Recognition: 1 theorem link
· Lean TheoremSteerable but Not Decodable: Function Vectors Operate Beyond the Logit Lens
Pith reviewed 2026-05-13 20:56 UTC · model grok-4.3
The pith
Function vectors steer models to correct answers even when no intermediate layer produces the right token under the logit lens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Function vectors extracted as mean activation differences across in-context learning demonstrations steer model outputs successfully in the large majority of cases where the logit lens cannot recover the correct answer from any intermediate layer; the converse pattern appears in only three of seventy-two task-model combinations. Steering accuracy above 0.90 still yields incoherent token distributions when the vector is projected through the unembedding. A diagonal tuned lens recovers one of fourteen steerable-not-decodable cases, while a two-layer MLP probe recovers five of ten via nonlinear structure but leaves the rest invisible to every decoder tested. Post-steering deltas, activation-pat
What carries the argument
Function vectors defined as the mean difference between activations on positive and negative ICL demonstrations; they are added to intermediate residual streams to steer behavior while the logit lens projects the same vectors through the unembedding matrix to test decodability.
If this is right
- Linear steerability and linear decodability are separable properties rather than two sides of the same representation.
- Vocabulary-projection tools miss interventions that still control model outputs on widely used families.
- Safety monitoring that relies on logit-lens inspection will overlook function-vector-style edits.
- Steering can succeed by rewriting intermediate computations without ever producing a decodable answer token.
Where Pith is reading between the lines
- Safety evaluations may need activation-patching or norm-transfer checks in addition to logit inspection to catch steering vectors.
- The observed family asymmetry suggests that architectural details determine whether steering leaves a visible trace or operates invisibly.
- Future probes could test whether the five cases left invisible to the MLP probe become visible under deeper nonlinear readouts or different training regimes.
Load-bearing premise
Task-relevant behaviors are carried by linear directions in activation space that must be both steerable when added and readable when projected through the unembedding.
What would settle it
A single task-model pair in which steering accuracy drops below chance while the logit lens recovers the correct answer from at least one intermediate layer.
Figures




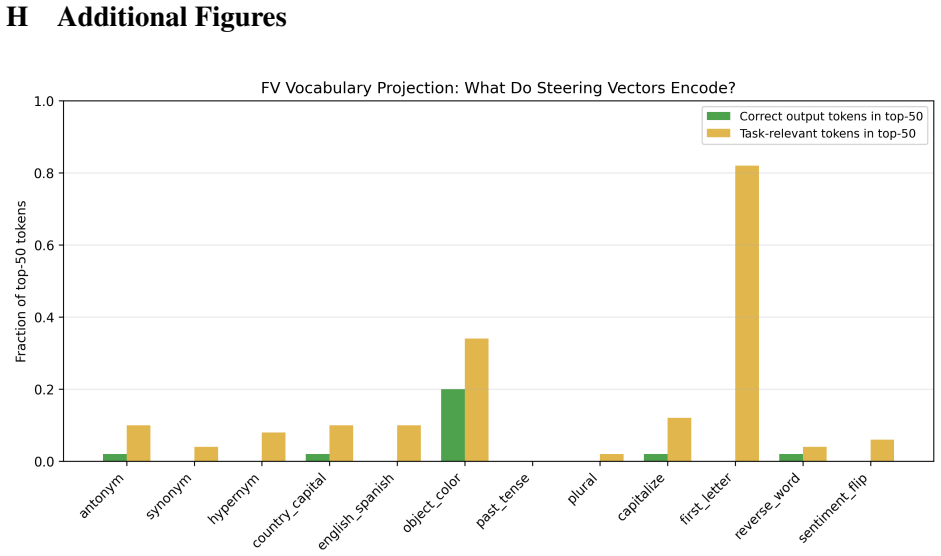


read the original abstract
Activation steering presupposes that task-relevant behaviors correspond to linear directions in activation space -- directions that should both steer the model and be readable along the unembedding. Function vectors (FVs), extracted as mean differences across ICL demonstrations, are the canonical test case; the prediction: steering and decoding succeed or fail together. Across 12 tasks, 6 models from 3 families, and 4,032 directed cross-template pairs, we find the opposite. FV steering routinely succeeds where the logit lens cannot decode the correct answer at any intermediate layer, while the converse -- decodable without steerable -- is nearly empty (3 of 72). The gap is not representational dialect. A diagonal tuned lens closes 1 of 14 steerable-not-decodable cases; a 2-layer MLP probe with a Hewitt \& Liang control closes 5 of 10 via nonlinearly encoded structure but leaves 5 invisible to every decoder tested. Even at $> 0.90$ steering accuracy, projecting the FV through the unembedding yields incoherent token distributions: FVs encode computational instructions, not answer directions. A model-family asymmetry sharpens the picture. Mistral FVs rewrite intermediate representations, while Llama and Gemma FVs steer the final output without leaving a logit-lens-visible trace, corroborated by three signals (post-steering deltas, activation-patching recovery, FV norm-transfer correlations). A previously reported negative cosine-transfer correlation dissolves at scale, adding at most $\Delta R^2 = 0.011$ beyond task identity. These results decompose the linear representation hypothesis into linear decodability and linear steerability and show they come apart opposite to intuition, with implications for safety monitoring: vocabulary-projection tools are blind to FV-style interventions on widely deployed model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that function vectors (FVs) extracted as mean differences across ICL demonstrations can steer model behavior even when the logit lens (and tuned lens or MLP probes) cannot decode the correct answer from any intermediate layer. Across 12 tasks, 6 models from 3 families, and 4032 directed cross-template pairs, steering succeeds where decoding fails (converse nearly empty at 3 of 72 cases); the gap persists after controls, FVs produce incoherent token distributions when projected through the unembedding, model-family asymmetries appear (Mistral rewrites intermediates while Llama/Gemma steer final outputs without logit-lens trace), and a previously reported negative cosine-transfer correlation dissolves at scale (adding at most ΔR²=0.011 beyond task identity).
Significance. If the results hold, the work is significant for decomposing the linear representation hypothesis into separable components of linear steerability and linear decodability, with the dissociation running opposite to the naive prediction that they should co-occur. The scale of the experiments (4032 pairs, multiple families, activation-patching recovery, norm-transfer correlations, and explicit controls) plus the falsifiable prediction that vocabulary-projection tools will miss FV-style interventions provide strong empirical grounding, with clear implications for safety monitoring on deployed models.
minor comments (3)
- [Abstract] Abstract and body use both '4,032' and '4032'; standardize the comma formatting for all numerical counts.
- [Results] The statement that 'projecting the FV through the unembedding yields incoherent token distributions' would be strengthened by a brief quantitative summary (e.g., top-token entropy or perplexity) rather than qualitative description alone.
- [Figures] Figure captions or legends should explicitly note the number of directed pairs per task-model combination to allow readers to assess the per-cell sample sizes supporting the 3-of-72 converse claim.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, detailed summary of the results, and recommendation to accept. We appreciate the recognition of the experimental scale, the model-family asymmetries, and the implications for safety monitoring via vocabulary-projection tools.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical study reporting observed dissociations between function-vector steering success and logit-lens decodability across 4032 cross-template pairs, 12 tasks, and 6 models. Central claims rest on direct experimental measurements (post-steering output deltas, activation patching recovery, norm-transfer correlations) rather than any derivation that reduces to fitted parameters or self-citations by construction. No self-definitional steps, fitted-input predictions, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear in the reported chain. The dissolution of a prior cosine-transfer correlation is presented as an observation at scale, not a constructed prediction. The work is self-contained against external benchmarks and falsifiable via the stated protocols.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task-relevant behaviors correspond to linear directions in activation space that should both steer the model and be readable along the unembedding.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FV steering routinely succeeds where the logit lens cannot decode the correct answer at any intermediate layer, while the converse is nearly empty (3 of 72).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Decodable but Not Corrected by Fixed Residual-Stream Linear Steering: Evidence from Medical LLM Failure Regimes
Overthinking in medical QA is linearly decodable at 71.6% accuracy yet fixed residual-stream steering yields no correction across 29 configurations, while enabling selective abstention with AUROC 0.610.
Reference graph
Works this paper leans on
-
[1]
Refusal in Language Models Is Mediated by a Single Direction
Arditi, A., Obeso, O., Shlegeris, B., and Amodei, D. Refusal in language models is mediated by a single direction.arXiv preprint arXiv:2406.11717, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Belinkov, Y . Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
work page 2022
-
[3]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Belrose, N., Furman, Z., Smith, L., Halawi, D., Ostrovsky, I., McKinney, L., Biderman, S., and Steinhardt, J. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Deni- son, C., Askell, A., et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
work page 2023
-
[5]
Analyzing transformers in embedding space.ACL, 2023
Dar, G., Geva, M., Gupta, A., and Berant, J. Analyzing transformers in embedding space.ACL, 2023
work page 2023
-
[6]
N., Lynch, A., Heimersheim, S., and Garriga-Alonso, A
Conmy, A., Mavor-Parker, A. N., Lynch, A., Heimersheim, S., and Garriga-Alonso, A. Towards automated circuit discovery for mechanistic interpretability.NeurIPS, 2023
work page 2023
-
[7]
Transformer feed-forward layers are key-value mem- ories.EMNLP, 2022
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value mem- ories.EMNLP, 2022
work page 2022
-
[8]
Dissecting recall of factual associations in auto-regressive language models.EMNLP, 2023
Geva, M., Caciularu, A., Wang, K., and Goldberg, Y . Dissecting recall of factual associations in auto-regressive language models.EMNLP, 2023
work page 2023
-
[9]
In-context learning creates task vectors.EMNLP Findings, 2023
Hendel, R., Geva, M., and Globerson, A. In-context learning creates task vectors.EMNLP Findings, 2023
work page 2023
-
[10]
Hernandez, E., Li, B. Z., and Andreas, J. Linearity of relation representations in transformer language models.ICLR, 2024
work page 2024
-
[11]
Hewitt, J. and Liang, P. Designing and interpreting probes with control tasks.EMNLP, 2019. 28
work page 2019
-
[12]
Jain, N., Sahlgren, M., and Nivre, J. Mechanistically analyzing the effects of fine-tuning on procedu- rally defined tasks.arXiv preprint arXiv:2311.12786, 2024
-
[13]
Inference-time intervention: Eliciting truthful answers from a language model.NeurIPS, 2024
Li, K., Patel, O., Viégas, F., Pfister, H., and Wattenberg, M. Inference-time intervention: Eliciting truthful answers from a language model.NeurIPS, 2024
work page 2024
-
[14]
Liu, T., Guo, S., and Arora, S. In-context vectors: Making in context learning more effective and controllable through latent space steering.arXiv preprint arXiv:2311.06668, 2023
-
[15]
Marks, S. and Tegmark, M. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Locating and editing factual associations in GPT
Meng, K., Bau, D., Andonian, A., and Belinkov, Y . Locating and editing factual associations in GPT. NeurIPS, 2022
work page 2022
-
[17]
interpreting GPT: the logit lens.LessWrong, 2020.https://www.lesswrong
nostalgebraist. interpreting GPT: the logit lens.LessWrong, 2020.https://www.lesswrong. com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens
work page 2020
-
[18]
Nadaf, M. S. B. Cross-template steering vector transfer reveals task-dependent failures of the linear representation assumption.Preliminary study, 2025
work page 2025
-
[19]
In-context learning and induction heads.Transformer Circuits Thread, 2022
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y ., Chen, A., et al. In-context learning and induction heads.Transformer Circuits Thread, 2022
work page 2022
-
[20]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. NeurIPS, 2022
work page 2022
-
[21]
Panickssery, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A. M. Steering Llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Park, K., Choe, Y . J., and Veitch, V . The linear representation hypothesis and the geometry of large language models.arXiv preprint arXiv:2311.03658, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, et al
Sclar, M., Choi, Y ., Tsvetkov, Y ., and Suhr, A. Quantifying language models’ sensitivity to spurious features in prompt design.arXiv preprint arXiv:2310.11324, 2023
-
[24]
Simpson, E. H. The interpretation of interaction in contingency tables.Journal of the Royal Statistical Society: Series B, 13(2):238–241, 1951
work page 1951
-
[25]
Linear Representations of Sentiment in Large Language Models
Tigges, C., Hollinsworth, O. J., Geiger, A., and Nanda, N. Linear representations of sentiment in large language models.arXiv preprint arXiv:2310.15154, 2023
work page internal anchor Pith review arXiv 2023
-
[26]
Todd, E., Li, M. L., Sharma, A. S., Mueller, A., Wallace, B. C., and Bau, D. Function vectors in large language models.ICLR, 2024
work page 2024
-
[27]
Steering Language Models With Activation Engineering
Turner, A. M., Thiergart, L., Udell, D., Leech, G., Mini, U., and MacDiarmid, M. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Interpretability in the wild: A circuit for indirect object identification in GPT-2 small.ICLR, 2023
Wang, K., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J. Interpretability in the wild: A circuit for indirect object identification in GPT-2 small.ICLR, 2023
work page 2023
-
[29]
Webson, A. and Pavlick, E. Do prompt-based models really understand the meaning of their prompts? NAACL, 2022. 29
work page 2022
-
[30]
Jailbroken: How does LLM safety training fail?NeurIPS, 2024
Wei, A., Haghtalab, N., and Steinhardt, J. Jailbroken: How does LLM safety training fail?NeurIPS, 2024
work page 2024
-
[31]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dom- browski, A.-K., et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023. 30
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.