Recognition: 3 theorem links
· Lean TheoremPosterior-Calibrated Causal Circuits in Variational Autoencoders: Why Image-Domain Interpretability Fails on Tabular Data
Pith reviewed 2026-05-15 06:53 UTC · model grok-4.3
The pith
Causal circuits in tabular VAEs show roughly half the modularity of image VAEs, with beta-VAE collapsing due to reconstruction failure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
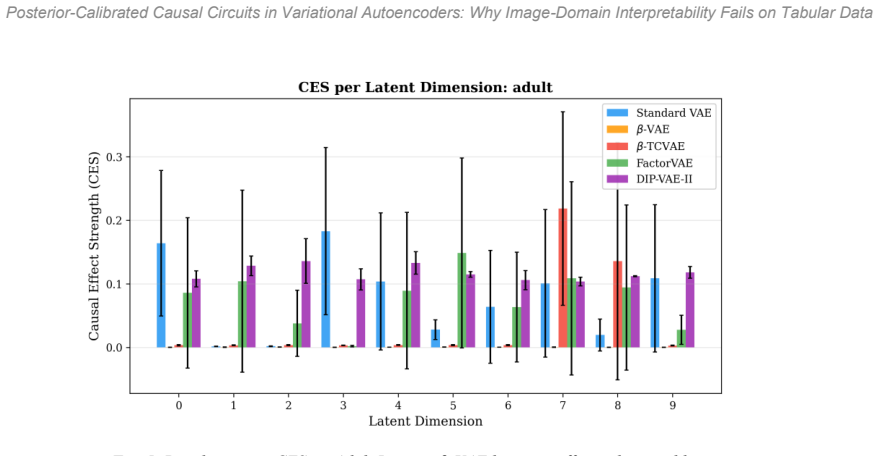
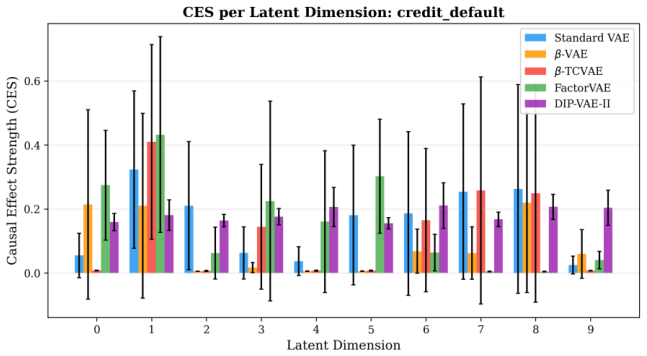
Tabular VAEs exhibit causal circuits whose modularity is approximately 50 percent lower than image counterparts. Beta-VAE undergoes near-complete collapse in posterior-calibrated causal effect strength scores on heterogeneous tabular features, a collapse directly attributable to reconstruction degradation. High-specificity interventions within the recovered circuits reliably predict the highest downstream task AUC.
What carries the argument
The four-level causal intervention framework extended by posterior-calibrated Causal Effect Strength (CES), path-specific activation patching, and Feature-Group Disentanglement (FGD), which together localize and quantify causal effects inside the VAE's generative circuits.
Load-bearing premise
The image-derived causal intervention levels and CES metric can be extended to heterogeneous tabular features without changing what they measure, and posterior calibration removes rather than masks reconstruction-induced artifacts.
What would settle it
If a tabular VAE achieves reconstruction error comparable to image VAEs yet still yields CES scores near 0.13 instead of collapsing to 0.043, or if high-specificity interventions no longer predict downstream AUC, the transfer-failure claim would be falsified.
Figures




read the original abstract
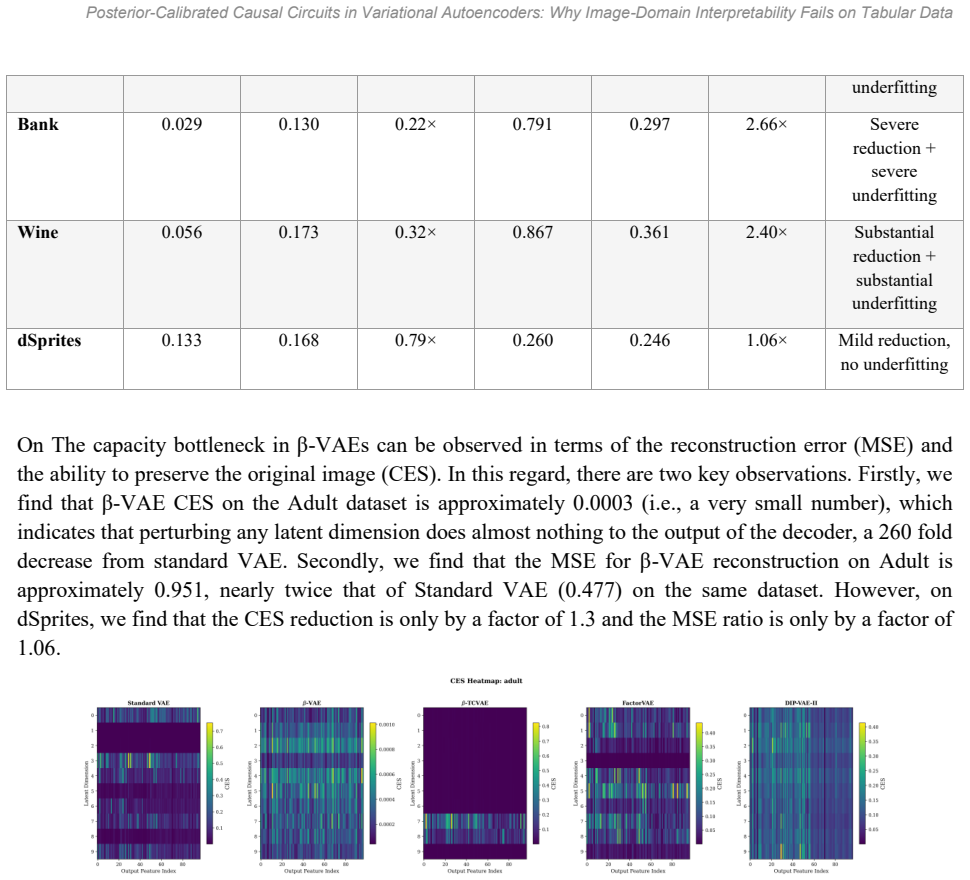
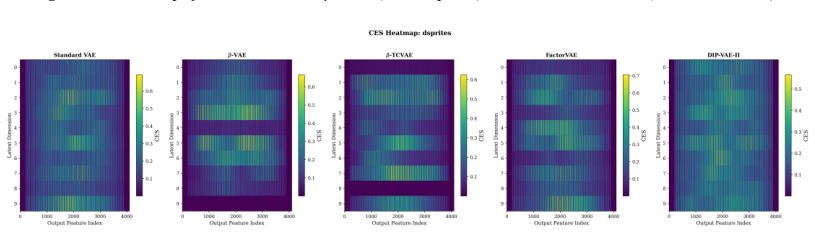
Although mechanism-based interpretability has generated an abundance of insight for discriminative network analysis, generative models are less understood -- particularly outside of image-related applications. We investigate how much of the causal circuitry found within image-related variational autoencoders (VAEs) will generalize to tabular data, as VAEs are increasingly used for imputation, anomaly detection, and synthetic data generation. In addition to extending a four-level causal intervention framework to four tabular and one image benchmark across five different VAE architectures (with 75 individual training runs per architecture and three random seed values for each run), this paper introduces three new techniques: posterior-calibration of Causal Effect Strength (CES), path-specific activation patching, and Feature-Group Disentanglement (FGD). The results from our experiments demonstrate that: (i) Tabular VAEs have circuits with modularity that is approximately 50% lower than their image counterparts. (ii) $\beta$-VAE experiences nearly complete collapse in CES scores when applied to heterogeneous tabular features (0.043 CES score for tabular data compared to 0.133 CES score for images), which can be directly attributed to reconstruction quality degradation (r = -0.886 correlation coefficient between CES and MSE). (iii) CES successfully captures nine of eleven statistically significant architecture differences using Holm--\v{S}id\'{a}k corrections. (iv) Interventions with high specificity predict the highest downstream AUC values (r = 0.460, p < .001). This study challenges the common assumption that architectural guidance from image-related studies can be transferred to tabular datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that causal circuits and interpretability methods developed for image VAEs do not transfer to tabular data. It extends a four-level causal intervention framework to four tabular and one image benchmark across five VAE architectures (75 runs per architecture), introduces posterior-calibrated Causal Effect Strength (CES), path-specific activation patching, and Feature-Group Disentanglement (FGD), and reports that tabular VAEs show ~50% lower modularity, beta-VAE exhibits near-complete CES collapse (0.043 vs. 0.133) attributable to reconstruction degradation (r=-0.886), CES detects nine of eleven architecture differences under Holm-Šidák correction, and high-specificity interventions predict higher downstream AUC (r=0.460). The work challenges the transferability of image-derived architectural guidance to tabular applications such as imputation and synthetic data generation.
Significance. If the central claims survive a control that isolates reconstruction quality, the paper would make a meaningful contribution to mechanistic interpretability of generative models by demonstrating domain-specific limitations of image-derived causal circuit methods and by proposing calibration and grouping techniques tailored to heterogeneous tabular inputs. The extensive run count, multiple-seed design, and downstream-task correlation provide a stronger empirical foundation than many interpretability studies; the negative CES-MSE link and specificity-AUC correlation offer falsifiable, practically relevant observations for VAE practitioners.
major comments (2)
- [Abstract / Results] Abstract and Results: The claim that tabular VAEs exhibit intrinsically lower modularity and CES collapse rests on the assumption that the four-level intervention framework and CES metric remain valid when inputs change from homogeneous pixel grids to mixed-type tabular vectors. The reported r=-0.886 between CES and MSE is consistent with the alternative that poor reconstruction renders activation patching ill-defined rather than revealing an architectural difference. No control experiment that holds reconstruction quality constant across domains while recomputing CES is described; without it the non-transfer conclusion is not yet load-bearing.
- [Methods] Methods (posterior calibration and CES definition): Posterior calibration is introduced to mitigate reconstruction artifacts, yet the manuscript provides no sensitivity analysis on the calibration parameters or explicit check that calibration does not introduce post-hoc selection that inflates the reported modularity gap or CES differences. Because CES is computed after calibration on the same data used for evaluation, a control that recomputes CES under fixed reconstruction quality is required to separate metric artifact from genuine causal-structure difference.
minor comments (2)
- [Abstract] Abstract: The text states that three new techniques are introduced but names only posterior-calibrated CES and FGD explicitly; path-specific activation patching is mentioned later. Ensure the abstract lists all three consistently.
- [Results] Results: The 50% modularity reduction is reported without the precise formula used for heterogeneous tabular features; clarify whether modularity is computed on feature groups or individual columns and how this compares to the pixel-grid definition.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results: The claim that tabular VAEs exhibit intrinsically lower modularity and CES collapse rests on the assumption that the four-level intervention framework and CES metric remain valid when inputs change from homogeneous pixel grids to mixed-type tabular vectors. The reported r=-0.886 between CES and MSE is consistent with the alternative that poor reconstruction renders activation patching ill-defined rather than revealing an architectural difference. No control experiment that holds reconstruction quality constant across domains while recomputing CES is described; without it the non-transfer conclusion is not yet load-bearing.
Authors: We agree that a control holding reconstruction quality constant would more definitively isolate domain effects from reconstruction artifacts. The reported r = -0.886 correlation is consistent with our interpretation that reconstruction degradation drives CES collapse, yet we acknowledge it leaves room for the alternative that activation patching becomes ill-defined under high MSE. In the revision we will add a control that degrades image VAE reconstructions (via increased noise or reduced capacity) to match the MSE distribution observed on tabular data, then recompute CES and modularity to test whether the ~50% gap persists. revision: yes
-
Referee: [Methods] Methods (posterior calibration and CES definition): Posterior calibration is introduced to mitigate reconstruction artifacts, yet the manuscript provides no sensitivity analysis on the calibration parameters or explicit check that calibration does not introduce post-hoc selection that inflates the reported modularity gap or CES differences. Because CES is computed after calibration on the same data used for evaluation, a control that recomputes CES under fixed reconstruction quality is required to separate metric artifact from genuine causal-structure difference.
Authors: We will include a sensitivity analysis over the posterior calibration strength parameter in the revised Methods and Results sections, reporting CES and modularity across a range of calibration values to demonstrate robustness. The reconstruction-matched control described above will also recompute CES after calibration under fixed MSE, directly addressing the concern that calibration may inflate differences. revision: yes
Circularity Check
No significant circularity in empirical extension of causal framework
full rationale
The paper reports direct experimental measurements of modularity, CES scores, and correlations (r = -0.886 with MSE; r = 0.460 with downstream AUC) across 75 runs per architecture on both image and tabular benchmarks. CES is computed via posterior calibration but then validated against independent reconstruction error and task performance rather than being tautological with its own definition. The four-level intervention framework is applied uniformly and its transfer failure is shown by observed drops, not by assuming equivalence. No load-bearing self-citations, fitted inputs renamed as predictions, or ansatz smuggling appear in the derivation; results remain falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- beta coefficient in beta-VAE
- CES calibration parameters
axioms (1)
- domain assumption Four-level causal intervention framework from image VAEs applies without modification to tabular features
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
posterior-calibrated CES … CES(d) = E_x[(1/|V|) Σ_v (1/n) ‖D_θ(z̃_{d,v}) − D_θ(μ)‖₁]
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Modularity M = 1 − (1/D) Σ_d H(R_{:,d}) / log G
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
β-VAE capacity bottleneck … r = −0.886 between CES and MSE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A mathematical framework for transformer circuits,
N. Elhage et al., "A mathematical framework for transformer circuits," Transformer Circuits Thread, 2021
work page 2021
-
[2]
Interpretability in the wild: A circuit for indirect object identification in GPT -2 small,
K. Wang, A. Variengien, A. Conmy, B. Shlegeris, and J. Steinhardt, "Interpretability in the wild: A circuit for indirect object identification in GPT -2 small," in Proc. Int. Conf. Learn. Represent. (ICLR), 2023
work page 2023
-
[3]
C. Olah, A. Mordvintsev, and L. Schubert, "Feature visualization," Distill, vol. 2, no. 11, 2017
work page 2017
-
[4]
Auto -encoding variational Bayes,
D. P. Kingma and M. Welling, "Auto -encoding variational Bayes," in Proc. Int. Conf. Learn. Represent. (ICLR), 2014
work page 2014
-
[5]
beta -VAE: Learning basic visual concepts with a constrained variational framework,
I. Higgins et al., "beta -VAE: Learning basic visual concepts with a constrained variational framework," in Proc. Int. Conf. Learn. Represent. (ICLR), 2017
work page 2017
-
[6]
Disentangling by factorising ,
H. Kim and A. Mnih, "Disentangling by factorising ," in Proc. Int. Conf. Mach. Learn. (ICML), pp. 2649–2658, 2018
work page 2018
-
[7]
Isolating sources of disentanglement in variational autoencoders,
R. T. Q. Chen, X. Li, R. B. Grosse, and D. K. Duvenaud, "Isolating sources of disentanglement in variational autoencoders," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), pp. 2610–2620, 2018. Posterior-Calibrated Causal Circuits in Variational Autoencoders: Why Image-Domain Interpretability Fails on Tabular Data 25
work page 2018
-
[8]
Variational inference of disentangled latent concepts from unlabeled observations,
A. Kumar, P. Sattigeri, and A. Balakrishnan, "Variational inference of disentangled latent concepts from unlabeled observations," in Proc. Int. Conf. Learn. Represent. (ICLR), 2018
work page 2018
-
[9]
A framework for the quantitative evaluation of disentangled representations,
C. Eastwood and C. K. I. Williams, "A framework for the quantitative evaluation of disentangled representations," in Proc. Int. Conf. Learn. Represent. (ICLR), 2018
work page 2018
-
[10]
A commentary on the unsupervised learning of disentangled representations,
F. Locatello, S. Bauer, M. Lucic, G. Ratsch, S. Gelly, B. Scholkopf, and O. Bachem, "A commentary on the unsupervised learning of disentangled representations," in Proc. AAAI Conf. Artif. Intell., vol. 34, no. 8, pp. 13681-13684, 2020
work page 2020
-
[11]
D. Roy and R. Misra, "A multi -level causal intervention framework for mechanistic interpretability in variational autoencoders," arXiv preprint arXiv:2505.03530, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Modeling tabular data using conditional GAN,
L. Xu, M. Skoularidou, A. Cuesta -Infante, and K. Veeramachaneni, "Modeling tabular data using conditional GAN," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), pp. 7335–7345, 2019
work page 2019
-
[13]
Variational autoencoder based anomaly detection using reconstruction probability,
J. An and S. Cho, "Variational autoencoder based anomaly detection using reconstruction probability," Special Lecture on IE, vol. 2, no. 1, pp. 1–18, 2015
work page 2015
-
[14]
Synthesizing Tabular Data using Generative Adversarial Networks
L. Xu et al., "Synthesizing tabular data using generative adversarial networks," arXiv:1811.11264, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Locating and editing factual associations in GPT,
K. Meng, D. Bau, A. Andonian, and Y. Belinkov, "Locating and editing factual associations in GPT," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), pp. 17359–17372, 2022
work page 2022
-
[16]
Network dissection: Quantifying interpretability of deep visual representations,
D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba, "Network dissection: Quantifying interpretability of deep visual representations," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 6541–6549, 2017
work page 2017
-
[17]
GAN dissection: Visualizing and understanding generative adversarial networks,
D. Bau et al., "GAN dissection: Visualizing and understanding generative adversarial networks," in Proc. Int. Conf. Learn. Represent. (ICLR), 2019
work page 2019
- [18]
-
[19]
Challenging common assumptions in the unsupervised learning of disentangled representations,
F. Locatello et al., "Challenging common assumptions in the unsupervised learning of disentangled representations," in Proc. Int. Conf. Mach. Learn. (ICML), pp. 4114–4124, 2019
work page 2019
-
[20]
Theory and evaluation metrics for learning disentangled representations,
K. Do and T. Tran, "Theory and evaluation metrics for learning disentangled representations," in Proc. Int. Conf. Learn. Represent. (ICLR), 2020
work page 2020
-
[21]
Pearl, Causality: Models, Reasoning, and Inference, 2nd ed
J. Pearl, Causality: Models, Reasoning, and Inference, 2nd ed. Cambridge University Press, 2009
work page 2009
-
[22]
Causal abstractions of neural networks,
A. Geiger, H. Lu, T. Icard, and C. Potts, "Causal abstractions of neural networks," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), pp. 9574–9586, 2021
work page 2021
-
[23]
Towards automated circuit discovery for mechanistic interpretability,
A. Conmy et al., "Towards automated circuit discovery for mechanistic interpretability," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2023
work page 2023
-
[24]
Investigating gender bias in language models using causal mediation analysis,
J. Vig et al., "Investigating gender bias in language models using causal mediation analysis," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), pp. 12388–12401, 2020
work page 2020
-
[25]
CausalVAE: Disentangled representation learning via neural structural causal models,
M. Yang et al., "CausalVAE: Disentangled representation learning via neural structural causal models," in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), pp. 9593–9602, 2021. Posterior-Calibrated Causal Circuits in Variational Autoencoders: Why Image-Domain Interpretability Fails on Tabular Data 26
work page 2021
-
[26]
Robustly disentangled causal mechanisms,
R. Suter, D. Miladinovic, B. Scholkopf, and S. Bauer, "Robustly disentangled causal mechanisms," in Proc. Int. Conf. Mach. Learn. (ICML), pp. 6056–6065, 2019
work page 2019
-
[27]
EDDI: Efficient dynamic discovery of high -value information with partial VAE,
C. Ma et al., "EDDI: Efficient dynamic discovery of high -value information with partial VAE," in Proc. Int. Conf. Mach. Learn. (ICML), pp. 4234–4243, 2019
work page 2019
-
[28]
dSprites: Disentanglement testing sprites dataset,
L. Matthey, I. Higgins, D. Hassabis, and A. Lerchner, "dSprites: Disentanglement testing sprites dataset," GitHub, 2017
work page 2017
-
[29]
Scaling up the accuracy of Naive -Bayes classifiers,
R. Kohavi, "Scaling up the accuracy of Naive -Bayes classifiers," in Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Mining, pp. 202–207, 1996
work page 1996
-
[30]
I.-C. Yeh and C.-H. Lien, "The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients," Expert Syst. Appl., vol. 36, no. 2, pp. 2473–2480, 2009
work page 2009
-
[31]
A data -driven approach to predict the success of bank telemarketing,
S. Moro, P. Cortez, and P. Rita, "A data -driven approach to predict the success of bank telemarketing," Decis. Support Syst., vol. 62, pp. 22–31, 2014
work page 2014
-
[32]
Modeling wine preferences by data mining from physicochemical properties,
P. Cortez et al., "Modeling wine preferences by data mining from physicochemical properties," Decis. Support Syst., vol. 47, no. 4, pp. 547–553, 2009
work page 2009
-
[33]
Experiment tracking with Weights and Biases,
L. Biewald, "Experiment tracking with Weights and Biases," wandb.com, 2020
work page 2020
-
[34]
Sparse autoencoders find highly interpretable features in language models,
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey, "Sparse autoencoders find highly interpretable features in language models," in Proc. Int. Conf. Learn. Represent. (ICLR), 2024
work page 2024
-
[35]
Towards monosemanticity : Decomposing language models with dictionary learning,
T. Bricken et al., "Towards monosemanticity : Decomposing language models with dictionary learning," Transformer Circuits Thread, 2023
work page 2023
-
[36]
TabNet: Attentive interpretable tabular learning,
S. Arik and T. Pfister, "TabNet: Attentive interpretable tabular learning," in Proc. AAAI Conf. Artif. Intell., vol. 35, pp. 6679–6687, 2021
work page 2021
-
[37]
SAINT: Improved neural networks for tabular data,
G. Somepalli et al., "SAINT: Improved neural networks for tabular data," arXiv:2106.01342, 2021
-
[38]
Revisiting deep learning models for tabular data,
Y. Gorishniy et al., "Revisiting deep learning models for tabular data," in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), pp. 18932–18943, 2021
work page 2021
-
[39]
The information bottleneck method
N. Tishby, F. C. Pereira, and W. Bialek, "The information bottleneck method," arXiv:physics/0004057, 2000
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[40]
Deep variational information bottleneck,
A. A. Alemi, I. Fischer, J. V. Dillon, and K. Murphy, "Deep variational information bottleneck," in Proc. Int. Conf. Learn. Represent. (ICLR), 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.