Recognition: 2 theorem links
· Lean TheoremFast Single Nitrogen-Vacancy Center Ramsey Characterization using a Physics-Informed Neural Network
Pith reviewed 2026-05-15 10:50 UTC · model grok-4.3
The pith
A physics-informed neural network reconstructs clean Ramsey waveforms from noisy minimal-sweep data on single NV centers and estimates their hyperfine couplings to 13C spins, achieving up to 40 times faster measurements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
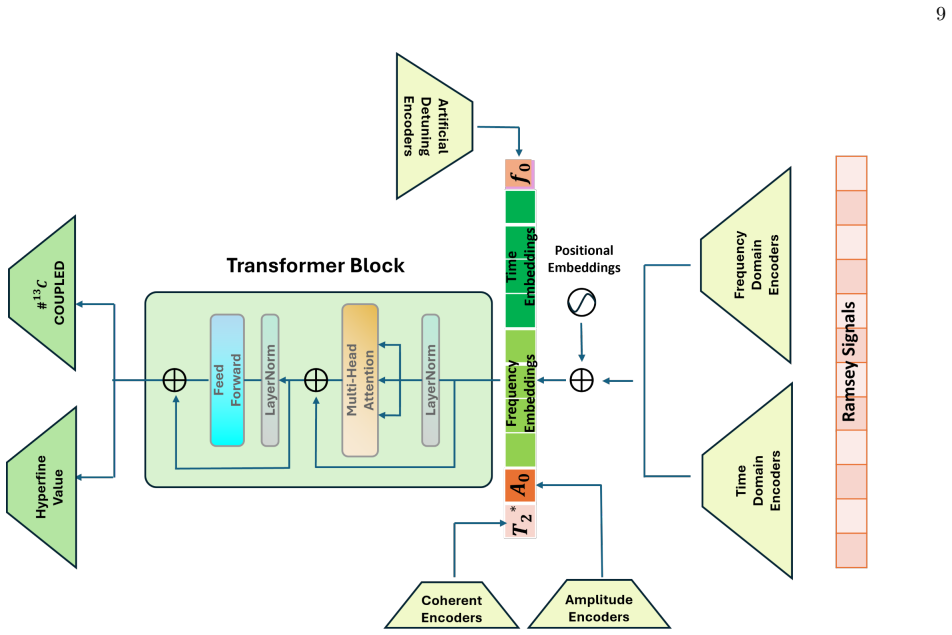
NVRNet is a physics-informed simulation-to-reality pipeline that employs a two-stage time-frequency U-Net denoiser augmented with an attention-based time-domain U-Net, pretrained on Hamiltonian spin simulations with calibrated noise, and uses parameter-efficient adapters fine-tuned on experimental data. A subsequent transformer extracts hyperfine parameters. Across three NV centers the fine-tuned model reduces median reconstruction error on held-out few-sweep traces to 0.44-0.67 times the experimental noise level, with normalized FFT errors of 0.10-0.19, supporting up to 40x faster Ramsey characterization.
What carries the argument
NVRNet pipeline: a U-Net based denoiser pretrained on simulated Ramsey signals from NV spin Hamiltonians and adapted via parameter-efficient fine-tuning to real data, paired with a transformer estimator for 13C hyperfine parameters.
If this is right
- Fewer sweeps suffice to obtain usable data for hyperfine inference, directly cutting acquisition time.
- Denoised waveforms and parameter estimates allow reliable forward modeling that reproduces key experimental signatures.
- High-throughput screening of NV centers for quantum applications becomes practical.
- The method provides a hardware-compatible path for autonomous characterization without extensive post-processing.
Where Pith is reading between the lines
- Similar simulation-to-reality adapter strategies could accelerate characterization in other quantum sensing platforms like superconducting qubits or trapped ions.
- The reduced data needs might allow measurements in shorter total times, minimizing sensitivity to slow drifts in the apparatus.
- Extending the pipeline to include more complex spin environments or multi-qubit interactions would be a natural next step for broader applicability.
Load-bearing premise
The simulation-trained model can be adapted to match real NV center data sufficiently well using only small amounts of experimental data to tune lightweight adapters without retraining the entire network.
What would settle it
Run the adapted model on a new held-out set of few-sweep Ramsey traces from an NV center and verify if the median error stays below the raw experimental noise level as reported.
Figures












read the original abstract
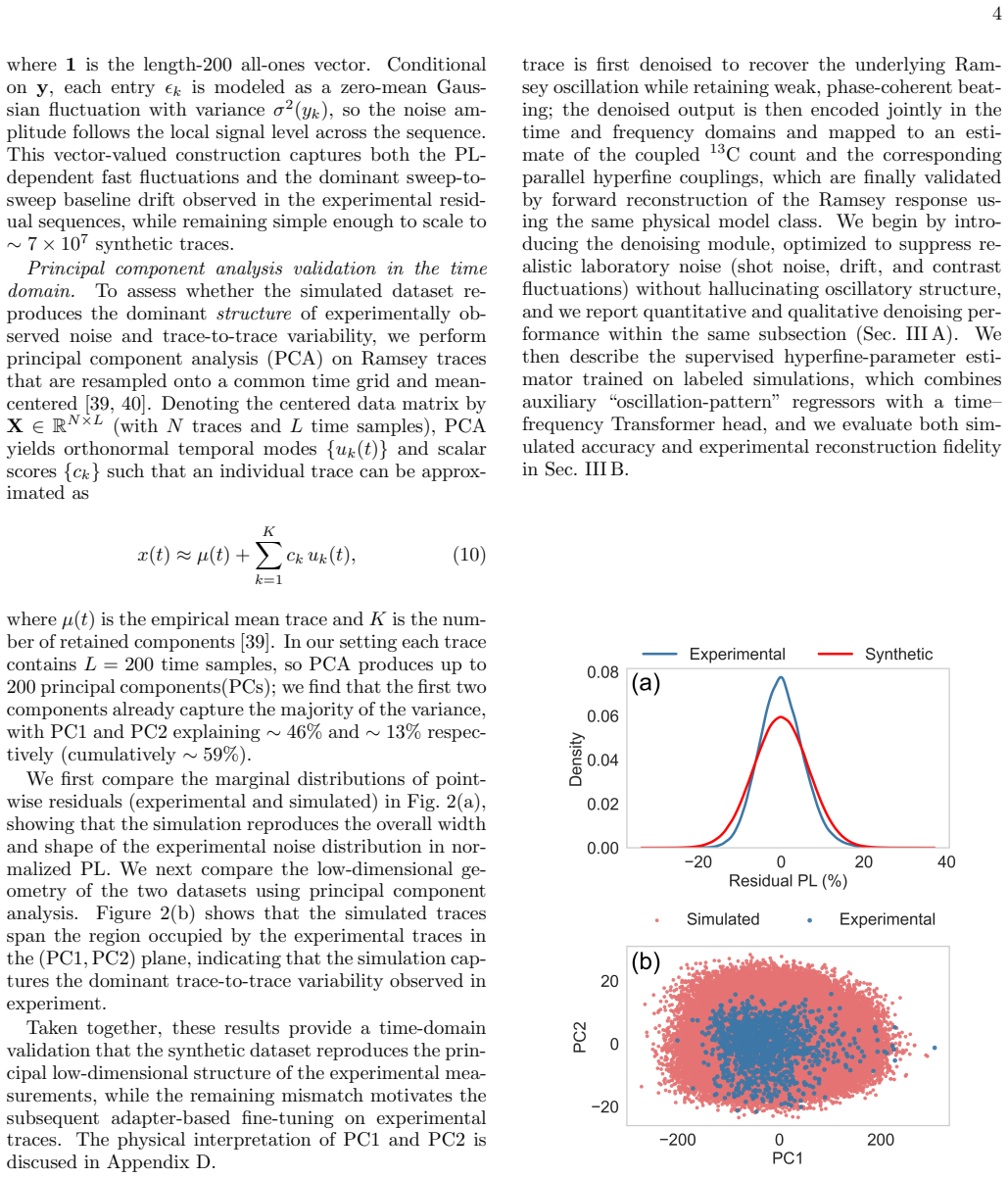
Precise characterization of the local spin environment of single diamond nitrogen-vacancy (NV) centers is crucial for advancing quantum sensing, quantum networking, and the optimization of quantum materials. However, single NV center fluorescence measurements requires long averaging times to obtain clean data that is suitable for conventional model fitting, and that constitutes a key experimental bottleneck for high-throughput characterization. To address this, we introduce \textsc{NVRNet}, a physics-informed simulation-to-reality machine learning pipeline that maps minimal-sweep, noisy Ramsey data to a denoised waveform while directly estimating the hyperfine coupling to proximal ${}^{13}\mathrm{C}$ nuclear spins. The pipeline's denoiser utilizes a two-stage time-frequency U-Net and an attention-augmented time-domain U-Net, pretrained on Hamiltonian-based spin-dynamics simulations with experimentally calibrated noise. To effectively bridge the simulation-to-reality gap, parameter-efficient adapters are attached to the backbone and fine-tuned on targeted experimental data. Across three distinct NV centers, this experimentally fine-tuned model reduces the median reconstruction error on held-out, few-sweep traces to $0.44\text{-}0.67\times$ of the raw experimental noise level. Subsequently, a transformer-based estimator extracts the underlying hyperfine parameters. Forward reconstructions derived from these inferred parameters faithfully reproduce the dominant experimental time- and frequency-domain features, yielding representative normalized fast Fourier transform (FFT) reconstruction errors of $0.10\text{-}0.19$. By reducing both the required data volume and acquisition time, \textsc{NVRNet} enables up to $\sim 40\times$ acceleration of the measurement process, establishing a fast, hardware-compatible pathway for robust hyperfine inference and autonomous qubit characterization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NVRNet, a physics-informed pipeline that pretrains a two-stage time-frequency U-Net denoiser and attention-augmented time-domain U-Net on Hamiltonian spin-dynamics simulations, attaches parameter-efficient adapters for fine-tuning on experimental Ramsey data from single NV centers, and uses a transformer estimator to extract 13C hyperfine couplings from few-sweep noisy traces. Across three NV centers it reports median reconstruction errors reduced to 0.44-0.67 times the raw noise level on held-out traces and normalized FFT reconstruction errors of 0.10-0.19, claiming up to 40x acceleration of the measurement process.
Significance. If the hyperfine estimates prove quantitatively accurate, the work would offer a practical route to high-throughput NV characterization by cutting acquisition time while preserving dominant time- and frequency-domain features, directly addressing a bottleneck in quantum sensing and networking experiments. The simulation-to-reality adapter strategy is a concrete strength that could generalize to other qubit platforms.
major comments (2)
- [Abstract] Abstract: the central claim that the transformer extracts accurate hyperfine couplings rests solely on forward-simulation fidelity (normalized FFT errors 0.10-0.19) matching experimental traces; no direct comparison is reported against hyperfine values obtained from conventional high-SNR Ramsey fits on the same three NV centers, leaving open the possibility that the estimator recovers only the dominant envelope while missing or biasing the actual couplings.
- [Methods / Results] Methods / Results (training protocol): the reported performance gains lack any description of training/validation splits, error bars on the 0.44-0.67x noise reduction, statistical significance tests, or ablation studies that isolate the contribution of the adapters versus the pretrained backbone, so the quantitative claims cannot be assessed for robustness.
minor comments (1)
- [Figures] Figure captions and text should explicitly state the number of experimental traces per NV center and the exact definition of 'held-out' data to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation and validation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the transformer extracts accurate hyperfine couplings rests solely on forward-simulation fidelity (normalized FFT errors 0.10-0.19) matching experimental traces; no direct comparison is reported against hyperfine values obtained from conventional high-SNR Ramsey fits on the same three NV centers, leaving open the possibility that the estimator recovers only the dominant envelope while missing or biasing the actual couplings.
Authors: We agree that a direct quantitative comparison between the hyperfine parameters inferred by the transformer estimator and those obtained from conventional high-SNR Ramsey fits on the same NV centers would provide additional validation. While the forward reconstructions from the inferred parameters faithfully reproduce the dominant features of the experimental data (as evidenced by the low normalized FFT errors), this does not explicitly confirm the accuracy of individual coupling values. In the revised manuscript, we will include such a comparison using the high-SNR data available for the three NV centers, reporting the differences in the extracted hyperfine couplings. This will help demonstrate that the estimator recovers accurate parameters rather than just the envelope. revision: yes
-
Referee: [Methods / Results] Methods / Results (training protocol): the reported performance gains lack any description of training/validation splits, error bars on the 0.44-0.67x noise reduction, statistical significance tests, or ablation studies that isolate the contribution of the adapters versus the pretrained backbone, so the quantitative claims cannot be assessed for robustness.
Authors: We acknowledge the need for more rigorous statistical reporting to assess the robustness of our quantitative claims. The current manuscript focuses on the overall performance across the three NV centers but does not detail the splits or provide error bars and ablations. In the revised version, we will add a dedicated subsection describing the training and validation splits used during pretraining and fine-tuning, include error bars (e.g., standard deviations across multiple runs or NV centers) on the noise reduction metrics, conduct statistical significance tests (such as paired t-tests) where applicable, and perform ablation studies to quantify the impact of the parameter-efficient adapters compared to the pretrained backbone alone. revision: yes
Circularity Check
No significant circularity in NVRNet derivation or validation
full rationale
The pipeline pretrains a U-Net denoiser and transformer estimator on Hamiltonian spin simulations (with known ground-truth hyperfine values), attaches and fine-tunes adapters on real experimental Ramsey traces from each NV center, then evaluates reconstruction error and normalized FFT match strictly on held-out few-sweep experimental data. These metrics are measured on traces excluded from both pretraining and fine-tuning, so reported error reductions (0.44-0.67× noise level, FFT errors 0.10-0.19) are empirical generalization results rather than quantities forced by construction from fitted parameters. No self-definitional equations, fitted-input-renamed-as-prediction steps, load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the abstract or described chain. The forward-reconstruction check is a standard consistency test on independent held-out data and does not collapse the extracted hyperfine values to the input measurements by definition.
Axiom & Free-Parameter Ledger
free parameters (2)
- adapter weights
- U-Net and transformer weights
axioms (1)
- domain assumption Hamiltonian-based spin-dynamics simulations with experimentally calibrated noise accurately capture the dominant features of real NV Ramsey signals
Reference graph
Works this paper leans on
-
[1]
Lattice construction, cutoff, and 13Cstatistics Diamond supercell enumeration.We generate a finite diamond simulation lattice by explicitly enumerating a conventional-cell basis over ann×n×nsupercell. Using the lattice constanta= 3.57 ˚A, atomic coordinates are constructed from integer “mod-4” basis pointsp µ (eight sites per conventional cell) and an FCC...
-
[2]
In the following derivation, we treatℏ= 1 for convinience
Rotating-wave approximation for the NV center: elimination of perpendicular hyperfine terms and rotating-frame reduction This appendix derives the effective two-level rotating- frame Hamiltonian used in the Ramsey simulator and jus- tifies neglecting perpendicular (spin-flip) hyperfine terms under our experimental conditions. In the following derivation, ...
work page 2000
-
[3]
During training and inference, traces are processed in mini-batches
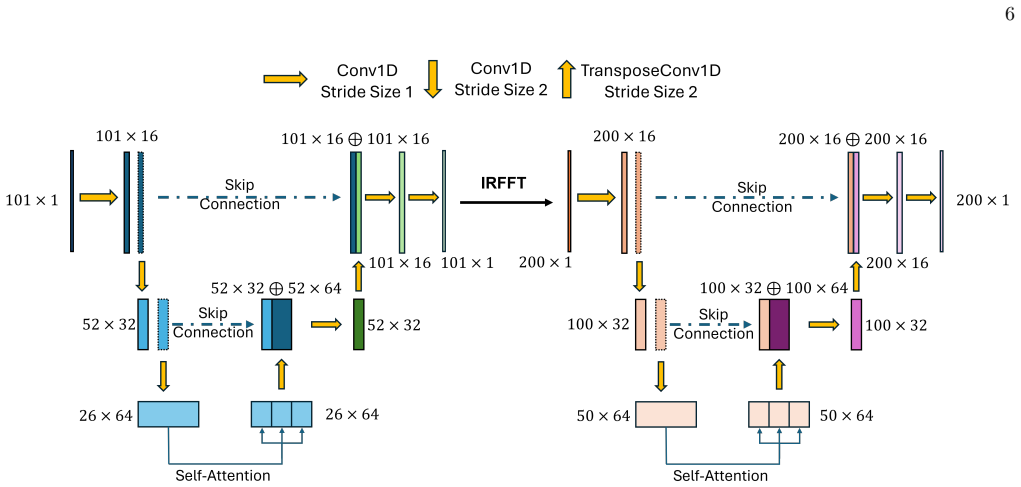
Detailed architecture of the denoising network Input representation.Each Ramsey trace consists of 200 uniformly sampled time points and is treated as a single-channel one-dimensional signal. During training and inference, traces are processed in mini-batches. For a batch of input traces, the time-domain input to the denoiser is therefore represented as a ...
-
[4]
Multi-head self-attention used at the UNet bottlenecks At the bottleneck of each 1D UNet we apply stan- dard multi-head self-attention (MHA) [30]. LetH∈ Rbatchsize×Lb×d denote the bottleneck representation written as a length-L b sequence ofd-dimensional tokens. 20 MHA withHheads computes queries, keys, and values by learned linear projections Q=HW Q,K=HW...
-
[5]
Token construction, embeddings, and Transformer self-attention for the hyperfine predictor This appendix specifies the exact tokenization and Transformer operations used by the hyperfine frequency predictor (Transformer head) in Sec. III B. Per-trace normalization.For a single tracey∈R 200 we compute ey= y−µ(y) σ(y) +ϵ , µ(y) = 1 200 200X ℓ=1 yℓ, σ2(y) = ...
-
[6]
False-Positive Test on the denoised result To verify that the denoiser does not hallucinate Ramsey-like structure when no physical signal is present, we perform a false-positive control usingpure-noisein- puts. Specifically, we generate random traces with the 21 same length and scale as the experimental PL read- out and provide an uncertainty channel set ...
-
[7]
More result on Experimental Hyperfine Prediction and reconstruction To complement the representative examples shown in the main text (Fig. 8), we provide additional qualita- tive results illustrating the consistency of the hyperfine- parameter estimator across the held-out experimental test set. Figure 15 shows multiple randomly selected re- constructions...
-
[8]
M. W. Doherty, N. B. Manson, P. Delaney, F. Jelezko, J. Wrachtrup, and L. C. L. Hollenberg, The nitrogen- vacancy colour centre in diamond, Phys. Rep.528, 1 (2013)
work page 2013
-
[9]
F. Jelezko and J. Wrachtrup, Single defect centres in dia- mond: A review, Phys. Status Solidi A203, 3207 (2006)
work page 2006
-
[10]
D. D. Awschalom, R. Hanson, J. Wrachtrup, and B. B. Zhou, Quantum technologies with optically interfaced solid-state spins, Nat. Photonics12, 516 (2018)
work page 2018
-
[11]
C. L. Degen, F. Reinhard, and P. Cappellaro, Quantum sensing, Rev. Mod. Phys.89, 035002 (2017)
work page 2017
-
[12]
J. R. Maze, P. L. Stanwix, J. S. Hodges, S. Hong, J. M. Taylor, P. Cappellaro, L. Jiang, M. V. G. Dutt, E. Togan, A. S. Zibrov, A. Yacoby, R. L. Walsworth, and M. D. Lukin, Nanoscale magnetic sensing with an individual electronic spin in diamond, Nature455, 644 (2008)
work page 2008
-
[13]
J. M. Taylor, P. Cappellaro, L. Childress, L. Jiang, D. Budker, P. R. Hemmer, A. Yacoby, R. Walsworth, and M. D. Lukin, High-sensitivity diamond magnetome- ter with nanoscale resolution, Nat. Phys.4, 810 (2008)
work page 2008
-
[14]
P. Maletinsky, S. Hong, M. S. Grinolds, B. Hausmann, M. D. Lukin, R. L. Walsworth, M. Lonˇ car, and A. Ya- coby, A robust scanning diamond sensor for nanoscale imaging with single nitrogen-vacancy centres, Nat. Nan- otechnol.7, 320 (2012)
work page 2012
-
[15]
M. S. Grinolds, S. Hong, P. Maletinsky, L. Luan, M. D. Lukin, R. L. Walsworth, and A. Yacoby, Nanoscale mag- netic imaging of a single electron spin under ambient con- ditions, Nat. Phys.9, 215 (2013)
work page 2013
-
[16]
L. Rondin, J.-P. Tetienne, T. Hingant, J.-F. Roch, P. Maletinsky, and V. Jacques, Magnetometry with nitrogen-vacancy defects in diamond, Rep. Prog. Phys. 77, 056503 (2014)
work page 2014
-
[17]
J.-P. Tetienne, R. W. de Gille, D. A. Broadway, T. Teraji, S. E. Lillie, J. M. McCoey, N. Dontschuk, L. T. Hall, A. Stacey, D. A. Simpson, and L. C. L. Hollenberg, Spin properties of dense near-surface ensembles of nitrogen- vacancy centers in diamond, Phys. Rev. B97, 085402 (2018)
work page 2018
-
[18]
R. Schirhagl, K. Chang, M. Loretz, and C. L. Degen, Nitrogen-vacancy centers in diamond: Nanoscale sensors for physics and biology, Annu. Rev. Phys. Chem.65, 83 (2014)
work page 2014
-
[19]
L. P. McGuinness, Y. Yan, A. Stacey, D. A. Simp- son, L. T. Hall, D. Maclaurin, S. Prawer, P. Mul- vaney, J. Wrachtrup, F. Caruso, R. E. Scholten, and L. C. L. Hollenberg, Quantum measurement and orien- tation tracking of fluorescent nanodiamonds inside living cells, Nat. Nanotechnol.6, 358 (2011)
work page 2011
-
[20]
V. V. Soshenko, S. V. Bolshedvorskii, O. Rubinas, V. N. Sorokin, A. N. Smolyaninov, V. V. Vorobyov, and A. V. Akimov, Nuclear spin gyroscope based on the nitrogen vacancy center in diamond, Physical Review Letters126, 197702 (2021)
work page 2021
-
[21]
J. Kuan and G. D. Fuchs, Optical readout of coherent nuclear spins in diamond coupled to electronic spins in a thermal state, Phys. Rev. Appl.24, 064059 (2025)
work page 2025
-
[22]
A. Jarmola, S. Lourette, V. M. Acosta, A. G. Birdwell, P. Bl¨ umler, D. Budker, T. Ivanov, and V. S. Malinovsky, Demonstration of diamond nuclear spin gyroscope, Sci- ence advances7, eabl3840 (2021)
work page 2021
-
[23]
G. Wang, M.-T. Nguyen, and P. Cappellaro, Hyperfine- enhanced gyroscope based on solid-state spins, Phys. Rev. Lett.133, 150801 (2024)
work page 2024
-
[24]
A. Ajoy and P. Cappellaro, Stable three-axis nuclear- spin gyroscope in diamond, Physical Review A—Atomic, Molecular, and Optical Physics86, 062104 (2012)
work page 2012
-
[25]
L. Childress, M. V. G. Dutt, J. M. Taylor, A. S. Zi- brov, F. Jelezko, J. Wrachtrup, P. R. Hemmer, and M. D. Lukin, Coherent dynamics of coupled electron and nu- clear spin qubits in diamond, Science314, 281 (2006)
work page 2006
-
[26]
T. H. Taminiau, J. J. T. Wagenaar, T. van der Sar, F. Jelezko, V. V. Dobrovitski, and R. Hanson, Detection and control of individual nuclear spins using a weakly coupled electron spin, Phys. Rev. Lett.109, 137602 (2012)
work page 2012
-
[27]
T. H. Taminiau, J. Cramer, T. van der Sar, V. V. Do- brovitski, and R. Hanson, Universal control and error correction in multi-qubit spin registers in diamond, Nat. Nanotechnol.9, 171 (2014)
work page 2014
-
[28]
E. R. MacQuarrie, T. A. Gosavi, A. M. Moehle, N. R. Jungwirth, S. A. Bhave, and G. D. Fuchs, Coherent con- trol of a nitrogen-vacancy center spin ensemble with a diamond mechanical resonator, Optica2, 233 (2015)
work page 2015
-
[29]
P. Ovartchaiyapong, K. W. Lee, B. A. Myers, and A. C. Bleszynski Jayich, Dynamic strain-mediated coupling of a single diamond spin to a mechanical resonator, Nat. Commun.5, 4429 (2014)
work page 2014
-
[30]
J. Teissier, A. Barfuss, P. Appel, E. Neu, and P. Maletinsky, Strain coupling of a nitrogen-vacancy cen- ter spin to a diamond mechanical oscillator, Phys. Rev. Lett.113, 020503 (2014)
work page 2014
-
[31]
D. A. Hopper, H. J. Shulevitz, and L. C. Bassett, Spin readout techniques of the nitrogen-vacancy center in di- amond, Micromachines9, 437 (2018)
work page 2018
-
[32]
O. Ronneberger, P. Fischer, and T. Brox, U-net: Con- volutional networks for biomedical image segmentation, inInternational Conference on Medical image computing and computer-assisted intervention(Springer, 2015) pp. 234–241
work page 2015
-
[33]
J. Ho, A. Jain, and P. Abbeel, Denoising diffusion proba- bilistic models, Advances in neural information process- ing systems33, 6840 (2020)
work page 2020
-
[34]
H. Wu, Z. Zhao, and Z. Wang, Meta-unet: Multi-scale efficient transformer attention unet for fast and high- accuracy polyp segmentation, IEEE Transactions on Au- tomation Science and Engineering21, 4117 (2023)
work page 2023
-
[35]
M. Drozdzal, E. Vorontsov, G. Chartrand, S. Kadoury, and C. Pal, The importance of skip connections in biomedical image segmentation, inInternational workshop on deep learning in medical image analysis (Springer, 2016) pp. 179–187
work page 2016
-
[36]
R. Azad, M. Heidari, Y. Wu, and D. Merhof, Contextual attention network: Transformer meets u-net, inInterna- tional workshop on machine learning in medical imaging (Springer, 2022) pp. 377–386
work page 2022
-
[37]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, At- tention is all you need, Advances in neural information processing systems30(2017)
work page 2017
-
[38]
D. Bahdanau, K. Cho, and Y. Bengio, Neural machine translation by jointly learning to align and translate, in 25 3rd International Conference on Learning Representa- tions, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, edited by Y. Bengio and Y. LeCun (2015)
work page 2015
-
[39]
S.-Y. Shih, F.-K. Sun, and H.-y. Lee, Temporal pattern attention for multivariate time series forecasting, Ma- chine Learning108, 1421 (2019)
work page 2019
-
[40]
B. Varona-Uriarte, C. Munuera-Javaloy, E. Terradillos, Y. Ban, A. Alvarez-Gila, E. Garrote, and J. Casanova, Automatic detection of nuclear spins at arbitrary mag- netic fields via signal-to-image ai model, Physical Review Letters132, 150801 (2024)
work page 2024
-
[41]
K. Jung, M. Abobeih, J. Yun, G. Kim, H. Oh, A. Henry, T. Taminiau, and D. Kim, Deep learning enhanced indi- vidual nuclear-spin detection, npj Quantum Information 7, 41 (2021)
work page 2021
-
[42]
N. Xu, F. Zhou, X. Ye, X. Lin, B. Chen, T. Zhang, F. Yue, B. Chen, Y. Wang, and J. Du, Noise prediction and reduction of single electron spin by deep-learning- enhanced feedforward control, Nano Letters23, 2460 (2023)
work page 2023
-
[43]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wain- wright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, Training language models to follow instructions with human feedback (2022), arXiv:2203.02155 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y. Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Ding, H. Gao, H. Qu, H. Li, J. Gu...
work page 2025
-
[45]
N. Lambert, E. Gigu‘ere, P. Menczel, B. Li, P. Hopf, G. Su’arez, M. Gali, J. Lishman, R. Gadhvi, R. Agarwal, A. Galicia, N. Shammah, P. Nation, J. R. Johansson, S. Ahmed, S. Cross, A. Pitchford, and F. Nori, Qutip 5: The quantum toolbox in Python, Physics Reports1153, 1 (2026)
work page 2026
-
[46]
K. Pearson, Liii. on lines and planes of closest fit to sys- tems of points in space, The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science2, 559 (1901)
work page 1901
-
[47]
H. Hotelling, Analysis of a complex of statistical vari- ables into principal components, Journal of Educational Psychology24, 417 (1933)
work page 1933
-
[48]
X. Wang, R. Girshick, A. Gupta, and K. He, Non- local neural networks, in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2018) pp. 7794–7803
work page 2018
- [49]
-
[50]
R. Yamamoto, E. Song, and J.-M. Kim, Parallel Wave- GAN: A fast waveform generation model based on gen- erative adversarial networks with multi-resolution spec- trogram, inProceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)(2020) pp. 6199–6203
work page 2020
-
[51]
University of Cambridge, Digital signal processing (lec- ture slides) (2024), see slide section defining DC com- ponent as the mean and AC component as signal minus mean
work page 2024
- [52]
-
[53]
S. Ioffe and C. Szegedy, Batch normalization: Accelerat- ing deep network training by reducing internal covariate shift, inProceedings of the 32nd International Conference on Machine Learning (ICML), Proceedings of Machine Learning Research, Vol. 37 (PMLR, 2015) pp. 448–456
work page 2015
-
[54]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, Gaussian error linear units (gelus), arXiv:1606.08415 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[55]
G. E. P. Box and D. R. Cox, An analysis of transforma- tions, Journal of the Royal Statistical Society: Series B (Methodological)26, 211 (1964)
work page 1964
-
[56]
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and A. C. Berg, Ssd: Single shot multi- box detector, inEuropean conference on computer vision (Springer, 2016) pp. 21–37
work page 2016
-
[57]
R. Girshick, Fast r-cnn, inProceedings of the IEEE inter- national conference on computer vision(2015) pp. 1440– 1448
work page 2015
-
[58]
P. J. Huber, Robust estimation of a location parameter, inBreakthroughs in statistics: Methodology and distribu- tion(Springer, 1992) pp. 492–518
work page 1992
-
[59]
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, inProceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies (NAACL-HLT), Volume 1(Association for Computational Linguistics, 2019) pp. 4171–4186
work page 2019
-
[60]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, An im- age is worth 16x16 words: Transformers for image recog- nition at scale, inInternational Conference on Learning Representations (ICLR)(2021). 26
work page 2021
-
[61]
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablay- rolles, and H. J´ egou, Training data-efficient image trans- formers & distillation through attention, inProceedings of the 38th International Conference on Machine Learn- ing (ICML), Proceedings of Machine Learning Research, Vol. 139 (PMLR, 2021) pp. 10347–10357
work page 2021
-
[62]
J. Bridle, Training stochastic model recognition algo- rithms as networks can lead to maximum mutual infor- mation estimation of parameters, Advances in neural in- formation processing systems2(1989)
work page 1989
-
[63]
D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, A learn- ing algorithm for boltzmann machines, Cognitive science 9, 147 (1985)
work page 1985
-
[64]
J. J. Hopfield, Learning algorithms and probability dis- tributions in feed-forward and feed-back networks, Pro- ceedings of the national academy of sciences84, 8429 (1987)
work page 1987
-
[65]
E. Baum and F. Wilczek, Supervised learning of proba- bility distributions by neural networks, inNeural infor- mation processing systems(1987)
work page 1987
-
[66]
E. Levin and M. Fleisher, Accelerated learning in layered neural networks, Complex systems2, 3 (1988)
work page 1988
-
[67]
D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Learning representations by back-propagating errors, na- ture323, 533 (1986)
work page 1986
-
[68]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, Decoupled weight decay reg- ularization (2019), arXiv:1711.05101 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[69]
M. Abobeih, J. Randall, C. Bradley, H. Bartling, M. Bakker, M. Degen, M. Markham, D. Twitchen, and T. Taminiau, Atomic-scale imaging of a 27-nuclear-spin cluster using a quantum sensor, Nature576, 411 (2019)
work page 2019
-
[70]
Abragam,The Principles of Nuclear Magnetism (Clarendon Press, 1961)
A. Abragam,The Principles of Nuclear Magnetism (Clarendon Press, 1961)
work page 1961
-
[71]
K. He, X. Zhang, S. Ren, and J. Sun, Deep residual learning for image recognition, in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
work page 2016
-
[72]
J. L. Ba, J. R. Kiros, and G. E. Hinton, Layer normal- ization, inNIPS 2016 Deep Learning Workshop(2016)
work page 2016
-
[73]
J. Chen, Y. Lu, Q. Yu, X. Luo, E. Adeli, Y. Wang, L. Lu, A. L. Yuille, and Y. Zhou, Transunet: Transformers make strong encoders for medical image segmentation, arXiv 10.48550/arXiv.2102.04306 (2021)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2102.04306 2021
-
[74]
A. Hatamizadeh, Y. Tang, V. Nath, D. Yang, A. My- ronenko, B. Landman, H. R. Roth, and D. Xu, Unetr: Transformers for 3d medical image segmentation, in2022 IEEE/CVF Winter Conference on Applications of Com- puter Vision (WACV)(2022) pp. 1748–1758
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.