Recognition: 2 theorem links
· Lean TheoremLow-Complexity Algorithm for Stackelberg Prediction Games with Global Optimality
Pith reviewed 2026-05-13 19:03 UTC · model grok-4.3
The pith
An ADMM solver for the spherical reformulation of Stackelberg prediction games delivers global solutions at low per-iteration cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
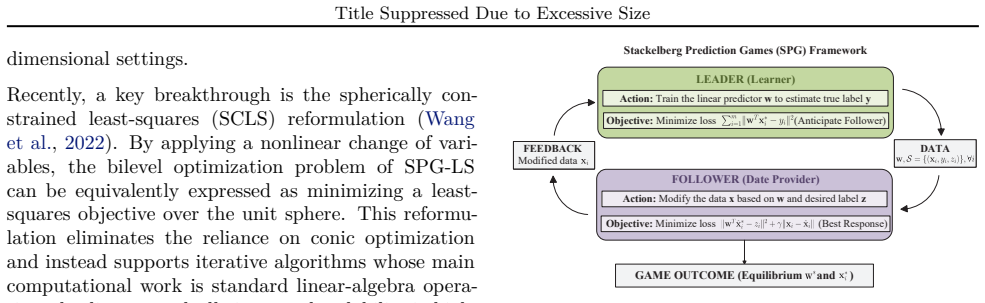
The authors establish that the bilevel Stackelberg prediction game in least squares reduces to a spherically constrained least-squares problem, and that an ADMM algorithm built on consensus splitting solves this problem to global optimality through fixed-point iterations whose updates remain closed-form and therefore inexpensive.
What carries the argument
Consensus splitting of the augmented Lagrangian that separates the quadratic objective from the spherical constraint, enabling a primal step that solves a constant shifted linear system, a projection onto the unit sphere, and a lightweight dual update.
If this is right
- Pre-factorization of the constant linear system matrix produces substantial speedups on repeated solves.
- The method remains competitive in solution quality with existing global solvers while scaling better to sparse high-dimensional data.
- The low per-iteration cost supports practical use of Stackelberg models in adversarial learning tasks that were previously limited by solver expense.
- Global optimality is retained without resorting to costly conic programming formulations.
Where Pith is reading between the lines
- The same splitting technique could be tested on other bilevel problems that admit spherical or norm-constrained reformulations.
- In dynamic settings the fast iterations might allow online re-optimization when new data arrives.
- Empirical scaling curves on even larger synthetic instances would quantify the practical speedup beyond the reported regimes.
Load-bearing premise
The consensus splitting must produce an ADMM iteration whose fixed point is exactly the global solution of the spherically constrained least-squares problem.
What would settle it
Run the ADMM solver on a small instance of the spherically constrained least-squares problem whose global solution is already known from an exact solver, then check whether the outputs match to machine precision.
Figures



read the original abstract
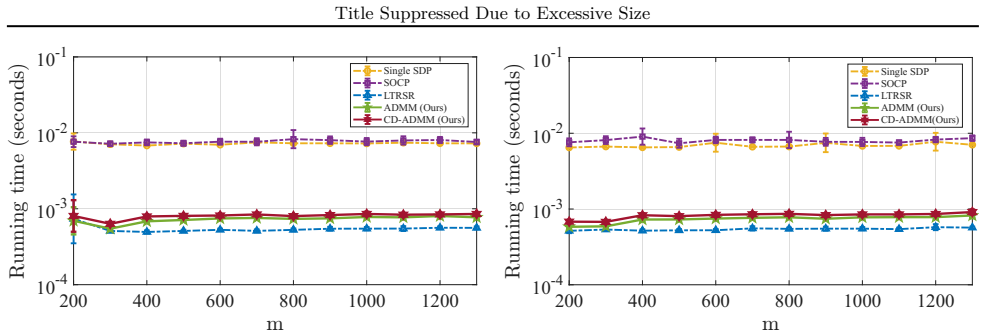
Stackelberg prediction games (SPGs) model strategic data manipulation in adversarial learning via a leader--follower interaction between a learner and a self-interested data provider, leading to challenging bilevel optimization problems. Focusing on the least-squares setting (SPG-LS), recent work shows that the bilevel program admits an equivalent spherically constrained least-squares (SCLS) reformulation, which avoids costly conic programming and enables scalable algorithms. In this paper, we develop a simple and efficient alternating direction method of multiplier (ADMM) based solver for the SCLS problem. By introducing a consensus splitting that separates the quadratic objective from the spherical constraint, we obtain an augmented Lagrangian formulation with closed-form updates: the primal quadratic step reduces to solving a fixed shifted linear system, the constraint step is a projection onto the unit sphere, and the dual step is a lightweight scaled ascent. The resulting method has low per-iteration complexity and allows pre-factorization of the constant system matrix for substantial speedups. Experiments demonstrate that the proposed ADMM approach achieves competitive solution quality with significantly improved computational efficiency compared with existing global solvers for SCLS, particularly in sparse and high-dimensional regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a low-complexity ADMM solver for the spherically constrained least-squares (SCLS) reformulation of Stackelberg prediction games in the least-squares setting (SPG-LS). A consensus splitting separates the quadratic objective from the unit-sphere constraint, yielding an augmented Lagrangian whose updates are closed-form: a fixed shifted linear system solve for the primal quadratic step, projection onto the sphere for the constraint step, and scaled dual ascent. Pre-factorization of the constant system matrix is used for speed. Experiments report competitive solution quality with substantially lower runtimes than existing global SCLS solvers, especially in sparse high-dimensional regimes.
Significance. If the fixed points of the ADMM iteration coincide with the global SCLS optimum, the work would supply a practical, scalable alternative to conic-programming solvers for bilevel optimization arising in adversarial learning. The closed-form updates and pre-factorization constitute clear algorithmic strengths that directly address computational bottlenecks. The reported efficiency gains in sparse regimes are empirically promising and could influence downstream applications in robust regression and strategic data manipulation.
major comments (2)
- [Abstract and §3] Abstract and §3 (ADMM derivation): the headline claim of 'global optimality' rests on the assertion that the consensus splitting produces an iteration whose fixed point is exactly the global minimizer of the non-convex QCQP. No convergence analysis is supplied showing that every stationary point is global rather than a local KKT point; standard non-convex ADMM theory only guarantees stationarity under additional assumptions (e.g., Kurdyka-Łojasiewicz inequality with verifiable parameters) that are not checked here. This equivalence is load-bearing for the title and central contribution.
- [§4] §4 (Experiments): competitive quality is demonstrated via runtime and objective-value comparisons, yet no verification of globality is performed (e.g., optimality-gap bounds via SDP relaxation on small instances, or exhaustive enumeration in low-dimensional cases). Without such controls it remains unclear whether the method consistently recovers the global solution or occasionally converges to inferior stationary points in the sparse high-dimensional regime highlighted in the abstract.
minor comments (2)
- [§3] The precise scaling factor appearing in the dual update step should be stated explicitly when the augmented Lagrangian is first introduced.
- [§2] A brief reminder of the prior SCLS equivalence (including any restrictions) would improve readability for readers unfamiliar with the referenced reformulation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments correctly identify that the current manuscript does not supply a rigorous convergence proof for global optimality of the ADMM fixed points and lacks explicit globality verification in the experiments. We address both points below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (ADMM derivation): the headline claim of 'global optimality' rests on the assertion that the consensus splitting produces an iteration whose fixed point is exactly the global minimizer of the non-convex QCQP. No convergence analysis is supplied showing that every stationary point is global rather than a local KKT point; standard non-convex ADMM theory only guarantees stationarity under additional assumptions (e.g., Kurdyka-Łojasiewicz inequality with verifiable parameters) that are not checked here. This equivalence is load-bearing for the title and central contribution.
Authors: We agree that the manuscript does not contain a convergence analysis proving every stationary point of the ADMM iteration is a global minimizer. The derivation shows that fixed points satisfy the KKT conditions of the SCLS QCQP via the consensus splitting, but this is insufficient to guarantee globality in the non-convex setting. In the revision we will change the title, abstract, and §3 to state that the algorithm computes stationary points of the SCLS problem (with closed-form updates and pre-factorization) and that these points yield competitive objective values in practice. We will add a short discussion noting the absence of a global-convergence guarantee and identifying the specific structure (quadratic objective plus sphere constraint) as a potential avenue for future analysis under additional assumptions such as the Kurdyka-Łojasiewicz property. revision: yes
-
Referee: [§4] §4 (Experiments): competitive quality is demonstrated via runtime and objective-value comparisons, yet no verification of globality is performed (e.g., optimality-gap bounds via SDP relaxation on small instances, or exhaustive enumeration in low-dimensional cases). Without such controls it remains unclear whether the method consistently recovers the global solution or occasionally converges to inferior stationary points in the sparse high-dimensional regime highlighted in the abstract.
Authors: We concur that the current experiments do not include explicit checks for globality. In the revised §4 we will add results on small-scale instances comparing the ADMM output to SDP relaxations (reporting optimality gaps) and, where dimension permits, to exhaustive enumeration or a global solver. These controls will be used to assess whether the method recovers the global solution on the tested low-dimensional cases. For the sparse high-dimensional regime we will retain the runtime and objective-value comparisons while noting the limitation that global optimality cannot be certified at scale. revision: yes
Circularity Check
Standard ADMM splitting on prior SCLS reformulation; minor self-citation not load-bearing
full rationale
The derivation introduces a consensus splitting for the SCLS problem, forms the augmented Lagrangian, and obtains closed-form primal/dual updates (quadratic solve + sphere projection). These steps follow directly from standard ADMM algebra applied to the given objective and constraint; no equation is defined in terms of its own output. The SPG-LS to SCLS equivalence is referenced to recent work rather than re-derived here, but the algorithm's per-iteration complexity and empirical speedups are independent of that citation. No fitted parameter is relabeled as a prediction, and no uniqueness theorem is invoked to force the method. This is the normal case of applying an established solver template to a known reformulation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The bilevel Stackelberg least-squares program admits an equivalent spherically constrained least-squares reformulation
- domain assumption The proposed consensus splitting produces an ADMM iteration whose limit solves the original SCLS problem globally
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By introducing a consensus splitting that separates the quadratic objective from the spherical constraint, we obtain an augmented Lagrangian formulation with closed-form updates... every limit point is a KKT point of (13) (hence a stationary point).
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1. The function f(r) is closed, smooth, bounded, and convex. Then, the strong duality for the non-convex problem (13) holds.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Springer Berlin Heidelberg. ISBN 978-3-642- 40994-3. Bishop, N., Tran-Thanh, L., and Gerding, E. Optimal learning from verified training data. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 9520–9529. Curran Associates, Inc., 2020. URL https: //proceedings.neur...
work page 2020
-
[2]
Foundations and Trends® in Machine Learning , author =
doi: 10.1561/2200000016. Brückner, M. and Scheffer, T. Stackelberg games for adversarial prediction problems. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’11, pp. 547–555, New York, NY, USA, 2011. Association for Computing Machinery. ISBN 9781450308137. doi: 10.1145/2020408.2020495. URL https:...
-
[3]
Association for Computing Machinery. ISBN 1581138881. doi: 10.1145/1014052.1014066. URL https://doi.org/10.1145/1014052.1014066. Gast, N., Ioannidis, S., Loiseau, P., and Roussillon, B. Linear regression from strategic data sources. ACM Trans. Econ. Comput., 8(2), May 2020. ISSN 2167-
-
[4]
URL https://doi.org/ 10.1145/3391436
doi: 10.1145/3391436. URL https://doi.org/ 10.1145/3391436. Higham, N. J. Cholesky factorization. WIREs Com- put. Stat., 1(2):251–254, September 2009. ISSN 1939-5108. doi: 10.1002/wics.18. URL https://doi. org/10.1002/wics.18. Jeroslow, R. G. The polynomial hierarchy and a sim- ple model for competitive analysis. Mathematical Programming, 32(2):146–164, 1...
-
[5]
URL https: //doi.org/10.24963/ijcai.2019/862
doi: 10.24963/ijcai.2019/862. URL https: //doi.org/10.24963/ijcai.2019/862. Perdomo, J. C., Zrnic, T., Mendler-Dünner, C., and Hardt, M. Performative prediction. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020. Rafiei, M. H. and Adeli, H. A novel machine learn- ing model for estimation of sale prices of rea...
-
[6]
The s-subproblem in ( 16b) is an exact projection onto the unit sphere
(33) Step 3: Descent property of the s-update. The s-subproblem in ( 16b) is an exact projection onto the unit sphere. Therefore, L2(rk+1, sk, vk) − L2(rk+1, sk+1, vk) ≥ 0. (34) Step 4: Effect of the dual update. Using vk+1 = vk + dk+1, we directly compute L2(rk+1, sk+1, vk+1) = L2(rk+1, sk+1, vk) + ρ 2 ∥dk+1∥2
-
[7]
Define the Lyapunov function for k ≥ 1 as Φk ≜ L2(rk, sk, vk) + ρ 2 ∥sk − sk−1∥2
(35) Step 5: Lyapunov function and global descent. Define the Lyapunov function for k ≥ 1 as Φk ≜ L2(rk, sk, vk) + ρ 2 ∥sk − sk−1∥2
-
[8]
(36) Combining ( 33)–(35) and using sk+1 − sk → 0, we obtain Φk − Φk+1 ≥ ρ 2 ∥rk+1 − rk∥2 2 + ρ 2 ∥sk+1 − sk∥2 2 + ρ 2 ∥dk+1∥2
-
[9]
Step 6: Residual and variable convergence
(37) Since f (r) is bounded below on the unit sphere, {Φk} is bounded below and monotonically decreasing, hence convergent. Step 6: Residual and variable convergence. Summing ( 37) over k yields ∞X k=0 ∥rk+1 − rk∥2 2 + ∞X k=0 ∥sk+1 − sk∥2 2 + ∞X k=0 ∥dk+1∥2 2 < ∞. Consequently, rk pri = ∥sk − rk∥2 → 0, r k dual = ρ∥sk − sk−1∥2 → 0, and ∥vk+1 − vk∥2 → 0. S...
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.