Recognition: no theorem link
Understanding Latent Diffusability via Fisher Geometry
Pith reviewed 2026-05-13 19:58 UTC · model grok-4.3
The pith
Diffusion models in latent spaces succeed when the encoder preserves Fisher information rate through controlled local geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We quantify latent-space diffusability through the rate of change of the Minimum Mean Squared Error (MMSE) along the diffusion trajectory. Our framework decomposes this MMSE rate into contributions from Fisher Information (FI) and Fisher Information Rate (FIR). We demonstrate that while global isometry ensures FI alignment, FIR is governed by the encoder's local geometric properties. Our analysis explicitly decouples latent geometric distortion into three measurable penalties: dimensional compression, tangential distortion, and curvature injection. We derive theoretical conditions for FIR preservation across spaces, ensuring maintained diffusability.
What carries the argument
The Fisher Information Rate (FIR), which measures the local rate of change in information along diffusion trajectories and is determined by the encoder's geometric properties in the latent space.
If this is right
- If the encoder meets the theoretical conditions for FIR preservation, then latent diffusion models will avoid degradation in performance.
- Computing the three distortion penalties provides a practical way to diagnose and select suitable latent spaces for diffusion training.
- Global isometry alone is insufficient; local properties must also be considered to maintain diffusability.
- The FI and FIR metrics serve as efficient diagnostics for identifying latent diffusion failures across different autoencoding architectures.
Where Pith is reading between the lines
- Optimizing autoencoders to minimize the three specific penalties could lead to better latent spaces for diffusion models without relying on post-hoc fixes.
- Similar geometric analysis might apply to other generative processes that rely on latent representations, such as in variational autoencoders for other tasks.
- Testing the framework on new architectures like transformer-based encoders could reveal whether the conditions generalize beyond the tested models.
Load-bearing premise
The separation of the MMSE rate of change into distinct Fisher information and Fisher information rate contributions is valid for the diffusion trajectories and encoder mappings considered.
What would settle it
Observing a latent space where the encoder violates the derived FIR preservation conditions but the diffusion model still trains without performance loss compared to the data space would falsify the framework.
Figures












read the original abstract
Diffusion models often degrade when trained in latent spaces (e.g., VAEs), yet the formal causes remain poorly understood. We quantify latent-space diffusability through the rate of change of the Minimum Mean Squared Error (MMSE) along the diffusion trajectory. Our framework decomposes this MMSE rate into contributions from Fisher Information (FI) and Fisher Information Rate (FIR). We demonstrate that while global isometry ensures FI alignment, FIR is governed by the encoder's local geometric properties. Our analysis explicitly decouples latent geometric distortion into three measurable penalties: dimensional compression, tangential distortion, and curvature injection. We derive theoretical conditions for FIR preservation across spaces, ensuring maintained diffusability. Experiments across diverse autoencoding architectures validate our framework and establish these efficient FI and FIR metrics as a robust diagnostic suite for identifying and mitigating latent diffusion failure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to quantify latent-space diffusability for diffusion models by tracking the time derivative of the Minimum Mean Squared Error (MMSE) along diffusion trajectories. It decomposes this derivative into separate Fisher Information (FI) and Fisher Information Rate (FIR) contributions, shows that global isometry aligns FI while local encoder geometry controls FIR, decouples latent geometric distortion into the three penalties of dimensional compression, tangential distortion, and curvature injection, derives theoretical conditions for FIR preservation, and validates the resulting FI/FIR metrics as diagnostics via experiments on diverse autoencoding architectures.
Significance. If the decomposition and preservation conditions hold under the requisite regularity assumptions, the framework supplies a concrete geometric diagnostic suite (FI and FIR) for diagnosing and mitigating diffusion degradation in latent spaces. The explicit three-penalty decoupling and the link between encoder local geometry and FIR could inform VAE design choices and provide falsifiable predictions for when latent diffusion succeeds or fails.
major comments (2)
- [Abstract] Abstract (and the central derivation): the decomposition of the MMSE rate of change into separate FI and FIR terms requires interchanging differentiation and integration over the probability path p(x,t) and the encoder map. This interchange holds only under regularity conditions (continuous differentiability of the density in appropriate Sobolev norms, Lipschitz continuity of the encoder, and sufficient smoothness of the diffusion schedule) that are neither stated nor verified. Because this split is load-bearing for the subsequent decoupling into the three geometric penalties and for the FIR-preservation theorems, the claims remain non-rigorous without these conditions.
- [Abstract] Abstract: the manuscript asserts that global isometry ensures FI alignment while FIR is governed by local encoder properties, yet provides no explicit statement of the isometry assumption or the precise local geometric quantities (e.g., the metric tensor or Jacobian factors) used to derive the three penalties. Without these definitions, it is impossible to confirm that the penalties are exhaustive or that the preservation conditions follow.
minor comments (2)
- [Abstract] The abstract contains no equations, proof sketches, or experimental details (e.g., architectures, datasets, or quantitative metrics), which makes immediate assessment of the validation experiments difficult.
- Consider adding a short table or figure that reports the measured FI and FIR values across the tested autoencoders together with the observed diffusion performance, to make the diagnostic utility concrete.
Simulated Author's Rebuttal
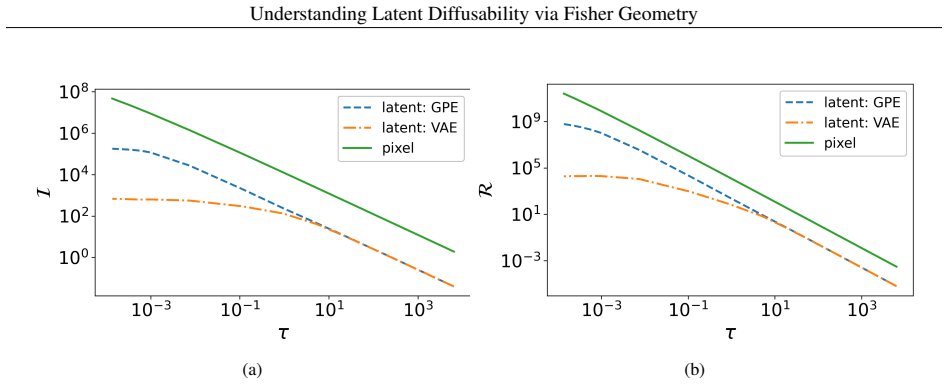
We thank the referee for the constructive comments on rigor and definitional clarity. We address each point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the central derivation): the decomposition of the MMSE rate of change into separate FI and FIR terms requires interchanging differentiation and integration over the probability path p(x,t) and the encoder map. This interchange holds only under regularity conditions (continuous differentiability of the density in appropriate Sobolev norms, Lipschitz continuity of the encoder, and sufficient smoothness of the diffusion schedule) that are neither stated nor verified. Because this split is load-bearing for the subsequent decoupling into the three geometric penalties and for the FIR-preservation theorems, the claims remain non-rigorous without these conditions.
Authors: We acknowledge that the interchange of differentiation and integration requires explicit regularity conditions for rigor. In the revised manuscript we will add a dedicated paragraph in the theoretical framework (new Section 2.3) stating the assumptions: continuous differentiability of p(x,t) in the requisite Sobolev norms, Lipschitz continuity of the encoder map, and C^2 smoothness of the diffusion schedule. We will also include a short verification that these conditions are satisfied by the standard variance-preserving Gaussian diffusion process used in all experiments. This addition directly supports the subsequent derivations without changing any results. revision: yes
-
Referee: [Abstract] Abstract: the manuscript asserts that global isometry ensures FI alignment while FIR is governed by local encoder properties, yet provides no explicit statement of the isometry assumption or the precise local geometric quantities (e.g., the metric tensor or Jacobian factors) used to derive the three penalties. Without these definitions, it is impossible to confirm that the penalties are exhaustive or that the preservation conditions follow.
Authors: We agree that the isometry assumption and the precise local geometric quantities must be stated explicitly. We will revise the abstract and expand Section 3 to define global isometry as the encoder preserving the data manifold metric up to a constant scaling factor, and to specify the local quantities as the Jacobian matrix of the encoder together with the induced Riemannian metric tensor on the latent space. Under this definition the three penalties arise exhaustively from the first-order expansion of the FIR term, and the FIR-preservation theorems follow as direct corollaries. These clarifications will make the claims verifiable. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper defines diffusability via the MMSE rate of change along diffusion trajectories and decomposes it into FI and FIR contributions using information-geometric identities. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or tautological redefinition of the target quantity. The three geometric penalties and FIR-preservation conditions are derived from the decomposition without circular grounding. The framework remains independent of its inputs and is validated experimentally against external autoencoding architectures.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The rate of change of MMSE along the diffusion trajectory admits a decomposition into Fisher Information and Fisher Information Rate terms
invented entities (1)
-
FIR preservation conditions
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amari, S.i.: Information Geometry and Its Applications, Applied Mathematical Sciences, vol. 194. Springer, Tokyo (2016). https://doi.org/10.1007/978-4-431-55978-8
-
[2]
Arvanitidis, G., Hansen, L.K., Hauberg, S.: Latent space oddity: on the curvature of deep generative models. In: International Conference on Learning Representations (2018), https://openreview.net/forum?id= r1Y7pYxRb
work page 2018
-
[3]
Latent forcing: Reordering the diffusion trajectory for pixel-space image generation
Baade, A., Chan, E.R., Sargent, K., Chen, C., Johnson, J., Adeli, E., Fei-Fei, L.: Latent forcing: Reordering the diffusion trajectory for pixel-space image generation. arXiv preprint arXiv:2602.11401 (2026)
-
[4]
In: S´eminaire de Probabilit´es XIX 1983/84
Bakry, D., ´Emery, M.: Diffusions hypercontractives. In: S´eminaire de Probabilit´es XIX 1983/84. pp. 177–206. Springer (1985)
work page 1983
-
[5]
In: International Conference on Machine Learning (2020)
Chen, N., Klushyn, A., Ferroni, F., Bayer, J., Van Der Smagt, P.: Learning flat latent manifolds with V AEs. In: International Conference on Machine Learning (2020)
work page 2020
-
[6]
Advances in Neural Information Processing Systems36, 569–588 (2023)
Cho, S., Lee, J., Kim, D.: Hyperbolic V AE via latent Gaussian distributions. Advances in Neural Information Processing Systems36, 569–588 (2023)
work page 2023
-
[7]
IEEE Transactions on Information Theory31(6), 751–760 (1985)
Costa, M.: A new entropy power inequality. IEEE Transactions on Information Theory31(6), 751–760 (1985)
work page 1985
-
[8]
Journal of the American Statistical Association106(496), 1602– 1614 (2011)
Efron, B.: Tweedie’s formula and selection bias. Journal of the American Statistical Association106(496), 1602– 1614 (2011). https://doi.org/10.1198/jasa.2011.tm11181, https://doi.org/10.1198/jasa.2011.tm11181, pMID: 22505788 11 Understanding Latent Diffusability via Fisher Geometry
-
[9]
IEEE Transactions on Information Theory51(4), 1261–1282 (2005)
Guo, D., Shamai, S., Verdu, S.: Mutual information and minimum mean-square error in Gaussian channels. IEEE Transactions on Information Theory51(4), 1261–1282 (2005). https://doi.org/10.1109/TIT.2005.844072
-
[10]
arXiv preprint arXiv:2602.17270 (2026)
Heek, J., Hoogeboom, E., Mensink, T., Salimans, T.: Unified latents (ul): How to train your latents. arXiv preprint arXiv:2602.17270 (2026)
-
[11]
In: Larochelle, H., Ranzato, M., Had- sell, R., Balcan, M., Lin, H
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Larochelle, H., Ranzato, M., Had- sell, R., Balcan, M., Lin, H. (eds.) Advances in Neural Information Processing Systems. vol. 33, pp. 6840–
-
[12]
Curran Associates, Inc. (2020), https://proceedings.neurips.cc/paper_files/paper/2020/ file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
work page 2020
-
[13]
Communications in Statistics-Simulation and Computation18(3), 1059–1076 (1989)
Hutchinson, M.F.: A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines. Communications in Statistics-Simulation and Computation18(3), 1059–1076 (1989)
work page 1989
-
[14]
Karczewski, R., Heinonen, M., Pouplin, A., Hauberg, S., Garg, V .K.: The spacetime of diffusion models: An information geometry perspective. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=qCsbYJZRA5
work page 2026
-
[15]
Advances in neural information processing systems35, 26565–26577 (2022)
Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion-based generative models. Advances in neural information processing systems35, 26565–26577 (2022)
work page 2022
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019)
work page 2019
-
[17]
In: International Conference on Learning Represen- tations (2014)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: International Conference on Learning Represen- tations (2014)
work page 2014
-
[18]
In: Forty-second International Conference on Machine Learning (2025)
Kouzelis, T., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: EQ-V AE: Equivariance regularized latent space for improved generative image modeling. In: Forty-second International Conference on Machine Learning (2025)
work page 2025
-
[19]
arXiv preprint arXiv:2504.17219 (2025)
Lee, H., Kim, M., Jang, S., Jeong, J., Hwang, S.J.: Enhancing variational autoencoders with smooth robust latent encoding. arXiv preprint arXiv:2504.17219 (2025)
-
[20]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lee, J., Shin, J., Choi, H., Lee, J.: Latent diffusion models with masked autoencoders. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17422–17431 (2025)
work page 2025
- [21]
-
[22]
Lobashev, A., Guskov, D., Larchenko, M., Tamm, M.: Hessian geometry of latent space in generative models. In: Forty-second International Conference on Machine Learning (2025), https://openreview.net/forum?id= H8JTsbG4KW
work page 2025
-
[23]
Advances in Neural Information Processing Systems36, 38370–38403 (2023)
S´aez de Oc´ariz Borde, H., Arroyo, A., Morales, I., Posner, I., Dong, X.: Neural latent geometry search: Product manifold inference via gromov-hausdorff-informed bayesian optimization. Advances in Neural Information Processing Systems36, 38370–38403 (2023)
work page 2023
-
[24]
Palma, A., Rybakov, S., Hetzel, L., G¨unnemann, S., Theis, F.J.: Enforcing latent euclidean geometry in single- cell V AEs for manifold interpolation. In: Forty-second International Conference on Machine Learning (2025), https://openreview.net/forum?id=DoDXFkF10S
work page 2025
-
[25]
In: Proceedings of the IEEE/CVF international conference on computer vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
work page 2023
-
[26]
In: International conference on machine learning
Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Bengio, Y ., Courville, A.: On the spectral bias of neural networks. In: International conference on machine learning. pp. 5301–5310. PMLR (2019)
work page 2019
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10684–10695 (June 2022)
work page 2022
-
[28]
arXiv preprint arXiv:2510.15301 (2025)
Shi, M., Wang, H., Zheng, W., Yuan, Z., Wu, X., Wang, X., Wan, P., Zhou, J., Lu, J.: Latent diffusion model without variational autoencoder. arXiv preprint arXiv:2510.15301 (2025)
-
[29]
Skorokhodov, I., Girish, S., Hu, B., Menapace, W., Li, Y ., Abdal, R., Tulyakov, S., Siarohin, A.: Improving the diffusability of autoencoders. In: Forty-second International Conference on Machine Learning (2025), https://openreview.net/forum?id=2hEDcA7xy4
work page 2025
-
[30]
Song, Y ., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations (2021), https://openreview.net/forum?id=PxTIG12RRHS 12 Understanding Latent Diffusability via Fisher Geometry
work page 2021
-
[31]
Advances in neural information processing systems33, 19667–19679 (2020)
Vahdat, A., Kautz, J.: NV AE: A deep hierarchical variational autoencoder. Advances in neural information processing systems33, 19667–19679 (2020)
work page 2020
-
[32]
Villani, C.: Optimal transport: old and new, vol. 338. Springer Science & Business Media (2009)
work page 2009
-
[33]
arXiv preprint arXiv:1901.06523 , year=
Xu, Z.Q.J., Zhang, Y ., Luo, T., Xiao, Y ., Ma, Z.: Frequency principle: Fourier analysis sheds light on deep neural networks. arXiv preprint arXiv:1901.06523 (2019)
-
[34]
Yang, J., Li, T., Fan, L., Tian, Y ., Wang, Y .: Latent denoising makes good visual tokenizers. In: The Four- teenth International Conference on Learning Representations (2026), https://openreview.net/forum?id= 1jBsi98fVe
work page 2026
- [35]
-
[36]
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders. In: The Four- teenth International Conference on Learning Representations (2026), https://openreview.net/forum?id= 0u1LigJaab 13 Understanding Latent Diffusability via Fisher Geometry Supplementary Material The appendices are organized as follows: Appendix A rev...
work page 2026
-
[37]
For ε, the remainder R(x) =∥E(x)−E(0)− ∇E(0)x∥ 2 is analyzed in L1(M, µ)
Inversion givesδ∝ϵ 1/(4(m+5)) GP E . For ε, the remainder R(x) =∥E(x)−E(0)− ∇E(0)x∥ 2 is analyzed in L1(M, µ). Taylor’s theorem provides R(x)≤ L2 E 4 ∥x∥4. Integrating overMsplit intoA 0 (good slice) andB 0 (bad slice): Z B0 R(x)dµ(x)≤ L2 ED4 M 4 µ(B0)≤ L2 ED4 M 4 ϵ1/4 GP E. For A0, we use the spatial expansion R(x)≤2(e ϵ1/4 GP E −1) + 2(e ϵ1/4 GP E + 1 +...
-
[38]
Diffusion models are then trained separately on the GPE and V AE latent representations
These vectors are reshaped into16×16 tensors using a serpentine ordering and normalized using Gaussian statistics prior to diffusion training. Diffusion models are then trained separately on the GPE and V AE latent representations. 6https://github.com/wonjunee/GPE_codes 20 Understanding Latent Diffusability via Fisher Geometry The diffusion model architec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.