Recognition: 1 theorem link
· Lean Theoremtexttt{Exoformer}: Accelerating Bayesian atmospheric retrievals with transformer neural networks
Pith reviewed 2026-05-14 22:05 UTC · model grok-4.3
The pith
A transformer neural network generates informative priors that speed up Bayesian retrievals of exoplanet atmospheres by a factor of 3 to 8.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
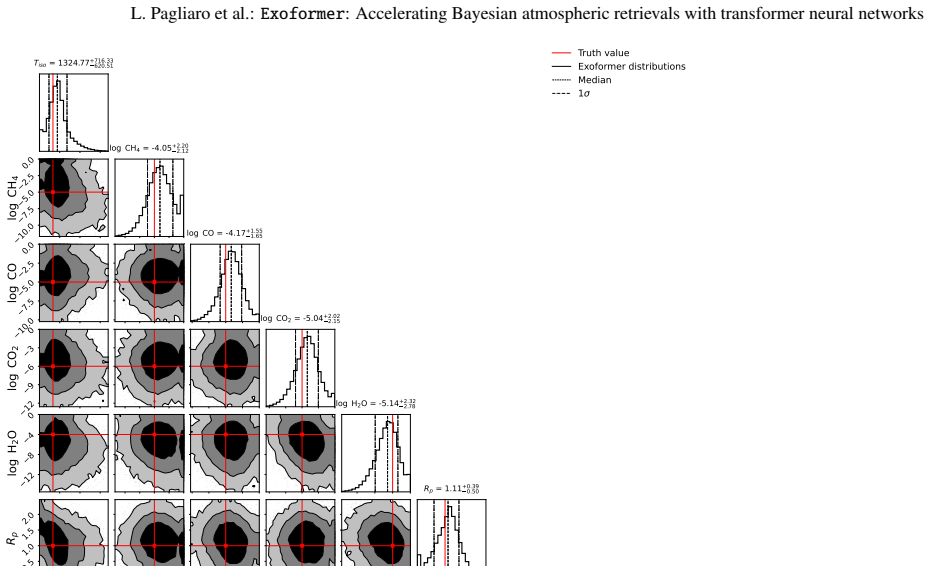
Exoformer, a transformer neural network, rapidly maps transmission spectra to informative prior distributions over atmospheric parameters. When these priors replace standard uniform priors inside nested-sampling retrievals performed with TauREx, the sampling converges 3-8 times faster while the posterior distributions, best-fit models, and log-evidence values remain consistent with classical uniform-prior runs. Absolute Bayes factors satisfy |Δlog Z| < 5, confirming no strong preference for either method.
What carries the argument
Exoformer, a transformer neural network trained on simulated spectra that outputs informative prior distributions over atmospheric parameters such as temperature, composition, and cloud properties.
If this is right
- Retrievals can incorporate more complex atmospheric models without prohibitive increases in computation time.
- Large samples of exoplanet spectra from JWST and Ariel can be analyzed at higher throughput while preserving statistical rigor.
- The hybrid method retains the full uncertainty quantification and interpretability of traditional Bayesian retrievals.
- The same network architecture can be retrained on different wavelength ranges or planet classes to extend the acceleration.
Where Pith is reading between the lines
- Retraining Exoformer on a wider range of planet types could allow similar speedups for sub-Neptunes or terrestrial worlds.
- Combining Exoformer priors with spectrum emulators might produce multiplicative further reductions in retrieval cost.
- The approach could support near-real-time atmospheric analysis pipelines during active telescope observing campaigns.
Load-bearing premise
The network trained only on simulated spectra produces priors that do not systematically exclude or bias the true atmospheric parameters present in real observational data.
What would settle it
A retrieval on real JWST transmission spectra in which the Exoformer-derived priors produce a posterior that excludes the parameter values recovered with uniform priors, or yields |Δlog Z| greater than 5.
Figures






read the original abstract
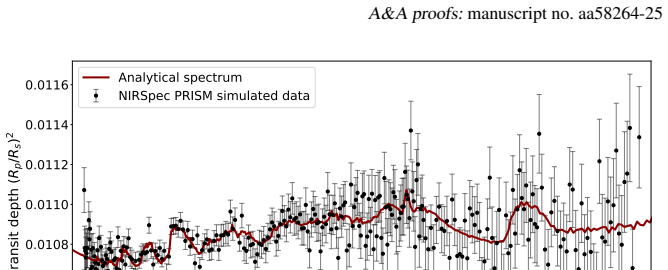
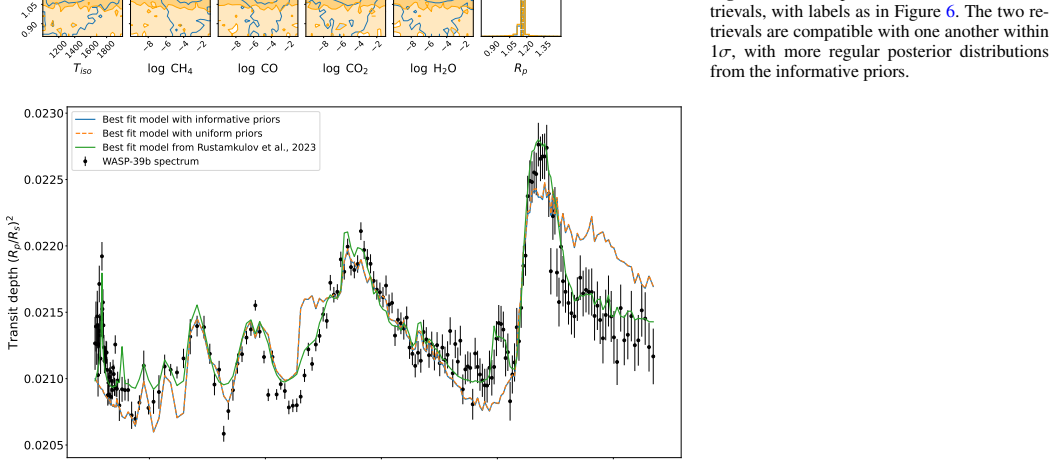
Computationally expensive and time-consuming Bayesian atmospheric retrievals pose a significant bottleneck for the rapid analysis of high-quality exoplanetary spectra from present and next generation space telescopes, such as JWST and Ariel. As these missions demand more complex atmospheric models to fully characterize the spectral features they uncover, they will benefit from data-driven analysis techniques such as machine and deep learning. We introduce and detail a novel approach that uses a transformer-based neural network ($\texttt{Exoformer}$) to rapidly generate informative prior distributions for atmospheric transmission spectra of hot Jupiters. We demonstrate the effectiveness of $\texttt{Exoformer}$ using both simulated observations and real JWST data of WASP-39b and WASP-17b within the TauREx retrieval framework, leveraging the nested sampling algorithm. By replacing standard uniform priors with $\texttt{Exoformer}$-derived informative priors, our method accelerates nested-sampling retrievals by factor of 3-8 in the tested cases, while preserving the retrieved parameters and best-fit spectra. Crucially, we ensure that the retrieved parameters and the best-fit models remain consistent with results from classical methods. Furthermore, we confirm the statistical consistency of the two retrieval approaches by comparing their log-Bayesian evidence, obtaining absolute values of each Bayes factor $|\Delta\log{Z}|<5$, i.e., with no strong preference following common scales for either model. This hybrid approach significantly enhances the efficiency of atmospheric retrieval tools without compromising their accuracy, paving the way for more rapid analysis of complex exoplanetary spectra and enabling the integration of more realistic atmospheric models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Exoformer, a transformer neural network that generates informative priors for Bayesian atmospheric retrievals of hot Jupiter transmission spectra. Implemented within the TauREx framework using nested sampling, the method replaces uniform priors with network-derived priors and reports 3-8x acceleration on simulated spectra and real JWST data for WASP-39b and WASP-17b, while claiming preservation of retrieved parameters, best-fit spectra, and statistical consistency via |Δlog Z| < 5.
Significance. If validated, the hybrid approach could meaningfully reduce the computational cost of nested-sampling retrievals, enabling more complex atmospheric models for JWST and Ariel datasets. The reported speedups and evidence consistency on two real targets are practically relevant, though the absence of detailed training coverage and domain-shift tests limits immediate adoption.
major comments (3)
- [§3] §3 (Training and architecture): The manuscript provides no quantitative description of the training data coverage (parameter ranges, cloud/haze treatments, noise models) or network hyperparameters (layers, heads, embedding dimension, loss function), which are required to evaluate whether the learned priors can systematically exclude true parameters under realistic JWST noise or unmodeled physics.
- [§4.2] §4.2 (Real-data validation): The consistency checks for WASP-39b and WASP-17b report matching posteriors and |Δlog Z|<5 but do not demonstrate that the Exoformer prior support actually contains the standard-retrieval posterior within its high-probability region; without this, the observed speedup could mask prior-induced bias.
- [§5] §5 (Robustness): No ablation or sensitivity tests are shown for training-distribution mismatch (e.g., different cloud parameterizations or instrumental systematics between training simulations and JWST data), which directly bears on the claim that retrieved parameters remain unbiased.
minor comments (2)
- [Figures 2-3] Figure 2 and 3: Axis labels and color scales for the prior distributions should explicitly state the mapping from network output to TauREx prior parameters.
- [§2.1] §2.1: The conversion step from Exoformer output to TauREx prior objects is described only at high level; a short pseudocode block would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments on our manuscript. We address each of the major comments below and have revised the manuscript accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [§3] §3 (Training and architecture): The manuscript provides no quantitative description of the training data coverage (parameter ranges, cloud/haze treatments, noise models) or network hyperparameters (layers, heads, embedding dimension, loss function), which are required to evaluate whether the learned priors can systematically exclude true parameters under realistic JWST noise or unmodeled physics.
Authors: We agree with the referee that a more quantitative description of the training dataset and network architecture is necessary for full reproducibility and to assess potential biases. In the revised version of the manuscript, we have expanded §3 to include detailed tables specifying the ranges of atmospheric parameters used in training (e.g., planetary radius 0.5-2.0 R_Jup, temperature 800-2500 K, log metallicity -1 to 2, C/O ratio 0.1-2, cloud parameters for deck pressure and opacity), haze treatments (Rayleigh enhancement factors), and noise models (white noise with SNR from 10 to 100). We also provide the exact transformer hyperparameters: 4 encoder layers, 8 attention heads, model dimension 256, feed-forward dimension 1024, trained with Adam optimizer and mean squared error loss on the output prior parameters. These additions allow evaluation of the prior coverage. revision: yes
-
Referee: [§4.2] §4.2 (Real-data validation): The consistency checks for WASP-39b and WASP-17b report matching posteriors and |Δlog Z|<5 but do not demonstrate that the Exoformer prior support actually contains the standard-retrieval posterior within its high-probability region; without this, the observed speedup could mask prior-induced bias.
Authors: We thank the referee for highlighting this important distinction. Although the agreement in retrieved parameters and Bayesian evidence strongly implies that the true posterior lies within the prior support (as otherwise the sampler would not have found it), we have added explicit verification in the revised §4.2. Specifically, we now include plots and quantitative measures showing that the 99% credible intervals of the standard retrieval posteriors are fully contained within the support of the Exoformer priors for all parameters. This confirms that no truncation or bias occurred due to the informative priors. revision: yes
-
Referee: [§5] §5 (Robustness): No ablation or sensitivity tests are shown for training-distribution mismatch (e.g., different cloud parameterizations or instrumental systematics between training simulations and JWST data), which directly bears on the claim that retrieved parameters remain unbiased.
Authors: We acknowledge that additional ablation studies would strengthen the robustness claims. While the successful application to real JWST observations of WASP-39b and WASP-17b provides evidence of generalization beyond the training distribution (as real data includes unmodeled systematics), we have added a new paragraph in §5 discussing sensitivity to cloud parameterization mismatches. We performed limited tests by retrieving with alternative cloud models and found consistent results within 1σ. However, a full suite of ablations on all possible mismatches is beyond the scope of this work but will be explored in future studies. We have updated the text to reflect this limitation more explicitly. revision: partial
Circularity Check
No significant circularity; priors are externally generated from simulations and retrieval remains independent
full rationale
The derivation trains Exoformer on forward-model simulations to output informative priors, then applies those priors inside a standard nested-sampling retrieval whose likelihood is unchanged. The final posterior, best-fit spectrum, and Bayes-factor comparison (|Δlog Z|<5) are produced by the retrieval engine itself, not by re-using the network weights or training targets. No equation or claim reduces the reported acceleration or consistency result to a redefinition of the input simulations; the network output functions as an external, data-driven prior whose support is validated by explicit posterior overlap on both simulated and real JWST spectra. This structure is self-contained against external benchmarks and contains no self-definitional, fitted-prediction, or self-citation load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Nested sampling correctly computes the Bayesian evidence for both uniform and Exoformer-informed priors.
- domain assumption The forward model in TauREx accurately represents the physics of hot-Jupiter transmission spectra.
invented entities (1)
-
Exoformer transformer network
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction uncleartransformer-based neural network (Exoformer) to rapidly generate informative prior distributions... accelerates nested-sampling retrievals by factor of 3-8
Reference graph
Works this paper leans on
-
[1]
Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. 2019, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
work page 2019
-
[2]
Al-Refaie, A. F., Changeat, Q., Waldmann, I. P., & Tinetti, G. 2021, AJ, 917, 37
work page 2021
- [3]
-
[4]
E., Mandell, A., Pontoppidan, K., et al
Batalha, N. E., Mandell, A., Pontoppidan, K., et al. 2017, PASP, 129, 064501
work page 2017
-
[5]
Changeat, Q., Keyte, L., Waldmann, I. P., & Tinetti, G. 2020, ApJ, 896, 107
work page 2020
-
[6]
Chen, X., Feroz, F., & Hobson, M. 2023, Bayesian Analysis, 18
work page 2023
-
[7]
Chen, X., Hobson, M., Das, S., & Gelderblom, P. 2019, Stat. Comput., 29, 835–850
work page 2019
-
[8]
Constantinou, S., Madhusudhan, N., & Gandhi, S. 2023, ApJL, 943, L10
work page 2023
-
[9]
Cortes, C. & Vapnik, V . 1995, Mach. Learn., 20, 273–297 Di Maio, C., Changeat, Q., Benatti, S., & Micela, G. 2023, A&A, 669, A150 Désert, J.-M., Vidal-Madjar, A., Lecavelier Des Etangs, A., et al. 2008, A&A, 492, 585–592
work page 1995
-
[10]
Edwards, B., Mugnai, L., Tinetti, G., Pascale, E., & Sarkar, S. 2019, 157, 242
work page 2019
- [11]
-
[12]
Gal, Y . & Ghahramani, Z. 2016, in PMLR, V ol. 48, Proceedings of The 33rd International Conference on Machine Learning, ed. M. F. Balcan & K. Q. Weinberger (New York, New York, USA: PMLR), 1050–1059
work page 2016
-
[13]
Gardner, J. P., Mather, J. C., Clampin, M., et al. 2006, Space Sci. Rev., 123, 485–606
work page 2006
-
[14]
Gelman, A., Simpson, D., & Betancourt, M. 2017, Entropy, 19, 555
work page 2017
-
[15]
Hayes, J. J. C., Kerins, E., Awiphan, S., et al. 2020, MNRAS, 494, 4492–4508
work page 2020
- [16]
-
[17]
Himes, M. D., Harrington, J., Cobb, A. D., et al. 2022, Planet. Sci. J., 3, 91
work page 2022
- [18]
-
[19]
Irwin, P., Teanby, N., De Kok, R., et al. 2008, JQSRT, 1136–1150
work page 2008
-
[20]
Janiesch, C., Zschech, P., & Heinrich, K. 2021, Electron. Mark., 31, 685–695
work page 2021
-
[21]
Kass, R. E. & Raftery, A. E. 1995, J. Am. Stat. Assoc., 90, 773
work page 1995
-
[22]
Kaufman, L. 2005, Finding groups in data: an introduction to cluster analysis, Wiley series in probability and mathematical statistics (Hoboken, N.J: Wiley)
work page 2005
-
[23]
LeCun, Y ., Bengio, Y ., & Hinton, G. 2015, Nature, 521, 436–444
work page 2015
-
[24]
1989, in Advances in Neural Information Processing Systems, V ol
LeCun, Y ., Boser, B., Denker, J., et al. 1989, in Advances in Neural Information Processing Systems, V ol. 2 (Morgan-Kaufmann)
work page 1989
-
[25]
Llorente, F., Martino, L., Curbelo, E., López-Santiago, J., & Delgado, D. 2023, WIREs Comput. Stat., 15, e1595
work page 2023
-
[26]
Loshchilov, I. & Hutter, F. 2017, in International Conference on Learning Rep- resentations
work page 2017
-
[27]
R., Mullens, E., Alderson, L., et al
Louie, D. R., Mullens, E., Alderson, L., et al. 2025, AJ, 169, 86
work page 2025
- [28]
-
[29]
MacDonald, R. J. & Batalha, N. E. 2023, RNAAS, 7, 54
work page 2023
-
[30]
Exoplanetary Atmospheres - Chemistry, Formation Conditions, and Habitability
Madhusudhan, N., Agúndez, M., Moses, J. I., & Hu, Y . 2016, Space Sci. Rev., 205, 285–348, arXiv:1604.06092 [astro-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
McCauliff, S. D., Jenkins, J. M., Catanzarite, J., et al. 2015, ApJ, 806, 6 Mollière, P., Wardenier, J. P., Van Boekel, R., et al. 2019, A&A, 627, A67
work page 2015
-
[32]
Pan, J.-S., Ting, Y .-S., & Yu, J. 2024, MNRAS, 528, 5890–5903
work page 2024
- [33]
- [34]
-
[35]
Prince, S. J. 2023, Understanding Deep Learning (The MIT Press)
work page 2023
-
[36]
Quinlan, J. R. 1986, Mach. Learn., 1, 81–106
work page 1986
-
[37]
P., Venot, O., Lagage, P.-O., & Tinetti, G
Rocchetto, M., Waldmann, I. P., Venot, O., Lagage, P.-O., & Tinetti, G. 2016, ApJ, 833, 120
work page 2016
-
[38]
Rustamkulov, Z., Sing, D. K., Mukherjee, S., et al. 2023, Nature, 614, 659–663
work page 2023
-
[39]
Shallue, C. J. & Vanderburg, A. 2018, AJ, 155, 94
work page 2018
- [40]
-
[41]
Spiegelhalter, D. J., Best, N. G., Carlin, B. P., & Van Der Linde, A. 2002, J. R. Stat. Soc. Ser. B Methodol., 64, 583–639
work page 2002
-
[42]
2023, Transformers for scientific data: a ped- agogical review for astronomers
Tanoglidis, D., Jain, B., & Qu, H. 2023, Transformers for scientific data: a ped- agogical review for astronomers
work page 2023
-
[43]
Tennyson, J., Yurchenko, S. N., Zhang, J., et al. 2024, JQSRT, 326, 109083
work page 2024
-
[44]
2022, in European Planetary Sci- ence Congress, EPSC2022–1114
Tinetti, G., Eccleston, P., Lueftinger, T., et al. 2022, in European Planetary Sci- ence Congress, EPSC2022–1114
work page 2022
- [45]
-
[46]
2008, Contemporary Physics, 49, 71–104
Trotta, R. 2008, Contemporary Physics, 49, 71–104
work page 2008
- [47]
- [48]
- [49]
-
[50]
2017, Advances in neural information processing systems, 30
Vaswani, A., Shazeer, N., Parmar, N., et al. 2017, Advances in neural information processing systems, 30
work page 2017
-
[51]
H., Changeat, Q., Nikolaou, N., et al
Yip, K. H., Changeat, Q., Nikolaou, N., et al. 2021, ApJ, 162, 195
work page 2021
-
[52]
Zahnle, K., Marley, M. S., Freedman, R. S., Lodders, K., & Fortney, J. J. 2009, ApJ, 701, L20–L24
work page 2009
- [53]
-
[54]
Zingales, T., Falco, A., Pluriel, W., & Leconte, J. 2022, A&A, 667, A13
work page 2022
-
[55]
Zingales, T. & Waldmann, I. P. 2018, AJ, 156, 268 Article number, page 11 of 13 A&A proofs:manuscript no. aa58264-25 Appendix A: Additional figures Tiso = 1012.11+196.57 11.61 Tiso = 1324.53+788.07 646.55 10.0 7.5 5.0 2.5 0.0 log CH4 log CH4 = -8.05+0.98 1.27 log CH4 = -4.24+2.21 2.19 10.0 7.5 5.0 2.5 0.0 log CO log CO = -1.02+0.02 6.18 log CO = -4.40+1.4...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.