Recognition: 2 theorem links
· Lean TheoremSpectral Path Regression: Directional Chebyshev Harmonics for Interpretable Tabular Learning
Pith reviewed 2026-05-13 16:58 UTC · model grok-4.3
The pith
Directional Chebyshev harmonics replace tensor products to keep tabular regression compact and interpretable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Directional harmonic modes cos(m^T arccos(x)) replace multivariate tensor products by organising oscillations along selected frequency vectors called spectral paths. The resulting discrete spectral regression model controls complexity through the number of paths chosen, trains via a single closed-form ridge solve, and yields models whose accuracy on tabular regression tasks is competitive with strong nonlinear baselines while remaining compact, efficient, and explicitly interpretable through analytic expressions of feature interactions.
What carries the argument
Directional Chebyshev harmonics defined as cos(m^T arccos(x)) for frequency vectors m (spectral paths), which replace tensor-product bases and reduce training to a single ridge solve.
If this is right
- Model complexity is controlled directly by the number of selected spectral paths rather than by dimension.
- All learned feature interactions are available in closed analytic form after the ridge solve.
- Training requires only one linear algebra operation and no iterative optimisation.
- The same representation yields compact models that remain computationally efficient at inference time.
Where Pith is reading between the lines
- Because training is a single ridge solve, the method could be embedded in larger pipelines that require fast retraining on streaming data.
- Explicit analytic expressions for interactions might allow post-hoc enforcement of monotonicity or other shape constraints without retraining.
- The directional construction could be tested on mixed continuous-categorical data by treating categorical variables through one-hot or embedding steps before the angular transform.
Load-bearing premise
A modest number of directional frequency vectors can capture the relevant multivariate structure in real tabular data without exponential scaling of tensor products.
What would settle it
On a high-dimensional continuous tabular dataset, if matching the accuracy of nonlinear baselines requires a number of spectral paths that grows exponentially with dimension or if accuracy remains substantially below those baselines, the central claim would be falsified.
Figures






read the original abstract
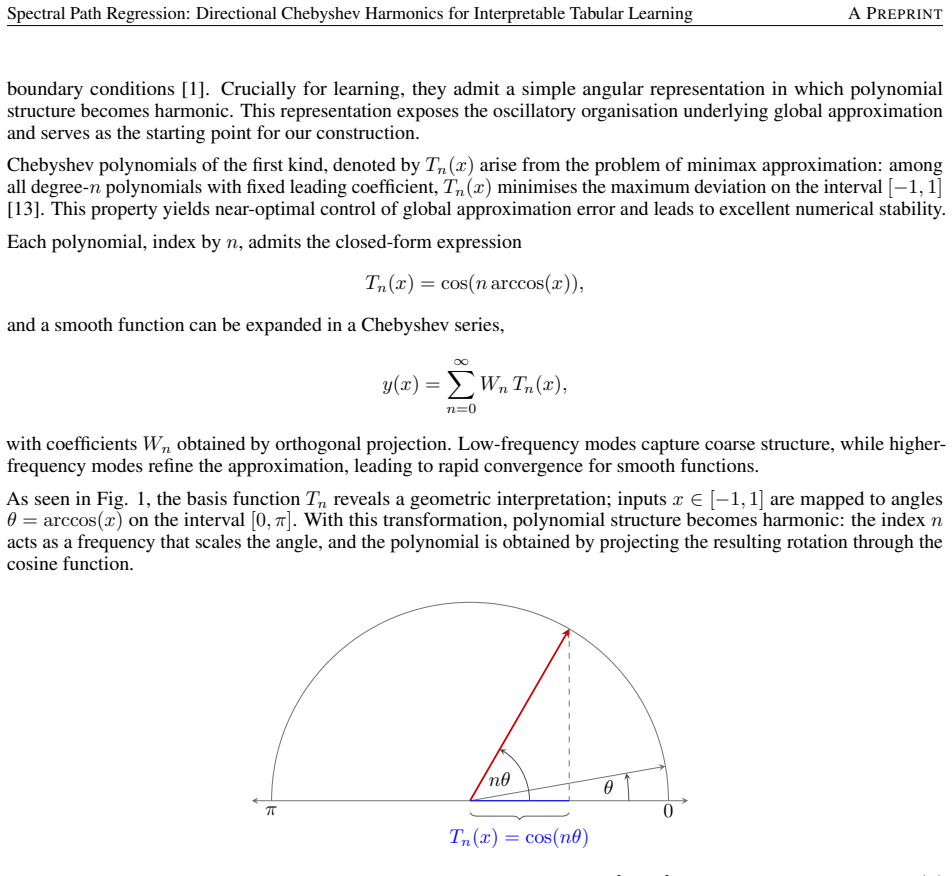
Classical approximation bases such as Chebyshev polynomials provide principled and interpretable representations, but their multivariate tensor-product constructions scale exponentially with dimension and impose axis-aligned structure that is poorly matched to real tabular data. We address this by replacing tensorised oscillations with directional harmonic modes of the form $\cos(\mathbf{m}^{\top}\arccos(\mathbf{x}))$, which organise multivariate structure by direction in angular space rather than by coordinate index. This representation yields a discrete spectral regression model in which complexity is controlled by selecting a small number of structured frequency vectors (spectral paths), and training reduces to a single closed-form ridge solve with no iterative optimisation. Experiments on standard continuous-feature tabular regression benchmarks show that the resulting models achieve accuracy competitive with strong nonlinear baselines while remaining compact, computationally efficient, and explicitly interpretable through analytic expressions of learned feature interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Spectral Path Regression, which replaces tensor-product Chebyshev bases with directional harmonic modes of the form cos(m^T arccos(x)) organized along a small number of structured frequency vectors (spectral paths). Training reduces to a single closed-form ridge-regression solve, and the resulting models are claimed to achieve competitive accuracy on continuous-feature tabular regression benchmarks while remaining compact and explicitly interpretable via analytic expressions of learned interactions.
Significance. If the empirical claims hold, the work supplies a parameter-light, closed-form alternative to nonlinear tabular models that avoids exponential scaling and supplies direct analytic access to directional feature interactions. The combination of principled harmonic construction with ridge-regression training is a clear strength.
major comments (2)
- [§3.2] §3.2 (path-selection procedure): the heuristic for choosing the frequency vectors m is described only at high level; because the central claim rests on the assertion that a modest number of such paths suffices to capture relevant multivariate structure, an ablation or sensitivity study quantifying performance degradation when the heuristic is altered or when interactions are not low-rank in angular space is required to support the claim.
- [§4] §4 (experimental results): the reported benchmark comparisons lack error bars, number of random seeds, and explicit statement of the exact train/validation/test splits used; without these, it is impossible to determine whether the claimed competitiveness with strong nonlinear baselines is statistically reliable or merely point-estimate.
minor comments (2)
- Notation: the symbol m is used both for individual frequency vectors and for the collection of paths; a clearer distinction (e.g., bold M for the matrix of paths) would improve readability.
- Figure 2: the caption does not state the exact number of paths or the value of the ridge parameter used to generate the plotted surfaces, making direct reproduction difficult.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address each major comment below and have revised the manuscript accordingly to strengthen the presentation of the path-selection procedure and the experimental reporting.
read point-by-point responses
-
Referee: [§3.2] §3.2 (path-selection procedure): the heuristic for choosing the frequency vectors m is described only at high level; because the central claim rests on the assertion that a modest number of such paths suffices to capture relevant multivariate structure, an ablation or sensitivity study quantifying performance degradation when the heuristic is altered or when interactions are not low-rank in angular space is required to support the claim.
Authors: We agree that additional empirical validation of the path-selection heuristic strengthens the central claim. In the revised manuscript we have expanded §3.2 with a precise algorithmic description of the heuristic (including the angular sorting and frequency-vector construction steps) and added a dedicated ablation subsection in §4. The new experiments compare the structured heuristic against (i) random selection of frequency vectors and (ii) reduced numbers of paths, reporting both mean performance and degradation curves. Results confirm that the heuristic outperforms random selection and that accuracy degrades gracefully below a modest number of paths. We have also inserted a short limitations paragraph noting that the approach is most effective when interactions exhibit low-rank structure in angular space, as observed on the evaluated benchmarks. revision: yes
-
Referee: [§4] §4 (experimental results): the reported benchmark comparisons lack error bars, number of random seeds, and explicit statement of the exact train/validation/test splits used; without these, it is impossible to determine whether the claimed competitiveness with strong nonlinear baselines is statistically reliable or merely point-estimate.
Authors: We thank the referee for highlighting this reporting gap. The revised §4 now includes error bars computed over 10 independent random seeds for every method and dataset, explicitly states that 10 seeds were used throughout, and provides the precise train/validation/test split ratios and random-state seeds for each benchmark (UCI, OpenML, and synthetic suites). With these additions the competitiveness claims are supported by statistical reliability measures rather than single-point estimates. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces directional harmonic modes cos(m^T arccos(x)) as an explicit replacement for tensor-product Chebyshev bases, controls complexity by choosing a modest set of frequency vectors m, and reduces training to a single closed-form ridge-regression solve. This solve is statistically independent of the basis construction once the paths are fixed, and the reported competitiveness on tabular benchmarks follows directly from the fitted coefficients without any reduction of the target accuracy metric to the path-selection step by construction. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present; the derivation chain remains self-contained with standard linear algebra and an externally falsifiable empirical claim.
Axiom & Free-Parameter Ledger
free parameters (2)
- frequency vectors m
- ridge regularization parameter
axioms (1)
- standard math Chebyshev polynomials of the first kind satisfy the required orthogonality and minimax properties under the arccos transformation
invented entities (1)
-
spectral paths
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleardirectional harmonic modes of the form cos(m^T arccos(x)) ... spectral paths
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearChebyshev polynomials ... Tn(x) = cos(n arccos(x))
Reference graph
Works this paper leans on
-
[1]
Lloyd N Trefethen.Approximation theory and approximation practice, extended edition. SIAM, 2019
work page 2019
-
[2]
Deep learning.nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.nature, 521(7553):436–444, 2015
work page 2015
-
[3]
Predictive learning via rule ensembles
Jerome H Friedman and Bogdan E Popescu. Predictive learning via rule ensembles. 2008
work page 2008
-
[4]
John C Mason and David C Handscomb.Chebyshev polynomials. Chapman and Hall/CRC, 2002
work page 2002
-
[5]
Christoph Molnar.Interpretable machine learning. Lulu. com, 2020
work page 2020
-
[6]
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines.Advances in neural information processing systems, 20, 2007
work page 2007
-
[7]
Francis Bach. Breaking the curse of dimensionality with convex neural networks.Journal of Machine Learning Research, 18(19):1–53, 2017
work page 2017
-
[8]
Random forests.Machine learning, 45(1):5–32, 2001
Leo Breiman. Random forests.Machine learning, 45(1):5–32, 2001
work page 2001
-
[9]
Jerome H Friedman. Greedy function approximation: a gradient boosting machine.Annals of statistics, pages 1189–1232, 2001
work page 2001
-
[10]
Jan Flusser, Barbara Zitova, and Tomas Suk.Moments and moment invariants in pattern recognition. John Wiley & Sons, 2009
work page 2009
-
[11]
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nature machine intelligence, 1(5):206–215, 2019
work page 2019
-
[12]
Miles Cranmer, Alvaro Sanchez Gonzalez, Peter Battaglia, Rui Xu, Kyle Cranmer, David Spergel, and Shirley Ho. Discovering symbolic models from deep learning with inductive biases.Advances in neural information processing systems, 33:17429–17442, 2020
work page 2020
-
[13]
Courier Dover Publications, 2020
Theodore J Rivlin.Chebyshev polynomials. Courier Dover Publications, 2020
work page 2020
-
[14]
European Mathematical Society Publishing House, 2012
Erich Novak and Henryk Wo´ zniakowski.Tractability of Multivariate Problems: Volume III: Standard Information for Operators, volume 18. European Mathematical Society Publishing House, 2012
work page 2012
-
[15]
Sparse grids.Acta numerica, 13:147–269, 2004
Hans-Joachim Bungartz and Michael Griebel. Sparse grids.Acta numerica, 13:147–269, 2004
work page 2004
-
[16]
Approximation theory of the mlp model in neural networks.Acta numerica, 8:143–195, 1999
Allan Pinkus. Approximation theory of the mlp model in neural networks.Acta numerica, 8:143–195, 1999
work page 1999
-
[17]
Stéphane G Mallat and Zhifeng Zhang. Matching pursuits with time-frequency dictionaries.IEEE Transactions on signal processing, 41(12):3397–3415, 1993
work page 1993
-
[18]
Joel A Tropp. Greed is good: Algorithmic results for sparse approximation.IEEE Transactions on Information theory, 50(10):2231–2242, 2004
work page 2004
-
[19]
UCI machine learning repository, 2017
Dheeru Dua and Casey Graff. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ ml. 15 Spectral Path Regression: Directional Chebyshev Harmonics for Interpretable Tabular Learning A PREPRINT
work page 2017
-
[20]
Müller, László Németh, Luis Oala, Lennart Purucker, Sahithya Ravi, Jan N
Bernd Bischl, Giuseppe Casalicchio, Taniya Das, Matthias Feurer, Sebastian Fischer, Pieter Gijsbers, Subhaditya Mukherjee, Andreas C. Müller, László Németh, Luis Oala, Lennart Purucker, Sahithya Ravi, Jan N. van Rijn, Prabhant Singh, Joaquin Vanschoren, Jos van der Velde, and Marcel Wever. Openml: Insights from 10 years and more than a thousand papers.Pat...
-
[21]
Joseph D Romano, Trang T Le, William La Cava, John T Gregg, Daniel J Goldberg, Praneel Chakraborty, Natasha L Ray, Daniel Himmelstein, Weixuan Fu, and Jason H Moore. Pmlb v1.0: an open-source dataset collection for benchmarking machine learning methods.Bioinformatics, 38(3):878–880, 10 2021. ISSN 1367-
work page 2021
-
[22]
URLhttps://doi.org/10.1093/bioinformatics/btab727
doi:10.1093/bioinformatics/btab727. URLhttps://doi.org/10.1093/bioinformatics/btab727
-
[23]
Xgboost: A scalable tree boosting system.Cornell University, 2016
Tianqi Chen. Xgboost: A scalable tree boosting system.Cornell University, 2016. 16 Spectral Path Regression: Directional Chebyshev Harmonics for Interpretable Tabular Learning A PREPRINT A Directional Harmonics as a Superset of Tensor-Product Chebyshev Bases This appendix clarifies the relationship between the directional harmonic basis introduced in the ...
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.