Recognition: no theorem link
Feature Weighting Improves Pool-Based Sequential Active Learning for Regression
Pith reviewed 2026-05-13 21:45 UTC · model grok-4.3
The pith
Weighting features by ridge regression coefficients from early labeled samples refines distance calculations and improves sample selection in pool-based active learning for regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ridge regression coefficients trained on previously labeled samples supply per-feature weights that are multiplied into every inter-sample distance computation; the resulting distances produce more accurate rankings of representativeness and diversity, so the sequential selection of new points yields lower regression error than unweighted baselines.
What carries the argument
Ridge regression coefficients used as multiplicative feature weights inside the distance metric that drives representativeness and diversity scoring.
If this is right
- Five existing single-task and multi-task ALR methods gain accuracy with almost no extra computation.
- The same weighting step applies unchanged to both pool-based and stream-based selection.
- The modification extends directly to classification algorithms that rely on distance-based selection.
- Labeling budgets can be reduced while reaching the same target accuracy.
Where Pith is reading between the lines
- In high-dimensional regression the benefit should grow because unweighted distances become dominated by noise features.
- Any distance-based selection criterion, not just the five tested here, can adopt the same weighting step without changing its other logic.
- Iteratively updating the weights after each new batch is labeled would be a low-cost next refinement.
Load-bearing premise
Ridge coefficients estimated from a small initial labeled set are stable enough to serve as reliable indicators of feature importance for distance calculations.
What would settle it
Run the same active learning loop on a dataset where the ridge coefficients from the first batch show no correlation with the true predictive importance of each feature; if the weighted versions then perform no better or worse than the unweighted versions, the central claim fails.
Figures





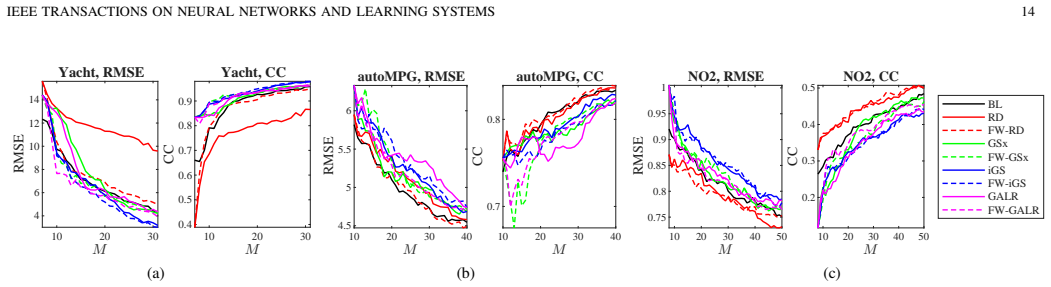
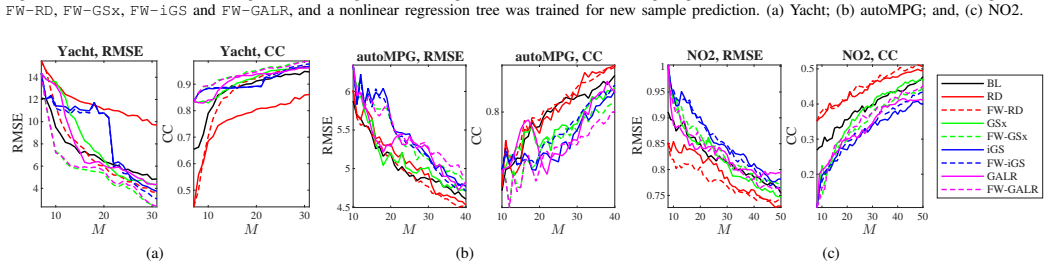

read the original abstract
Pool-based sequential active learning for regression (ALR) optimally selects a small number of samples sequentially from a large pool of unlabeled samples to label, so that a more accurate regression model can be constructed under a given labeling budget. Representativeness and diversity, which involve computing the distances among different samples, are important considerations in ALR. However, previous ALR approaches do not incorporate the importance of different features in inter-sample distance computation, resulting in inaccurate distances and hence sub-optimal sample selection. This paper proposes four feature weighted single-task ALR approaches and three feature weighted multi-task ALR approaches, where the ridge regression coefficients trained from a small amount of previously labeled samples are used to weight the corresponding features in inter-sample distance computation. Extensive experiments showed that this intuitive and easy-to-implement enhancement almost always improves the performance of five existing ALR approaches, in both single-task and multi-task regression problems. The feature weighting strategy may also be easily extended to stream-based ALR, and classification algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that weighting features in inter-sample distance computations using ridge regression coefficients trained on a small initial labeled pool improves the performance of five existing pool-based sequential active learning for regression (ALR) methods. It introduces four single-task and three multi-task variants of this enhancement and reports that extensive experiments show consistent gains over the unweighted baselines in both single- and multi-task regression settings.
Significance. If the empirical improvements are robust, the work offers a simple, low-overhead modification that can be plugged into existing ALR pipelines to better respect feature importance when enforcing representativeness and diversity. The multi-task extension broadens applicability, and the parameter-free nature of the weighting step (once the ridge fit is performed) is a practical strength.
major comments (2)
- [§3.2] §3.2 (Feature Weighting via Ridge Regression): The central mechanism computes feature weights from ridge regression on the initial labeled set and inserts them into the distance metric used by the base ALR selectors. No analysis or ablation examines the variance of these weights as a function of initial labeled-set size or feature dimensionality; when the initial set is small or unrepresentative, high-variance coefficients can distort rather than correct the distances that the five base methods rely upon for selection.
- [§5] §5 (Experimental Results): Tables 1–4 report consistent outperformance, yet the manuscript provides neither statistical significance tests across repeated runs nor an ablation that varies the size of the initial labeled pool. Without these, it is impossible to determine whether the reported gains survive the very regime (small initial labels) that the method presupposes.
minor comments (2)
- [§3.3] The multi-task distance formula is described only in prose; an explicit equation would clarify how the per-task ridge weights are combined.
- [Figures 1–4] Figure captions should state the number of independent runs and the exact initial labeled-set size used for each dataset.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and indicate the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Feature Weighting via Ridge Regression): The central mechanism computes feature weights from ridge regression on the initial labeled set and inserts them into the distance metric used by the base ALR selectors. No analysis or ablation examines the variance of these weights as a function of initial labeled-set size or feature dimensionality; when the initial set is small or unrepresentative, high-variance coefficients can distort rather than correct the distances that the five base methods rely upon for selection.
Authors: We agree that an explicit analysis of the variance of the ridge-derived feature weights would be valuable, particularly for small or unrepresentative initial labeled sets. While our experiments across multiple datasets already show consistent gains, we will add a new ablation in the revised manuscript (likely as an appendix) that varies initial pool size (e.g., 5–50 samples) and feature dimensionality, reporting both coefficient variance and its effect on downstream selection quality. This will directly address the stability concern. revision: yes
-
Referee: [§5] §5 (Experimental Results): Tables 1–4 report consistent outperformance, yet the manuscript provides neither statistical significance tests across repeated runs nor an ablation that varies the size of the initial labeled pool. Without these, it is impossible to determine whether the reported gains survive the very regime (small initial labels) that the method presupposes.
Authors: We acknowledge the absence of formal statistical tests and an explicit ablation on initial pool size. In the revision we will (i) rerun the experiments with multiple random initializations and add statistical significance results (Wilcoxon signed-rank tests with p-values) to Tables 1–4, and (ii) include a dedicated ablation subsection that varies the initial labeled pool size from very small values upward, confirming that the reported improvements hold in the low-label regime the method targets. revision: yes
Circularity Check
No significant circularity in the proposed feature weighting for ALR
full rationale
The paper introduces a method that computes ridge regression coefficients on already-labeled samples and applies them as feature weights when calculating inter-sample distances for pool-based selection. This is a one-way application with no feedback loop in which the active learning selections influence the weight computation itself. No equations or steps reduce the claimed improvement to a self-definition, fitted prediction, or self-citation chain; the performance gains are asserted via external experiments on five base ALR methods rather than by algebraic identity. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- Ridge regression regularization parameter
axioms (1)
- domain assumption Ridge regression coefficients from a small labeled set reflect the relative importance of features for inter-sample distance computation in the unlabeled pool
Reference graph
Works this paper leans on
-
[1]
R. Picard, Affective Computing. Cambridge, MA: The MIT Press, 1997
work page 1997
-
[2]
Affective brain-comp uter interfaces (aBCIs): A tutorial,
D. Wu, B.-L. Lu, B. Hu, and Z. Zeng, “Affective brain-comp uter interfaces (aBCIs): A tutorial,” Proc. of the IEEE , vol. 11, no. 10, pp. 1314–1332, 2023
work page 2023
-
[3]
The Vera Am Mi ttag German audio-visual emotional speech database,
M. Grimm, K. Kroschel, and S. S. Narayanan, “The Vera Am Mi ttag German audio-visual emotional speech database,” in Proc. Int’l Conf. on Multimedia & Expo (ICME) , Hannover, German, June 2008, pp. 865– 868
work page 2008
-
[4]
DEAP: A database for emoti on anal- ysis using physiological signals,
S. Koelstra, C. Muhl, M. Soleymani, J. S. Lee, A. Y azdani, T. Ebrahimi, T. Pun, A. Nijholt, and I. Patras, “DEAP: A database for emoti on anal- ysis using physiological signals,” IEEE Trans. on Affective Computing , vol. 3, no. 1, pp. 18–31, 2012
work page 2012
-
[5]
Emo tionMeter: A multimodal framework for recognizing human emotions,
W.-L. Zheng, W. Liu, Y . Lu, B.-L. Lu, and A. Cichocki, “Emo tionMeter: A multimodal framework for recognizing human emotions,” IEEE Trans. on Cybernetics , vol. 49, no. 3, pp. 1110–1122, 2019
work page 2019
-
[6]
E. S. Dan-Glauser and K. R. Scherer, “The Geneva affectiv e picture database (GAPED): a new 730-picture database focusing on va lence and normative significance,” Behavior Research Methods , vol. 43, pp. 468–477, 2011
work page 2011
-
[7]
M. M. Bradley and P . J. Lang, “The international affectiv e digitized sounds (2nd edition; IADS-2): Affective ratings of sounds a nd instruc- tion manual,” University of Florida, Gainesville, FL, Tech . Rep. B-3, 2007
work page 2007
-
[8]
Forecasting t he post fracturing response of oil wells in a tight reservoir,
J. Joo, D. Wu, J. M. Mendel, and A. Bugacov, “Forecasting t he post fracturing response of oil wells in a tight reservoir,” in Proc. SPE W estern Regional Meeting, San Jose, CA, March 2009
work page 2009
-
[9]
B. Settles, Active learning . Morgan & Claypool Publishers, 2012
work page 2012
- [10]
-
[11]
A survey on negati ve transfer,
W. Zhang, L. Deng, L. Zhang, and D. Wu, “A survey on negati ve transfer,” IEEE/CAA Journal of Automatica Sinica , vol. 10, no. 2, pp. 305–329, 2023
work page 2023
-
[12]
A survey on self-supervised learning: Algorithms, applications, a nd future trends,
J. Gui, T. Chen, J. Zhang, Q. Cao, Z. Sun, H. Luo, and D. Tao , “A survey on self-supervised learning: Algorithms, applications, a nd future trends,” IEEE Trans. on Pattern Analysis and Machine Intelligence , vol. 46, no. 12, pp. 9052–9071, 2024
work page 2024
-
[13]
Ac tive transfer learning for cross-system recommendation,
L. Zhao, S. Pan, E. Xiang, E. Zhong, Z. Lu, and Q. Y ang, “Ac tive transfer learning for cross-system recommendation,” in Proc. AAAI Conf. on Artificial Intelligence , Bellevue, W A, July 2013
work page 2013
-
[14]
Active semi-supervised transfer learning (AST L) for offline BCI calibration,
D. Wu, “Active semi-supervised transfer learning (AST L) for offline BCI calibration,” in Proc. IEEE Int’l. Conf. on Systems, Man and Cybernetics, Banff, Canada, October 2017
work page 2017
-
[15]
Semi-supervis ed transfer boosting (SS-TrBoosting),
L. Deng, C. Zhao, Z. Du, K. Xia, and D. Wu, “Semi-supervis ed transfer boosting (SS-TrBoosting),” IEEE Trans. on Artificial Intelligence , vol. 5, no. 7, pp. 3431–3444, 2024
work page 2024
-
[16]
Deep source semi-s upervised transfer learning (DS3TL) for cross-subject EEG classifica tion,
X. Jiang, L. Meng, Z. Wang, and D. Wu, “Deep source semi-s upervised transfer learning (DS3TL) for cross-subject EEG classifica tion,” IEEE Trans. on Biomedical Engineering , vol. 71, no. 4, pp. 1308–1318, 2024
work page 2024
-
[17]
A survey on deep active learning: Recent advances and new fron tiers,
D. Li, Z. Wang, Y . Chen, R. Jiang, W. Ding, and M. Okumura, “A survey on deep active learning: Recent advances and new fron tiers,” IEEE Trans. on Neural Networks and Learning Systems , vol. 36, no. 4, pp. 5879–5899, 2025
work page 2025
-
[18]
Pool-based sequential active learning for regr ession,
D. Wu, “Pool-based sequential active learning for regr ession,” IEEE Trans. on Neural Networks and Learning Systems , vol. 30, no. 5, pp. 1348–1359, 2019
work page 2019
-
[19]
Minimisation of data col lection by active learning,
T. RayChaudhuri and L. Hamey, “Minimisation of data col lection by active learning,” in Proc. IEEE Int’l. Conf. on Neural Networks , vol. 3, Perth, Australia, November 1995, pp. 1338–1341
work page 1995
-
[20]
Maximizing expected mode l change for active learning in regression,
W. Cai, Y . Zhang, and J. Zhou, “Maximizing expected mode l change for active learning in regression,” in Proc. IEEE 13th Int’l. Conf. on Data Mining, Dallas, TX, December 2013
work page 2013
-
[21]
Passive sampling for regression,
H. Y u and S. Kim, “Passive sampling for regression,” in Proc. IEEE Int’l. Conf. on Data Mining , Sydney, Australia, December 2010, pp. 1151–1156
work page 2010
-
[22]
Active learning for regr ession using greedy sampling,
D. Wu, C.-T. Lin, and J. Huang, “Active learning for regr ession using greedy sampling,” Information Sciences , vol. 474, pp. 90–105, 2019
work page 2019
-
[23]
A graph-based app roach for active learning in regression,
H. Zhang, S. S. Ravi, and I. Davidson, “A graph-based app roach for active learning in regression,” in Proc. SIAM Int’l Conf. on Data Mining , Cincinnati, OH, May 2020
work page 2020
-
[24]
Affect estimation in 3D space using m ulti-task active learning for regression,
D. Wu and J. Huang, “Affect estimation in 3D space using m ulti-task active learning for regression,” IEEE Trans. on Affective Computing , vol. 13, no. 1, pp. 16–27, 2022
work page 2022
-
[25]
Active learning for convolut ional neural networks: A core-set approach,
O. Sener and S. Savarese, “Active learning for convolut ional neural networks: A core-set approach,” in Proc. Int’l Conf. on Learning Representations, V ancouver, Canada, Apr. 2018. [Online]. Available: https://openreview.net/forum?id=H1aIuk-RW
work page 2018
-
[26]
Gaussi an process regression: Active data selection and test point rejection ,
S. Seo, M. Wallat, T. Graepel, and K. Obermayer, “Gaussi an process regression: Active data selection and test point rejection ,” in Proc. IEEE- INNS-ENNS Int’l Joint Conf. on Neural Networks , vol. 3, Como, Italy, Jul. 2000, pp. 241–246
work page 2000
-
[27]
A framework and benchmark for deep batch active learning for regression ,
D. Holzm ¨ uller, V . Zaverkin, J. K¨ astner, and I. Steinwart, “A framework and benchmark for deep batch active learning for regression ,” Journal of Machine Learning Research , vol. 24, no. 164, pp. 1–81, 2023
work page 2023
-
[28]
Bayesian active learning for classification and preferenc e learning,
N. Houlsby, F. Husz´ ar, Z. Ghahramani, and M. Lengyel, “Bayesian active learning for classification and preferenc e learning,” arXiv:1112.5745, 2011
-
[29]
Batch mode active learni ng for re- gression with expected model change,
W. Cai, M. Zhang, and Y . Zhang, “Batch mode active learni ng for re- gression with expected model change,” IEEE Trans. on Neural Networks and Learning Systems , vol. 28, no. 7, pp. 1668–1681, July 2017
work page 2017
-
[30]
Individual comparisons by ranking metho ds,
F. Wilcoxon, “Individual comparisons by ranking metho ds,” Biometrics bulletin, vol. 1, no. 6, pp. 80–83, 1945
work page 1945
-
[31]
Stream -based active learning for regression with dynamic feature selection,
D. Cacciarelli, J. S. Tyssedal, and M. Kulahci, “Stream -based active learning for regression with dynamic feature selection,” i n Proc. 5th Int’l Conf. on Transdisciplinary AI , Laguna Hills, CA, Sep. 2023, pp. 243–248
work page 2023
-
[32]
Z. Liu, X. Jiang, H. Luo, W. Fang, J. Liu, and D. Wu, “Pool- based unsu- pervised active learning for regression using iterative re presentativeness- diversity maximization (iRDM),” Pattern Recognition Letters , vol. 142, pp. 11–19, 2021
work page 2021
-
[33]
Unsupervised pool-based ac tive learning for linear regression,
Z. Liu, X. Jiang, and D. Wu, “Unsupervised pool-based ac tive learning for linear regression,” Acta Automatica Sinica, vol. 47, no. 12, pp. 2771– 2783, 2021, in Chinese
work page 2021
-
[34]
Pr imitives- based evaluation and estimation of emotions in speech,
M. Grimm, K. Kroschel, E. Mower, and S. S. Narayanan, “Pr imitives- based evaluation and estimation of emotions in speech,” Speech Com- munication, vol. 49, pp. 787–800, 2007
work page 2007
-
[35]
Emotion estimation in speech using a 3D emotion space concept,
M. Grimm and K. Kroschel, “Emotion estimation in speech using a 3D emotion space concept,” in Robust Speech Recognition and Understanding, M. Grimm and K. Kroschel, Eds. Vienna, Austria: I-Tech, 2007, pp. 281–300
work page 2007
-
[36]
Spee ch emotion estimation in 3D space,
D. Wu, T. D. Parsons, E. Mower, and S. S. Narayanan, “Spee ch emotion estimation in 3D space,” in Proc. IEEE Int’l Conf. on Multimedia & Expo (ICME) , Singapore, July 2010, pp. 737–742
work page 2010
-
[37]
Acoustic feat ure analysis in speech emotion primitives estimation,
D. Wu, T. D. Parsons, and S. S. Narayanan, “Acoustic feat ure analysis in speech emotion primitives estimation,” in Proc. InterSpeech, Makuhari, Japan, September 2010
work page 2010
-
[38]
Active learning for dat a streams: a survey,
D. Cacciarelli and M. Kulahci, “Active learning for dat a streams: a survey,” Machine Learning , vol. 113, no. 1, pp. 185–239, 2024
work page 2024
-
[39]
Streaming act ive learning for regression problems using regression via classification,
S. Horiguchi, K. Dohi, and Y . Kawaguchi, “Streaming act ive learning for regression problems using regression via classification,” in proc. IEEE Int’l Conf. on Acoustics, Speech and Signal Processing , Seoul, Korea, Apr. 2024, pp. 4955–4959
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.