 279–292. https://doi.org/10.14778/3368289.3368294
- [50]
-
[51]
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, and George Karypis. 2024. Mixed- Type Tabular Data Synthesis with Score-based Diffusion in Latent Space. In International Conference on Learning Representations (ICLR). 13
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.