Recognition: no theorem link
YC Bench: a Live Benchmark for Forecasting Startup Outperformance in Y Combinator Batches
Pith reviewed 2026-05-13 23:04 UTC · model grok-4.3
The pith
YC Bench creates a live benchmark that scores startup outperformance in YC batches using public signals before Demo Day.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
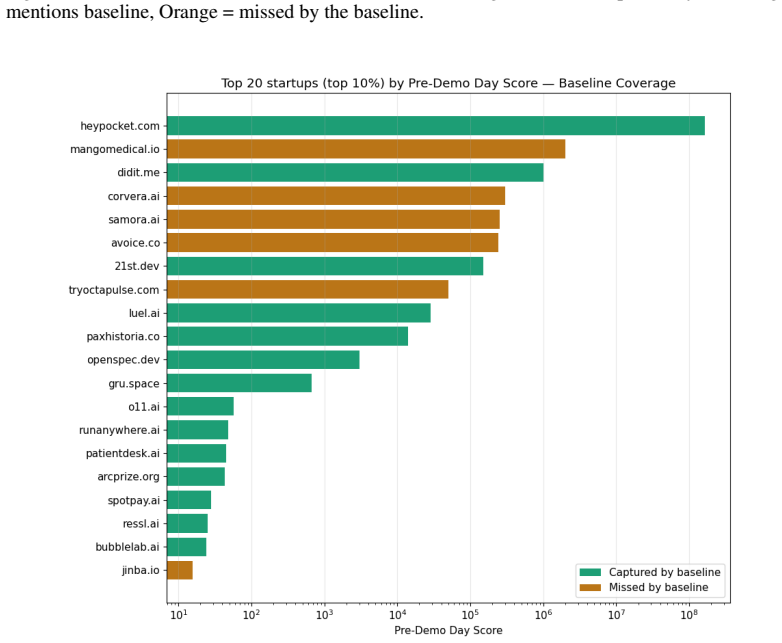
YC Bench is a live benchmark for forecasting early outperformance within YC batches. It defines outperformance via the Pre-Demo Day Score, a KPI that combines publicly available traction signals and web visibility, and demonstrates the setup on the W26 batch where a Google-mentions baseline recovers 55 percent of top Demo Day performers.
What carries the argument
The Pre-Demo Day Score, a KPI that aggregates publicly available traction signals and web visibility to rank startups before Demo Day.
If this is right
- Forecasting models can be evaluated and iterated on new YC batches every few months rather than years.
- Public data sources like Google mentions provide usable baselines that already recover more than half of top batch performers.
- Research on startup prediction can now use repeated, short-cycle experiments across successive YC batches.
Where Pith is reading between the lines
- If the score holds across batches, sequential training on multiple YC cohorts could steadily improve model accuracy.
- The batch structure might be adapted to create similar fast benchmarks for other accelerators or early-stage funding programs.
- Adding richer public signals beyond Google mentions could raise recall well above the 55 percent baseline shown.
Load-bearing premise
The Pre-Demo Day Score serves as a valid short-term proxy for meaningful outperformance that generalizes beyond the W26 batch.
What would settle it
Apply the Pre-Demo Day Score to the next YC batch and measure whether its top-ranked startups actually appear among the strongest performers at that batch's Demo Day, or track long-term outcomes such as funding and exits for the W26 top scorers.
Figures






read the original abstract
Forecasting startup success is notoriously difficult, partly because meaningful outcomes, such as exits, large funding rounds, and sustained revenue growth, are rare and can take years to materialize. As a result, signals are sparse and evaluation cycles are slow. Y Combinator batches offer a unique mitigation: each batch comprises around 200 startups, funded simultaneously, with evaluation at Demo Day only three months later. We introduce YC Bench, a live benchmark for forecasting early outperformance within YC batches. Using the YC W26 batch as a case study (196 startups), we measure outperformance with a Pre-Demo Day Score, a KPI combining publicly available traction signals and web visibility. This short-term metric enables rapid evaluation of forecasting models. As a baseline, we take Google mentions prior to the YC W26 application deadline, a simple proxy for prior brand recognition, recovering 6 of 11 top performers at YC Demo Day (55% recall). YC Bench provides a live benchmark for studying startup success forecasting, with iteration cycles measured in months rather than years. Code and Data are available on GitHub: https://github.com/benstaf/ycbench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces YC Bench, a live benchmark for forecasting early outperformance within Y Combinator batches. Using the W26 batch (196 startups) as a case study, it defines a Pre-Demo Day Score combining public traction signals and web visibility as a short-term KPI, releases associated code and data, and reports a simple baseline (pre-application Google mentions) that recovers 6 of 11 top performers at Demo Day (55% recall). The central contribution is the benchmark itself, which enables month-scale iteration cycles rather than multi-year waits for exits or large rounds.
Significance. If the benchmark and its short-term proxy hold, the work supplies a reproducible, public resource that lowers the barrier to developing and iterating on startup-success forecasting models. The explicit release of code, data, and an unfitted external baseline (Google mentions) is a concrete strength that supports community use and rapid evaluation.
major comments (1)
- [Baseline and Case Study] The manuscript does not specify the exact criteria used to identify the 11 'top performers' whose recall is reported for the Google-mentions baseline. Without this definition, it is impossible to assess selection effects, reproducibility of the 55% figure, or whether the Pre-Demo Day Score is being evaluated against a stable target.
minor comments (2)
- [Pre-Demo Day Score] The Pre-Demo Day Score is described as combining traction signals and web visibility, but the precise weighting or aggregation formula is not stated; an explicit equation or pseudocode would improve reproducibility.
- The GitHub repository link is provided but no commit hash or snapshot is given; pinning the exact version used for the W26 results would strengthen the reproducibility claim.
Simulated Author's Rebuttal
Thank you for the referee's thoughtful review and recommendation for minor revision. We are pleased that the significance of the benchmark is recognized. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Baseline and Case Study] The manuscript does not specify the exact criteria used to identify the 11 'top performers' whose recall is reported for the Google-mentions baseline. Without this definition, it is impossible to assess selection effects, reproducibility of the 55% figure, or whether the Pre-Demo Day Score is being evaluated against a stable target.
Authors: We thank the referee for highlighting this omission. The 11 top performers are defined as the startups that rank highest according to the Pre-Demo Day Score within the W26 batch. This choice makes the evaluation self-consistent with the short-term KPI we propose, allowing for rapid iteration. To address the concern about selection effects and reproducibility, we will explicitly state this definition in the revised manuscript, along with the precise formula for the Pre-Demo Day Score (a combination of public traction signals and web visibility). We believe this will make the 55% recall figure fully reproducible. Regarding the stability of the target, the Pre-Demo Day Score serves as the target by design, as it captures early outperformance observable at Demo Day time scale. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central contribution is the release of YC Bench, a live benchmark defined explicitly via the Pre-Demo Day Score (a transparent combination of public traction signals and web visibility) for the W26 batch, together with an unfitted external baseline of pre-application Google mentions. No equations, predictions, or claims reduce by construction to fitted inputs or self-citations; the metric is presented as a short-term proxy without hidden assumptions about long-term generalization, and the work is self-contained against external benchmarks with released code and data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Public traction signals and web visibility are sufficient to construct a meaningful short-term outperformance metric.
Reference graph
Works this paper leans on
-
[1]
Nikhil Chandak, Shashwat Goel, Ameya Prabhu, Moritz Hardt, and Jonas Geiping
URL https://arxiv.org/abs/ 1904.08171. Nikhil Chandak, Shashwat Goel, Ameya Prabhu, Moritz Hardt, and Jonas Geiping. Scaling Open- Ended Reasoning to Predict the Future,
-
[2]
Rick Chen, Joseph Ternasky, Afriyie Samuel Kwesi, et al
URL https://arxiv.org/abs/2512.25070. Rick Chen, Joseph Ternasky, Afriyie Samuel Kwesi, et al. VCBench: Benchmarking LLMs in Venture Capital,
-
[3]
VCBench: Benchmarking LLMs in Venture Capital
URL https://arxiv.org/abs/2509.14448. Tianle Chen, R. Matthew Hutchison, Carrie Rubel, et al. A review of evidence supporting amyloid beta reduction as a surrogate endpoint in Alzheimer’s disease.The Journal of Prevention of Alzheimer’s Disease, 13(2):100458,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
URL https://doi.org/10.1016/j.tjpad.2025.100458. Susan L. Cohen, Christopher B. Bingham, and Benjamin L. Hallen. The Design of Startup Accelera- tors. Research Policy, 48(7):1781–1797,
-
[5]
doi: https://doi.org/10.1016/j.mlwa.2021.100062
ISSN 2666-8270. doi: https://doi.org/10.1016/j.mlwa.2021.100062. URL https://www.sciencedirect.com/science/article/pii/S2666827021000311. Thomas R. Fleming and David L. DeMets. Surrogate End Points in Clinical Trials: Are We Being Misled? Annals of Internal Medicine, 125(7):605–613,
-
[6]
Charly Gastaud, Thibault Carniel, and Jean-Michel Dalle. The Varying Importance of Extrinsic Factors in the Success of Startup Fundraising: Competition, Market Timing and Startup Ecosystem. arXiv preprint arXiv:1906.03210,
-
[7]
URL https://arxiv.org/abs/2312.06236. Benjamin L. Hallen, Susan L. Cohen, and Christopher B. Bingham. Do accelerators accelerate? A study of venture accelerators as a path to success? Academy of Management Proceedings, 2014(1): 12955,
-
[8]
Predicting the outcome of startups: Less failure, more success
Amar Krishna, Ankit Agrawal, and Alok Choudhary. Predicting the outcome of startups: Less failure, more success. In 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), pages 798–805,
work page 2016
-
[9]
doi: 10.1109/ICDMW.2016.0118. Jinze Li. Prediction of the Success of Startup Companies Based on Support Vector Machine and Random Forset. In 2020 2nd International Workshop on Artificial Intelligence and Education, W AIE 2020, page 5–11, New York, NY , USA,
-
[10]
Association for Computing Machinery. ISBN 9781450388252. URL https://doi.org/10.1145/3447490.3447492. Jiashuo Liu et al. FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains,
-
[11]
URL https://arxiv.org/abs/2601.12259. arXiv:2601.12259. Mucan Liu, Manting Hu, and Junming Liu. A Graph Learning Model of Network Resources for Early Stage Startup Success Prediction. In Proceedings of the 44th International Conference on Information Systems (ICIS
- [12]
-
[13]
Zhiyuan Zeng, Jiashuo Liu, Siyuan Chen, et al
URLhttps://doi.org/10.1145/ 3269206.3272011. Zhiyuan Zeng, Jiashuo Liu, Siyuan Chen, et al. FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction. arXiv preprint arXiv:2508.11987,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.