Recognition: 2 theorem links
· Lean TheoremDRAFT: Task Decoupled Latent Reasoning for Agent Safety
Pith reviewed 2026-05-16 02:18 UTC · model grok-4.3
The pith
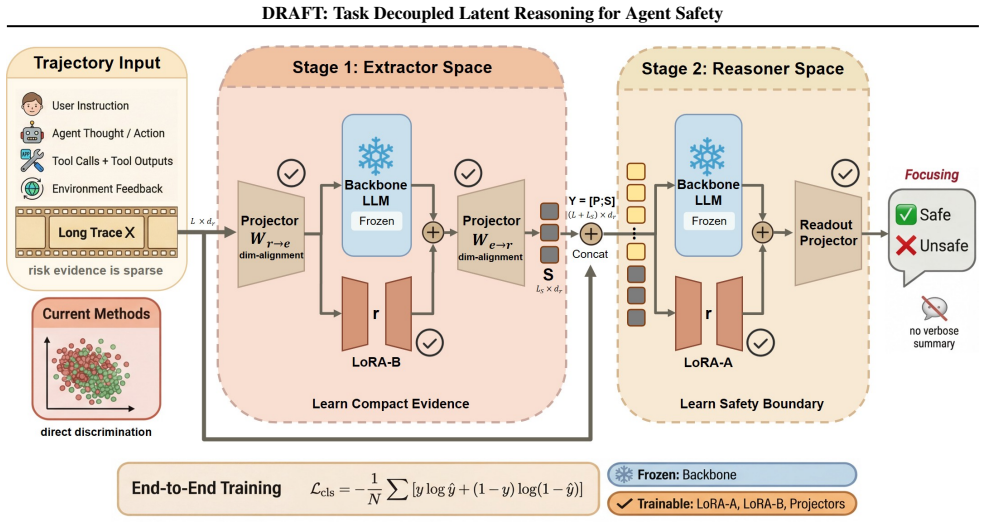
DRAFT decouples safety judgment into an Extractor that compresses agent trajectories into a compact latent draft and a Reasoner that attends to both draft and original sequence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DRAFT establishes that safety judgment over long noisy agent trajectories becomes more accurate when evidence is first aggregated into a trainable continuous latent draft and then jointly reasoned over with the original sequence rather than through lossy explicit summarization.
What carries the argument
The two-stage DRAFT architecture: an Extractor that distills each trajectory into a compact continuous latent draft followed by a Reasoner that jointly attends to the draft and the original trajectory to predict safety.
If this is right
- Safety classifiers can be trained end-to-end on full trajectories without intermediate human-readable summaries.
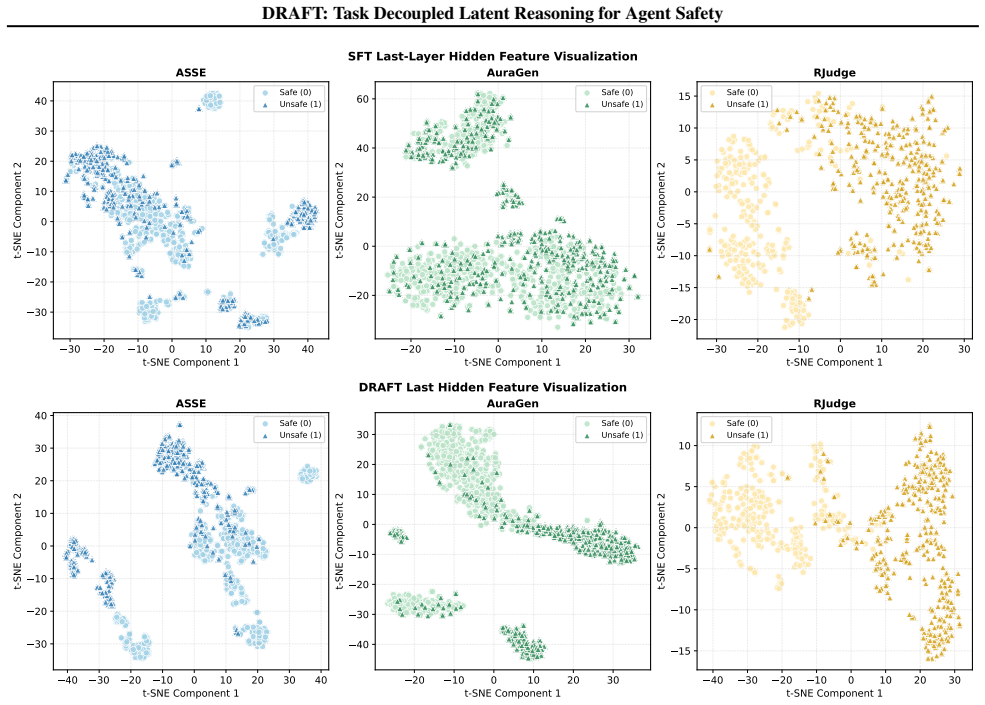
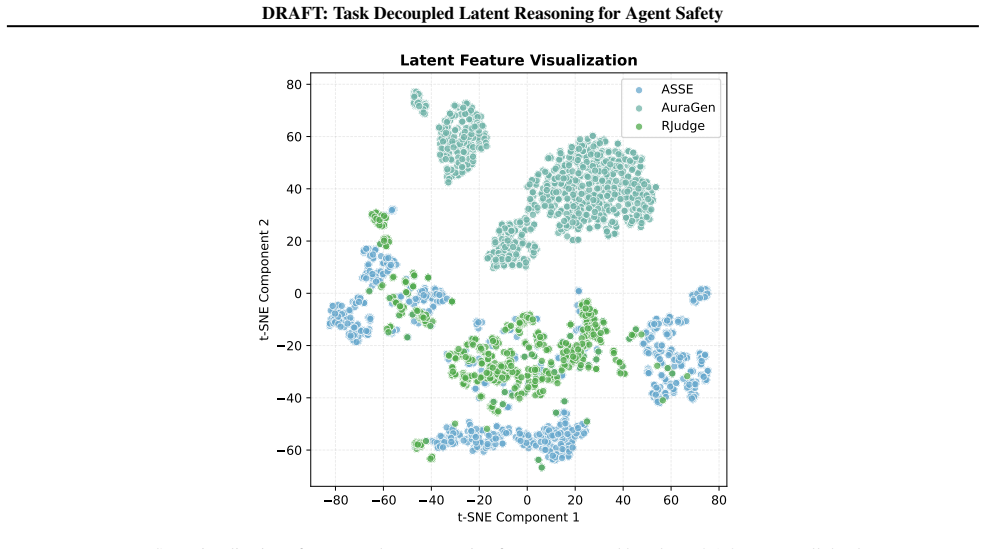
- Representations from the joint Extractor-Reasoner become more separable than those from single-stage baselines.
- Ablations show that neither module alone reaches the reported accuracy on sparse-evidence benchmarks.
- The approach scales directly to long-context safety tasks such as ASSEBench and R-Judge.
Where Pith is reading between the lines
- The same latent-draft decoupling could be tested on other rare-event detection tasks in long sequences beyond safety.
- Integration with existing agent planners might enable real-time safety filtering during execution.
- Further experiments could check whether the pattern improves non-safety metrics such as task completion under uncertainty.
Load-bearing premise
Evidence aggregation performed in continuous latent space avoids lossy explicit summarize-then-judge pipelines and enables effective end-to-end training for sparse risk evidence in long trajectories.
What would settle it
Train an identical model that first writes an explicit natural-language summary of each trajectory and then classifies safety from that summary alone; if its accuracy and representation separability match or exceed DRAFT on the same benchmarks, the advantage of latent-space aggregation is refuted.
Figures





read the original abstract
The advent of tool-using LLM agents shifts safety monitoring from output moderation to auditing long, noisy interaction trajectories, where risk-critical evidence is sparse-making standard binary supervision poorly suited for credit assignment. To address this, we propose DRAFT (Task Decoupled Latent Reasoning for Agent Safety), a latent reasoning framework that decouples safety judgment into two trainable stages: an Extractor that distills the full trajectory into a compact continuous latent draft, and a Reasoner that jointly attends to the draft and the original trajectory to predict safety. DRAFT avoids lossy explicit summarize-then-judge pipelines by performing evidence aggregation in latent space, enabling end-to-end differentiable training.Across benchmarks including ASSEBench and R-Judge, DRAFT consistently outperforms strong baselines, improving accuracy from 63.27% (LoRA) to 91.18% averaged over benchmarks, and learns more separable representations. Ablations demonstrate a clear synergy between the Extractor and the Reasoner.Overall, DRAFT suggests that continuous latent reasoning prior to readout is a practical path to robust agent safety under long-context supervision with sparse evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DRAFT, a task-decoupled latent reasoning framework for agent safety monitoring. It decouples safety judgment into an Extractor that distills long noisy trajectories into a compact continuous latent draft and a Reasoner that jointly attends to the draft and original trajectory to predict safety. The approach claims to enable end-to-end differentiable training by performing evidence aggregation in latent space rather than via explicit summarize-then-judge pipelines. Across benchmarks including ASSEBench and R-Judge, DRAFT is reported to outperform strong baselines such as LoRA, raising average accuracy from 63.27% to 91.18%, while producing more separable representations; ablations are said to confirm synergy between the two stages.
Significance. If the empirical claims hold under full experimental scrutiny, the work would address a practically important credit-assignment problem in sparse-risk, long-context agent trajectories. Performing aggregation in continuous latent space could reduce information loss relative to discrete summarization pipelines and support more robust end-to-end training for safety classifiers.
major comments (2)
- [Abstract] Abstract: The central performance claim (accuracy rising from 63.27% for LoRA to 91.18% averaged over benchmarks) is presented without any description of experimental protocol, baseline implementations, number of runs, statistical tests, or error analysis. This absence prevents verification of the reported gains and of the assertion that the latent draft retains sparse risk evidence effectively.
- [Abstract] Abstract: The claim of 'end-to-end differentiable training' is load-bearing for the method's solution to credit assignment, yet the text supplies no information on the training objective or auxiliary supervision (reconstruction, contrastive, or localization) provided to the Extractor. If the Extractor receives gradients only from the final binary safety loss, the credit-assignment problem the framework is designed to solve may remain unresolved.
minor comments (1)
- [Abstract] Abstract: The benchmarks ASSEBench and R-Judge are referenced without citations or brief characterizations of their trajectory lengths, risk sparsity, or label distributions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the presentation of our experimental claims and training procedure. We will revise the manuscript to incorporate the requested details while preserving the core contributions of DRAFT.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim (accuracy rising from 63.27% for LoRA to 91.18% averaged over benchmarks) is presented without any description of experimental protocol, baseline implementations, number of runs, statistical tests, or error analysis. This absence prevents verification of the reported gains and of the assertion that the latent draft retains sparse risk evidence effectively.
Authors: We agree that the abstract should be expanded for self-containment. In the revision we will add a concise description of the protocol: evaluation on ASSEBench and R-Judge, LoRA baseline trained with identical data and hyperparameters, results averaged over 5 random seeds with standard deviation, and paired t-test significance (p < 0.01). A brief error analysis paragraph will also be added to the results section showing that the latent draft preserves sparse risk tokens more reliably than explicit summarization baselines. revision: yes
-
Referee: [Abstract] Abstract: The claim of 'end-to-end differentiable training' is load-bearing for the method's solution to credit assignment, yet the text supplies no information on the training objective or auxiliary supervision (reconstruction, contrastive, or localization) provided to the Extractor. If the Extractor receives gradients only from the final binary safety loss, the credit-assignment problem the framework is designed to solve may remain unresolved.
Authors: We acknowledge the current draft omits explicit description of the Extractor objective. The revision will clarify that the Extractor is trained jointly with the Reasoner under the final binary cross-entropy safety loss plus an auxiliary reconstruction loss on the latent draft (Equation 3). This auxiliary term supplies direct gradient signal to the Extractor, ensuring it retains sparse risk evidence rather than relying solely on the downstream loss. The entire pipeline remains end-to-end differentiable because the draft is a continuous latent vector. revision: yes
Circularity Check
No circularity: empirical claims independent of derivations
full rationale
The manuscript describes DRAFT as a two-stage framework (Extractor producing continuous latent draft, Reasoner attending to draft plus trajectory) trained end-to-end on safety prediction. No equations, derivations, or parameter-fitting steps are shown that reduce any claimed prediction to its own inputs by construction. No self-citations appear in the provided text, and the performance numbers (e.g., accuracy lift from 63.27% to 91.18%) are benchmark comparisons rather than fitted quantities renamed as predictions. The end-to-end differentiability assertion is a design claim, not a mathematical reduction. This is a standard empirical ML contribution whose central results do not collapse to self-definition or self-citation chains.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
S=ϕ_ΔB(X), S∈R^{Ls×d} ... Y=[P;S] ... p(y|X)≈p(y|S,X)≈p(y|S)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat embedding and orbit separation echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
excess risk decomposes as Extraction Error + Readout Error
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alemi, A. A., Fischer, I., Dillon, J. V ., and Murphy, K. Deep variational information bottleneck.arXiv preprint arXiv:1612.00410,
-
[2]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[3]
Towards tool use alignment of large language models
Chen, Z.-Y ., Shen, S., Shen, G., Zhi, G., Chen, X., and Lin, Y . Towards tool use alignment of large language models. InProceedings of the 2024 Conference on Em- pirical Methods in Natural Language Processing, pp. 1382–1400,
work page 2024
-
[4]
URL https: //arxiv.org/abs/2407.21783. Ghosh, S., Varshney, P., Galinkin, E., and Parisien, C. Aegis: Online adaptive ai content safety moderation with ensem- ble of llm experts.arXiv preprint arXiv:2404.05993,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Large Language Models to Reason in a Continuous Latent Space
Hao, S., Sukhbaatar, S., Su, D., Li, X., Hu, Z., Weston, J., and Tian, Y . Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection
Hartvigsen, T., Gabriel, S., Palangi, H., Sap, M., Ray, D., and Kamar, E. Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. arXiv preprint arXiv:2203.09509,
-
[7]
Huang, Y ., Hua, H., Zhou, Y ., Jing, P., Nagireddy, M., Padhi, I., Dolcetti, G., Xu, Z., Chaudhury, S., Rawat, A., et al. Building a foundational guardrail for general agentic sys- tems via synthetic data.arXiv preprint arXiv:2510.09781,
-
[8]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
URL https: //arxiv.org/abs/2312.06674. Lian, L., Wang, S., Juefei-Xu, F., Fu, T.-J., Li, X., Yala, A., Darrell, T., Suhr, A., Tian, Y ., and Lin, X. V . Thread- weaver: Adaptive threading for efficient parallel reason- ing in language models.arXiv preprint arXiv:2512.07843,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Luo, H., Dai, S., Ni, C., Li, X., Zhang, G., Wang, K., Liu, T., and Salam, H. Agentauditor: Human-level safety and security evaluation for llm agents.arXiv preprint arXiv:2506.00641,
-
[10]
WebGPT: Browser-assisted question-answering with human feedback
Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V ., Saunders, W., et al. Webgpt: Browser-assisted question-answering with hu- man feedback.arXiv preprint arXiv:2112.09332,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Ignore Previous Prompt: Attack Techniques For Language Models
Perez, F. and Ribeiro, I. Ignore previous prompt: At- tack techniques for language models.arXiv preprint arXiv:2211.09527,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Ruan, Y ., Dong, H., Wang, A., Pitis, S., Zhou, Y ., Ba, J., Dubois, Y ., Maddison, C. J., and Hashimoto, T. Identify- ing the risks of lm agents with an lm-emulated sandbox. arXiv preprint arXiv:2309.15817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Evil geniuses: Delving into the safety of llm-based agents
9 DRAFT: Task Decoupled Latent Reasoning for Agent Safety Tian, Y ., Yang, X., Zhang, J., Dong, Y ., and Su, H. Evil geniuses: Delving into the safety of llm-based agents. arXiv preprint arXiv:2311.11855,
-
[14]
The information bottleneck method
Tishby, N., Pereira, F. C., and Bialek, W. The informa- tion bottleneck method.arXiv preprint physics/0004057,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., and Anandkumar, A. V oyager: An open- ended embodied agent with large language models.arXiv preprint arXiv: Arxiv-2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. Self-consistency im- proves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Wang, X., Li, B., Song, Y ., Xu, F. F., Tang, X., Zhuge, M., Pan, J., Song, Y ., Li, B., Singh, J., et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Toolsafety: A comprehensive dataset for enhancing safety in llm-based agent tool invocations
Xie, Y ., Yuan, Y ., Wang, W., Mo, F., Guo, J., and He, P. Toolsafety: A comprehensive dataset for enhancing safety in llm-based agent tool invocations. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 14146–14167,
work page 2025
-
[19]
URL https: //arxiv.org/abs/2505.09388. Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K. R., and Cao, Y . React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
R-judge: Benchmark- ing safety risk awareness for llm agents.arXiv preprint arXiv:2401.10019,
Yuan, T., He, Z., Dong, L., Wang, Y ., Zhao, R., Xia, T., Xu, L., Zhou, B., Li, F., Zhang, Z., et al. R-judge: Benchmark- ing safety risk awareness for llm agents.arXiv preprint arXiv:2401.10019,
-
[21]
Zelikman, E., Harik, G., Shao, Y ., Jayasiri, V ., Haber, N., and Goodman, N. D. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629,
work page internal anchor Pith review arXiv
-
[22]
URLhttps:// arxiv.org/abs/2407.21772
URLhttps://arxiv.org/abs/2407.21772. Zhan, Q., Fang, R., Panchal, H. S., and Kang, D. Adaptive attacks break defenses against indirect prompt injection attacks on llm agents.arXiv preprint arXiv:2503.00061,
-
[23]
Rest-mcts*: Llm self-training via process reward guided tree search
Zhang, D., Zhoubian, S., Hu, Z., Yue, Y ., Dong, Y ., and Tang, J. Rest-mcts*: Llm self-training via process reward guided tree search. InAdvances in Neural Information Processing Systems, pp. 64735–64772, 2024a. Zhang, D., Zhoubian, S., Cai, M., Li, F., Yang, L., Wang, W., Dong, T., Hu, Z., Tang, J., and Yue, Y . Datascibench: An llm agent benchmark for ...
-
[24]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
10 DRAFT: Task Decoupled Latent Reasoning for Agent Safety Zhang, H., Huang, J., Mei, K., Yao, Y ., Wang, Z., Zhan, C., Wang, H., and Zhang, Y . Agent security bench (asb): For- malizing and benchmarking attacks and defenses in llm- based agents.arXiv preprint arXiv:2410.02644, 2024b. Zhang, Z., Cui, S., Lu, Y ., Zhou, J., Yang, J., Wang, H., and Huang, M...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Zhu, H., Hao, S., Hu, Z., Jiao, J., Russell, S., and Tian, Y . Reasoning by superposition: A theoretical perspec- tive on chain of continuous thought.arXiv preprint arXiv:2505.12514,
-
[26]
IB intuition.Let S=ϕ ∆B(X) be an intermediate latent variable used for prediction
through an Information Bottleneck (IB) perspective (Tishby et al., 2000; Alemi et al., 2016). IB intuition.Let S=ϕ ∆B(X) be an intermediate latent variable used for prediction. A compact draft should (i) preserve information about the labelywhile (ii) discarding irrelevant details inX. This can be expressed by the IB objective: max ϕ I(S;y)−β I(S;X),(31) ...
work page 2000
-
[27]
is a curated benchmark for evaluatingrisk awarenessin tool-using agents by judging whether an interaction record is safe or unsafe. It comprises569annotated multi-turn interaction cases across 5application categories and27scenarios, with10risk types. The dataset is approximately balanced (about half unsafe) and has moderate trajectory length (on average ∼...
work page 2024
-
[28]
as a benchmark for evaluating whether LLM-based evaluators can detectboth safety risks and security threatsin agent interaction trajectories. It consists of2,293 meticulously annotated interaction records, covering15risk types across29application scenarios. A distinctive feature is its ambiguity-aware labeling, includingStrictandLenientjudgment standards ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.