Obliviator Reveals the Cost of Nonlinear Guardedness in Concept Erasure
Pith reviewed 2026-05-15 14:51 UTC · model grok-4.3
The pith
Obliviator erases unwanted attributes from representations using gradual kernel optimization to resist nonlinear adversaries while losing less task utility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Obliviator formulates concept erasure as the search for a transformation that neutralizes nonlinear dependencies via compositions of kernels, then solves it by successive small adjustments to the feature space rather than a single closed-form step. This gradual morphing both guards the unwanted attribute against nonlinear adversaries and makes the cost of that protection visible as a smooth curve relating erasure strength to retained utility.
What carries the argument
Iterative optimization over compositions of kernels that gradually morphs the feature space to neutralize nonlinear statistical dependencies.
If this is right
- The utility-erasure trade-off becomes measurable at every step of the process rather than only at the end.
- Post-hoc application to already-trained representations yields stronger protection against nonlinear attacks than one-shot linear or adversarial baselines.
- Representations learned by more capable models become easier to erase with less utility loss once Obliviator is applied.
- The same gradual procedure can be used to compare different starting representations by how much utility they retain after equivalent erasure.
Where Pith is reading between the lines
- Gradual nonlinear erasure may generalize to other post-processing fairness interventions where only the final representation is accessible.
- The observed trade-off curves could serve as a diagnostic for how well any given representation has already disentangled the target attribute.
- If the kernel-composition iteration converges reliably, the method offers a practical way to audit black-box models for residual nonlinear leakage.
Load-bearing premise
Iterative optimization over kernel compositions can capture and remove all nonlinear dependencies between the representation and the unwanted attribute without creating new artifacts that reduce utility.
What would settle it
Train a deep nonlinear classifier on the Obliviator-processed representations and observe whether it can still recover the unwanted attribute at accuracy significantly above chance.
Figures







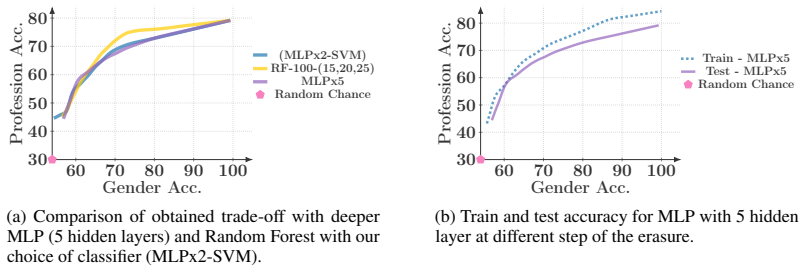
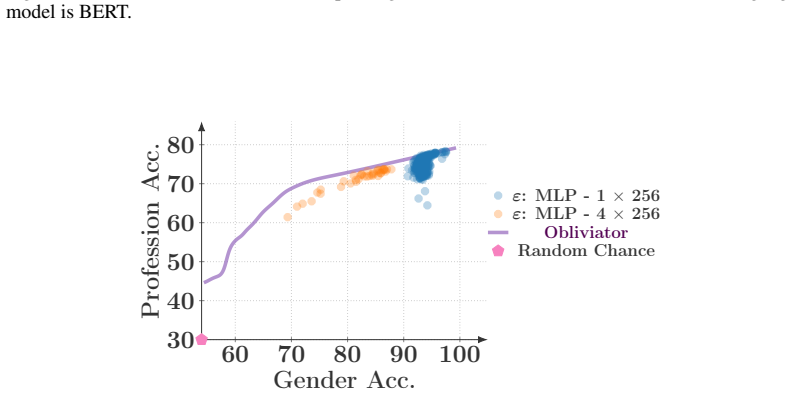


read the original abstract
Concept erasure aims to remove unwanted attributes, such as social or demographic factors, from learned representations, while preserving their task-relevant utility. While the goal of concept erasure is protection against all adversaries, existing methods remain vulnerable to nonlinear ones. This vulnerability arises from their failure to fully capture the complex, nonlinear statistical dependencies between learned representations and unwanted attributes. Moreover, although the existence of a trade-off between utility and erasure is expected, its progression during the erasure process, i.e., the cost of erasure, remains unstudied. In this work, we introduce Obliviator, a post-hoc erasure method designed to fully capture nonlinear statistical dependencies. We formulate erasure from a functional perspective, leading to an optimization problem involving a composition of kernels that lacks a closed-form solution. Instead of solving this problem in a single shot, we adopt an iterative approach that gradually morphs the feature space to achieve a more utility-preserving erasure. Unlike prior methods, Obliviator guards unwanted attribute against nonlinear adversaries. Our gradual approach quantifies the cost of nonlinear guardedness and reveals the dynamics between attribute protection and utility-preservation over the course of erasure. The utility-erasure trade-off curves obtained by Obliviator outperform the baselines and demonstrate its strong generalizability: its erasure becomes more utility-preserving when applied to the better-disentangled representations learned by more capable models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Obliviator, a post-hoc concept erasure method that formulates the problem from a functional perspective as an optimization over compositions of kernels lacking a closed-form solution. It proposes an iterative gradual-morphing procedure to capture and neutralize nonlinear statistical dependencies between representations and unwanted attributes, thereby guarding against nonlinear adversaries. The approach is claimed to quantify the cost of nonlinear guardedness via utility-erasure trade-off curves that outperform baselines and exhibit improved utility preservation when applied to better-disentangled representations from more capable models.
Significance. If the central claims hold, the work would be significant for advancing concept erasure beyond linear methods by addressing nonlinear dependencies and for introducing a gradual procedure that explicitly tracks the dynamics and cost of the utility-erasure trade-off. The functional kernel-composition view and emphasis on generalizability to stronger base models represent a useful contribution to the literature on representation debiasing.
major comments (2)
- [§3] §3: The iterative gradual-morphing procedure is asserted to fully capture and neutralize nonlinear statistical dependencies, yet the manuscript provides no proof that the iteration converges to the global optimum of the kernel-composition objective nor any bound demonstrating that intermediate feature-space morphs do not introduce new higher-order dependencies between the transformed representation and the unwanted attribute. This directly undermines the claim that Obliviator guards against nonlinear adversaries.
- [Experimental section] Experimental evaluation: The abstract and reported claims of outperformance on utility-erasure trade-off curves lack explicit details on experimental controls, error bars, data splits, exact baseline implementations, and statistical significance testing. Without these, the support for the central empirical claims remains limited.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on both the theoretical grounding and experimental details. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [§3] §3: The iterative gradual-morphing procedure is asserted to fully capture and neutralize nonlinear statistical dependencies, yet the manuscript provides no proof that the iteration converges to the global optimum of the kernel-composition objective nor any bound demonstrating that intermediate feature-space morphs do not introduce new higher-order dependencies between the transformed representation and the unwanted attribute. This directly undermines the claim that Obliviator guards against nonlinear adversaries.
Authors: We acknowledge that the current manuscript does not include a formal proof of convergence to the global optimum of the kernel-composition objective or explicit bounds preventing the introduction of new higher-order dependencies during intermediate morphs. The iterative procedure is motivated as a practical, gradual approximation to the non-convex optimization problem that lacks a closed-form solution. In the revision we will update §3 to explicitly qualify the method as an empirical heuristic rather than a provably optimal procedure, add plots of the objective value across iterations to demonstrate practical convergence behavior, and include additional nonlinear probing results on the final representations to show that detectable dependencies are neutralized. We maintain that the empirical trade-off curves and outperformance against nonlinear adversaries provide supporting evidence, but we will tone down the claim of fully capturing all nonlinear dependencies to reflect the lack of theoretical guarantees. revision: partial
-
Referee: [Experimental section] Experimental evaluation: The abstract and reported claims of outperformance on utility-erasure trade-off curves lack explicit details on experimental controls, error bars, data splits, exact baseline implementations, and statistical significance testing. Without these, the support for the central empirical claims remains limited.
Authors: We agree that the experimental section requires substantially more detail to support the reported claims. In the revised manuscript we will expand the experimental protocol to specify exact data splits (including train/validation/test ratios and any stratification), report error bars as mean ± standard deviation over five independent random seeds, provide precise implementation details and hyperparameter settings for all baselines (with links to public code where available), and include statistical significance testing (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) for the observed improvements on the utility-erasure curves. These additions will appear in the main experimental section and an expanded appendix. revision: yes
Circularity Check
No significant circularity; claims rest on independent experimental comparisons
full rationale
The paper formulates erasure as a kernel-composition optimization lacking closed form, then solves via iterative gradual morphing. This construction does not reduce any claimed result to its inputs by definition, nor rename a fitted parameter as a prediction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to bear the central load. Utility-erasure curves and nonlinear guarding claims are supported by direct comparisons to baselines on disentangled representations, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Nonlinear statistical dependencies between learned representations and unwanted attributes exist and are not captured by existing linear erasure methods.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
formulate erasure from a functional perspective, leading to an optimization problem involving a composition of kernels that lacks a closed-form solution... iterative approach that gradually morphs the feature space... HSIC(F,G, pZθ,S) = 0
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Obliviator guards unwanted attribute against nonlinear adversaries... utility-erasure trade-off curves
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Adversarial scrubbing of demographic information for text classification
Somnath Basu Roy Chowdhury, Sayan Ghosh, Yiyuan Li, Junier Oliva, Shashank Srivastava, and Snigdha Chaturvedi. Adversarial scrubbing of demographic information for text classification. InConference on Empirical Methods in Natural Language Processing, 2021
work page 2021
-
[2]
Robust concept erasure via kernelized rate-distortion maximization
Somnath Basu Roy Chowdhury, Nicholas Monath, Kumar Avinava Dubey, Amr Ahmed, and Snigdha Chaturvedi. Robust concept erasure via kernelized rate-distortion maximization. Advances in Neural Information Processing Systems, 2023
work page 2023
-
[3]
Nora Belrose, David Schneider-Joseph, Shauli Ravfogel, Ryan Cotterell, Edward Raff, and Stella Biderman. Leace: Perfect linear concept erasure in closed form.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[4]
Demographic dialectal variation in social media: A case study of African-American English
Su Lin Blodgett, Lisa Green, and Brendan O’Connor. Demographic dialectal variation in social media: A case study of African-American English. InConference on Empirical Methods in Natural Language Processing, 2016
work page 2016
-
[5]
Tolga Bolukbasi, Kai-Wei Chang, James Y Zou, Venkatesh Saligrama, and Adam T Kalai. Man is to computer programmer as woman is to homemaker? debiasing word embeddings.Advances in Neural Information Processing Systems, 29, 2016
work page 2016
-
[6]
Somnath Basu Roy Chowdhury and Snigdha Chaturvedi. Learning fair representations via rate-distortion maximization.Transactions of the Association for Computational Linguistics, 10:1159–1174, 2022
work page 2022
-
[7]
Robust concept erasure via kernelized rate-distortion maximization
Somnath Basu Roy Chowdhury, Nicholas Monath, Kumar Avinava Dubey, Amr Ahmed, and Snigdha Chaturvedi. Robust concept erasure via kernelized rate-distortion maximization. In Advances in Neural Information Processing Systems, 2023
work page 2023
-
[8]
Bias in bios: A case study of semantic representation bias in a high-stakes setting
Maria De-Arteaga, Alexey Romanov, Hanna Wallach, Jennifer Chayes, Christian Borgs, Alexan- dra Chouldechova, Sahin Geyik, Krishnaram Kenthapadi, and Adam Tauman Kalai. Bias in bios: A case study of semantic representation bias in a high-stakes setting. InConference on Fairness, Accountability, and Transparency, 2019
work page 2019
-
[9]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
DeepSeek-AI. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954, 2024. URL https://github.com/deepseek-ai/ DeepSeek-LLM
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Utility-fairness trade-offs and how to find them
Sepehr Dehdashtian, Bashir Sadeghi, and Vishnu Naresh Boddeti. Utility-fairness trade-offs and how to find them. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[11]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics, 2019
work page 2019
-
[12]
Censoring representations with an adversary
Harrison Edwards and Amos Storkey. Censoring representations with an adversary. InInterna- tional Conference on Learning Representations, 2016
work page 2016
-
[13]
Adversarial removal of demographic attributes from text data
Yanai Elazar and Yoav Goldberg. Adversarial removal of demographic attributes from text data. InConference on Empirical Methods in Natural Language Processing, 2018
work page 2018
-
[14]
Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad Rahwan, and Sune Lehmann. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. InConference on Empirical Methods in Natural Language Processing, 2017
work page 2017
-
[15]
Hila Gonen and Yoav Goldberg. Lipstick on a pig: Debiasing methods cover up systematic gender biases in word embeddings but do not remove them. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics, 2019
work page 2019
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Measuring statistical dependence with hilbert-schmidt norms
Arthur Gretton, Olivier Bousquet, Alex Smola, and Bernhard Schölkopf. Measuring statistical dependence with hilbert-schmidt norms. InInternational Conference on Algorithmic Learning Theory, 2005
work page 2005
-
[18]
Kernel methods for measuring independence.Journal of Machine Learning Research, 6(12), 2005
Arthur Gretton, Ralf Herbrich, Alexander Smola, Olivier Bousquet, Bernhard Schölkopf, and Aapo Hyvärinen. Kernel methods for measuring independence.Journal of Machine Learning Research, 6(12), 2005
work page 2005
-
[19]
Yazhe Li, Roman Pogodin, Danica J Sutherland, and Arthur Gretton. Self-supervised learning with kernel dependence maximization.Advances in Neural Information Processing Systems, 34:15543–15556, 2021
work page 2021
-
[20]
Towards robust and privacy-preserving text representations
Yitong Li, Timothy Baldwin, and Trevor Cohn. Towards robust and privacy-preserving text representations. InAnnual Meeting of the Association for Computational Linguistics, 2018
work page 2018
-
[21]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-perfo...
work page 2019
-
[22]
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. Glove: Global vectors for word representation. InConference on Empirical Methods in Natural Language Processing, 2014
work page 2014
-
[23]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019
work page 2019
-
[24]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. 2007
work page 2007
-
[25]
Sebastian Raschka, Joshua Patterson, and Corey Nolet. Machine learning in python: Main developments and technology trends in data science, machine learning, and artificial intelligence. arXiv preprint arXiv:2002.04803, 2020
-
[26]
Null it out: Guarding protected attributes by iterative nullspace projection
Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, and Yoav Goldberg. Null it out: Guarding protected attributes by iterative nullspace projection. InAnnual Meeting of the Association for Computational Linguistics, 2020
work page 2020
-
[27]
Linear adversarial concept erasure
Shauli Ravfogel, Michael Twiton, Yoav Goldberg, and Ryan D Cotterell. Linear adversarial concept erasure. InInternational Conference on Machine Learning, 2022
work page 2022
-
[28]
Adversarial concept erasure in kernel space
Shauli Ravfogel, Francisco Vargas, Yoav Goldberg, and Ryan Cotterell. Adversarial concept erasure in kernel space. InConference on Empirical Methods in Natural Language Processing, 2022
work page 2022
-
[29]
Bashir Sadeghi, Sepehr Dehdashtian, and Vishnu Boddeti. On characterizing the trade-off in invariant representation learning.Transactions in Machine Learning Research, 2022. ISSN 2835-
work page 2022
-
[30]
URLhttps://openreview.net/forum?id=3gfpBR1ncr. Featured Certification
-
[31]
Shun Shao, Yftah Ziser, and Shay B. Cohen. Gold doesn‘t always glitter: Spectral removal of linear and nonlinear guarded attribute information. InConference of the European Chapter of the Association for Computational Linguistics, 2023
work page 2023
-
[32]
Twisty: a multilingual twitter stylometry corpus for gender and personality profiling
Ben Verhoeven, Walter Daelemans, and Barbara Plank. Twisty: a multilingual twitter stylometry corpus for gender and personality profiling. InInternational Conference on Language Resources and Evaluation, 2016
work page 2016
-
[33]
Dynamically disen- tangling social bias from task-oriented representations with adversarial attack
Liwen Wang, Yuanmeng Yan, Keqing He, Yanan Wu, and Weiran Xu. Dynamically disen- tangling social bias from task-oriented representations with adversarial attack. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics, 2021
work page 2021
-
[34]
Rich Zemel, Yu Wu, Kevin Swersky, Toni Pitassi, and Cynthia Dwork. Learning fair representa- tions. InInternational Conference on Machine Learning, 2013. 12 Supplementary Material for Obliviator This supplementary material provides additional details to support the main paper. It includes mathematical proofs, implementation specifics, ablation studies, an...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.