Recognition: unknown
From Intent to Evidence: A Categorical Approach for Structural Evaluation of Deep Research Agents
Pith reviewed 2026-05-15 00:21 UTC · model grok-4.3
The pith
A category-theoretic framework shows that even top deep research agents achieve only 19.9 percent accuracy on key structural tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
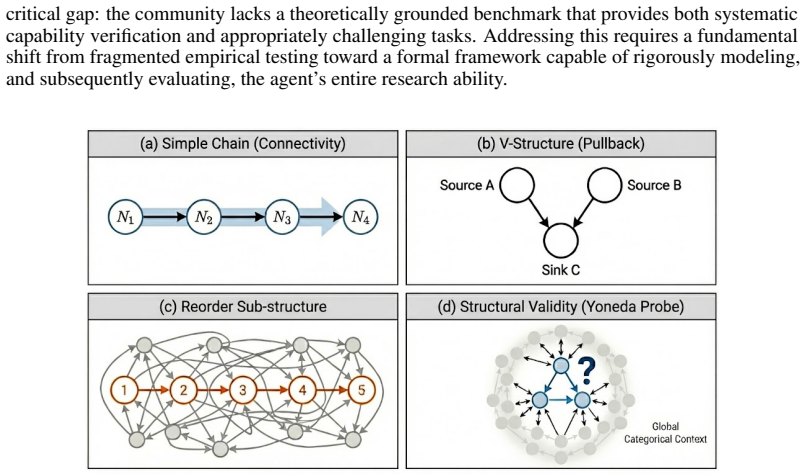
The paper claims that deep research can be formalized as a categorical mapping from intent to evidence, which allows derivation of a benchmark targeting multi-hop evidence following, cross-source claim verification, fragmented information reordering, and unsupported assumption rejection. Evaluation of frontier agents shows low performance with a maximum of 19.9% accuracy, while theory-guided interventions such as tracked search and category tools produce measurable improvements in system reliability.
What carries the argument
The category-theoretic framework that models deep research as a structured mapping from user intent to evidence-grounded conclusions, making retrieval traces, alignments, and synthesis explicit.
Load-bearing premise
The category-theoretic abstraction accurately represents the core structure of deep research without introducing modeling artifacts that distort the measured skills.
What would settle it
A controlled experiment where agents improved on real-world research tasks without improving on this benchmark, or improved on the benchmark without real-world gains, would indicate the framework does not capture essential research structure.
Figures





read the original abstract
Deep Research Agents (DRAs) aim to answer complex questions by searching the web, checking evidence, and synthesizing conclusions across heterogeneous sources. We introduce a category-theoretic framework for evaluating and improving such agents. The framework treats deep research as a structured mapping from user intent to evidence-grounded conclusions, making retrieval traces, cross-source alignment, and final synthesis explicit. Guided by this view, we derive a mechanism-aware benchmark of 296 bilingual questions. The benchmark targets four structural skills central to real research: following multi-hop evidence chains, verifying claims across sources, re-ordering fragmented information, and rejecting unsupported assumptions. We evaluate 16 frontier systems with human verification and find that these structural tasks remain highly challenging: the best system reaches only 19.9% average accuracy. The results show that strong agents can sometimes reorganize evidence and detect false premises, but still struggle with long-horizon synthesis and intersection-heavy verification. Beyond evaluation, the same theory also leads to practical system improvements. We instantiate theory-guided interventions such as tracked search, which preserves retrieval traces, and category tools, which add explicit verification and synthesis steps. These interventions yield measurable gains in API-based deep research systems. Our work therefore provides both a challenging benchmark and concrete design guidance for building more reliable research agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a category-theoretic framework for deep research agents (DRAs) that models the mapping from user intent to evidence-grounded conclusions, making retrieval traces and synthesis explicit. It derives a 296-question bilingual benchmark targeting four structural skills (multi-hop evidence chains, cross-source verification, re-ordering fragmented information, and rejecting unsupported assumptions). Evaluation of 16 frontier systems with human verification shows low performance, with the best system at 19.9% average accuracy. The framework is further used to guide interventions such as tracked search and category tools, which are claimed to yield measurable gains in API-based systems.
Significance. If the results hold, the work would provide a structurally grounded benchmark that highlights persistent weaknesses in long-horizon synthesis and verification for DRAs, along with concrete intervention guidance that could improve agent reliability. The explicit use of category theory to derive both the benchmark and the interventions is a potential strength for falsifiability and design insight, but the absence of ablations, raw data, or derivation details limits the ability to confirm that the framework itself drives the reported gains rather than generic structuring.
major comments (3)
- [Abstract] Abstract: the claim that 'the same theory also leads to practical system improvements' via tracked search and category tools is load-bearing for the improvement half of the thesis, yet no control arm is described that applies equivalent explicit tracking or verification steps without the categorical decomposition or four-skill framing. If generic structured prompting produces statistically indistinguishable deltas on the 296-question set, the framework is not shown to be necessary.
- [Abstract] Abstract (benchmark derivation): the 296 questions are presented as derived from the category-theoretic view, but no description is given of question construction, validation against the four targeted skills, or controls for modeling artifacts. This directly affects whether the benchmark validly measures the claimed structural skills.
- [Evaluation] Evaluation section: the reported 19.9% best-system accuracy and human verification results lack any mention of inter-annotator agreement, error bars, statistical tests, or raw data release, undermining the ability to assess the robustness of the performance claims or the intervention gains.
minor comments (2)
- [Abstract] Abstract: 'bilingual questions' is stated without specifying the languages or the motivation for bilingualism in the structural evaluation.
- [Abstract] Abstract: the term 'mechanism-aware benchmark' is used without clarifying what 'mechanism' denotes in the category-theoretic mapping.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the same theory also leads to practical system improvements' via tracked search and category tools is load-bearing for the improvement half of the thesis, yet no control arm is described that applies equivalent explicit tracking or verification steps without the categorical decomposition or four-skill framing. If generic structured prompting produces statistically indistinguishable deltas on the 296-question set, the framework is not shown to be necessary.
Authors: We agree that a direct comparison to generic structured prompting would strengthen the claim that the categorical framework is necessary for the observed gains. The interventions were specifically derived from the category theory to address the four structural skills (e.g., tracked search preserves morphisms for multi-hop chains). However, the current experiments compare to baseline agents without such explicit steps. In the revision, we will add a control condition using generic structured prompting with equivalent tracking and verification prompts, and report the comparative results on the benchmark. This will clarify whether the framework provides unique benefits beyond generic structuring. revision: partial
-
Referee: [Abstract] Abstract (benchmark derivation): the 296 questions are presented as derived from the category-theoretic view, but no description is given of question construction, validation against the four targeted skills, or controls for modeling artifacts. This directly affects whether the benchmark validly measures the claimed structural skills.
Authors: The 296 questions were generated by first defining the four structural skills as specific compositions in the category (intent to evidence to conclusion), then creating questions that require those compositions. Validation involved expert review to ensure each question targets the intended skill without artifacts. Due to length constraints, these details were summarized in the abstract and methods. We will expand the 'Benchmark Construction' subsection in the revision to provide the full derivation process, including examples of question templates, validation criteria, and controls (e.g., ensuring no leakage from training data). We believe this will confirm the benchmark's validity. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported 19.9% best-system accuracy and human verification results lack any mention of inter-annotator agreement, error bars, statistical tests, or raw data release, undermining the ability to assess the robustness of the performance claims or the intervention gains.
Authors: We acknowledge the importance of these statistical details for assessing robustness. In the revised version, we will add inter-annotator agreement metrics (computed via Cohen's kappa), error bars on the accuracy figures, statistical significance tests for the intervention improvements, and release the raw annotations and system outputs in a public repository. These will be detailed in the Evaluation section. revision: yes
Circularity Check
No significant circularity: framework, benchmark, and empirical results are independently constructed
full rationale
The paper defines a category-theoretic mapping from intent to evidence, uses it to motivate a new 296-question benchmark targeting four observable structural skills (multi-hop chains, cross-source verification, re-ordering, and premise rejection), and reports human-verified accuracy numbers on 16 external frontier systems. These accuracy figures are measured outcomes, not quantities algebraically forced by the framework's own definitions or by any fitted parameters internal to the paper. The reported interventions (tracked search, category tools) are described as practical instantiations that produce measurable deltas; nothing in the supplied text shows these deltas reducing by construction to the same categorical decomposition used to score the benchmark. No self-citation chain, uniqueness theorem, or ansatz is invoked as load-bearing justification for the central claims. The derivation therefore remains self-contained against external system evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Category theory provides a suitable structure for modeling mappings from user intent to evidence-grounded conclusions
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2508.06600. Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents, 2025. URL https://arxiv.org/abs/ 2506.11763. Brendan Fong, David Spivak, and Rémy Tuyéras. Backprop as functor: A compositional perspective on supervised learning. In2019 34th Ann...
-
[2]
URLhttps://arxiv.org/abs/2501.07572. xAI. Grok 4: A large language model. https://docs.x.ai/docs/models# models-and-pricing, 2025. Accessed: April 2026. Renjun Xu and Jingwen Peng. A comprehensive survey of deep research: Systems, methodologies, and applications, 2025. URLhttps://arxiv.org/abs/2506.12594. Yang Yuan. On the power of foundation models. InIn...
-
[3]
URLhttps://arxiv.org/abs/2504.19314. 18 Appendix A DETAILEDPROOFS Theorem A.1(Categorical Validity of Agentic State Spaces).Let Q, W, Sub(W), and A be the agentic state spaces equipped with their respective objects and relations. If we define the morphisms in Q, W, and A as above, then all four spaces strictly satisfy the Eilenberg-Mac Lane axioms and thu...
-
[4]
• Identity:For any query q∈Ob(Q) , resolving q trivially depends on itself
The Intent Category Q (Query Space):We model Q as a thin category (a preorder) where at most one morphism exists between any two queries. • Identity:For any query q∈Ob(Q) , resolving q trivially depends on itself. Thus, we assign the identity morphismid q :q→q. • Composition:Let q1, q2, q3 ∈Ob(Q) . If f:q 1 dep − − →q2 (resolving q2 depends on q1) and g:q...
-
[5]
The Knowledge Category W (Web Space):To ensure compositional closure, we define the morphisms of W as the paths (the free category construction) generated by the directed graph of hyperlinks and direct causal premises. • Identity:For any web entity w∈Ob(W) , it trivially serves as a premise for its own semantic content. This constitutes the empty path, se...
-
[6]
This defines the identity inclusion mapid G :G ,→G
The Retrieval SubcategorySub(W): • Identity:For any retrieved subgraph G∈Ob(Sub(W)) , the subset relation is reflexive (G⊆G). This defines the identity inclusion mapid G :G ,→G. • Composition:Let G1, G2, G3 be subgraphs. If i:G 1 ,→G 2 and j:G 2 ,→G 3 are inclusion mappings, standard set theory guarantees G1 ⊆G 3. The function composition of two inclusion...
-
[7]
The Reasoning Category A (Logic Space):We model A analogously to a deductive system (a propositional category). • Identity:For any proposition a∈Ob(A) , the implication a=⇒a is a fundamental logical tautology (the law of identity). This serves as the identity morphismid a :a→a. • Composition:If we have logical entailments f:a 1 =⇒a 2 and g:a 2 =⇒a 3, the ...
work page 2025
-
[8]
entirely built upon the library versions installed by a senior student previously
THETECHNICALEXECUTIONFLAW(THEDEPENDENCYTRAP) The timeline of the student’s personal contribution describes a scenario that is practically impossible without entirely rewriting the codebase or resolving massive dependency conflicts, which contradicts the claim that the work was “entirely built upon the library versions installed by a senior student previou...
work page 2023
-
[9]
compliance- oriented hybrid storage system
ACADEMICNOVELTYASSESSMENT Even if we assume the technical hurdles were silently resolved, the theoretical novelty of the work is insufficient for a doctoral dissertation award. • Applied Engineering vs. Foundational Research:Constructing a “compliance- oriented hybrid storage system” by combining SQL (permission hierarchies) and NoSQL (document fragmentat...
work page 2025
-
[10]
Software Costs (ASC 350-40) The closest relevant guidance arises from the FASB’s ongoing modernization efforts related to software cost accounting, particularly under ASC 350-40. These updates are motivated by the inadequacy of legacy frameworks in handling agile development cycles and AI model training. A key structural shift in the proposed updates is t...
-
[11]
Fair Value Measurement (ASC 820 and ASC 805) When generative AI assets are acquired through a business combination, they must be recognized at fair value in accordance with ASC 805, with measurement governed by ASC 820. Three primary valuation approaches are applied: • Cost Approach:This is the most commonly applied method for AI assets. It esti- mates th...
-
[12]
GAAP is the treatment of training data
The “Data” Recognition Problem A persistent limitation within current U.S. GAAP is the treatment of training data. Costs associated with acquiring, scraping, and curating large-scale datasets are generally expensed as incurred rather than capitalized. This creates a structural disconnect between the reported book value of technology firms and the economic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.