Recognition: 1 theorem link
· Lean TheoremQuantum Hamlets: Distributed Compilation of Large Algorithmic Graph States
Pith reviewed 2026-05-15 15:14 UTC · model grok-4.3
The pith
A heuristic partitioning algorithm called BURY generates large algorithmic graph states across many quantum processors using fewer Bell pairs than existing methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The BURY heuristic solves balanced k-graph partitioning by minimizing the sizes of maximum matchings between partitions rather than the number of cut edges. This produces partitions that require fewer Bell pairs to generate the full graph state in a distributed setting. The same partitions also exhibit lower cut-rank, indicating that the entanglement cost would remain low even under improved future generation protocols. The approach extends to the dynamic case where generation and measurement occur concurrently.
What carries the argument
The BURY heuristic algorithm, which performs balanced k-partitioning of graph states by minimizing the sizes of maximum matchings between partitions to reduce required Bell pairs.
Load-bearing premise
That minimizing the sizes of the maximum matchings between partitions leads to lower entanglement requirements across partitions for algorithmic graph states in both static and dynamic generation on homogeneous processors.
What would settle it
A side-by-side execution of BURY and a leading k-partition algorithm on a large algorithmic graph state, followed by counting the actual Bell pairs consumed by a concrete distributed generation protocol on each set of partitions.
Figures



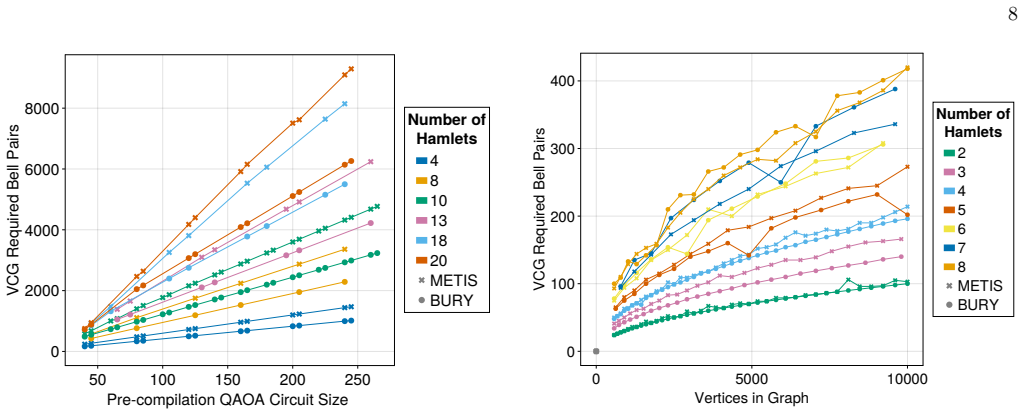


read the original abstract
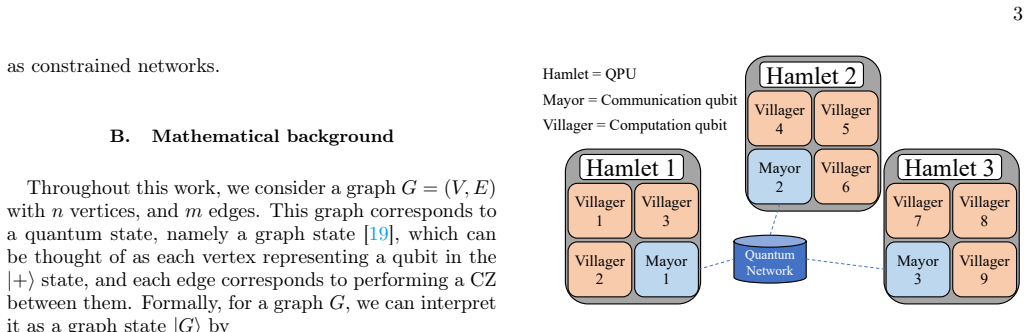
We investigate the problem of compiling the generation of graph states to arbitrarily many distributed homogeneous quantum processing units (QPUs), providing a scalable partitioning algorithm and graph state generation protocol to minimize the number of Bell pairs required. Current approaches focus on the naive metric of cut edges to estimate the quantum communication cost. We show that the problem of balanced k graph partitioning, with the objective of minimizing the sizes of the maximum matchings between the partitions, leads to lower entanglement requirements across partitions. Our heuristic algorithm, BURY, partitions graph states to require fewer Bell pairs for generation than state-of-the-art k partition algorithms. Furthermore, we show that BURY reduces the cut-rank of the partitions, demonstrating that the partitioning found by our algorithm is likely to minimize the Bell pair utilization of any future improved distributed graph state generation protocol. We also discuss how our methods apply to the dynamic case where the graph state generation and measurement are performed concurrently. Our compilation approach provides a scalable foundation for reducing quantum network overhead for distributed measurement-based quantum computation (MBQC), as well as any scheme where distributed graph state generation is desired.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BURY, a heuristic algorithm for balanced k-partitioning of algorithmic graph states across distributed homogeneous QPUs. It claims that minimizing the sizes of maximum matchings between partitions yields lower Bell-pair requirements than state-of-the-art k-partition methods, additionally reduces cut-rank (suggesting optimality for future protocols), and extends to both static and dynamic generation scenarios for measurement-based quantum computation.
Significance. If the reported reductions hold under the actual generation protocol, the work would provide a practical, scalable improvement over cut-edge-based partitioning for reducing entanglement overhead in distributed MBQC and related graph-state applications.
major comments (2)
- [Abstract] The central claim that minimizing maximum matching sizes between partitions directly produces fewer Bell pairs is not derived from the protocol mechanics; without an explicit accounting of entanglement consumption (including possible re-use, fusion, or measurement-based adjustments), the reduction in matching size may not translate to commensurate Bell-pair savings (Abstract and protocol description).
- [Abstract] No quantitative results, Bell-pair counts, cut-rank values, or error analysis are supplied to support the superiority claim over SOTA k-partition algorithms, preventing verification of the reported improvements (Abstract).
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the two major comments point by point below. Both concerns can be resolved through targeted revisions that clarify the protocol derivation and incorporate quantitative results into the abstract.
read point-by-point responses
-
Referee: [Abstract] The central claim that minimizing maximum matching sizes between partitions directly produces fewer Bell pairs is not derived from the protocol mechanics; without an explicit accounting of entanglement consumption (including possible re-use, fusion, or measurement-based adjustments), the reduction in matching size may not translate to commensurate Bell-pair savings (Abstract and protocol description).
Authors: We agree that the link between maximum matching size and Bell-pair count requires an explicit derivation for full transparency. In the manuscript the distributed generation protocol is constructed so that the entanglement cost equals the size of the maximum matching: each edge in the matching corresponds to a dedicated Bell pair that must be consumed to realize the cut edges of the algorithmic graph state, with no reuse or fusion possible under the simultaneous-generation constraint of the MBQC protocol. We will revise the abstract to state this accounting explicitly and add a short derivation subsection in the protocol description that rules out reuse/fusion adjustments for this setting. revision: yes
-
Referee: [Abstract] No quantitative results, Bell-pair counts, cut-rank values, or error analysis are supplied to support the superiority claim over SOTA k-partition algorithms, preventing verification of the reported improvements (Abstract).
Authors: Quantitative comparisons of Bell-pair counts, cut-rank values, and heuristic error bounds versus standard k-partition baselines appear in Sections 4 and 5. To allow immediate verification from the abstract we will insert a concise summary sentence reporting the observed average reductions (e.g., X % fewer Bell pairs and Y % lower cut-rank on the benchmark suite). revision: yes
Circularity Check
No significant circularity: claims rest on explicit protocol and external SOTA comparisons
full rationale
The paper introduces BURY as a heuristic for balanced k-partitioning whose objective (minimize max matching sizes) is motivated by and directly implemented in the provided graph-state generation protocol. Lower Bell-pair counts are demonstrated via comparison to external state-of-the-art partitioners rather than by fitting parameters or self-referential equations. No self-citations are load-bearing, no ansatz is smuggled, and no derivation reduces to its own inputs by construction. The central claim therefore remains independent of the algorithm's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Graph states are generated via controlled-Z gates along graph edges and can be distributed using Bell pairs for inter-partition connections.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our heuristic algorithm, BURY, partitions graph states to require fewer Bell pairs for generation than state-of-the-art k partition algorithms. Furthermore, we show that BURY reduces the cut-rank of the partitions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Space-Time Tradeoffs of Pauli-Based Computation in Distributed qLDPC Architectures
Large qLDPC blocks in distributed quantum computing enable Pauli-based computation to run up to 10x faster than surface codes for optimization algorithms by using spare nodes to bypass serialization bottlenecks.
Reference graph
Works this paper leans on
-
[1]
using a Game of Surface Codes [11] style abstraction. As the spatial cost of generating graph states scales with its path width [6], even in the most optimized MBQC model of computation, in order to realize large al- gorithmic graph states, scheduling the generation of such states in a distributed setting is an essential and underex- plored area of resear...
-
[2]
[30]. To generalize this “bury heuristic” approach tokpar- tition, we simply run Algorithm 1 withr= n k, then 3 23 3 3 44 233555 44 r=53 3 44 3 3 44 445555 44 r=8Bury top left FIG. 3.Example first step of the bury heuristic al- gorithm on a4×4grid graph.On the left, the weights of the nodes are initialized to be equal to their degree plus one. The right s...
work page 2000
- [3]
-
[4]
Optimized compiler for distributed quantum computing,
D. Cuomo, M. Caleffi, K. Krsulich, F. Tramonto, G. Agliardi, E. Prati, and A. S. Cacciapuoti, ACM Trans- actions on Quantum Computing4, 10.1145/3579367 (2023)
- [5]
-
[6]
H. J. Briegel, D. E. Browne, W. Dür, R. Raussendorf, and M. Van den Nest, Nature Physics5, 19 (2009)
work page 2009
-
[7]
M. Krishnan Vijayan, A. Paler, J. Gavriel, C. R. My- ers, P. P. Rohde, and S. J. Devitt, Quantum Science and Technology9, 025005 (2024)
work page 2024
-
[8]
S. J. Elman, J. Gavriel, and R. L. Mann, Physical Review A111, 10.1103/physreva.111.012627 (2025)
-
[9]
B. W. Kernighan and S. Lin, The Bell System Technical Journal49, 291 (1970)
work page 1970
-
[10]
G. Karypis and V. Kumar, Journal of Parallel and Dis- tributed Computing48, 96 (1998)
work page 1998
- [11]
-
[12]
S. Liu, N. Benchasattabuse, D. Q. Morgan, M. Hajdušek, S. J. Devitt, and R. Van Meter, in2023 IEEE Interna- tional Conference on Quantum Computing and Engineer- ing (QCE)(IEEE, 2023) p. 870–880
work page 2023
- [13]
-
[14]
C. Meignant, D. Markham, and F. Grosshans, Phys. Rev. A100, 052333 (2019)
work page 2019
-
[15]
A. Fischer and D. Towsley, in2021 IEEE International Conference on Quantum Computing and Engineering (QCE)(2021) pp. 324–333
work page 2021
- [16]
- [17]
-
[18]
R. Satoh,Resource Allocation Policy for Noisy Dis- tributed Quantum Computing, Bachelor’s thesis, Keio University Faculty of Environment and Information Studies (2020)
work page 2020
- [19]
-
[20]
Entanglement in the stabilizer formalism
D. Fattal, T. S. Cubitt, Y. Yamamoto, S. Bravyi, and I. L. Chuang, Entanglement in the stabilizer formalism (2004), arXiv:quant-ph/0406168 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[21]
M. Hein, W. Dür, J. Eisert, R. Raussendorf, M. V. den Nest,andH.J.Briegel,Entanglementingraphstatesand its applications (2006), arXiv:quant-ph/0602096 [quant- ph]
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[22]
H. J. Kimble, Nature453, 1023 (2008). 11
work page 2008
-
[23]
S. Wehner, D. Elkouss, and R. Han- son, Science362, eaam9288 (2018), https://www.science.org/doi/pdf/10.1126/science.aam9288
-
[24]
D. Main, P. Drmota, D. P. Nadlinger, E. M. Ainley, A. Agrawal, B. C. Nichol, R. Srinivas, G. Araneda, and D. M. Lucas, Nature638, 383 (2025)
work page 2025
-
[25]
H. Saran and V. Vazirani, in[1991] Proceedings 32nd Annual Symposium of Foundations of Computer Science (1991) pp. 743–751
work page 1991
-
[26]
K. Andreev and H. Räcke, inProceedings of the Sixteenth Annual ACM Symposium on Parallelism in Algorithms and Architectures, SPAA ’04 (Association for Computing Machinery, New York, NY, USA, 2004) p. 120–124
work page 2004
-
[27]
M. R. Garey and D. S. Johnson,Computers and In- tractability: A Guide to the Theory of NP-Completeness (Series of Books in the Mathematical Sciences), first edi- tion ed. (W. H. Freeman, 1979)
work page 1979
-
[28]
G. Szárnyas, Graphs and matrices: A translation of “graphok es matrixok” by dénes kőnig (1931) (2020), arXiv:2009.03780 [math.HO]
-
[29]
J. E. Hopcroft and R. M. Karp, SIAM Journal on Com- puting2, 225 (1973), https://doi.org/10.1137/0202019
-
[30]
C. Konrad, A. McGregor, R. Sengupta, and C. Than, in44th IARCS Annual Conference on Foundations of Software Technology and Theoretical Computer Science (FSTTCS 2024), Leibniz International Proceedings in Informatics (LIPIcs), Vol. 323, edited by S. Barman and S. Lasota (Schloss Dagstuhl – Leibniz-Zentrum für Infor- matik, Dagstuhl, Germany, 2024) pp. 29:1...
work page 2024
- [31]
-
[32]
G. Karypis and V. Kumar,METIS: A Software Pack- age for Partitioning Unstructured Graphs, Partition- ing Meshes, and Computing Fill-Reducing Orderings of Sparse Matrices(1997)
work page 1997
-
[33]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, A quan- tum approximate optimization algorithm (2014), arXiv:1411.4028 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
S. Sunami and M. Fukushima, Graphix: optimizing and simulating measurement-based quantum computation on local-clifford decorated graph (2022), arXiv:2212.11975 [quant-ph]
-
[35]
J. Fairbanks, M. Besançon, S. Simon, J. Hoffiman, N. Eu- bank, and S. Karpinski, Juliagraphs/graphs.jl: an opti- mizedgraphspackageforthejuliaprogramminglanguage (2021)
work page 2021
- [36]
-
[37]
D. E. Browne, E. Kashefi, M. Mhalla, and S. Perdrix, New Journal of Physics9, 250 (2007)
work page 2007
- [38]
-
[39]
First, to define cut rank, we consider a cut as a subset of edgesC⊆Eof some graphG= (V, E)
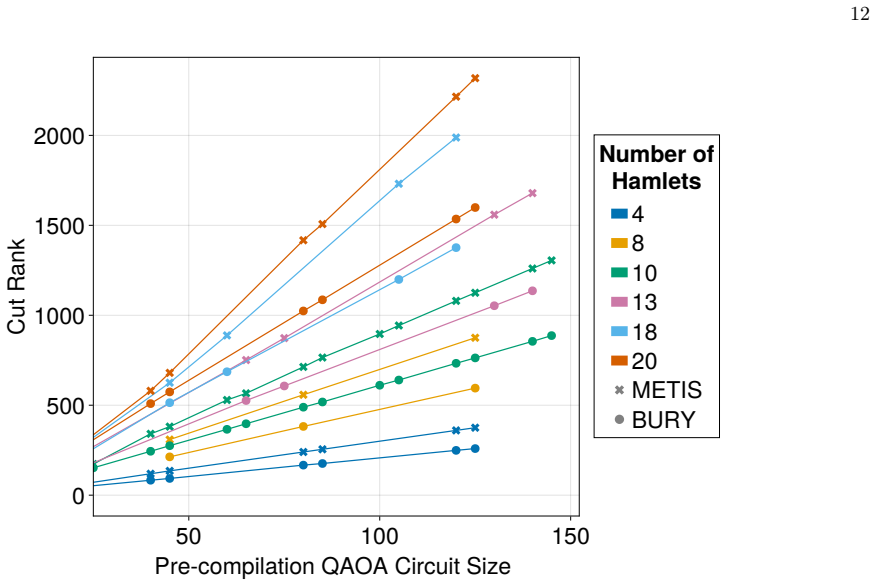
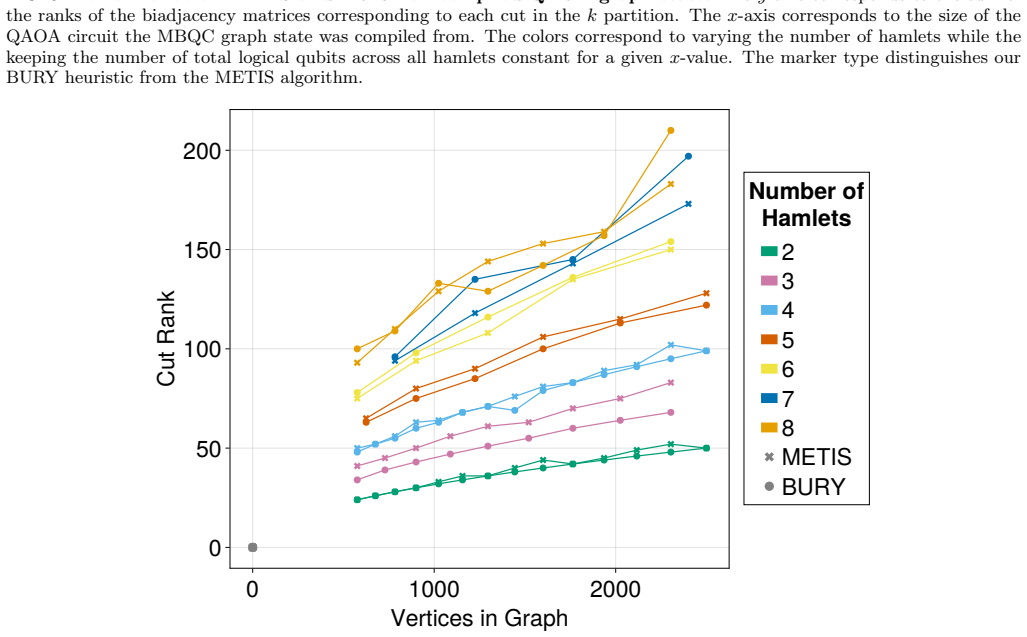
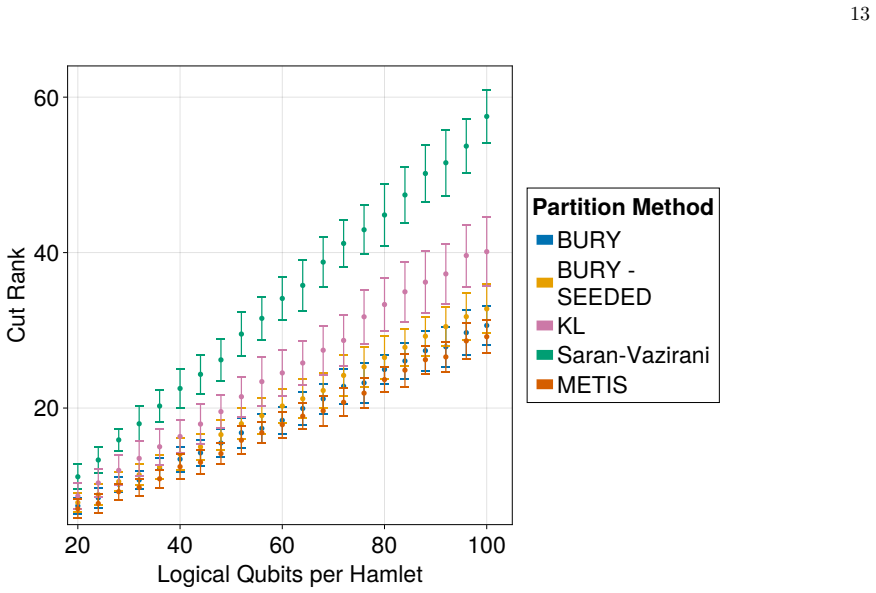
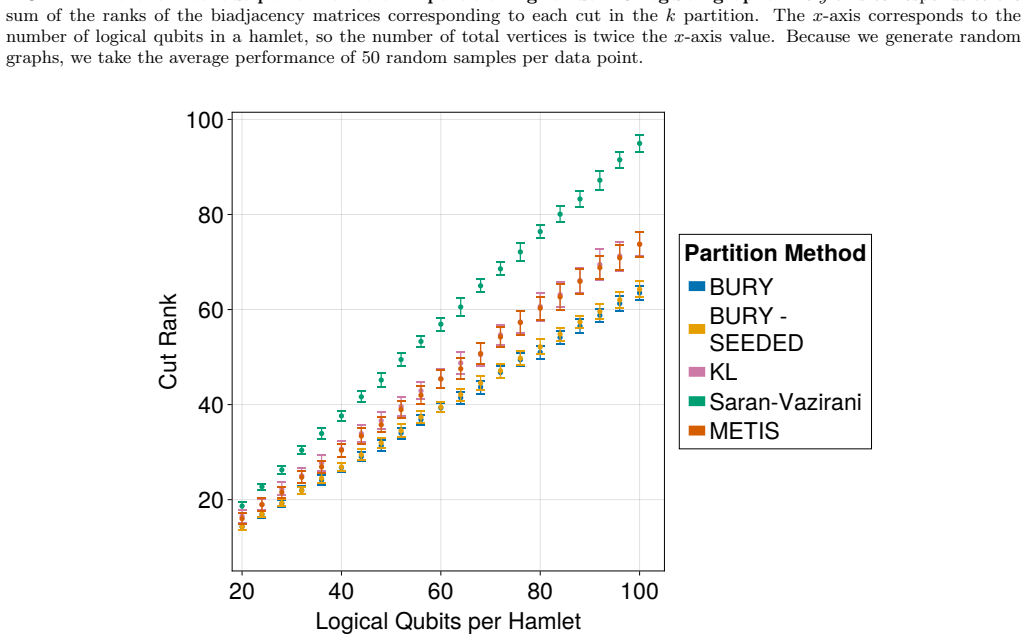
Performance on Cut Rank Here we show provide plots and discuss how our BURY algorithm also outperforms existing methods forkparti- tion when evaluated on the metric of cut rank. First, to define cut rank, we consider a cut as a subset of edgesC⊆Eof some graphG= (V, E). Then, we con- sider the adjacency matrix,A, representing edge-induced subgraphH= (V ′, ...
work page 2000
-
[40]
yes” instance of BCM iff(G, k) is a “yes
NP Completeness We consider the following three decision problems: 1.Minimum Balanced Cut-Matching (BCM).Given an undirected graphG= (V, E)integerk, does there exist a partitionV=A∪Bsuch that |A|=|B|=|V|/2andν(E(A, B))≤kwhere E(A, B)are the edges crossing(A, B)andν(·)de- notes maximum matching size. 2.Minimum Balanced Vertex Separator (BVS).Given an undir...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.