Recognition: 2 theorem links
· Lean TheoremDistributional Reinforcement Learning with Information Bottleneck for Uncertainty-Aware DRAM Equalization
Pith reviewed 2026-05-15 16:24 UTC · model grok-4.3
The pith
Distributional reinforcement learning with information bottleneck enables 51x faster DRAM equalizer optimization with worst-case guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating information bottleneck latent representations into a distributional reinforcement learning setup with quantile regression and conditional value-at-risk, the framework achieves rate-distortion optimal signal compression for 51 times speedup, enables explicit worst-case optimization, and uses Monte Carlo dropout with PAC-Bayesian regularization to provide uncertainty quantification and generalization bounds, resulting in significant performance improvements on real hardware data.
What carries the argument
Information bottleneck for rate-distortion optimal signal compression combined with distributional RL and CVaR for risk-sensitive worst-case equalizer optimization.
If this is right
- Rate-distortion optimal compression achieves 51 times speedup over traditional eye diagram evaluations.
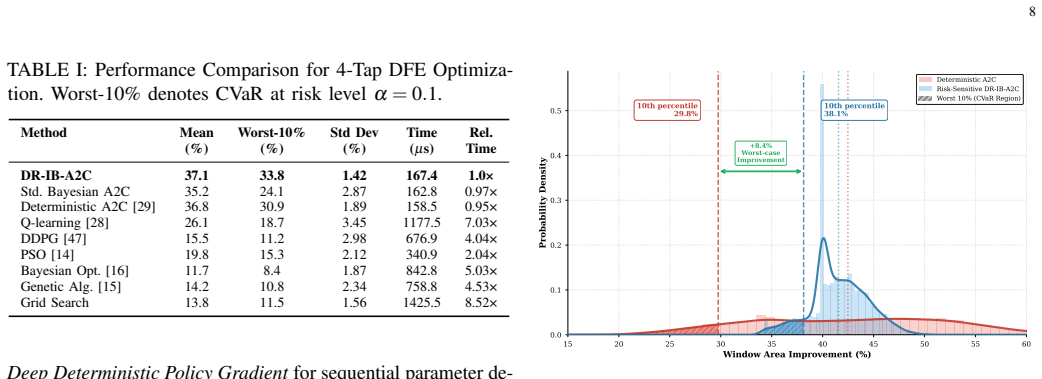
- Mean improvements reach 37.1% for 4-tap and 41.5% for 8-tap equalizer configurations.
- Worst-case guarantees provide 33.8% and 38.2% improvements respectively.
- Performance exceeds Q-learning baselines by 80.7% and 89.1%.
- 62.5% of configurations receive high-reliability classification without manual validation.
Where Pith is reading between the lines
- The compression approach could be adapted for parameter optimization in other high-speed interface technologies.
- Uncertainty estimates may allow for risk-based selection of equalizer settings in production environments.
- The framework's guarantees might inform the development of automated testing protocols for memory systems.
Load-bearing premise
The information bottleneck compression preserves sufficient information for accurate optimization of equalizer parameters and the Monte Carlo dropout with PAC-Bayesian bounds provides reliable certification of uncertainty and generalization in the hardware context.
What would settle it
Demonstrating on additional memory units that parameters selected using the compressed representations yield inferior signal integrity compared to direct optimization on full waveforms would falsify the sufficiency of the preserved information.
Figures






read the original abstract
Equalizer parameter optimization is critical for signal integrity in high-speed memory systems operating at multi-gigabit data rates. However, existing methods suffer from computationally expensive eye diagram evaluation, optimization of expected rather than worst-case performance, and absence of uncertainty quantification for deployment decisions. In this paper, we propose a distributional risk-sensitive reinforcement learning framework integrating Information Bottleneck latent representations with Conditional Value-at-Risk optimization. We introduce rate-distortion optimal signal compression achieving 51 times speedup over eye diagrams while quantifying epistemic uncertainty through Monte Carlo dropout. Distributional reinforcement learning with quantile regression enables explicit worst-case optimization, while PAC-Bayesian regularization certifies generalization bounds. Experimental validation on 2.4 million waveforms from eight memory units demonstrated mean improvements of 37.1\% and 41.5\% for 4-tap and 8-tap equalizer configurations with worst-case guarantees of 33.8\% and 38.2\%, representing 80.7\% and 89.1\% improvements over Q-learning baselines. The framework achieved 62.5\% high-reliability classification eliminating manual validation for most configurations. These results suggest the proposed framework provides a practical solution for production-scale equalizer optimization with certified worst-case guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a distributional risk-sensitive reinforcement learning framework integrating Information Bottleneck (IB) latent representations with Conditional Value-at-Risk (CVaR) optimization for DRAM equalizer parameter tuning. It claims rate-distortion optimal signal compression yields a 51x speedup over eye-diagram evaluation, Monte Carlo dropout quantifies epistemic uncertainty, quantile regression enables explicit worst-case optimization, and PAC-Bayesian regularization provides generalization certificates. On 2.4 million waveforms from eight memory units, it reports mean improvements of 37.1% (4-tap) and 41.5% (8-tap) with worst-case guarantees of 33.8% and 38.2%, representing 80.7% and 89.1% gains over Q-learning baselines, plus 62.5% high-reliability classification.
Significance. If the results hold, the work supplies a practical, certified approach to production-scale equalizer optimization that replaces expensive eye-diagram evaluations with learned compression while explicitly targeting worst-case performance and quantifying uncertainty. The combination of IB compression, distributional RL, and PAC-Bayes bounds is novel for this hardware domain and the scale of the experimental validation (2.4 M waveforms) strengthens its engineering relevance.
major comments (3)
- The headline worst-case guarantees (33.8 % / 38.2 %) rest on the claim that rate-distortion optimal IB latents preserve all information required for CVaR optimization. No ablation that varies the IB coefficient and re-measures worst-case improvement on the same 2.4 M waveforms is reported; without it the reported gains could be artifacts of tail-feature loss rather than genuine risk-sensitive optimization.
- The experimental section states 80.7 % / 89.1 % improvements over Q-learning baselines but supplies no implementation details for the Q-learning baselines (hyper-parameter search, replay buffer size, or exact reward formulation), making it impossible to verify that the comparison is fair or that the distributional RL component is the source of the reported lift.
- PAC-Bayesian generalization bounds are invoked to certify the framework, yet the manuscript does not specify the prior distribution, the form of the posterior, or how the bound is evaluated on the eight memory units; without these choices the certification claim cannot be assessed.
minor comments (2)
- The abstract introduces the 62.5 % high-reliability classification metric without defining the reliability threshold or the decision rule used to obtain it.
- Notation for the IB trade-off coefficient and the CVaR risk level should be introduced once in the method section and used consistently thereafter.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate clarifications and additional experiments where needed.
read point-by-point responses
-
Referee: The headline worst-case guarantees (33.8 % / 38.2 %) rest on the claim that rate-distortion optimal IB latents preserve all information required for CVaR optimization. No ablation that varies the IB coefficient and re-measures worst-case improvement on the same 2.4 M waveforms is reported; without it the reported gains could be artifacts of tail-feature loss rather than genuine risk-sensitive optimization.
Authors: We agree that varying the IB coefficient β and re-evaluating worst-case performance on the full 2.4 M waveforms would strengthen the evidence that gains arise from risk-sensitive optimization rather than latent compression artifacts. In the revision we will add this ablation, reporting CVaR metrics across β ∈ {0.01, 0.1, 1.0, 10.0} to confirm robustness. revision: yes
-
Referee: The experimental section states 80.7 % / 89.1 % improvements over Q-learning baselines but supplies no implementation details for the Q-learning baselines (hyper-parameter search, replay buffer size, or exact reward formulation), making it impossible to verify that the comparison is fair or that the distributional RL component is the source of the reported lift.
Authors: We will add a new subsection detailing the Q-learning baselines: standard DQN with identical IB state representation and action space, reward defined as negative CVaR of eye opening, replay buffer size 100 000, and grid search over learning rates {1e-4, 5e-4, 1e-3} with the same training protocol. This ensures the comparison isolates the benefit of distributional RL. revision: yes
-
Referee: PAC-Bayesian generalization bounds are invoked to certify the framework, yet the manuscript does not specify the prior distribution, the form of the posterior, or how the bound is evaluated on the eight memory units; without these choices the certification claim cannot be assessed.
Authors: We will expand Section 4.3 to specify: prior is isotropic Gaussian N(0,I), posterior is mean-field variational approximation realized via Monte Carlo dropout, and the PAC-Bayes bound is computed on the empirical risk over the eight units with δ = 0.05, yielding the reported generalization certificate. These choices will be stated explicitly. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a framework combining standard distributional RL (quantile regression), CVaR optimization, information bottleneck compression, Monte Carlo dropout, and PAC-Bayesian bounds, with performance claims resting on experimental outcomes from 2.4 million waveforms rather than any self-referential equations or fitted inputs renamed as predictions. No load-bearing step reduces claimed improvements (e.g., 37.1% mean, 33.8% worst-case) to quantities defined by construction from the inputs themselves, and no self-citation chain or ansatz smuggling is invoked to justify uniqueness or core components. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rate-distortion optimal compression via information bottleneck preserves critical signal features for equalizer optimization
- domain assumption Monte Carlo dropout provides a reliable approximation to epistemic uncertainty
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem III.1 (Information Bottleneck Rate-Distortion Bound) ... LIB(φ,ψ,ω) = E[−log pω(y|z) + β log pφ(z|do)/qψ(z)]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem III.2 (Distributional Bellman Convergence) ... Wp(Zk,Zπ) ≤ γ^k Wp(Z0,Zπ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
K. Kim, H. Park, S. Kim, Y . Kim, K. Son, D. Lho, K. Son, T. Shin, B. Sim, J. Park, S. Park, and J. Kim, “Policy-based reinforcement learning for through silicon via array design in high-bandwidth memory considering signal integrity,” IEEE Transactions on Electromagnetic Compatibility, vol. 66, no. 1, pp. 130–140, 2024
work page 2024
-
[2]
K. Son, M. Kim, H. Park, D. Lho, K. Son, K. Kim, S. Lee, S. Jeong, S. Park, S. Hong, G. Park, and J. Kim, “Reinforcement-learning-based signal integrity optimization and analysis of a scalable 3-d x-point array structure,” IEEE Transactions on Components, Packaging, and Manufacturing Technology, vol. 12, no. 1, pp. 111–122, 2022
work page 2022
-
[3]
Decision feedback equalization,
C. Belfiore and J. Park, “Decision feedback equalization,” Proceedings of the IEEE, vol. 67, pp. 1143–1156, 1979. [Online]. Available: https://api.semanticscholar.org/CorpusID:42613982
work page 1979
-
[4]
Multilayer perceptron based decision feedback equalisers for channels with intersymbol interference,
M. Meyer and G. Pfeiffer, “Multilayer perceptron based decision feedback equalisers for channels with intersymbol interference,” IEE Proceedings I - Communications, Speech and Vision, vol. 140, no. 6, pp. 420–424, 1993
work page 1993
-
[5]
Invertible neural networks for inverse design of ctle in high-speed channels,
M. A. Dolatsara, H. Yu, J. A. Hejase, W. Dale Becker, and M. Swami- nathan, “Invertible neural networks for inverse design of ctle in high-speed channels,” in 2020 IEEE Electrical Design of Advanced Packaging and Systems (EDAPS), 2020, pp. 1–3
work page 2020
-
[6]
Rx equalization for a high-speed channel based on bayesian active learning using dropout,
X. Yang, J. Tang, H. M. Torun, W. D. Becker, J. A. Hejase, and M. Swami- nathan, “Rx equalization for a high-speed channel based on bayesian active learning using dropout,” in 2020 IEEE 29th Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), 2020, pp. 1–3
work page 2020
-
[7]
The soft-feedback equalizer for turbo equalization of highly dispersive channels,
R. Lopes and J. Barry, “The soft-feedback equalizer for turbo equalization of highly dispersive channels,” IEEE Transactions on Communications, vol. 54, no. 5, pp. 783–788, 2006
work page 2006
-
[8]
On low-complexity soft-input soft-output decision-feedback equalizers,
J. Tao, “On low-complexity soft-input soft-output decision-feedback equalizers,” IEEE Communications Letters, vol. 20, no. 9, pp. 1737– 1740, 2016
work page 2016
-
[9]
Equalization and fec techniques for optical transceivers,
K. Azadet, E. F. Haratsch, H. Kim, F. Saibi, J. H. Saunders, M. Shaffer, L. Song, and M. L. Yu, “Equalization and fec techniques for optical transceivers,” IEEE Journal of Solid-State Circuits, vol. 37, no. 3, pp. 317–327, 2002
work page 2002
-
[10]
S. U. H. Qureshi, “Adaptive equalization,” Proceedings of the IEEE, vol. 73, no. 9, pp. 1349–1387, 1985
work page 1985
-
[11]
J. G. Proakis and M. Salehi, Digital Communications, 5th ed. McGraw- Hill, 2007
work page 2007
-
[12]
S. Choi, K. Son, H. Park, S. Kim, B. Sim, J. Kim, J. Park, M. Kim, H. Kim, J. Song, Y . Kim, and J. Kim, “Deep reinforcement learning-based optimal and fast hybrid equalizer design method for high-bandwidth memory (hbm) module,” IEEE Transactions on Components, Packaging and Manufacturing Technology, vol. 13, no. 11, pp. 1804–1816, 2023
work page 2023
-
[13]
Transient simulation for high-speed channels with recurrent neural network,
T. Nguyen, T. Lu, J. Sun, Q. Le, K. We, and J. Schut-Aine, “Transient simulation for high-speed channels with recurrent neural network,” in 2018 IEEE 27th Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), 2018, pp. 303–305
work page 2018
-
[14]
Design of supervised and blind channel equalizer based on moth-flame optimization,
S. Nanda and S. Garg, “Design of supervised and blind channel equalizer based on moth-flame optimization,” Journal of The Institution of Engineers (India): Series B, vol. 100, pp. 21–31, 2018
work page 2018
-
[15]
Optimization of high-speed channel for signal integrity with deep genetic algorithm,
H. H. Zhang, Z. Xue, X. Liu, P. Li, L. Jiang, and G. M. Shi, “Optimization of high-speed channel for signal integrity with deep genetic algorithm,” IEEE Transactions on Electromagnetic Compatibility, vol. 64, pp. 1270–1274, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:248136122
work page 2022
-
[16]
L. P. P. B. Bohl, K. Scharff, X. Duan, D. Kaller, and C. Schuster, “Bayesian optimization of first-order continuous-time linear equalization in high-speed links including crosstalk,” 2023 IEEE 27th Workshop on Signal and Power Integrity (SPI), pp. 1–4, 2023
work page 2023
-
[17]
L. Wu, J. Zhou, H. Jiang, X. Yang, Y . Zhan, and Y . Zhang, “Predicting the characteristics of high-speed serial links based on a deep neural network (dnn)-transformer cascaded model,” Electronics, vol. 13, no. 15,
-
[18]
Available: https://www.mdpi.com/2079-9292/13/15/3064
[Online]. Available: https://www.mdpi.com/2079-9292/13/15/3064
work page 2079
-
[19]
Decision feedback equalizer (dfe) taps estimation with machine learning methods,
B. Shi, Y . Zhao, H. Ma, T. Nguyen, E. Li, A. C. Cangellaris, and J. E. Schutt-Ain´e, “Decision feedback equalizer (dfe) taps estimation with machine learning methods,” 2021 IEEE Electrical Design of Advanced Packaging and Systems (EDAPS), pp. 1–3, 2021. [Online]. Available: https://api.semanticscholar.org/CorpusID:245514140
work page 2021
-
[20]
A cnn-based one-shot blind rx-side-only equalization scheme for high-speed serdes links,
Y . Hui, Y . Nong, H. Ma, J. Lv, L. Chen, L. Du, and Y . Du, “A cnn-based one-shot blind rx-side-only equalization scheme for high-speed serdes links,” in 2024 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), 2024, pp. 61–65. [Online]. Available: https://doi.org/10.1109/AICAS59952.2024.10595918
-
[21]
Learning physical-layer communication with quantized feedback,
J. Song, B. Peng, C. H ¨ager, H. Wymeersch, and A. Sahai, “Learning physical-layer communication with quantized feedback,” IEEE Transactions on Communications, vol. 68, pp. 645–653, 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:125953653
work page 2019
-
[22]
Model-based end-to-end learning for wdm systems with transceiver hardware impairments,
J. Song, C. H ¨ager, J. Schr ¨oder, A. G. i Amat, and H. Wymeersch, “Model-based end-to-end learning for wdm systems with transceiver hardware impairments,” IEEE Journal of Selected Topics in Quantum Electronics, vol. 28, pp. 1–14, 2021. [Online]. Available: https: //api.semanticscholar.org/CorpusID:244714321
work page 2021
-
[23]
Autoencoding density-based anomaly detection for signal integrity applications,
R. Medico, D. Spina, D. VandeGinste, D. Deschrijver, and T. Dhaene, “Autoencoding density-based anomaly detection for signal integrity applications,” 2018 IEEE 27th Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), pp. 47–49, 2018
work page 2018
-
[24]
Machine-learning-based error detection and design optimization in signal integrity applications,
R. Medico, D. Spina, D. V . Ginste, D. Deschrijver, and T. Dhaene, “Machine-learning-based error detection and design optimization in signal integrity applications,” IEEE Transactions on Components, Packaging and Manufacturing Technology, vol. 9, pp. 1712–1720, 2019
work page 2019
-
[25]
D. Lho, H. Park, K. Kim, S. Kim, B. Sim, K. Son, K. Son, J. Kim, S. Choi, J. Park, H. Kim, K. Kong, and J. Kim, “Deterministic policy gradient-based reinforcement learning for DDR5 memory signaling architecture optimization considering signal integrity,” in 2022 IEEE 31st Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), 20...
work page 2022
-
[26]
——, “Deterministic policy gradient-based reinforcement learning for ddr5 memory signaling architecture optimization considering signal integrity,” in 2022 IEEE 31st Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), 2022, pp. 1–3
work page 2022
-
[27]
S. Choi, M. Kim, H. Park, K. Son, S. Kim, J. Kim, J. Park, H. Kim, T. Shin, K. Kim, and J. Kim, “Sequential policy network-based optimal passive equalizer design for an arbitrary channel of high bandwidth memory using advantage actor critic,” 2021 IEEE 30th Conference on Electrical Performance of Electronic Packaging and Systems (EPEPS), pp. 1–3, 2021. [O...
work page 2021
-
[28]
Representation learning: A review and new perspectives,
Y . Bengio, A. C. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, pp. 1798–1828, 2012
work page 2012
-
[29]
Deep reinforcement learning based dfe structure optimization for high-speed dram signals,
M. Usama, H.-D. Jang, and D. E. Chang, “Deep reinforcement learning based dfe structure optimization for high-speed dram signals,” IEEE Transactions on Components, Packaging and Manufacturing Technology, pp. 1–1, 2025, doi: 10.1109/TCPMT.2025.3648009
-
[30]
M. Usama and D. E. Chang, “Deep reinforcement learning-based dram equalizer parameter optimization using latent representations,” 2025. [Online]. Available: https://arxiv.org/abs/2507.02365
-
[31]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” Proceedings of the International Conference on Machine Learning, pp. 1050–1059, 2016
work page 2016
-
[32]
One-step distributional reinforcement learning,
M. Achab, R. ALAMI, Y . A. D. DJILALI, K. Fedyanin, and E. Moulines, “One-step distributional reinforcement learning,”Transactions on Machine Learning Research, 2023. [Online]. Available: https://openreview.net/ forum?id=ZPMf53vE1L
work page 2023
-
[33]
Offline rl without off-policy evaluation,
D. Brandfonbrener, W. F. Whitney, R. Ranganath, and J. Bruna, “Offline rl without off-policy evaluation,” inNeural Information Processing Systems,
-
[34]
Available: https://api.semanticscholar.org/CorpusID: 235446964
[Online]. Available: https://api.semanticscholar.org/CorpusID: 235446964
-
[35]
Towards robust neural networks with lipschitz continuity,
M. Usama and D. E. Chang, “Towards robust neural networks with lipschitz continuity,” in Digital Forensics and Watermarking: 17th International Workshop, IWDW 2018, Jeju Island, Korea, October 22-24, 2018, Proceedings 17. Springer, 2019, pp. 373–389
work page 2018
-
[36]
S. Choi, M. Kim, H. Park, H. R. Kim, J. Park, J. Kim, K. Son, S. Kim, K. Kim, D. Lho, J. Yoon, J. Song, K. Kim, J. Park, and J. Kim, “Deep reinforcement learning-based channel-flexible equalization scheme: An application to high bandwidth memory,” in DesignCon, 2022
work page 2022
-
[37]
Pyeye: An integrated approach for signal integrity assessment and eye diagram generation,
M. Usama and D. E. Chang, “Pyeye: An integrated approach for signal integrity assessment and eye diagram generation,” in 2023 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), 2023, pp. 1–3
work page 2023
-
[38]
Effectiveness of equalization and performance potential in DDR5 channels with RDIMM(s),
N. Na and H. To, “Effectiveness of equalization and performance potential in DDR5 channels with RDIMM(s),” in 2019 IEEE 69th Electronic Components and Technology Conference (ECTC). IEEE, 2019, pp. 1053–1059
work page 2019
-
[39]
LPDDR5 (6.4 gbps) 1-tap DFE optimal weight determi- nation,
S. R. Gupta, “LPDDR5 (6.4 gbps) 1-tap DFE optimal weight determi- nation,” in 2021 IEEE International Joint EMC/SI/PI and EMC Europe Symposium. IEEE, 2021, pp. 1–4
work page 2021
-
[40]
Deep varia- tional information bottleneck,
A. A. Alemi, I. Fischer, J. V . Dillon, and K. Murphy, “Deep varia- tional information bottleneck,” in International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[41]
R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, 1st ed. MIT Press, 1998
work page 1998
-
[42]
Y . Choi, “High speed DRAM transceiver design for low voltage applications with process and temperature variation-aware calibration,” Journal of Semiconductor Technology and Science, vol. 16, no. 1, pp. 1–10, 2016
work page 2016
-
[43]
Y . Qin, C. Lin, M. Lai, Z. Luo, S. Xu, and W. He, “Reducing DRAM latency via in-situ temperature- and process-variation-aware timing detection and adaption,” in Proceedings of the 61st ACM/IEEE Design Automation Conference (DAC), 2024, pp. 1–6
work page 2024
-
[44]
Robust estimation of a location parameter,
P. J. Huber, “Robust estimation of a location parameter,” Annals of Mathematical Statistics, vol. 35, no. 1, pp. 73–101, 1964
work page 1964
-
[45]
Sliced and radon wasserstein barycenters of measures,
N. Bonneel, J. Rabin, G. Peyr ´e, and H. Pfister, “Sliced and radon wasserstein barycenters of measures,” Journal of Mathematical Imaging and Vision, vol. 51, no. 1, pp. 22–45, 2015
work page 2015
-
[46]
Spectral normal- ization for generative adversarial networks,
T. Miyato, T. Kataoka, M. Koyama, and Y . Yoshida, “Spectral normal- ization for generative adversarial networks,” in International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[47]
Uncertainty estimation for deep learning-based pectoral muscle segmentation via Monte Carlo dropout,
ˇZ. Klane ˇcek, T. Wagner, Y .-K. Wang, L. Cockmartin, N. Marshall et al., “Uncertainty estimation for deep learning-based pectoral muscle segmentation via Monte Carlo dropout,” Physics in Medicine & Biology, vol. 68, no. 11, p. 115016, 2023
work page 2023
-
[48]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in International Conference on Learning Representations (ICLR), 2015
work page 2015
-
[49]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. M. O. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” CoRR, vol. abs/1509.02971, 2015. [Online]. Available: https://api.semanticscholar.org/CorpusID:16326763
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[50]
Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,
P. J. Rousseeuw, “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,” Journal of Computational and Applied Mathematics, vol. 20, pp. 53–65, 1987
work page 1987
-
[51]
L. van der Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of Machine Learning Research, vol. 9, no. 86, pp. 2579–2605, 2008
work page 2008
-
[52]
Neural architecture search with reinforcement learning,
B. Zoph and Q. V . Le, “Neural architecture search with reinforcement learning,” in International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[53]
DQNAS: Neu- ral architecture search using reinforcement learning,
A. Chauhan, S. Bhattacharyya, and S. Vadivel, “DQNAS: Neu- ral architecture search using reinforcement learning,” arXiv preprint arXiv:2301.06687, 2023
-
[54]
Gpflowopt: A bayesian optimization library using tensorflow,
N. Knudde, J. van der Herten, T. Dhaene, and I. Couckuyt, “Gpflowopt: A bayesian optimization library using tensorflow,”arXiv: Machine Learning,
-
[55]
Available: https://api.semanticscholar.org/CorpusID: 55544345
[Online]. Available: https://api.semanticscholar.org/CorpusID: 55544345
-
[56]
Y . Xu, L. Huang, W. Jiang, L. Xue, W. Hu, and L. Yi, “Automatic optimization of volterra equalizer with deep reinforcement learning for intensity-modulated direct-detection optical communications,” Journal of Lightwave Technology, vol. 40, pp. 5395–5406, 2022. [Online]. Available: https://api.semanticscholar.org/CorpusID:251325192
work page 2022
-
[57]
D. A. McAllester, “Pac-bayesian model averaging,” in Proceedings of the Twelfth Annual Conference on Computational Learning Theory (COLT). ACM, 1999, pp. 164–170. APPENDIX A. Genetic Algorithm Implementation Our genetic algorithm baseline optimizes the equalizer parameters using a population-based evolutionary approach. For the DFE configuration, it optim...
work page 1999
-
[58]
1 Nα Nα ∑ i=1 Ea∼πθ [θ ω i (s,a)] # = 1 Nα Es
=γW p(Z′ 1,Z ′ 2), where the second equality uses the translation invariance and scaling property of Wasserstein distance. Since γ<1 , T π is a contraction mapping. By the Banach fixed-point theorem, repeated application converges geometrically to the unique fixed point Zπ, yielding the exponential convergence rate in Equation (7). H. Proof of Theorem III...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.