Recognition: 2 theorem links
· Lean TheoremMerged amplitude encoding for Chebyshev quantum Kolmogorov--Arnold networks: trading qubits for circuit executions
Pith reviewed 2026-05-15 17:04 UTC · model grok-4.3
The pith
Merged amplitude encoding in Chebyshev quantum KANs reduces circuit executions by a factor of n while preserving trainability under tested conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
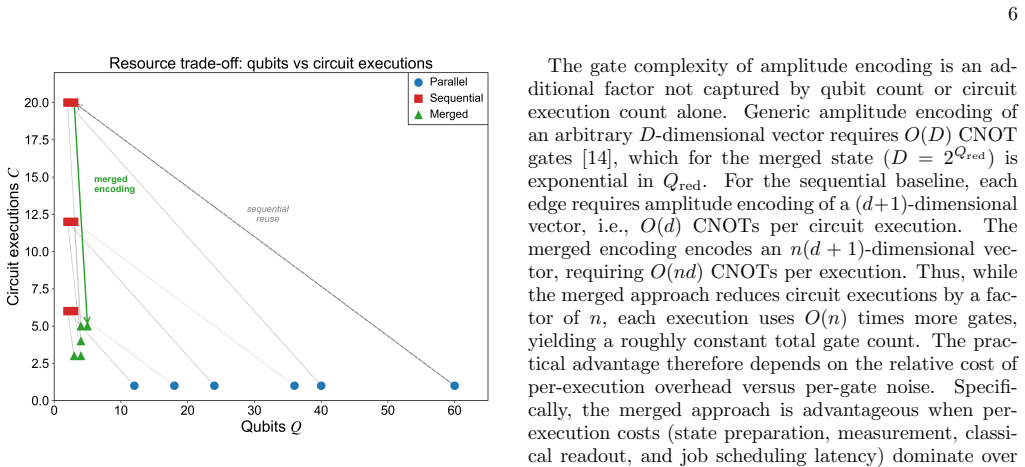
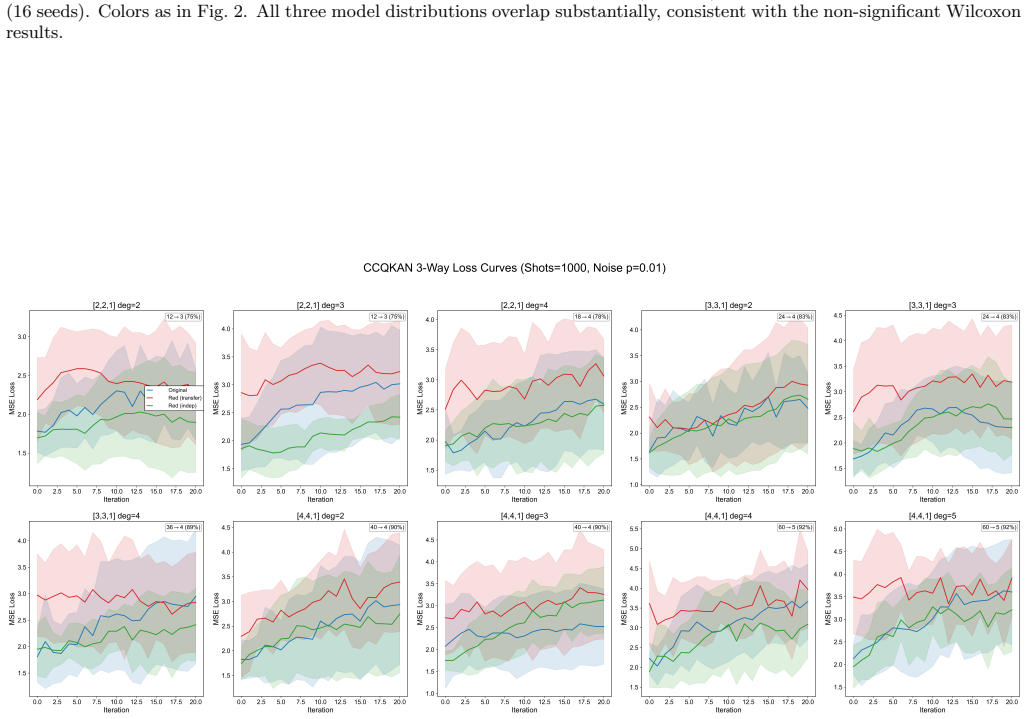
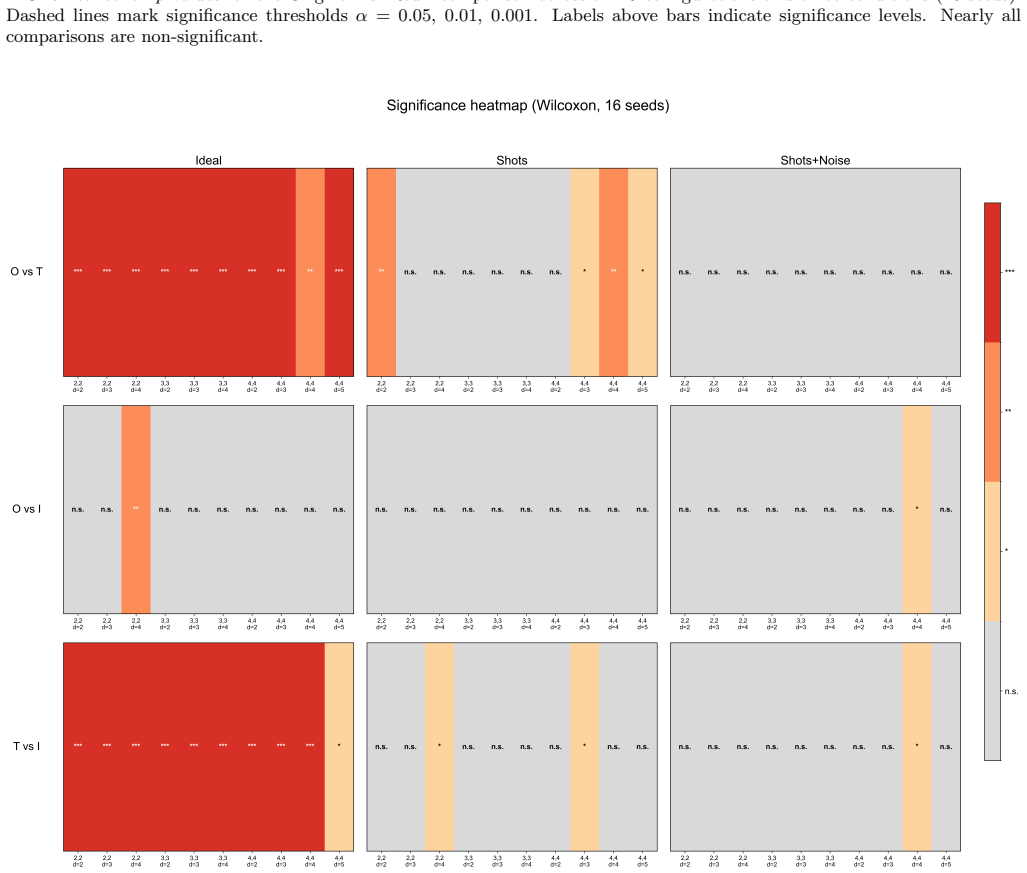
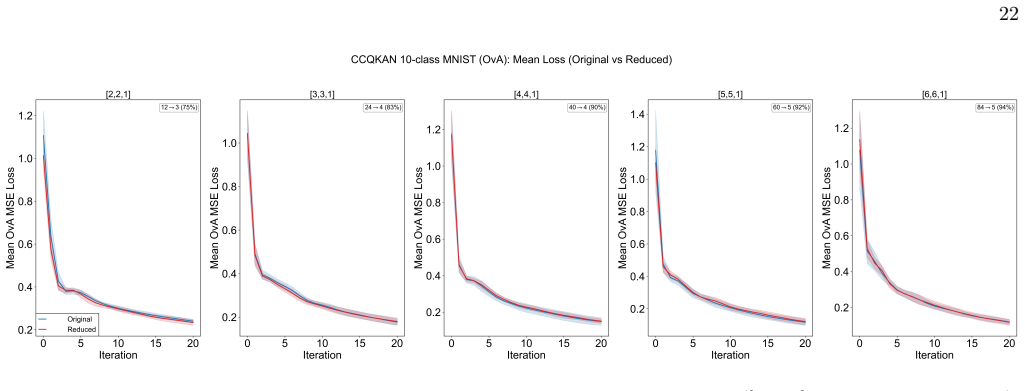
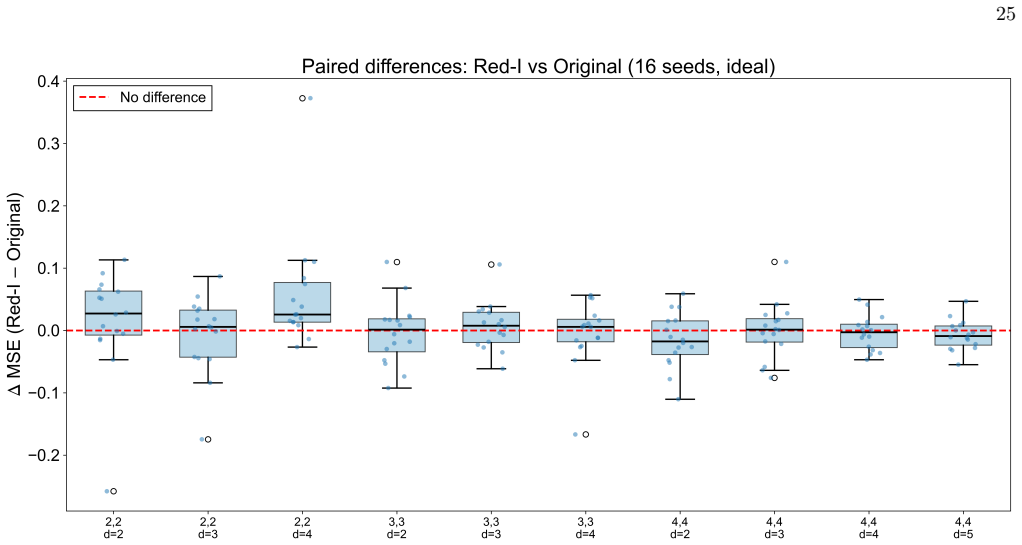
Merged amplitude encoding packs all n input-edge products for a given output node into a single amplitude state. The resulting circuit computes exactly the same inner-product activations as the sequential baseline. Wilcoxon signed-rank tests across ten configurations show no significant difference between independently initialized merged circuits and the original in 28 of 30 comparisons, while parameter transfer yields lower loss under ideal conditions in 9 of 10 cases. On 8x8 MNIST one-vs-all classification both reach 53-78% test accuracy with no detectable difference.
What carries the argument
Merged amplitude encoding, which combines the element-wise products of all n input vectors for an output node into one amplitude-encoded quantum state.
If this is right
- One or two extra qubits can replace an n-fold increase in circuit executions per forward pass.
- Gradient-based optimization remains effective for the merged circuit in the tested ideal, shot-limited, and noisy regimes.
- Parameter transfer from a trained original circuit can accelerate training of the merged version under noise-free conditions.
- Comparable performance extends from loss minimization to 10-class digit classification with a one-vs-all strategy.
Where Pith is reading between the lines
- The qubit-execution trade-off may allow larger networks on hardware with tight qubit limits but high repetition rates.
- Similar merging of amplitude states could reduce runtime in other quantum models that encode activations via inner products.
- If the pattern holds on physical devices, the method points toward a general resource-balancing principle for variational quantum circuits.
Load-bearing premise
The ten specific network configurations and the three simulation regimes are representative enough to conclude that trainability is preserved in general.
What would settle it
A statistically significant increase in final loss or drop in classification accuracy for the merged circuit relative to the original when both are trained on real quantum hardware under identical protocols and initializations.
Figures







read the original abstract
Quantum Kolmogorov--Arnold networks based on Chebyshev polynomials (CCQKAN) evaluate each edge activation function as a quantum inner product, creating a trade-off between qubit count and the number of circuit executions per forward pass. We introduce merged amplitude encoding, a technique that packs the element-wise products of all $n$ input-edge vectors for a given output node into a single amplitude state, reducing circuit executions by a factor of $n$ at a cost of only 1--2 additional qubits relative to the sequential baseline. The merged and original circuits compute the same mathematical quantity exactly; the open question is whether they remain equally trainable within a gradient-based optimization loop. We address this question through numerical experiments on 10 network configurations under ideal, finite-shot, and noisy simulation conditions, comparing original, parameter-transferred, and independently initialized merged circuits over 16 random seeds. Wilcoxon signed-rank tests show no significant difference between the independently initialized merged circuit and the original ($p > 0.05$ in 28 of 30 comparisons), while parameter transfer yields significantly lower loss under ideal conditions ($p < 0.001$ in 9 of 10 configurations). On 10-class digit classification with the $8\times8$ MNIST dataset using a one-vs-all strategy, original and merged circuits achieve comparable test accuracies of 53--78\% with no significant difference in any configuration. These results provide empirical evidence that merged amplitude encoding preserves trainability under the simulation conditions tested.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes merged amplitude encoding for Chebyshev quantum Kolmogorov-Arnold networks (CCQKANs). This packs the element-wise products of all n input-edge vectors for an output node into one amplitude state, cutting circuit executions by a factor of n at the cost of 1-2 extra qubits. The merged and original circuits are shown to compute exactly the same quantity; numerical experiments on 10 network configurations under ideal, finite-shot, and noisy simulations (16 seeds) use Wilcoxon signed-rank tests to demonstrate no significant difference in trainability between independently initialized merged circuits and the original (p > 0.05 in 28/30 cases), with parameter transfer sometimes improving loss. On 8×8 MNIST one-vs-all classification the two achieve comparable test accuracies (53-78%) with no significant differences.
Significance. If the simulation results hold, the technique supplies a concrete qubit-versus-execution trade-off that could help scale quantum neural networks by lowering the number of circuit runs per forward pass while preserving gradient-based trainability. The work is strengthened by its direct mathematical equivalence statement, use of non-parametric statistical tests across multiple noise models and random seeds, and reproducible empirical protocol on a standard dataset.
major comments (1)
- [Numerical Experiments] Numerical Experiments section: the claim that merged encoding 'preserves trainability' rests on non-significant Wilcoxon results (p > 0.05 in 28/30 comparisons) without reported effect sizes, confidence intervals on loss differences, or equivalence testing (e.g., TOST); with only 16 seeds this leaves open whether the tests had sufficient power to detect practically relevant differences.
minor comments (2)
- [Abstract and Introduction] The abstract and conclusion correctly qualify results as holding 'under the simulation conditions tested,' yet the title and introduction could add an explicit sentence on the absence of real-device validation to avoid over-generalization.
- [Figures and Methods] Figure captions and the experimental setup description should state the precise noise model parameters and qubit counts used for the merged versus baseline circuits so that the 1-2 qubit overhead is immediately verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We address the single major comment on the numerical experiments below.
read point-by-point responses
-
Referee: [Numerical Experiments] Numerical Experiments section: the claim that merged encoding 'preserves trainability' rests on non-significant Wilcoxon results (p > 0.05 in 28/30 comparisons) without reported effect sizes, confidence intervals on loss differences, or equivalence testing (e.g., TOST); with only 16 seeds this leaves open whether the tests had sufficient power to detect practically relevant differences.
Authors: We agree that the reliance on non-significant p-values alone, without effect sizes, confidence intervals, or equivalence testing, weakens the strength of the trainability claim, and that 16 seeds may provide insufficient power to detect small but meaningful differences. The mathematical equivalence of the merged and original circuits remains exact, and the consistent pattern of non-significance (28/30 cases) together with comparable MNIST accuracies offers supporting evidence under the simulated conditions. In the revised manuscript we will add effect-size reporting (rank-biserial correlation for the Wilcoxon tests) and explicit confidence intervals on the loss differences; we will also include a short discussion of statistical power limitations. We will not add TOST equivalence tests, as determining appropriate equivalence bounds would require additional simulation runs and is beyond the scope of the current study. revision: partial
Circularity Check
No circularity: empirical equivalence shown via direct simulation comparison
full rationale
The paper defines merged amplitude encoding, states that it computes the identical mathematical quantity as the sequential baseline (by construction of the packing), and then validates trainability via independent numerical experiments under ideal/finite-shot/noisy conditions using Wilcoxon tests and accuracy metrics on MNIST. No self-citations, no fitted parameters renamed as predictions, no ansatz smuggled via prior work, and no reduction of the central claim to its own inputs. The derivation chain is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard quantum circuit model and amplitude encoding principles hold for the inner-product evaluations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
merged amplitude encoding packs the element-wise products of all n input-edge vectors ... into a single amplitude state, reducing circuit executions by a factor of n at a cost of only 1-2 additional qubits
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Wilcoxon signed-rank tests show no significant difference ... comparable test accuracies of 53-78%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Inputsx∈R n are normalized from the data range to [−1,1]
-
[2]
For each hidden nodej∈ {1, . . . , n}, the hidden activation is hj = tanh nX i=1 φij(xi) ! ,(5) whereφ ij(xi) = Pd k=0 cij,kTk(xi) is evaluated via the quantum inner product. In the original circuit, this requiresnseparate inner product evaluations per hidden node
-
[3]
The output isy=α Pn i=1 φ(2) i (hi) +β, computed byninner products followed by the classical GFCF. 3 III. MERGED AMPLITUDE ENCODING A. Derivation Consider the computation of hidden nodejin the first layer. In the original architecture, each edge (i, j) com- putes the inner product⟨ ˆcij, ˆT(x i)⟩between normalized amplitude states, then rescales by∥c ij∥ ...
-
[4]
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Quantum machine learning, Na- ture549, 195 (2017)
work page 2017
-
[5]
M. Schuld and N. Killoran, Quantum machine learning in feature Hilbert spaces, Phys. Rev. Lett.122, 040504 (2019)
work page 2019
- [6]
-
[7]
M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Pa- rameterized quantum circuits as machine learning mod- els, Quantum Sci. Technol.4, 043001 (2019)
work page 2019
-
[8]
Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
J. Preskill, Quantum computing in the NISQ era and beyond, Quantum2, 79 (2018)
work page 2018
-
[9]
A. P´ erez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Data re-uploading for a universal quantum classifier, Quantum4, 226 (2020)
work page 2020
-
[10]
A. N. Kolmogorov, On the representation of continuous functions of many variables by superposition of continu- ous functions of one variable and addition, Dokl. Akad. Nauk SSSR114, 953 (1957)
work page 1957
-
[11]
V. I. Arnold, On functions of three variables, Dokl. Akad. Nauk SSSR114, 679 (1957)
work page 1957
-
[12]
Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halver- son, M. Soljaˇ ci´ c, T. Y. Hou, and M. Tegmark, KAN: Kolmogorov–Arnold networks (2024), arXiv:2404.19756
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
A. Kundu and D. Sarkar, Quantum Kolmogorov–Arnold networks (2024), arXiv:2410.04435
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
H. Wakaura, Variational quantum Kolmogorov– Arnold network (2024), research Square preprint, doi:10.21203/rs.3.rs-5765513/v1
-
[15]
Wakaura, Chebyshev-based continuous quantum Kolmogorov–Arnold network (2025), arXiv:2501.09392
H. Wakaura, Chebyshev-based continuous quantum Kolmogorov–Arnold network (2025), arXiv:2501.09392
-
[16]
H. Buhrman, R. Cleve, J. Watrous, and R. de Wolf, Quantum fingerprinting, Phys. Rev. Lett.87, 167902 (2001)
work page 2001
-
[17]
V. V. Shende, S. S. Bullock, and I. L. Markov, Synthesis of quantum-logic circuits, IEEE Trans. Comput.-Aided Design Integr. Circuits Syst.25, 1000 (2006)
work page 2006
-
[18]
D. P. Kingma and J. Ba, Adam: A method for stochas- tic optimization, inProceedings of the 3rd International Conference on Learning Representations (ICLR)(2015)
work page 2015
-
[19]
K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quan- tum circuit learning, Phys. Rev. A98, 032309 (2018)
work page 2018
-
[20]
Wilcoxon, Individual comparisons by ranking meth- ods, Biom
F. Wilcoxon, Individual comparisons by ranking meth- ods, Biom. Bull.1, 80 (1945)
work page 1945
-
[21]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cour- napeau, M. Brucher, M. Perrot, and E. Duchesnay, Scikit-learn: Machine learning in Python, J. Mach. Learn. Res.12, 2825 (2011)
work page 2011
-
[22]
S. Wang, E. Fontana, M. Cerezo, K. Sharma, A. Sone, L. Cincio, and P. J. Coles, Noise-induced barren plateaus in variational quantum algorithms, Nat. Commun.12, 6961 (2021)
work page 2021
-
[23]
D. Stilck Fran¸ ca and R. Garcia-Patron, Limitations of optimization algorithms on noisy quantum devices, Nat. Phys.17, 1221 (2021)
work page 2021
-
[24]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, Barren plateaus in quantum neural net- work training landscapes, Nat. Commun.9, 4812 (2018)
work page 2018
- [25]
- [26]
-
[27]
M. Kjaergaard, M. E. Schwartz, J. Braum¨ uller, P. Krantz, J. I.-J. Wang, S. Gustavsson, and W. D. Oliver, Superconducting qubits: Current state of play, Annu. Rev. Condens. Matter Phys.11, 369 (2020)
work page 2020
- [28]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.