Recognition: 2 theorem links
· Lean TheoremFoundation Models Defining A New Era In Sensor-based Human Activity Recognition: A Survey And Outlook
Pith reviewed 2026-05-13 18:45 UTC · model grok-4.3
The pith
Foundation models offer a unifying paradigm for sensor-based human activity recognition through large-scale self-supervised pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that foundation models pretrained at scale using self-supervised and multimodal learning provide a unifying approach to overcome limitations in sensor-based HAR by creating reusable and adaptable representations for understanding activities. It synthesizes work into a lifecycle taxonomy and identifies three trajectories: HAR-specific models, adaptation of general models, and LLM integration, while noting challenges in data, privacy, and alignment.
What carries the argument
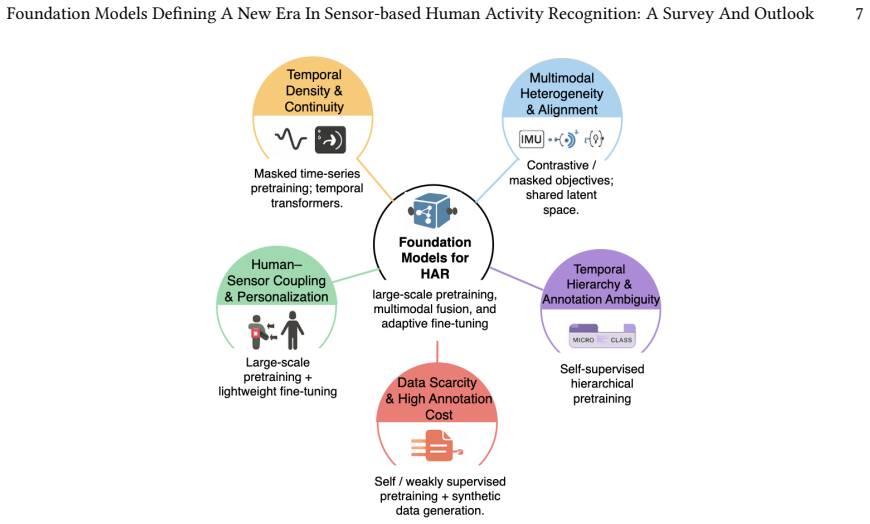
The lifecycle-oriented taxonomy for organizing foundation model development in HAR, covering input design, pretraining, adaptation, and utilization to reveal patterns in modality scope, architectures, and learning methods.
If this is right
- Foundation models reduce dependence on large labeled datasets for training HAR systems.
- Reusable representations improve generalization across different users, devices, and contexts.
- Multimodal pretraining helps handle heterogeneity in sensor types and placements.
- LLM integration enables more advanced reasoning and human-friendly interaction in activity recognition.
- Addressing challenges in data curation and privacy will be key to responsible deployment.
Where Pith is reading between the lines
- These models may enable always-on activity understanding on edge devices with minimal retraining.
- The survey suggests a shift toward general-purpose activity models that could apply across health monitoring and smart environments.
- Future work could validate the trajectories by measuring adaptation efficiency on diverse sensor benchmarks.
Load-bearing premise
The surveyed works are mature and comprehensive enough to support a stable taxonomy and clear identification of three main development trajectories.
What would settle it
A new survey or set of papers revealing additional major trajectories or significant omissions in the current taxonomy would indicate the synthesis is incomplete.
Figures




read the original abstract
Sensor-based Human Activity Recognition (HAR) underpins many ubiquitous and wearable computing applications, yet current models remain limited by scarce labels, sensor heterogeneity, and weak generalization across users, devices, and contexts. Foundation models, which are generally pretrained at scale using self-supervised and multimodal learning, offer a unifying paradigm to address these challenges by learning reusable, adaptable representations for activity understanding. This survey synthesizes emerging foundation models for sensor-based HAR. We first clarify foundational concepts, definitions, and evaluation criteria, then organize existing work using a lifecycle-oriented taxonomy spanning input design, pretraining, adaptation, and utilization. Rather than enumerating individual models, we analyze recurring design patterns and trade-offs across nine technical axes, including modality scope, tokenization, architectures, learning paradigms, adaptation mechanisms, and deployment settings. From this synthesis, we identify three dominant development trajectories: (1) HAR-specific foundation models trained from scratch on large sensor corpora, (2) adaptation of general time-series or multimodal foundation models to sensor-based HAR, and (3) integration of large language models for reasoning, annotation, and human-AI interaction. We conclude by highlighting open challenges in data curation, multimodal alignment, personalization, privacy, and responsible deployment, and outline directions toward general-purpose, interpretable, and human-centered foundation models for activity understanding. A complete, continuously updated index of papers and models is available in our companion repository: https://github.com/zhaxidele/Foundation-Models-Defining-A-New-Era-In-Human-Activity-Recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey on foundation models for sensor-based human activity recognition (HAR). It clarifies foundational concepts and evaluation criteria, organizes existing work using a lifecycle-oriented taxonomy that spans input design, pretraining, adaptation, and utilization, analyzes recurring design patterns and trade-offs across nine technical axes, identifies three dominant development trajectories (HAR-specific models trained from scratch, adaptation of general time-series or multimodal models, and integration of large language models), and discusses open challenges in data curation, multimodal alignment, personalization, privacy, and responsible deployment, while providing a companion GitHub repository for an updated index of papers and models.
Significance. If the synthesis holds, this survey offers significant value by providing the first systematic framework for an emerging intersection of foundation models and sensor-based HAR. It moves beyond enumeration to highlight design patterns and trajectories, which can guide researchers in addressing challenges like scarce labels and weak generalization. The continuously updated repository is a notable strength, enhancing the work's utility and longevity in a rapidly evolving field.
major comments (1)
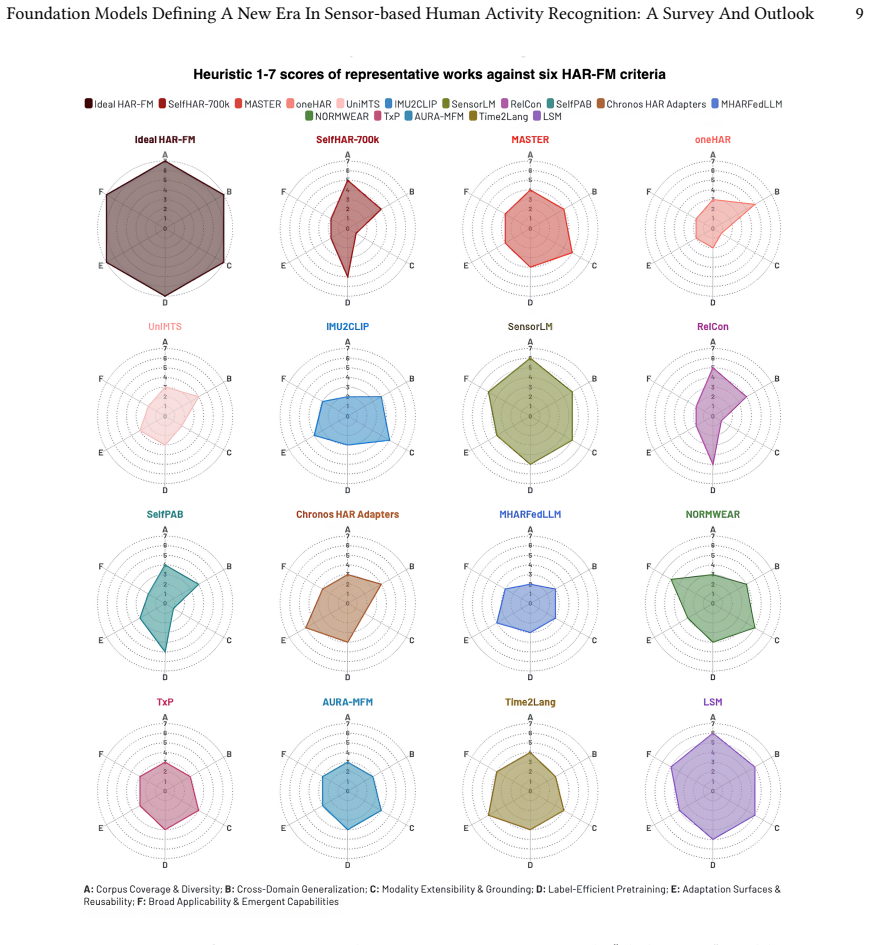
- [Lifecycle taxonomy and trajectories identification] The central claim that foundation models provide a unifying paradigm rests on the proposed lifecycle taxonomy and the extraction of three dominant trajectories. The manuscript acknowledges the field as emerging with limited large-scale sensor corpora and few models pretrained at typical scales; therefore, the section should include explicit details on the literature review methodology, search terms, and inclusion criteria to substantiate that the identified patterns and trajectories are representative rather than reflective of the current small and potentially transient corpus.
minor comments (2)
- [Abstract] The abstract refers to analysis 'across nine technical axes' but does not enumerate them; listing the axes (e.g., modality scope, tokenization, architectures) would improve clarity for readers.
- [Conclusion] The outlook on future directions toward general-purpose models could benefit from more concrete milestones or benchmarks to make the recommendations more actionable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the survey's contributions. We have revised the manuscript to address the concern regarding methodological transparency in the literature review.
read point-by-point responses
-
Referee: [Lifecycle taxonomy and trajectories identification] The central claim that foundation models provide a unifying paradigm rests on the proposed lifecycle taxonomy and the extraction of three dominant trajectories. The manuscript acknowledges the field as emerging with limited large-scale sensor corpora and few models pretrained at typical scales; therefore, the section should include explicit details on the literature review methodology, search terms, and inclusion criteria to substantiate that the identified patterns and trajectories are representative rather than reflective of the current small and potentially transient corpus.
Authors: We agree that explicit details on the literature review methodology are necessary to substantiate the taxonomy and trajectories, particularly in an emerging field. In the revised manuscript, we have added a new subsection 'Literature Review Methodology' immediately following the introduction. This subsection specifies: (1) the databases searched (Google Scholar, arXiv, IEEE Xplore, ACM Digital Library); (2) the exact search strings employed (combinations of 'foundation model', 'pretrained model', 'self-supervised learning' with 'sensor-based human activity recognition', 'wearable HAR', 'time-series foundation model', and 'multimodal HAR'); (3) the temporal scope (January 2020 to March 2024); (4) inclusion criteria (papers proposing or adapting models pretrained on sensor data at scale, or demonstrating adaptation of general foundation models to HAR tasks, with emphasis on self-supervised or multimodal pretraining); and (5) exclusion criteria (purely supervised small-scale studies without pretraining components). We also report the initial retrieval count (approximately 180 papers) and the final curated set (42 papers) after duplicate removal and screening. These additions clarify that the three trajectories emerge from a systematic synthesis of the available literature rather than selective enumeration. revision: yes
Circularity Check
No circularity: survey synthesis rests on external literature
full rationale
This is a survey paper that reviews and categorizes existing external work on foundation models for sensor-based HAR. The lifecycle taxonomy (input design, pretraining, adaptation, utilization) and the three identified trajectories are extracted from patterns across cited papers rather than any internal derivations, equations, or parameter fits. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear; the central claim of a unifying paradigm is presented as an observation from the reviewed corpus. The analysis is therefore self-contained against external benchmarks with no reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Foundation models are generally pretrained at scale using self-supervised and multimodal learning to produce reusable representations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe first clarify foundational concepts... organize existing work using a lifecycle-oriented taxonomy spanning input design, pretraining, adaptation, and utilization... three dominant development trajectories: (1) HAR-specific foundation models trained from scratch...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPretraining paradigms... Contrastive... Generative... Hybrid / Self-supervised
Forward citations
Cited by 1 Pith paper
-
EduGage: Methods and Dataset for Sensor-Based Momentary Assessment of Engagement in Self-Guided Video Learning
EduGage releases a multimodal sensor dataset and models for estimating learner engagement in self-guided video learning, reporting MAE of 0.81 and outperforming baselines with 16 participants.
Reference graph
Works this paper leans on
- [1]
-
[2]
R Akila, J Brindha Merin, A Radhika, and Niyati Kumari Behera. 2023. Human Activity Recognition Using Ensemble Neural Networks and The Analysis of Multi-Environment Sensor Data Within Smart Environments.Journal of Wireless Mobile Networks, Ubiquitous Computing, and Dependable Applications14, 3 (2023), 218–229
work page 2023
-
[3]
Furqan Alam, Paweł Pławiak, Ahmed Almaghthawi, Mohammad Reza Chalak Qazani, Sanat Mohanty, and Roohallah Alizadehsani. 2024. NeuroHAR: a neuroevolutionary method for human activity recognition (HAR) for health monitoring.IEEE Access(2024)
work page 2024
-
[4]
Sana Alamgeer, Yasine Souissi, and Anne Ngu. 2025. AI-Generated Fall Data: Assessing LLMs and Diffusion Model for Wearable Fall Detection. Sensors25, 16 (2025), 5144
work page 2025
-
[5]
Leonardo Alchieri, Vittoria Scocco, Nouran Abdalazim, Lidia Alecci, and Silvia Santini. 2025. Improving Human Behavior Recognition Using Bilateral Electrodermal Activity Data Collected From Wearable Devices. In2025 International Conference on Activity and Behavior Computing (ABC). IEEE, 1–10
work page 2025
-
[6]
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. 2024. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Anindya Das Antar, Masud Ahmed, and Md Atiqur Rahman Ahad. 2019. Challenges in sensor-based human activity recognition and a comparative analysis of benchmark datasets: A review. In2019 Joint 8th International Conference on Informatics, Electronics & Vision (ICIEV) and 2019 3rd International Conference on Imaging, Vision & Pattern Recognition (icIVPR). IE...
work page 2019
-
[8]
Muhammad Haseeb Arshad, Muhammad Bilal, and Abdullah Gani. 2022. Human activity recognition: Review, taxonomy and open challenges. Sensors22, 17 (2022), 6463
work page 2022
-
[9]
Lulu Ban, Tao Zhu, Xiangqing Lu, Qi Qiu, Wenyong Han, Shuangjian Li, Liming Chen, Kevin I-Kai Wang, Mingxing Nie, and Yaping Wan. 2025. HAR-DoReMi: Optimizing Data Mixture for Self-Supervised Human Activity Recognition Across Heterogeneous IMU Datasets.arXiv preprint arXiv:2503.13542(2025)
- [10]
-
[11]
Ling Bao and Stephen S. Intille. 2004. Activity recognition from user-annotated acceleration data. InPervasive Computing. Springer, 1–17
work page 2004
-
[12]
Billur Barshan and Aras Yurtman. 2016. Investigating inter-subject and inter-activity variations in activity recognition using wearable motion sensors.Comput. J.59, 9 (2016), 1345–1362
work page 2016
-
[13]
Mouna Benchekroun, Pedro Elkind Velmovitsky, Dan Istrate, Vincent Zalc, Plinio Pelegrini Morita, and Dominique Lenne. 2023. Cross dataset analysis for generalizability of HRV-based stress detection models.Sensors23, 4 (2023), 1807
work page 2023
-
[14]
Sizhen Bian, Mengxi Liu, Bo Zhou, and Paul Lukowicz. 2022. The state-of-the-art sensing techniques in human activity recognition: A survey. Sensors22, 12 (2022), 4596
work page 2022
-
[15]
Sizhen Bian, Mengxi Liu, Bo Zhou, Paul Lukowicz, and Michele Magno. 2024. Body-area capacitive or electric field sensing for human activity recognition and human-computer interaction: A comprehensive survey.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 1 (2024), 1–49
work page 2024
-
[16]
Sizhen Bian and Paul Lukowicz. 2021. A systematic study of the influence of various user specific and environmental factors on wearable human body capacitance sensing. InEAI International Conference on Body Area Networks. Springer, 247–274
work page 2021
- [17]
-
[18]
Sizhen Bian, Xiaying Wang, Tommaso Polonelli, and Michele Magno. 2022. Exploring automatic gym workouts recognition locally on wearable resource-constrained devices. In2022 IEEE 13th International Green and Sustainable Computing Conference (IGSC). IEEE, 1–6
work page 2022
-
[19]
Sizhen Bian, Bo Zhou, Hymalai Bello, and Paul Lukowicz. 2020. A wearable magnetic field based proximity sensing system for monitoring COVID-19 social distancing. InProceedings of the 2020 ACM International Symposium on Wearable Computers. 22–26
work page 2020
-
[20]
Simon B¨"ohi and Shkurta Gashi. 2024. Large language models for wearable data analysis and interpretation.The Second Tiny Papers Track at ICLR 2024(2024)
work page 2024
-
[21]
Pietro Bonazzi, Sizhen Bian, Giovanni Lippolis, Yawei Li, Sadique Sheik, and Michele Magno. 2024. Retina: Low-power eye tracking with event camera and spiking hardware. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5684–5692
work page 2024
-
[22]
Pietro Bonazzi, Thomas Rüegg, Sizhen Bian, Yawei Li, and Michele Magno. 2023. Tinytracker: Ultra-fast and ultra-low-power edge vision in-sensor for gaze estimation. In2023 IEEE SENSORS. IEEE, 1–4
work page 2023
-
[23]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language Models are Few-Shot Learners.Advances in Neural Information Processing Systems (NeurIPS)33 (2020), 1877–1901
work page 2020
-
[24]
Tori Andika Bukit, Ericka Pamela Bermudez Pillado, Bernardo Nugroho Yahya, and Seok-Lyong Lee. 2025. Activity Transitions for Semi-Supervised Federated Learning in Sensor-Based Human Activity Recognition.Applied Soft Computing(2025), 113793. Manuscript submitted to ACM 32 Trovato et al
work page 2025
-
[25]
Jin Chen, Zheng Liu, Xu Huang, Chenwang Wu, Qi Liu, Gangwei Jiang, Yuanhao Pu, Yuxuan Lei, Xiaolong Chen, Xingmei Wang, et al. 2024. When large language models meet personalization: Perspectives of challenges and opportunities.World Wide Web27, 4 (2024), 42
work page 2024
-
[26]
Kaixuan Chen, Dalin Zhang, Lina Yao, Bin Guo, Zhiwen Yu, and Yunhao Liu. 2021. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities.ACM Computing Surveys (CSUR)54, 4 (2021), 1–40
work page 2021
-
[27]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A Simple Framework for Contrastive Learning of Visual Representa- tions.International Conference on Machine Learning (ICML)(2020), 1597–1607
work page 2020
-
[28]
Wenqiang Chen, Jiaxuan Cheng, Leyao Wang, Wei Zhao, and Wojciech Matusik. 2024. Sensor2text: Enabling natural language interactions for daily activity tracking using wearable sensors.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 4 (2024), 1–26
work page 2024
-
[29]
Zheyi Chen, Liuchang Xu, Hongting Zheng, Luyao Chen, Amr Tolba, Liang Zhao, Keping Yu, and Hailin Feng. 2024. Evolution and Prospects of Foundation Models: From Large Language Models to Large Multimodal Models.Computers, Materials & Continua80, 2 (2024)
work page 2024
-
[30]
Dongzhou Cheng, Lei Zhang, Lutong Qin, Shuoyuan Wang, Hao Wu, and Aiguo Song. 2024. MaskCAE: Masked convolutional AutoEncoder via sensor data reconstruction for self-supervised human activity recognition.IEEE Journal of Biomedical and Health Informatics28, 5 (2024), 2687–2698
work page 2024
-
[31]
2013.Learning and recognizing the hierarchical and sequential structure of human activities
Heng-Tze Cheng. 2013.Learning and recognizing the hierarchical and sequential structure of human activities. Carnegie Mellon University
work page 2013
-
[32]
Akshat Choube, Ha Le, Jiachen Li, Kaixin Ji, Vedant Das Swain, and Varun Mishra. 2025. GLOSS: Group of LLMs for Open-Ended Sensemaking of Passive Sensing Data for Health and Wellbeing.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–32
work page 2025
-
[33]
Gabriele Civitarese, Michele Fiori, Priyankar Choudhary, and Claudio Bettini. 2025. Large language models are zero-shot recognizers for activities of daily living.ACM Transactions on Intelligent Systems and Technology16, 4 (2025), 1–32
work page 2025
-
[34]
Ian Cleland, Luke Nugent, Federico Cruciani, and Chris Nugent. 2024. Leveraging large language models for activity recognition in smart environments. In2024 International Conference on Activity and Behavior Computing (ABC). IEEE, 1–8
work page 2024
-
[35]
Federico Cruciani, Stefan Gerd Fritsch, Ian Cleland, Vitor Fortes Rey, Chris Nugent, and Paul Lukowicz. 2025. Few-Shot Human Activity Recognition Using Lightweight Language Models. In2025 International Conference on Activity and Behavior Computing (ABC). IEEE, 1–9
work page 2025
- [36]
-
[37]
Florenc Demrozi, Marin Jereghi, and Graziano Pravadelli. 2021. Towards the automatic data annotation for human activity recognition based on wearables and BLE beacons. In2021 IEEE International Symposium on Inertial Sensors and Systems (INERTIAL). IEEE, 1–4
work page 2021
- [38]
-
[39]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, and et al. 2021. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR)
work page 2021
-
[40]
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, et al. 2023. Palm-e: An embodied multimodal language model. (2023)
work page 2023
-
[41]
Linus Ericsson, Henry Gouk, Chen Change Loy, and Timothy M Hospedales. 2022. Self-supervised representation learning: Introduction, advances, and challenges.IEEE Signal Processing Magazine39, 3 (2022), 42–62
work page 2022
-
[42]
Eray Erturk, Fahad Kamran, Salar Abbaspourazad, Sean Jewell, Harsh Sharma, Yujie Li, Sinead Williamson, Nicholas J Foti, and Joseph Futoma
- [43]
-
[44]
Cathy Mengying Fang, Valdemar Danry, Nathan Whitmore, Andria Bao, Andrew Hutchison, Cayden Pierce, and Pattie Maes. 2024. Physiollm: Supporting personalized health insights with wearables and large language models. In2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI). IEEE, 1–8
work page 2024
-
[45]
Illia Fedorin. 2025. Virtual PPG Reconstruction from Accelerometer Data via Adaptive Denoising and Cross-Modal Fusion.Information Fusion (2025), 103781
work page 2025
-
[46]
Stefan Gerd Fritsch, Cennet Oguz, Vitor Fortes Rey, Lala Ray, Maximilian Kiefer-Emmanouilidis, and Paul Lukowicz. 2025. Mujo: Multimodal joint feature space learning for human activity recognition. In2025 IEEE International Conference on Pervasive Computing and Communications (PerCom). IEEE, 1–12
work page 2025
-
[47]
Yusuke Fukazawa and Megumi Kodaka. 2025. LLM-based Intermediate Interpretations for Predicting Nurse Stress and Its Causes from Step Count Data. (2025)
work page 2025
- [48]
- [49]
-
[50]
2023.Personalized Foundation Models for Decision-Making
Shijie Geng. 2023.Personalized Foundation Models for Decision-Making. Ph. D. Dissertation. Rutgers The State University of New Jersey, School of Graduate Studies
work page 2023
-
[51]
Marco Giordano, Christoph Leitner, Christian Vogt, Luca Benini, and Michele Magno. 2025. Pulse: Accurate and robust ultrasound-based continuous heart-rate monitoring on a wrist-worn iot device.IEEE Internet of Things Journal(2025). Manuscript submitted to ACM Foundation Models Defining A New Era In Sensor-based Human Activity Recognition: A Survey And Outlook 33
work page 2025
-
[52]
Yu Guan and Thomas Plötz. 2017. Ensembles of deep LSTM learners for activity recognition using wearables. InProceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT)
work page 2017
-
[53]
Yifan Guo, Zhu Wang, Qian Qin, Yangqian Lei, Qiwen Gan, Zhuo Sun, Chao Chen, Bin Guo, and Zhiwen Yu. 2025. mmPencil: Toward Writing- Style-Independent In-Air Handwriting Recognition via mmWave Radar and Large Vision-Language Model.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 3 (2025), 1–30
work page 2025
-
[54]
Harish Haresamudram, Irfan Essa, and Thomas Ploetz. 2024. Towards learning discrete representations via self-supervision for wearables-based human activity recognition.Sensors24, 4 (2024), 1238
work page 2024
-
[55]
Harish Haresamudram, Irfan Essa, and Thomas Plötz. 2022. Assessing the state of self-supervised human activity recognition using wearables. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies6, 3 (2022), 1–47
work page 2022
-
[56]
Harish Haresamudram, Chi Ian Tang, Sungho Suh, Paul Lukowicz, and Thomas Ploetz. 2025. Past, present, and future of sensor-based human activity recognition using wearables: A surveying tutorial on a still challenging task.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies9, 2 (2025), 1–44
work page 2025
-
[57]
Shruthi K Hiremath and Thomas Ploetz. 2024. Game of LLMs: Discovering structural constructs in activities using large language models. In Companion of the 2024 on ACM International Joint Conference on Pervasive and Ubiquitous Computing. 487–492
work page 2024
- [58]
-
[59]
Zhiqing Hong, Zelong Li, Shuxin Zhong, Wenjun Lyu, Haotian Wang, Yi Ding, Tian He, and Desheng Zhang. 2024. Crosshar: Generalizing cross-dataset human activity recognition via hierarchical self-supervised pretraining.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 2 (2024), 1–26
work page 2024
-
[60]
Zhiqing Hong, Yiwei Song, Zelong Li, Anlan Yu, Shuxin Zhong, Yi Ding, Tian He, and Desheng Zhang. 2025. Llm4har: Generalizable on-device human activity recognition with pretrained llms. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4511–4521
work page 2025
- [61]
-
[62]
Md Mofijul Islam and Tariq Iqbal. 2020. Hamlet: A hierarchical multimodal attention-based human activity recognition algorithm. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 10285–10292
work page 2020
-
[63]
Md Milon Islam, Sheikh Nooruddin, Fakhri Karray, and Ghulam Muhammad. 2022. Human activity recognition using tools of convolutional neural networks: A state of the art review, data sets, challenges, and future prospects.Computers in biology and medicine149 (2022), 106060
work page 2022
-
[64]
Yash Jain, Chi Ian Tang, Chulhong Min, Fahim Kawsar, and Akhil Mathur. 2022. Collossl: Collaborative self-supervised learning for human activity recognition.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies6, 1 (2022), 1–28
work page 2022
-
[65]
Ashish Jaiswal, Ashwin Ramesh Babu, Mohammad Zaki Zadeh, Debapriya Banerjee, and Fillia Makedon. 2020. A survey on contrastive self- supervised learning.Technologies9, 1 (2020), 2
work page 2020
-
[66]
Sijie Ji, Xinzhe Zheng, and Chenshu Wu. 2024. Hargpt: Are llms zero-shot human activity recognizers?. In2024 IEEE International Workshop on Foundation Models for Cyber-Physical Systems & Internet of Things (FMSys). IEEE, 38–43
work page 2024
-
[67]
Sivakumar Kalimuthu, Thinagaran Perumal, Razali Yaakob, Erzam Marlisah, and Lawal Babangida. 2021. Human Activity Recognition based on smart home environment and their applications, challenges. In2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE). IEEE, 815–819
work page 2021
- [68]
- [69]
-
[70]
Misha Karim, Shah Khalid, Aliya Aleryani, Jawad Khan, Irfan Ullah, and Zafar Ali. 2024. Human action recognition systems: A review of the trends and state-of-the-art.IEEE Access12 (2024), 36372–36390
work page 2024
-
[71]
Justin Khasentino, Anastasiya Belyaeva, Xin Liu, Zhun Yang, Nicholas A Furlotte, Chace Lee, Erik Schenck, Yojan Patel, Jian Cui, Logan Douglas Schneider, et al. 2025. A personal health large language model for sleep and fitness coaching.Nature Medicine(2025), 1–10
work page 2025
- [72]
-
[73]
Tomoyoshi Kimura, Jinyang Li, Tianshi Wang, Yizhuo Chen, Ruijie Wang, Denizhan Kara, Maggie Wigness, Joydeep Bhattacharyya, Mudhakar Srivatsa, Shengzhong Liu, et al. 2024. Vibrofm: Towards micro foundation models for robust multimodal iot sensing. In2024 IEEE 21st International Conference on Mobile Ad-Hoc and Smart Systems (MASS). IEEE, 10–18
work page 2024
-
[74]
Hilde Kuehne, Ali Arslan, and Thomas Serre. 2014. The language of actions: Recovering the syntax and semantics of goal-directed human activities. InProceedings of the IEEE conference on computer vision and pattern recognition. 780–787
work page 2014
-
[75]
Hyeokhyen Kwon, Gregory D Abowd, and Thomas Plötz. 2019. Handling annotation uncertainty in human activity recognition. InProceedings of the 2019 ACM international symposium on wearable computers. 109–117
work page 2019
-
[76]
Hyeokhyen Kwon, Bingyao Wang, Gregory D Abowd, and Thomas Plötz. 2021. Approaching the real-world: Supporting activity recognition training with virtual imu data.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies5, 3 (2021), 1–32. Manuscript submitted to ACM 34 Trovato et al
work page 2021
- [77]
-
[78]
Seohyun Lee, Wenzhi Fang, Dong-Jun Han, Seyyedali Hosseinalipour, and Christopher G Brinton. 2025. TAP: Two-Stage Adaptive Personalization of Multi-task and Multi-Modal Foundation Models in Federated Learning.arXiv preprint arXiv:2509.26524(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Zikang Leng, Amitrajit Bhattacharjee, Hrudhai Rajasekhar, Lizhe Zhang, Elizabeth Bruda, Hyeokhyen Kwon, and Thomas Pl¨"otz. 2024. Imugpt 2.0: Language-based cross modality transfer for sensor-based human activity recognition.Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies8, 3 (2024), 1–32
work page 2024
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.