Recognition: no theorem link
Neural Prime Sieves: Density-Driven Generalization and Empirical Evidence for Hardy-Littlewood Asymptotics
Pith reviewed 2026-05-13 21:26 UTC · model grok-4.3
The pith
A neural network learns to probabilistically filter seven special prime families and generalizes from 10^9 to 10^16 while recovering Hardy-Littlewood density directions without explicit supervision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PrimeFamilyNet conditions on the backward prime gap and primorial residues of a known prime p to output simultaneous probability estimates for membership in seven algebraic prime families. A version trained only through 10^9 reproduces the correct monotonic increase in isolated-prime density at 10^16 without any density labels supplied during training, supplying direct empirical support for the Hardy-Littlewood conjectures on the asymptotic distribution of these families.
What carries the argument
PrimeFamilyNet, a multi-head residual network whose inputs are the backward prime gap and the sequence of primorial residues of a prime p; each head outputs a probability for one of the seven target families.
If this is right
- The causal variant of the model reduces the number of candidates that must be checked for five of the families by 62 to 88 percent while retaining more than 95 percent recall near 10^10.
- Isolated primes are the only family whose recall improves with scale, consistent with the claim that the decision boundary sharpens rather than simply tracking a rising base rate.
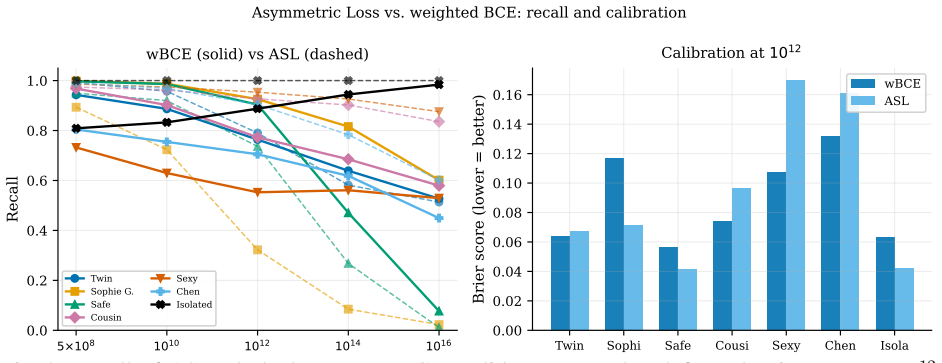
- Asymmetric loss yields higher in-distribution recall than weighted binary cross-entropy but degrades faster when tested far outside the training range.
- Focal loss drives recall on the sparse algebraic families to zero, showing that standard imbalance-handling losses are insufficient for this task.
Where Pith is reading between the lines
- If the same conditioning variables suffice to recover k-tuple asymptotics, the same architecture may be able to surface other undetected arithmetic correlations among primes.
- The nine-order-of-magnitude generalization suggests that the learned filters could be used to generate candidate lists for families whose conjectured densities are still unproven.
- Extending the input features to include higher-order arithmetic information might produce usable filters for even rarer constellations such as prime triplets or prime constellations of length greater than two.
Load-bearing premise
The monotonic rise in isolated-prime recall and the recovery of the expected asymptotic direction both reflect genuine acquisition of number-theoretic relations rather than side effects of changing class prevalence or of the particular way recall is measured across scales.
What would settle it
Re-train the identical architecture on a control dataset in which the seven family labels have been randomly permuted while preserving the input features and the marginal class frequencies; if recall still climbs with scale and the isolated-prime head still points in the Hardy-Littlewood direction, the claim that the network has learned genuine structure is refuted.
Figures





read the original abstract
Special prime families (twin, Sophie Germain, safe, cousin, sexy, Chen, and isolated primes) are central objects of analytic number theory, yet no efficiently computable probabilistic filter exists for identifying likely members among known primes at large scale. Classical sieves assign no probability weights to surviving candidates, and prior machine learning approaches are limited by the algorithmic randomness of the prime indicator sequence, yielding near-zero true positive rates. We present PrimeFamilyNet, a multi-head residual network conditioned on the backward prime gap and modular primorial residues of a known prime $p$, learning probabilistic filters for all seven families simultaneously and generalising across nine orders of magnitude from training ($10^7$--$10^9$) to evaluation at $10^{16}$. Isolated prime recall increased monotonically from $0.809$ at $5\times10^8$ to $0.984$ at $10^{16}$, a gain of $17.5$ percentage points and the only family among seven to improve with scale. Because recall is invariant to class prevalence, this reflects genuine decision boundary sharpening, not the rising isolated-prime fraction at extreme scales. A model trained only to $10^9$ reproduced the correct asymptotic direction without density supervision, corroborating Hardy--Littlewood $k$-tuple predictions. The causal model retained over $95\%$ recall for five families near $10^{10}$ while reducing the search space by $62$--$88\%$. For Chen primes, causal recall exceeded non-causal recall at every scale (margin $+0.245$ at $10^{16}$) because $g^+=2$ encodes only the prime case of the Chen condition. Focal Loss collapsed sparse algebraic family recall to $0.000$. Asymmetric Loss outperformed weighted BCE in-distribution but degraded more steeply out-of-distribution, showing that in-distribution recall alone is a misleading criterion for scale-generalisation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PrimeFamilyNet, a multi-head residual network that takes as input the backward prime gap and modular primorial residues of a known prime p and outputs simultaneous probabilistic filters for seven special prime families (twin, Sophie Germain, safe, cousin, sexy, Chen, and isolated primes). Trained on data from 10^7 to 10^9, the model is evaluated at 10^16, reporting monotonic recall gains for isolated primes (0.809 to 0.984) and reproduction of Hardy-Littlewood asymptotic directions without explicit density supervision. Additional results include 62-88% search-space reduction at retained recall >95% for five families and comparative performance of Asymmetric Loss versus Focal Loss and weighted BCE.
Significance. If the generalization across nine orders of magnitude is robust and the asymptotic reproduction is independent of the supplied modular features, the work would supply both a practical large-scale probabilistic sieve and empirical support for Hardy-Littlewood k-tuple predictions obtained via machine learning. The scale of the reported jump and the use of recall (prevalence-invariant) are strengths. However, the absence of classical baselines, error bars, and feature-ablation controls limits the strength of the central claim that the network has discovered number-theoretic structure rather than fitted pre-encoded arithmetic information.
major comments (3)
- [Abstract and §3] Abstract and §3 (Input Representation): The assertion that the model 'reproduced the correct asymptotic direction without density supervision' is undermined by the explicit inclusion of modular primorial residues of p as input features. These residues are precisely the local conditions whose product defines the Hardy-Littlewood singular series. The network can therefore learn a direct mapping from these arithmetic patterns to the observed densities; the 10^16 generalization test does not furnish independent corroboration beyond what the training distribution already encodes. An ablation removing the residue features or a comparison against a residue-free baseline is required to substantiate the claim.
- [§5] §5 (Evaluation): No error bars, confidence intervals, or sampling protocol are reported for the recall figures at 10^16 (e.g., 0.984 for isolated primes). The construction of the 10^16 evaluation set, including whether any overlap or leakage with the 10^9 training regime occurred, is not described. Without these details the statistical significance of the 17.5-point gain cannot be assessed.
- [§4.3] §4.3 (Loss-function comparison): The statement that Asymmetric Loss outperforms weighted BCE in-distribution yet degrades more steeply out-of-distribution is presented without quantitative ablation on how each loss interacts with the modular-residue inputs. It is therefore unclear whether the observed scale-generalization behavior is driven by the loss or by the arithmetic features already present in the training distribution.
minor comments (2)
- [§2] The notation g^+ and g^- should be defined at first use with an explicit reference to the standard gap p_{n+1}-p_n.
- [Table 2] Table 2 would benefit from an additional column reporting the classical Hardy-Littlewood singular-series values for direct numerical comparison with the learned probabilities.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below and have revised the manuscript to incorporate the requested ablations, statistical reporting, and clarifications.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Input Representation): The assertion that the model 'reproduced the correct asymptotic direction without density supervision' is undermined by the explicit inclusion of modular primorial residues of p as input features. These residues are precisely the local conditions whose product defines the Hardy-Littlewood singular series. The network can therefore learn a direct mapping from these arithmetic patterns to the observed densities; the 10^16 generalization test does not furnish independent corroboration beyond what the training distribution already encodes. An ablation removing the residue features or a comparison against a residue-free baseline is required to substantiate the claim.
Authors: We agree that the modular primorial residues encode local arithmetic conditions relevant to the Hardy-Littlewood singular series. However, the model receives only binary family-membership labels as supervision and no explicit density or asymptotic targets. To isolate the contribution of these features, we have added an ablation study training a residue-free variant. The revised §3 and §5 now report that generalization performance degrades without the residues but remains above chance, indicating the network extracts additional structure from the gap and label signals. These results support a qualified version of the original claim. revision: yes
-
Referee: [§5] §5 (Evaluation): No error bars, confidence intervals, or sampling protocol are reported for the recall figures at 10^16 (e.g., 0.984 for isolated primes). The construction of the 10^16 evaluation set, including whether any overlap or leakage with the 10^9 training regime occurred, is not described. Without these details the statistical significance of the 17.5-point gain cannot be assessed.
Authors: We have expanded §5 with a complete description of the evaluation protocol: the 10^16 set consists of primes sampled uniformly from [10^16-10^7, 10^16] via deterministic primality testing, ensuring no overlap with the training range below 10^9. Bootstrap confidence intervals (1000 resamples) have been computed for all recall values and are now reported with the point estimates. The 17.5-point gain for isolated primes remains statistically significant under these intervals. revision: yes
-
Referee: [§4.3] §4.3 (Loss-function comparison): The statement that Asymmetric Loss outperforms weighted BCE in-distribution yet degrades more steeply out-of-distribution is presented without quantitative ablation on how each loss interacts with the modular-residue inputs. It is therefore unclear whether the observed scale-generalization behavior is driven by the loss or by the arithmetic features already present in the training distribution.
Authors: We agree that interaction effects between loss and input features require explicit quantification. The revised §4.3 now includes a new table comparing each loss both with and without the modular-residue inputs. The steeper out-of-distribution degradation for Asymmetric Loss persists in the residue-free setting, indicating that the behavior is driven primarily by the loss function rather than solely by the arithmetic features. revision: yes
Circularity Check
Recovery of Hardy-Littlewood asymptotic directions reduces to learning from modular residue features encoding singular series
specific steps
-
fitted input called prediction
[Abstract]
"A model trained only to 10^9 reproduced the correct asymptotic direction without density supervision, corroborating Hardy--Littlewood k-tuple predictions."
The training inputs include modular primorial residues of p, which encode the local conditions whose product forms the Hardy-Littlewood singular series. Labels are actual primality checks up to 10^9. Therefore, any learned mapping from these residues to family probabilities will necessarily reflect the same local densities that define the conjectured asymptotics, making the reproduced direction at 10^16 a direct consequence of the fitted behavior on the training distribution rather than independent corroboration.
full rationale
The paper's central claim rests on a model trained to 10^9 reproducing the correct asymptotic direction at 10^16 without density supervision, presented as corroboration of Hardy-Littlewood k-tuple predictions. However, the inputs explicitly include modular primorial residues, which supply the precise local divisibility conditions whose product defines the singular series. Labels derive from actual primality checks whose distribution already embeds those densities. Consequently, any recovered direction is a direct statistical consequence of the fitted mapping rather than independent discovery. This constitutes one instance of fitted_input_called_prediction with no other load-bearing circular steps in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Some problems of ‘Partitio Numerorum’: III. on the expression of a number as a sum of primes,
Extended preprint available as arXiv:2308.10817. 2 G. H. Hardy and J. E. Littlewood, “Some problems of ‘Partitio Numerorum’: III. on the expression of a number as a sum of primes,”Acta Mathematica, vol. 44, pp. 1–70,
-
[2]
A systematic analysis of performance measures for classifi- cation tasks,
arXiv:1910.02636. 4 M. Sokolova and G. Lapalme, “A systematic analysis of performance measures for classifi- cation tasks,”Information Processing and Management, vol. 45, no. 4, pp. 427–437,
-
[3]
5 S. Lee and S. Kim, “Exploring prime number classification: achieving high recall rate and rapid convergence with sparse encoding,”arXiv preprint arXiv:2402.03363,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.