Recognition: 2 theorem links
· Lean TheoremRethinking Language Model Scaling under Transferable Hypersphere Optimization
Pith reviewed 2026-05-14 21:47 UTC · model grok-4.3
The pith
HyperP transfers one base learning rate across all scales under the Frobenius-sphere constraint, delivering 1.58 times compute efficiency at 6e21 FLOPs while keeping instability bounded.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
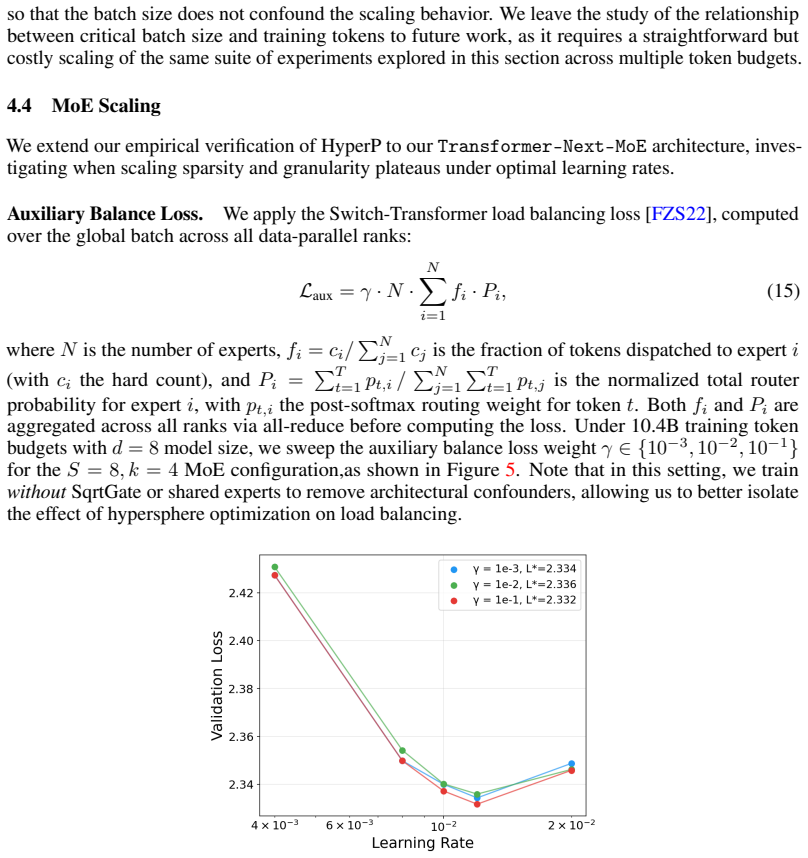
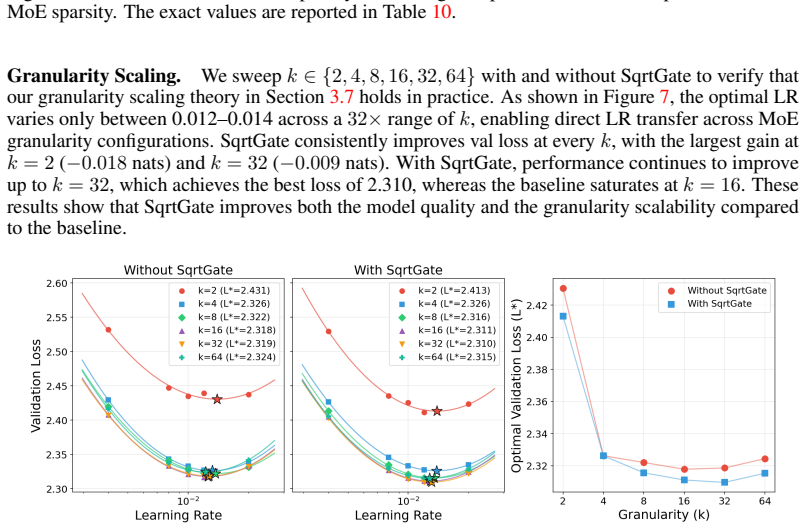
Under the Frobenius-sphere constraint with the Muon optimizer, the optimal learning rate obeys the same 0.32 data-scaling exponent previously seen for AdamW, so a base rate tuned at the smallest scale transfers across all larger compute budgets. This yields 1.58× compute efficiency at 6×10^21 FLOPs over a strong Muon baseline while all instability indicators (Z-values, output RMS, activation outliers) stay bounded and non-increasing. Weight decay becomes a first-order no-op on the sphere, Depth-μP remains necessary, and SqrtGate enables stable MoE granularity scaling with larger auxiliary load-balancing weights.
What carries the argument
The Frobenius-sphere constraint on weight matrices together with the Muon optimizer, which enforces fixed-norm weights and removes the need for per-scale learning-rate retuning.
If this is right
- One learning rate tuned at small scale works across every larger width, depth, token count, and MoE setting.
- Instability indicators remain bounded as training FLOPs increase.
- MoE models can use larger auxiliary load-balancing weights while staying balanced and performant.
- SqrtGate preserves output RMS across different MoE granularities.
Where Pith is reading between the lines
- The same sphere constraint might remove retuning needs for optimizers other than Muon.
- Checking transfer at scales beyond 6×10^21 FLOPs would test whether the 0.32 exponent continues to hold.
- Applying the sphere constraint to non-language models could show whether the stability transfer generalizes.
Load-bearing premise
The Frobenius-sphere constraint plus Muon optimizer preserves the 0.32 data-scaling exponent and prevents instability without any per-scale hyperparameter retuning.
What would settle it
Train a model at 10^22 FLOPs using the single small-scale tuned learning rate and check whether any instability indicator (Z-value, output RMS, or activation outlier count) begins to rise or whether efficiency falls below the predicted 1.58× gain.
Figures












read the original abstract
Scaling laws for large language models depend critically on the optimizer and parameterization. Existing hyperparameter transfer laws are mainly developed for first-order optimizers, and they do not structurally prevent training instability at scale. Recent hypersphere optimization methods constrain weight matrices to a fixed-norm hypersphere, offering a promising alternative for more stable scaling. We introduce HyperP (Hypersphere Parameterization), the first framework for transferring optimal learning rates across model width, depth, training tokens, and Mixture-of-Experts (MoE) granularity under the Frobenius-sphere constraint with the Muon optimizer. We prove that weight decay is a first-order no-op on the Frobenius sphere, show that Depth-$\mu$P remains necessary, and find that the optimal learning rate follows the same data-scaling power law with the "magic exponent" 0.32 previously observed for AdamW. A single base learning rate tuned at the smallest scale transfers across all compute budgets under HyperP, yielding $1.58\times$ compute efficiency over a strong Muon baseline at $6\times10^{21}$ FLOPs. Moreover, HyperP delivers transferable stability: all monitored instability indicators, including $Z$-values, output RMS, and activation outliers, remain bounded and non-increasing under training FLOPs scaling. We also propose SqrtGate, an MoE gating mechanism derived from the hypersphere constraint that preserves output RMS across MoE granularities for improved granularity scaling, and show that hypersphere optimization enables substantially larger auxiliary load-balancing weights, yielding both strong performance and good expert balance. We release our training codebase at https://github.com/microsoft/ArchScale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyperP, a hypersphere parameterization framework that constrains weight matrices to the Frobenius sphere and pairs it with the Muon optimizer. It proves that weight decay acts as a first-order no-op under this constraint, shows that Depth-μP remains necessary, and reports that the optimal learning rate obeys the same 0.32 data-scaling exponent previously observed for AdamW. A single base learning rate tuned at the smallest scale is claimed to transfer across width, depth, token count, and MoE granularity, delivering 1.58× compute efficiency over a strong Muon baseline at 6×10^21 FLOPs while keeping instability indicators (Z-values, output RMS, activation outliers) bounded and non-increasing. The work also proposes SqrtGate, an MoE gating mechanism derived from the hypersphere constraint, and demonstrates that larger auxiliary load-balancing weights can be used without harming expert balance. The training codebase is released.
Significance. If the transfer result and exponent invariance hold, the work offers a concrete route to reduce per-scale hyperparameter retuning for hypersphere-based optimizers, which could simplify scaling experiments and improve training stability at frontier compute budgets. The explicit proof that weight decay is a first-order no-op, the requirement for Depth-μP, the SqrtGate construction, and the public code release are all positive contributions that strengthen the manuscript's utility to the community.
major comments (2)
- [Empirical scaling results and learning-rate transfer section] The central transfer claim at 6×10^21 FLOPs rests on the data-scaling exponent for the optimal learning rate remaining exactly 0.32 under the Frobenius-sphere + Muon dynamics. The manuscript reports that this exponent matches prior AdamW observations from small-scale fits, but provides no derivation or invariance argument showing why the hypersphere constraint preserves the exponent when width, depth, tokens, and MoE granularity are scaled simultaneously. If the effective exponent shifts even modestly, the fixed base LR would mis-tune at the largest budget, undermining both the 1.58× efficiency figure and the “no per-scale retuning” claim.
- [Large-scale experiments and efficiency comparison] The 1.58× compute-efficiency comparison at 6×10^21 FLOPs is presented against a “strong Muon baseline.” The manuscript must specify exactly how the baseline was tuned (whether it received per-scale LR retuning or used the same transfer protocol) and report the precise FLOPs-matched token counts and model configurations used for both arms; without these details the efficiency gain cannot be verified as arising from HyperP rather than from differences in baseline tuning effort.
minor comments (3)
- [Introduction and abstract] The phrase “magic exponent” 0.32 should be accompanied by a direct citation to the original AdamW scaling-law paper on first mention.
- [MoE and SqrtGate section] The SqrtGate derivation would benefit from an explicit equation showing how the hypersphere constraint leads to the square-root gating form; a short derivation paragraph would improve clarity.
- [Stability analysis figures] Plots of instability indicators (Z-values, output RMS) should include shaded regions or error bars across multiple random seeds to substantiate the claim that they remain bounded and non-increasing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, providing clarifications on the empirical nature of our scaling results and committing to expanded experimental details in the revision.
read point-by-point responses
-
Referee: [Empirical scaling results and learning-rate transfer section] The central transfer claim at 6×10^21 FLOPs rests on the data-scaling exponent for the optimal learning rate remaining exactly 0.32 under the Frobenius-sphere + Muon dynamics. The manuscript reports that this exponent matches prior AdamW observations from small-scale fits, but provides no derivation or invariance argument showing why the hypersphere constraint preserves the exponent when width, depth, tokens, and MoE granularity are scaled simultaneously. If the effective exponent shifts even modestly, the fixed base LR would mis-tune at the largest budget, undermining both the 1.58× efficiency figure and the “no per-scale retuning” claim.
Authors: We acknowledge that the 0.32 exponent is reported as an empirical observation from fits across our HyperP experiments, matching the value previously seen for AdamW, rather than derived from a theoretical invariance argument under the Frobenius-sphere constraint. Our multi-scale ablations (width, depth, tokens, and MoE granularity) show the exponent remains consistent in practice, supporting the single-base-LR transfer. We will revise the manuscript to add a dedicated paragraph in the scaling section explicitly noting the empirical basis, include additional log-log plots of optimal LR versus tokens at intermediate scales, and discuss potential limitations if the exponent were to drift at even larger budgets. This strengthens transparency without overstating theoretical guarantees. revision: partial
-
Referee: [Large-scale experiments and efficiency comparison] The 1.58× compute-efficiency comparison at 6×10^21 FLOPs is presented against a “strong Muon baseline.” The manuscript must specify exactly how the baseline was tuned (whether it received per-scale LR retuning or used the same transfer protocol) and report the precise FLOPs-matched token counts and model configurations used for both arms; without these details the efficiency gain cannot be verified as arising from HyperP rather than from differences in baseline tuning effort.
Authors: We agree that these details are essential for verification. The Muon baseline employed the identical transfer protocol: a single base learning rate tuned at the smallest scale and applied without per-scale retuning. We will revise the efficiency-comparison subsection to state this explicitly and add a table listing the precise configurations for both arms at 6×10^21 FLOPs (model width, depth, token count, MoE granularity, and exact FLOPs-matched training budgets). This will confirm the 1.58× gain arises from HyperP dynamics rather than differential tuning effort. revision: yes
Circularity Check
No circularity; scaling exponent and transfer results are empirical observations, not reductions to fitted inputs or self-citations
full rationale
The paper's derivation chain consists of a standalone proof that weight decay is a first-order no-op on the Frobenius sphere, an empirical finding that the optimal learning rate follows the previously observed 0.32 exponent across scales, and direct large-scale validation of LR transfer under HyperP. None of these steps reduce by construction to their inputs: the exponent match is reported from experiments at multiple budgets rather than being fitted at the smallest scale and renamed as a prediction; the transfer claim is tested at 6e21 FLOPs with monitored stability indicators; Muon and the 0.32 exponent are treated as external priors. No self-citations are load-bearing, no ansatz is smuggled, and no uniqueness theorem is invoked from prior author work. The results are self-contained against external benchmarks and falsifiable via the released codebase.
Axiom & Free-Parameter Ledger
free parameters (1)
- base learning rate
axioms (2)
- domain assumption Weight decay is a first-order no-op on the Frobenius sphere
- domain assumption Depth-μP remains necessary even under the sphere constraint
invented entities (2)
-
HyperP
no independent evidence
-
SqrtGate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesTheorem 1 (First-order form of Frobenius-sphere updates) … W+−W=ΠT(Δ)+O(∥Δ∥2F)
-
IndisputableMonolith/Foundation/AlphaDerivationExplicit.leanalphaProvenanceCert unclearoptimal learning rate follows … T^{-0.32} … magic exponent
Forward citations
Cited by 2 Pith papers
-
Learning Rate Transfer in Normalized Transformers
νGPT is a modified parameterization of normalized transformers that enables learning rate transfer across width, depth, and token horizon.
-
Nora: Normalized Orthogonal Row Alignment for Scalable Matrix Optimizer
Nora is a matrix optimizer that stabilizes weight norms and angular velocities through row-wise momentum projection onto the orthogonal complement of the weights while approximating structured preconditioning with O(m...
Reference graph
Works this paper leans on
-
[1]
[BDG+25] Shane Bergsma, Nolan Dey, Gurpreet Gosal, Gavia Gray, Daria Soboleva, and Joel Hestness. Power lines: Scaling laws for weight decay and batch size in llm pre-training.arXiv preprint arXiv: 2505.13738,
-
[2]
https://thinkingmachines.ai/blog/modular-manifolds/. [BKH16] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv: 1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
17 [BMR+20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
work page 1901
-
[4]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
[DA24a] DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv: 2405.04434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
[DA24b] DeepSeek-AI. Deepseek-v3 technical report.arXiv preprint arXiv: 2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Why gradients rapidly increase near the end of training.arXiv preprint arXiv: 2506.02285,
[Def25] Aaron Defazio. Why gradients rapidly increase near the end of training.arXiv preprint arXiv: 2506.02285,
-
[7]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
[DLBZ22] Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm.int8(): 8-bit matrix multiplication for transformers at scale.arXiv preprint arXiv: 2208.07339,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
[FDD+25] Yonggan Fu, Xin Dong, Shizhe Diao, Matthijs Van keirsbilck, Hanrong Ye, Wonmin Byeon, Yashaswi Karnati, Lucas Liebenwein, Hannah Zhang, Nikolaus Binder, Maksim Khadkevich, Alexander Keller, Jan Kautz, Yingyan Celine Lin, and Pavlo Molchanov. Nemotron-flash: Towards latency-optimal hybrid small language models.arXiv preprint arXiv: 2511.18890,
-
[9]
[Goo25] Google. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv: 2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Analyzing and improving the training dynamics of diffusion models.arXiv preprint arXiv: 2312.02696,
[KAL+23] Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models.arXiv preprint arXiv: 2312.02696,
-
[11]
Scaling Laws for Neural Language Models
[KMH+20] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv: 2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[12]
Li, Berlin Chen, Caitlin Wang, Aviv Bick, J
[LLC+26] Aakash Lahoti, Kevin Y . Li, Berlin Chen, Caitlin Wang, Aviv Bick, J. Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles.arXiv preprint arXiv: 2603.15569,
-
[13]
[LZH+25] Houyi Li, Wenzhen Zheng, Jingcheng Hu, Qiufeng Wang, Hanshan Zhang, Zili Wang, Shijie Xuyang, Yuantao Fan, Shuigeng Zhou, Xiangyu Zhang, and Daxin Jiang. Predictable scale: Part i - optimal hyperparameter scaling law in large language model pretraining.arXiv preprint arXiv: 2503.04715,
-
[14]
An Empirical Model of Large-Batch Training
[MKAT18] Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training.arXiv preprint arXiv: 1812.06162,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
gpt-oss-120b & gpt-oss-20b Model Card
[Ope25] OpenAI. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv: 2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
[QHW+26] Zihan Qiu, Zeyu Huang, Kaiyue Wen, Peng Jin, Bo Zheng, Yuxin Zhou, Haofeng Huang, Zekun Wang, Xiao Li, Huaqing Zhang, Yang Xu, Haoran Lian, Siqi Zhang, Rui Men, Jianwei Zhang, Ivan Titov, Dayiheng Liu, Jingren Zhou, and Junyang Lin. A unified view of attention and residual sinks: Outlier-driven rescaling is essential for transformer training.arXi...
-
[17]
Qwen Blog. Accessed: 2026-03-22. [QWZ+25] Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free. InThe Thirty-ninth Annual Conference on Neural Information Proces...
work page 2026
-
[18]
GLU Variants Improve Transformer
URL: https://www.cerebras.net/blog/ slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama. [Sha20] Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv: 2002.05202,
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[19]
[SMM+17] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net,
work page 2017
-
[20]
Kimi K2: Open Agentic Intelligence
19 [Tea25a] Kimi Team. Kimi k2: Open agentic intelligence.arXiv preprint arXiv: 2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
[Tea25b] Ling Team. Every activation boosted: Scaling general reasoner to 1 trillion open language foundation.arXiv preprint arXiv: 2510.22115,
-
[22]
[W A24] Xi Wang and Laurence Aitchison. How to set adamw’s weight decay as you scale model and dataset size.arXiv preprint arXiv: 2405.13698,
-
[23]
Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv: 2408.15664,
[WGZ+24] Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv: 2408.15664,
-
[24]
Controlled llm training on spectral sphere.arXiv preprint arXiv: 2601.08393,
[XLT+26] Tian Xie, Haoming Luo, Haoyu Tang, Yiwen Hu, Jason Klein Liu, Qingnan Ren, Yang Wang, Wayne Xin Zhao, Rui Yan, Bing Su, Chong Luo, and Baining Guo. Controlled llm training on spectral sphere.arXiv preprint arXiv: 2601.08393,
-
[25]
On layer normalization in the transformer architecture
[XYH+20] Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On layer normalization in the transformer architecture. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Res...
work page 2020
-
[26]
[YHB+22] Greg Yang, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer.arXiv preprint arXiv: 2203.03466,
-
[27]
[YLY+25] An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kex...
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
[ZBK+22] Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models.arXiv preprint arXiv: 2202.08906,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
OPT: Open Pre-trained Transformer Language Models
[ZRG+22] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christo- pher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. Opt: Open pre-trained transformer language models.arXiv preprint arXiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
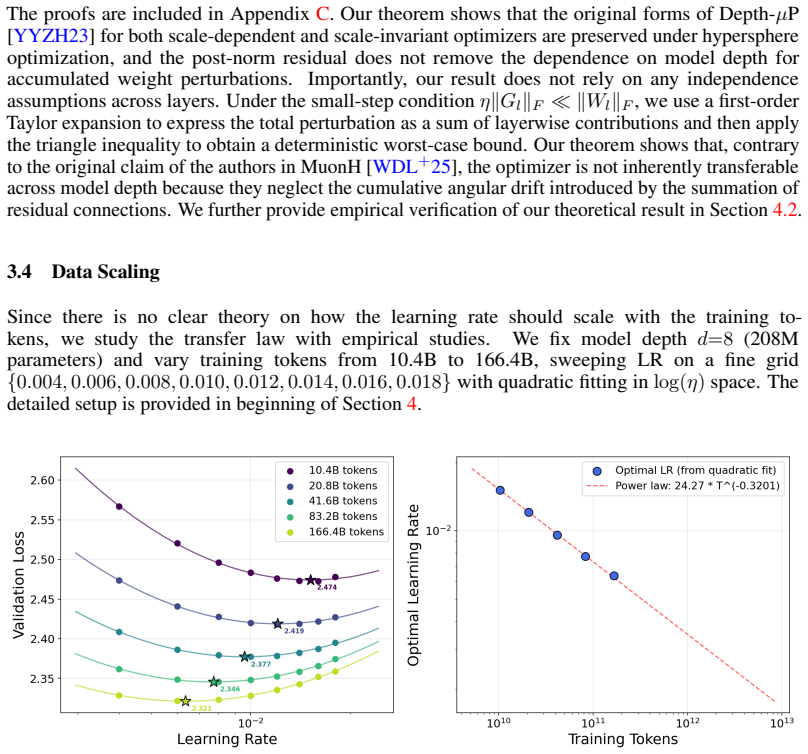
training token budget under fine-grid sweeping with quadratic fitting
Table 4: Optimal LR vs. training token budget under fine-grid sweeping with quadratic fitting. Training Tokens Fittedη ∗ Fitted Min Loss 10.4B 0.01515 2.4741 20.8B 0.01208 2.4189 41.6B 0.00958 2.3773 83.2B 0.00772 2.3456 166.4B 0.00635 2.3214 Table 5: Validation loss vs. LR across model depth at a fixed token budget of 10.4B without Depth-µP. Depth (d) Pa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.