Causal Evidence that Language Models use Confidence to Drive Behavior
Pith reviewed 2026-05-21 09:38 UTC · model grok-4.3
The pith
Language models use internal confidence signals to control whether they answer or abstain from questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
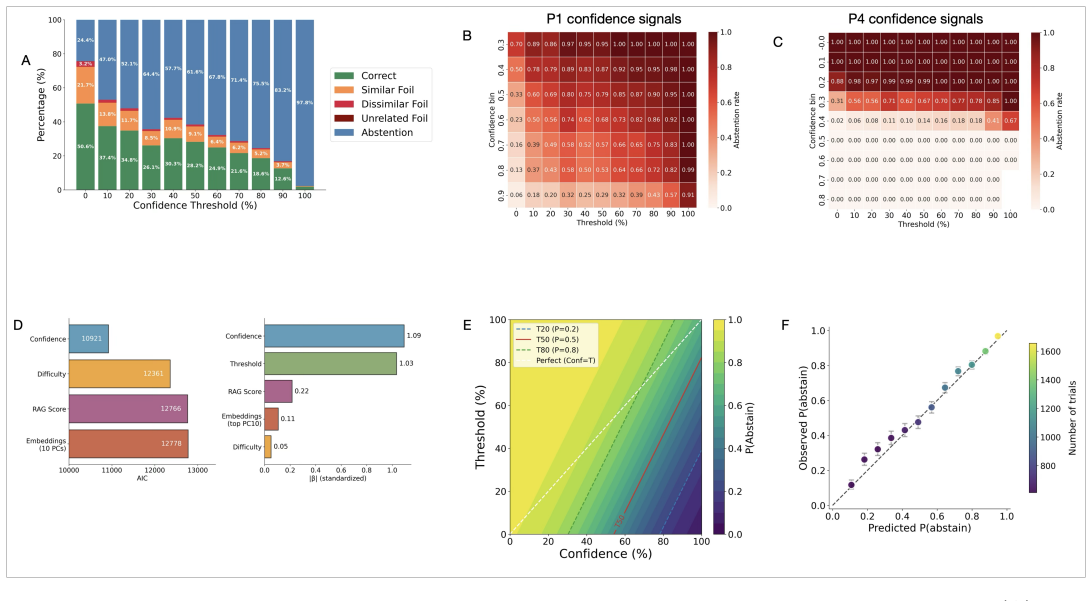
Through a four-phase paradigm, the paper shows that LLMs apply an implicit threshold to internal confidence when deciding to abstain, with these signals having much larger effects than alternatives. Direct causal evidence comes from activation steering that increases or decreases abstention rates by boosting or suppressing confidence. Models also adjust their abstention based on different instructed thresholds. Both verbal confidence and activation patterns at the pre-answer token indicate a multidimensional internal confidence representation that goes beyond output log-probabilities, supporting the view that abstention reflects structured metacognitive control.
What carries the argument
A multidimensional internal confidence representation combined with threshold-based policies, tested through activation steering to establish causality in abstention decisions.
If this is right
- Abstention decisions are causally driven by internal confidence rather than output distribution strength alone.
- Verbal confidence independently predicts abstention even when less accurate at judging correctness.
- Models can implement different abstention policies by adjusting thresholds on their confidence signals.
- Activation patterns reveal that observable confidence measures are incomplete readouts of deeper internal states.
Where Pith is reading between the lines
- If this holds, models could be made more reliable in agent settings by enhancing their ability to recognize uncertainty.
- Similar confidence mechanisms might underlie other adaptive behaviors like seeking more information or revising answers.
- Testing whether these signals can be aligned with human-like uncertainty judgments could improve model safety.
Load-bearing premise
The changes made by activation steering affect only the confidence signals and do not independently alter other model processes that influence abstention rates.
What would settle it
If boosting or suppressing the targeted activations changes abstention rates in the opposite direction from predictions or affects unrelated model outputs similarly, the specific causal role of confidence would be undermined.
Figures












read the original abstract
Metacognition -- assessing the quality of one's own cognitive performance -- guides adaptive behavior across species. Substantial research demonstrates that confidence signals can be extracted from language model outputs, yet a fundamental question remains: do models actually use these signals to control behavior, such as deciding whether to answer or abstain? To investigate, we developed a four-phase paradigm. Phase~1 elicited baseline confidence estimates without an abstention option. Phase~2 revealed that LLMs apply an implicit threshold to internal confidence when deciding to abstain, with confidence effect sizes approximately an order of magnitude larger than alternative mechanisms. Phase~3 provided direct causal evidence through activation steering: boosting or suppressing confidence signals correspondingly decreased or increased abstention rates. Phase~4 extended this by systematically varying instructed thresholds, demonstrating that LLMs actively deploy confidence signals to implement abstention policies. Critically, beyond calibrated log-probability based confidence derived from the output distribution, verbal confidence independently predicted abstention across all models, despite being objectively less discriminatory of answer correctness. Activation decoding at the last pre-answer token further showed that both observable measures are lossy readouts of a richer internal representation. Together, these results suggest that abstention is not fully captured by the strength of evidence in the output distribution alone, but is better explained by the joint operation of a multidimensional internal confidence representation and threshold-based policies -- consistent with structured metacognitive control in LLMs, a capacity of growing importance as models transition to autonomous agents that must recognize their own uncertainty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a four-phase paradigm to test whether language models utilize internal confidence signals for controlling abstention behavior. Phase 1 establishes baseline confidence estimates, Phase 2 demonstrates that LLMs apply an implicit threshold to internal confidence when deciding to abstain (with large effect sizes relative to alternatives), Phase 3 uses activation steering to provide causal evidence by boosting or suppressing confidence signals and observing corresponding changes in abstention rates, and Phase 4 varies instructed thresholds to show active deployment of confidence signals. The results indicate that abstention is better explained by a multidimensional internal confidence representation and threshold-based policies than by output distribution strength alone, with verbal confidence providing additional predictive power.
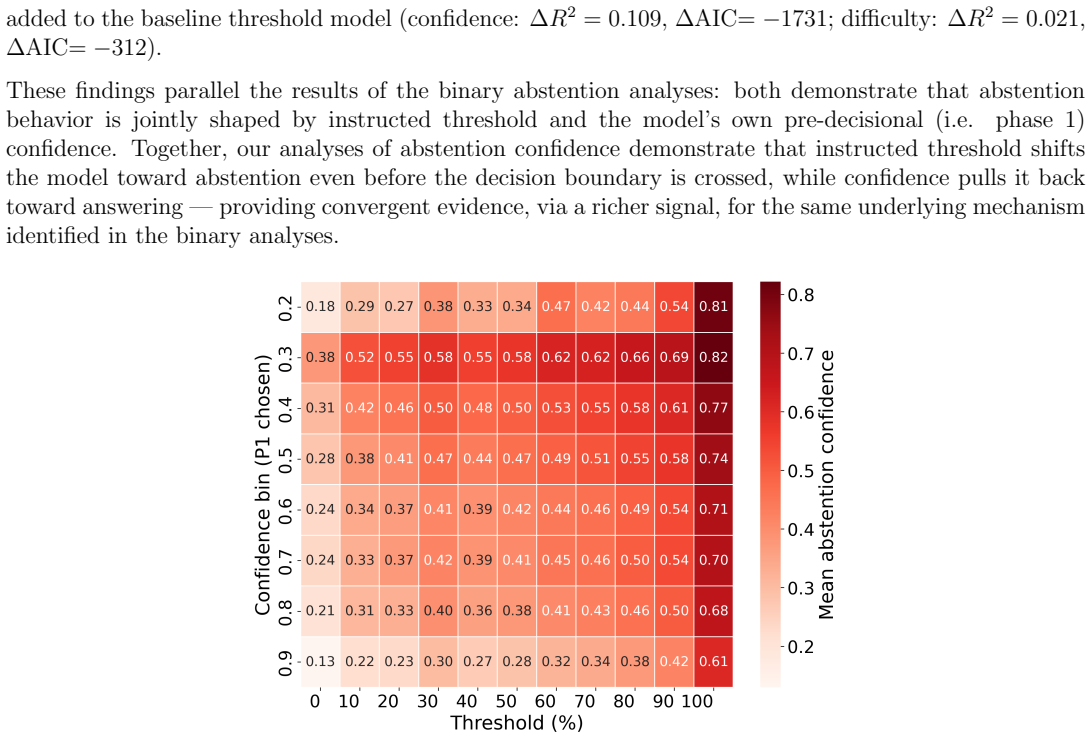
Significance. If the causal claims are supported by robust controls, this work offers valuable evidence for structured metacognitive control in LLMs, extending beyond correlational extraction of confidence signals. The multi-phase design incorporating activation steering as a causal tool is a strength, with implications for model reliability in autonomous agent settings where uncertainty recognition is essential.
major comments (1)
- [Phase 3] Phase 3 (activation steering): The central causal claim rests on steering confidence-related activations to change abstention rates. However, the manuscript provides no quantitative evidence (such as measurements of shifts in unrelated representations like output entropy, general uncertainty signals, or decision thresholds) that the intervention left non-confidence computations unchanged. This leaves open the possibility that observed abstention changes arise from confounding effects rather than selective modulation of a multidimensional confidence signal.
minor comments (2)
- [Abstract] Abstract: The statement that 'verbal confidence independently predicted abstention across all models, despite being objectively less discriminatory of answer correctness' would benefit from explicit definition of how verbal confidence is elicited and quantified, along with the precise statistical comparison to log-probability measures.
- [Phase 4] The manuscript should clarify the exact token position and decoding method used for 'activation decoding at the last pre-answer token' to allow replication of the claim that observable measures are lossy readouts of a richer internal representation.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address the single major comment below and are prepared to strengthen the manuscript with additional analyses.
read point-by-point responses
-
Referee: [Phase 3] Phase 3 (activation steering): The central causal claim rests on steering confidence-related activations to change abstention rates. However, the manuscript provides no quantitative evidence (such as measurements of shifts in unrelated representations like output entropy, general uncertainty signals, or decision thresholds) that the intervention left non-confidence computations unchanged. This leaves open the possibility that observed abstention changes arise from confounding effects rather than selective modulation of a multidimensional confidence signal.
Authors: We agree that explicit quantification of selectivity would strengthen the causal interpretation. The steering vectors were identified via targeted probing for confidence representations, and the resulting behavioral shifts were confined to abstention rates with no detectable changes in overall accuracy or response length distributions. Nevertheless, the original manuscript did not report direct pre/post comparisons on unrelated signals. In the revised version we will add quantitative measurements of output entropy, additional general uncertainty probes, and estimated decision thresholds to demonstrate that the intervention leaves non-confidence computations largely unchanged. revision: yes
Circularity Check
No significant circularity; central claims rest on experimental phases rather than self-referential derivations
full rationale
The paper advances its core argument through a sequence of four empirical phases: baseline confidence elicitation, observation of implicit thresholds, causal activation steering interventions, and systematic variation of instructed thresholds. These rely on direct behavioral measurements and model interventions rather than any mathematical derivation, fitted parameter renamed as prediction, or self-definitional loop. Prior literature on activation steering is invoked only as methodological background and does not serve as a load-bearing self-citation that forces the conclusion about multidimensional internal confidence representations. The results remain independently testable via abstention rates and decoding analyses, with no equations or ansatzes that reduce the claimed causal evidence to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs maintain internal representations of confidence that can be selectively altered via activation steering without major side effects on other behaviors
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Phase 2 revealed that LLMs apply an implicit threshold to internal confidence when deciding to abstain... Phase 3 provided direct causal evidence through activation steering
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Emergent introspective awareness in large language models.https://transformer-circuits
Anthropic. Emergent introspective awareness in large language models.https://transformer-circuits. pub/2025/introspection/,
work page 2025
-
[2]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Learning to route llms with confidence tokens.arXiv preprint arXiv:2410.13284,
Yu-Neng Chuang, Prathusha Kameswara Sarma, Parikshit Gopalan, John Boccio, Sara Bolouki, Xia Hu, and Helen Zhou. Learning to route llms with confidence tokens.arXiv preprint arXiv:2410.13284,
-
[4]
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 55–65,
work page 2019
-
[5]
arXiv preprint arXiv:2510.20487 , year =
Tim Tian Hua, Andrew Qin, Samuel Marks, and Neel Nanda. Steering evaluation-aware language models to act like they are deployed.arXiv preprint arXiv:2510.20487,
-
[6]
Ian T Jolliffe and Jorge Cadima. Principal component analysis: a review and recent developments.Philo- sophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374 (2065):20150202,
work page 2065
-
[7]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. Why language models hallu- cinate.arXiv preprint arXiv:2509.04664,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Abstentionbench: Reasoning llms fail on unanswerable questions.arXiv preprint arXiv:2506.09038,
Polina Kirichenko, Mark Ibrahim, Kamalika Chaudhuri, and Samuel J Bell. Abstentionbench: Reasoning llms fail on unanswerable questions.arXiv preprint arXiv:2506.09038,
-
[10]
Dharshan Kumaran, Stephen M Fleming, Larisa Markeeva, Joe Heyward, Andrea Banino, Mrinal Mathur, Razvan Pascanu, Simon Osindero, Benedetto De Martino, Petar Velickovic, et al. How overconfidence in initial choices and underconfidence under criticism modulate change of mind in large language models. arXiv preprint arXiv:2507.03120,
-
[11]
Nishanth Madhusudhan, Sathwik Tejaswi Madhusudhan, Vikas Yadav, and Masoud Hashemi. Do llms know when to not answer? investigating abstention abilities of large language models.arXiv preprint arXiv:2407.16221,
-
[12]
Steering Llama 2 via Contrastive Activation Addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2402.13213 , year=
Benjamin Plaut, Nguyen X Khanh, and Tu Trinh. Probabilities of chat llms are miscalibrated but still predict correctness on multiple-choice q&a.arXiv preprint arXiv:2402.13213,
-
[14]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992,
work page 2019
-
[15]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting.arXiv preprint arXiv:2310.11324,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, and Besmira Nushi. Improving instruction-following in language models through activation steering.arXiv preprint arXiv:2410.12877,
-
[17]
Linwei Tao, Yi-Fan Yeh, Minjing Dong, Tao Huang, Philip Torr, and Chang Xu. Revisiting uncertainty estimation and calibration of large language models.arXiv preprint arXiv:2505.23854,
-
[18]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback.arXiv preprint arXiv:2305.14975,
-
[19]
Benedict Aaron Tjandra, Muhammed Razzak, Jannik Kossen, Kunal Handa, and Yarin Gal. Fine-tuning large language models to appropriately abstain with semantic entropy.arXiv preprint arXiv:2410.17234,
-
[20]
Christian Tomani, Kamalika Chaudhuri, Ivan Evtimov, Daniel Cremers, and Mark Ibrahim. Uncertainty- based abstention in llms improves safety and reduces hallucinations.arXiv preprint arXiv:2404.10960,
-
[21]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models.arXiv preprint arXiv:2411.04368,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Bingbing Wen, Bill Howe, and Lucy Lu Wang. Characterizing llm abstention behavior in science qa with context perturbations.arXiv preprint arXiv:2404.12452,
-
[24]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Mitigating llm hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563,
Yasin Abbasi Yadkori, Ilja Kuzborskij, David Stutz, Andr´ as Gy¨ orgy, Adam Fisch, Arnaud Doucet, Iuliya Beloshapka, Wei-Hung Weng, Yao-Yuan Yang, Csaba Szepesv´ ari, et al. Mitigating llm hallucinations via conformal abstention.arXiv preprint arXiv:2405.01563,
-
[26]
R-tuning: Instructing large language models to say ‘i don’t know’
Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Instructing large language models to say ‘i don’t know’. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7106–7132,
work page 2024
-
[27]
DK carried out the experiments and analysis with input from ND
Author Contributions DK conceived the project and experimental design. DK carried out the experiments and analysis with input from ND. VP, ND, PV, SO advised on the project. DK wrote the paper, with input from ND, VP, PV, and SO. Acknowledgments We thank Lewis Smith for advice, Charles Blundell for useful discussions, and Kim Stachenfeld for com- ments on...
work page 2020
-
[28]
Baseline level of abstention in no steering condition is 28.8%. Figure 9: GPT4o Phase 4: Response breakdown among answered questions. Increasing threshold increases proportion of correct responses, whilst reducing frequency of similar and dissimilar errors. 6.2 Gemma Activation Steering: Mediation Analysis controlling for diffi- culty with Gemma specific ...
work page 1955
-
[29]
confidence. Together, our analyses of abstention confidence demonstrate that instructed threshold shifts the model toward abstention even before the decision boundary is crossed, while confidence pulls it back toward answering — providing convergent evidence, via a richer signal, for the same underlying mechanism identified in the binary analyses. Figure ...
work page 2017
-
[30]
Model AIC (↓) pseudo-R 2 (↑) Key Likelihood Ratio Tests Threshold only (T) 10021.8 0.342 – Threshold + Confidence 9632.0 0.368 vs. T:χ 2(1) = 391.82, p < .001 Threshold + Difficulty 9824.5 0.355 – Full (T + Confidence + Difficulty) 9544.4 0.374 vs. T+Conf:χ 2(1) = 89.62, p < .001 6.6 Results for DeepSeek 671B 6.6.1 Phase 1 and 2 Results for DeepSeek 671B ...
work page 2017
-
[31]
Model AIC (↓) pseudo-R 2 (↑) Key Likelihood Ratio Tests Threshold only (T) 13798.3 0.092 – Threshold + Confidence 13354.3 0.122 vs. T:χ 2(1) = 445.93, p < .001 Threshold + Difficulty 13540.5 0.109 – Full (T + Confidence + Difficulty) 13206.1 0.132 vs. T+Conf:χ 2(1) = 150.26, p < .001 6.7 Results for Qwen 80B 6.7.1 Phase 1 and 2 Results for Qwen 80B Qwen 8...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.