Recognition: 2 theorem links
· Lean TheoremSemantic Communication with an LLM-enabled Knowledge Base
Pith reviewed 2026-05-10 19:33 UTC · model grok-4.3
The pith
An LLM-enabled knowledge base with hallucination filtering and importance-weighted fusion improves semantic communication performance on cross-modality tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
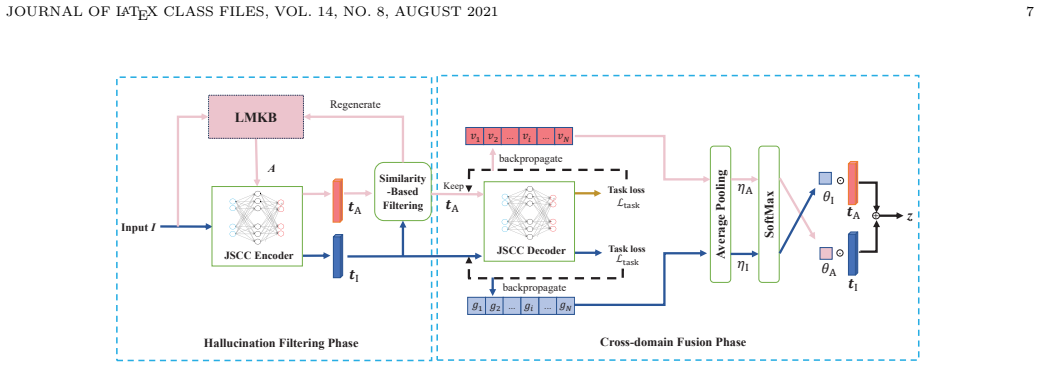
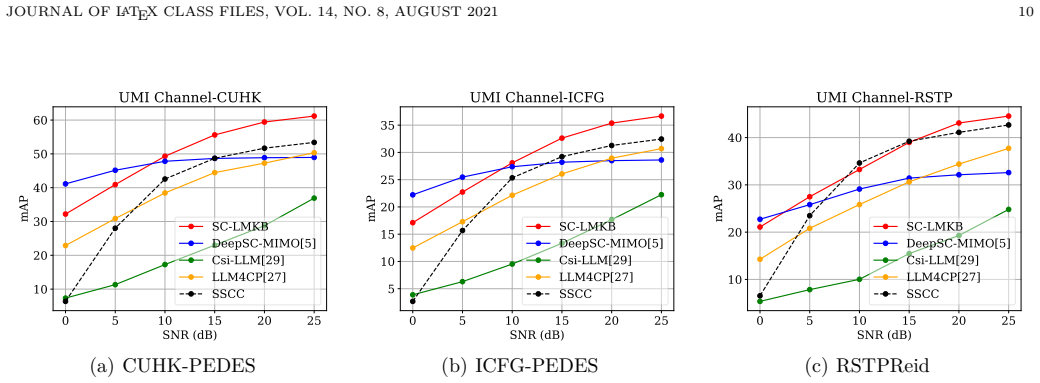
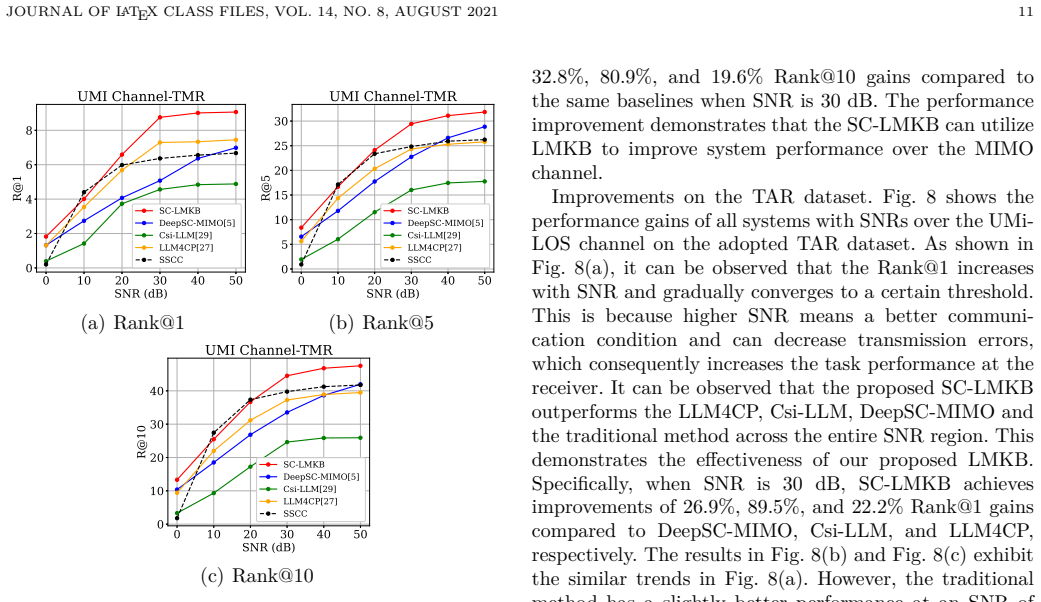
The central claim is that large language models can be used to generate source data through prompt engineering and channel data through cross-attention alignment, but the resulting hallucinations must be controlled by a cross-domain fusion codec consisting of a semantic-similarity filtering stage followed by an importance-weighted fusion stage; a combined cross-entropy and reconstruction loss further stabilizes channel generation, and the overall SC-LMKB architecture then delivers substantial gains on cross-modality retrieval tasks.
What carries the argument
The cross-domain fusion codec (CDFC), which applies semantic-similarity filtering to remove irrelevant LLM outputs and then performs importance-weighted fusion of retained generated data with the original source data.
Load-bearing premise
Semantic similarity filtering can reliably separate hallucinations from useful generated content without discarding beneficial data or introducing new noise that harms task performance.
What would settle it
Re-running the three cross-modality retrieval experiments while disabling the semantic-similarity filtering step inside the CDFC and checking whether the reported performance gains over both conventional SC and other LLM-enabled baselines disappear.
Figures








read the original abstract
Semantic communication (SC) can achieve superior coding and transmission performance based on the knowledge contained in the semantic knowledge base (KB). However, conventional KBs consist of source KBs and channel KBs, which are often costly to obtain data and limited in data scale. Fortunately, large language models (LLMs) have recently emerged with extensive knowledge and generative capabilities. Therefore, this paper proposes an SC system with LLM-enabled knowledge base (SC-LMKB), which utilizes the generation ability of LLMs to significantly enrich the KB of SC systems. In particular, we first design an LLM-enabled generation mechanism with a prompt engineering strategy for source data generation (SDG) and a cross-attention alignment method for channel data generation (CDG). However, hallucinations from LLMs may cause semantic noise, thus degrading SC performance. To mitigate the hallucination issue, a cross-domain fusion codec (CDFC) framework with a hallucination filtering phase and a cross-domain fusion phase is then proposed for SDG. In particular, the first phase filters out new data generated by the LMKB irrelevant to the original data based on semantic similarity. Then, a cross-domain fusion phase is proposed, which fuses source data with LLM-generated data based on their semantic importance, thereby enhancing task performance. Besides, a joint training objective that combines cross-entropy loss and reconstruction loss is proposed to reduce the impact of hallucination on CDG. Experiment results on three cross-modality retrieval tasks demonstrate that the proposed SC-LMKB can achieve up to 72.6\% and 90.7\% performance gains compared to conventional SC systems and LLM-enabled SC systems, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SC-LMKB, a semantic communication system that augments conventional source and channel knowledge bases with data generated by large language models. It introduces an LLM-enabled generation mechanism using prompt engineering for source data generation (SDG) and cross-attention alignment for channel data generation (CDG), followed by a cross-domain fusion codec (CDFC) that applies semantic-similarity filtering and importance-weighted fusion to mitigate LLM hallucinations. A joint cross-entropy plus reconstruction loss is used for CDG training. Experiments on three cross-modality retrieval tasks report performance gains of up to 72.6% over conventional SC systems and 90.7% over other LLM-enabled SC systems.
Significance. If the reported gains are reproducible with transparent baselines and controls, the work would demonstrate a practical route to scaling semantic knowledge bases via LLMs while addressing hallucination risks through filtering and fusion. The explicit design of CDFC and the joint loss objective provide concrete mechanisms that could be adopted or extended in semantic communication research. The absence of machine-checked proofs or parameter-free derivations is expected for an empirical system paper, but the lack of detailed experimental protocols currently limits the strength of the central claim.
major comments (2)
- [Experimental results section] Experimental results section: The central performance claims (72.6% and 90.7% gains on three cross-modality retrieval tasks) are stated without specifying the exact baseline systems, evaluation metrics, data splits, number of runs, or statistical tests used to compute the percentages. This information is load-bearing for evaluating whether the gains arise from the CDFC or from weaker baselines.
- [CDFC framework description] CDFC framework description: The semantic-similarity filtering phase discards generations below an unspecified threshold and then performs importance-weighted fusion. In cross-modality settings, LLM outputs can be semantically aligned with source data yet contain modality-specific factual errors; the manuscript does not provide evidence (e.g., manual inspection or auxiliary metrics) that such errors are reliably removed before fusion, which directly affects the claim that CDFC enriches the KB without introducing harmful noise.
minor comments (2)
- [LLM-enabled generation mechanism] The prompt-engineering strategy for SDG and the cross-attention alignment for CDG are described at a high level; adding the exact prompt templates or alignment equations would improve reproducibility.
- [Cross-domain fusion phase] Notation for the importance weights in the fusion phase and the threshold in the filtering phase should be defined explicitly with symbols rather than prose descriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the manuscript to provide the missing experimental details and additional evidence for the CDFC framework.
read point-by-point responses
-
Referee: The central performance claims (72.6% and 90.7% gains on three cross-modality retrieval tasks) are stated without specifying the exact baseline systems, evaluation metrics, data splits, number of runs, or statistical tests used to compute the percentages. This information is load-bearing for evaluating whether the gains arise from the CDFC or from weaker baselines.
Authors: We agree that these details are essential for assessing the validity of the reported gains. In the revised manuscript, the Experimental Results section will be expanded to explicitly describe all baseline systems (conventional SC and other LLM-enabled SC methods), the evaluation metrics for the cross-modality retrieval tasks, the data splits and datasets, the number of independent runs with mean and variance, and the statistical tests used to compute the performance improvements. This will clarify that the gains originate from the CDFC and joint loss rather than baseline choices. revision: yes
-
Referee: The semantic-similarity filtering phase discards generations below an unspecified threshold and then performs importance-weighted fusion. In cross-modality settings, LLM outputs can be semantically aligned with source data yet contain modality-specific factual errors; the manuscript does not provide evidence (e.g., manual inspection or auxiliary metrics) that such errors are reliably removed before fusion, which directly affects the claim that CDFC enriches the KB without introducing harmful noise.
Authors: We acknowledge the need for explicit evidence that the filtering removes modality-specific errors. The revised manuscript will specify the semantic similarity threshold value, include qualitative examples of filtered and retained generations with manual inspection notes, and add ablation results or auxiliary metrics (e.g., hallucination rate before/after filtering) to demonstrate noise reduction in cross-modality fusion. This will support the claim that CDFC enriches the KB without harmful noise. revision: yes
Circularity Check
No circularity: empirical system proposal with experimental validation
full rationale
The paper describes an SC-LMKB architecture using LLM generation, CDFC filtering/fusion, and a joint loss for CDG, then reports empirical gains on three retrieval tasks versus baselines. No equations, fitted parameters, or derivations are presented that reduce to their own inputs by construction. Performance claims rest on direct experimental comparison rather than any self-referential prediction or self-citation chain. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LLM-enabled knowledge base (LMKB)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a cross-domain fusion codec (CDFC) framework with a hallucination filtering phase and a cross-domain fusion phase... filters out new data generated by the LMKB irrelevant to the original data based on semantic similarity
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
cross-attention alignment method that aligns CSI features with the natural language modality in the LLM space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Enabling massive iot toward 6g: A comprehensive survey,
F. Guo, F. R. Yu, H. Zhang, X. Li, H. Ji, and V. C. M. Leung, “Enabling massive iot toward 6g: A comprehensive survey,” IEEE Internet Things J., vol. 8, no. 15, pp. 11 891–11 915, Mar. 2021
2021
-
[2]
Seman- tic communications with artificial intelligence tasks: Reducing bandwidth requirements and improving artificial intelligence task performance,
Y. Yang, C. Guo, F. Liu, L. Sun, C. Liu, and Q. Sun, “Seman- tic communications with artificial intelligence tasks: Reducing bandwidth requirements and improving artificial intelligence task performance,” IEEE Ind. Electron. Mag., vol. 17, no. 3, pp. 4–13, May 2022
2022
-
[3]
OFDM- based digital semantic communication with importance aware- ness,
C. Liu, C. Guo, Y. Yang, W. Ni, and T. Q. S. Quek, “OFDM- based digital semantic communication with importance aware- ness,” IEEE Trans. Commun., vol. 72, no. 10, pp. 6301–6315, Oct. 2024
2024
-
[4]
Adaptive information bottleneck guided joint source and channel coding for image transmission,
L. Sun, Y. Yang, M. Chen, C. Guo, W. Saad, and H. V. Poor, “Adaptive information bottleneck guided joint source and channel coding for image transmission,” IEEE J. Sel. Areas Commun., vol. 41, no. 8, pp. 2628–2644, Jun. 2023
2023
-
[5]
Scan: Semantic commu- nication with adaptive channel feedback,
G. Zhang, Q. Hu, Y. Cai, and G. Yu, “Scan: Semantic commu- nication with adaptive channel feedback,” IEEE Trans. Cogn. Commun. Netw., vol. 10, no. 5, pp. 1759–1773, Apr. 2024
2024
-
[6]
Robust image semantic coding with learnable CSI fusion masking over MIMO fading channels,
B. Xie, Y. Wu, Y. Shi, W. Zhang, S. Cui, and M. Debbah, “Robust image semantic coding with learnable CSI fusion masking over MIMO fading channels,” IEEE Trans. Wirel. Commun., vol. 23, no. 10, pp. 14 155–14 170, Jun. 2024
2024
-
[7]
Communication-efficient framework for distributed image se- mantic wireless transmission,
B. Xie, Y. Wu, Y. Shi, D. W. K. Ng, and W. Zhang, “Communication-efficient framework for distributed image se- mantic wireless transmission,” IEEE Internet Things J., vol. 10, no. 24, pp. 22 555–22 568, Aug. 2023
2023
-
[8]
Performance optimization for semantic communi- cations: An attention-based reinforcement learning approach,
Y. Wang, M. Chen, T. Luo, W. Saad, D. Niyato, H. V. Poor, and S. Cui, “Performance optimization for semantic communi- cations: An attention-based reinforcement learning approach,” IEEE J. Sel. Areas Commun., vol. 40, no. 9, pp. 2598–2613, Jul. 2022
2022
-
[9]
Knowledge base enabled semantic communication: A generative perspective,
J. Ren, Z. Zhang, J. Xu, G. Chen, Y. Sun, P. Zhang, and S. Cui, “Knowledge base enabled semantic communication: A generative perspective,” IEEE Wirel. Commun., vol. 31, no. 4, pp. 14–22, Aug. 2024
2024
-
[10]
Deep learning enabled semantic communication systems,
H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Trans. Signal Process., vol. 69, pp. 2663–2675, Apr. 2021
2021
-
[11]
Deep learning- empowered semantic communication systems with a shared knowledge base,
P. Yi, Y. Cao, X. Kang, and Y.-C. Liang, “Deep learning- empowered semantic communication systems with a shared knowledge base,” IEEE Trans. Wirel. Commun., vol. 23, no. 6, pp. 6174–6187, Nov. 2023
2023
-
[12]
Deep learning-enabled semantic communication systems with task- unaware transmitter and dynamic data,
H. Zhang, S. Shao, M. Tao, X. Bi, and K. B. Letaief, “Deep learning-enabled semantic communication systems with task- unaware transmitter and dynamic data,” IEEE J. Sel. Areas Commun., vol. 41, no. 1, pp. 170–185, Nov. 2022
2022
-
[13]
Semantic communications: Overview, open issues, and future research directions,
X. Luo, H.-H. Chen, and Q. Guo, “Semantic communications: Overview, open issues, and future research directions,” IEEE Wirel. Commun., vol. 29, no. 1, pp. 210–219, Jan. 2022
2022
-
[14]
Cog- nitive semantic communication systems driven by knowledge graph,
F. Zhou, Y. Li, X. Zhang, Q. Wu, X. Lei, and R. Q. Hu, “Cog- nitive semantic communication systems driven by knowledge graph,” in Proceedings of the IEEE International Conference on Communications. Seoul, South Korea: IEEE, 2022, pp. 4860–4865
2022
-
[15]
Explainable semantic communication for text tasks,
C. Liu, C. Guo, Y. Yang, W. Ni, Y. Zhou, L. Li, and T. Q. S. Quek, “Explainable semantic communication for text tasks,” IEEE Internet Things J., vol. 11, no. 24, pp. 3820–3833, Aug. 2024
2024
-
[16]
A new communication paradigm: From bit accuracy to semantic fidelity
G. Shi, D. Gao, X. Song, J. Chai, M. Yang, X. Xie, L. Li, and X. Li, “A new communication paradigm: From bit accuracy to semantic fidelity,” arXiv preprint arXiv:2101.12649, Jan. 2021
-
[17]
Large AI model-based semantic communications,
F. Jiang, Y. Peng, L. Dong, K. Wang, K. Yang, C. Pan, and X. You, “Large AI model-based semantic communications,” IEEE Wirel. Commun., vol. 31, no. 3, pp. 68–75, Jun. 2024
2024
-
[18]
Data augmentation for text-based person retrieval using large language models,
Z. Li, L. Si, C. Guo, Y. Yang, and Q. Cao, “Data augmentation for text-based person retrieval using large language models,” arXiv preprint arXiv:2405.11971, May 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14
-
[19]
Efficient multiple-input–multiple-output channel state infor- mation feedback: A semantic-knowledge-base-driven approach,
L. Tang, Y. Sun, S. Yao, X. Xu, H. Chen, and Z. Luo, “Efficient multiple-input–multiple-output channel state infor- mation feedback: A semantic-knowledge-base-driven approach,” Electronics, vol. 14, no. 8, p. 1666, Apr. 2025
2025
-
[20]
Large AI model empowered multimodal semantic communications,
F. Jiang, L. Dong, Y. Peng, K. Wang, K. Yang, C. Pan, and X. You, “Large AI model empowered multimodal semantic communications,” IEEE Commun. Mag., vol. 63, no. 1, pp. 76– 82, Sep. 2025
2025
-
[21]
Vector quan- tized semantic communication system,
Q. Fu, H. Xie, Z. Qin, G. Slabaugh, and X. Tao, “Vector quan- tized semantic communication system,” IEEE Wirel. Commun. Lett., vol. 12, no. 6, pp. 982–986, Mar. 2023
2023
-
[22]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, Feb. 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan et al., “Deepseek-v3 technical report,” arXiv preprint arXiv:2412.19437, Dec. 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
A comprehensive overview of large language models,
H. Naveed, A. U. Khan, S. Qiu, M. Saqib, S. Anwar, M. Usman, N. Akhtar, N. Barnes, and A. Mian, “A comprehensive overview of large language models,” arXiv preprint arXiv:2307.06435, Jul. 2023
-
[25]
Semantic importance- aware communications using pre-trained language models,
S. Guo, Y. Wang, S. Li, and N. Saeed, “Semantic importance- aware communications using pre-trained language models,” IEEE Commun. Lett., vol. 27, no. 9, pp. 2328–2332, Jul. 2023
2023
-
[26]
Rethinking generative semantic com- munication for multi-user systems with large language models,
W. Yang, Z. Xiong, S. Mao, T. Q. S. Quek, P. Zhang, M. Deb- bah, and R. Tafazolli, “Rethinking generative semantic com- munication for multi-user systems with large language models,” IEEE Wirel. Commun., pp. 1–9, Apr. 2025
2025
-
[27]
LLM4CP: Adapting large language models for channel prediction,
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “LLM4CP: Adapting large language models for channel prediction,” J. Commun. Inf. Netw., vol. 9, no. 2, pp. 113–125, Jun. 2024
2024
-
[28]
LLM4WM: Adapting LLM for wireless multi-tasking,
X. Liu, S. Gao, B. Liu, X. Cheng, and L. Yang, “LLM4WM: Adapting LLM for wireless multi-tasking,” arXiv preprint arXiv:2501.12983, Jul. 2025
-
[29]
CSI-LLM: A novel downlink channel prediction method aligned with LLM pre-training,
S. Fan, Z. Liu, X. Gu, and H. Li, “CSI-LLM: A novel downlink channel prediction method aligned with LLM pre-training,” in Proceedings of the 2025 IEEE Wireless Communications and Networking Conference. San Diego, CA, USA: IEEE, 2025, pp. 1–6
2025
-
[30]
On the impact of fine-tuning on chain-of- thought reasoning.arXiv preprint arXiv:2411.15382,
E. Lobo, C. Agarwal, and H. Lakkaraju, “On the impact of fine-tuning on chain-of-thought reasoning,” arXiv preprint arXiv:2411.15382, Mar. 2024
-
[31]
N. Chakraborty, M. Ornik, and K. Driggs-Campbell, “Halluci- nation detection in foundation models for decision-making: A flexible definition and review of the state of the art,” arXiv preprint arXiv:2403.16527, Mar. 2024
-
[32]
Task-oriented semantic communication with large language model enabled knowledge base,
W. Hu, C. Guo, Z. Zhu, Y. Yang, and C. Feng, “Task-oriented semantic communication with large language model enabled knowledge base,” in Proceedings of the IEEE International Conference on Communications. Montréal, Canada: IEEE, 2025, accepted
2025
-
[33]
The effect of sampling temperature on problem solving in large language models,
M. Renze, “The effect of sampling temperature on problem solving in large language models,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Pro- cessing. Singapore: Association for Computational Linguistics, 2024, pp. 7346–7356
2024
-
[34]
Haoxin Liu, Shangqing Xu, Zhiyuan Zhao, Lingkai Kong, Harshavardhan Kamarthi, Aditya B
M. Jin, S. Wang, L. Ma, Z. Chu, J. Y. Zhang, X. Shi, P.-Y. Chen, Y. Liang, Y.-F. Li, S. Pan et al., “Time-llm: Time series forecasting by reprogramming large language models,” arXiv preprint arXiv:2310.01728, Oct. 2023
-
[35]
Grad-cam: Visual explanations from deep net- works via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep net- works via gradient-based localization,” in Proceedings of the IEEE International Conference on computer vision. Venice, Italy: IEEE, 2017, pp. 618–626
2017
-
[36]
Person search with natural language description,
S. Li, T. Xiao, H. Li, B. Zhou, D. Yue, and X. Wang, “Person search with natural language description,” in Proceedings of the IEEE conference on computer vision and pattern recognition. Hawaii, USA: IEEE, 2017, pp. 1970–1979
2017
-
[37]
arXiv preprint arXiv:2107.12666 (2021) 2, 3, 11, 15
Z. Ding, C. Ding, Z. Shao, and D. Tao, “Semantically self-aligned network for text-to-image part-aware person re- identification,” arXiv preprint arXiv:2107.12666, Jul. 2021
-
[38]
Dssl: Deep surroundings-person separation learning for text-based person retrieval,
A. Zhu, Z. Wang, Y. Li, X. Wan, J. Jin, T. Wang, F. Hu, and G. Hua, “Dssl: Deep surroundings-person separation learning for text-based person retrieval,” in Proceedings of the 29th ACM international conference on multimedia. Chengdu, China: ACM, 2021, pp. 209–217
2021
-
[39]
Clotho: An audio cap- tioning dataset,
K. Drossos, S. Lipping, and T. Virtanen, “Clotho: An audio cap- tioning dataset,” in Proceedings of the IEEE International Con- ference on Acoustics, Speech and Signal Processing. Barcelona, Spain: IEEE, 2020, pp. 736–740
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.