Recognition: no theorem link
A BEV-Fusion Based Framework for Sequential Multi-Modal Beam Prediction in mmWave Systems
Pith reviewed 2026-05-10 18:58 UTC · model grok-4.3
The pith
Fusing camera, LiDAR, radar and GPS in shared bird's-eye-view space enables accurate sequential beam prediction for mmWave systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that multi-modal fusion performed in a shared bird's-eye-view space, using a learned camera-to-BEV cross-attention module and a temporal transformer over five-step sequences, supplies an effective spatial abstraction for sensing-assisted beam prediction and yields higher distance-based accuracy than prior one-dimensional fusion methods on the evaluated DeepSense 6G scenarios.
What carries the argument
The BEV-fusion module that aligns and merges multi-modal sensor features in a top-down spatial grid via cross-attention, followed by temporal aggregation.
If this is right
- Lower beam-training overhead for high-mobility mmWave links.
- More reliable predictions when motion is present through explicit temporal modeling.
- Reduced reliance on accurate camera extrinsic calibration for effective multi-modal use.
- Direct compatibility with perception pipelines already operating in BEV coordinates.
Where Pith is reading between the lines
- The same BEV-fusion structure could be reused for related tasks such as channel estimation or blockage prediction if geometric consistency remains the dominant factor.
- Integration with existing vehicle BEV perception stacks would require only modest additional modules for the temporal transformer and beam head.
- Performance gains may diminish in scenarios where sensor fields of view have minimal overlap or when heavy occlusions break the assumed spatial alignment.
Load-bearing premise
That direct fusion in BEV space preserves cross-modal geometric structure and visual semantics more effectively than global pooling of one-dimensional features.
What would settle it
On the same DeepSense 6G scenarios, a global-pooling baseline that receives identical modalities and five-step sequences achieves equal or higher distance-based accuracy.
Figures




read the original abstract
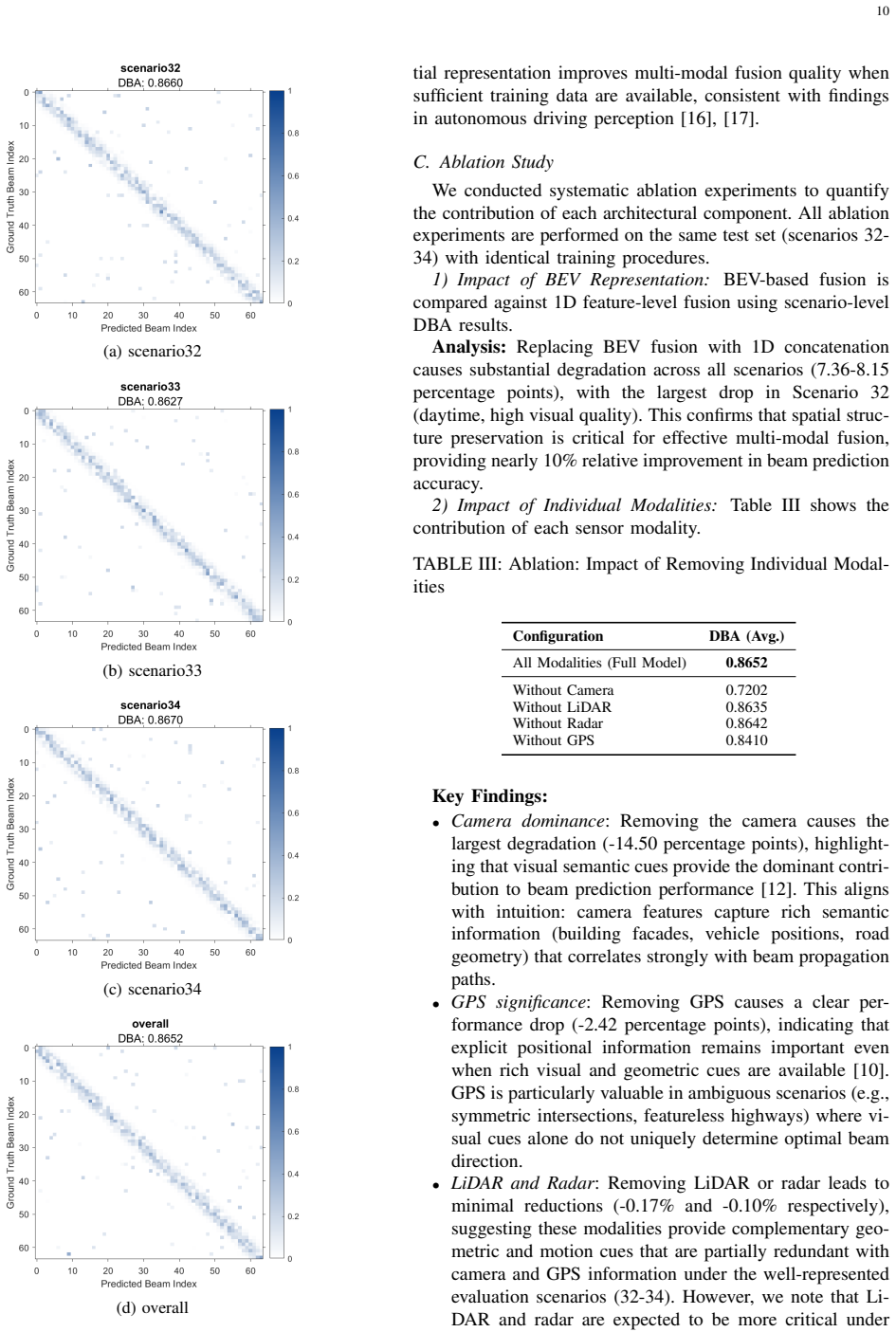
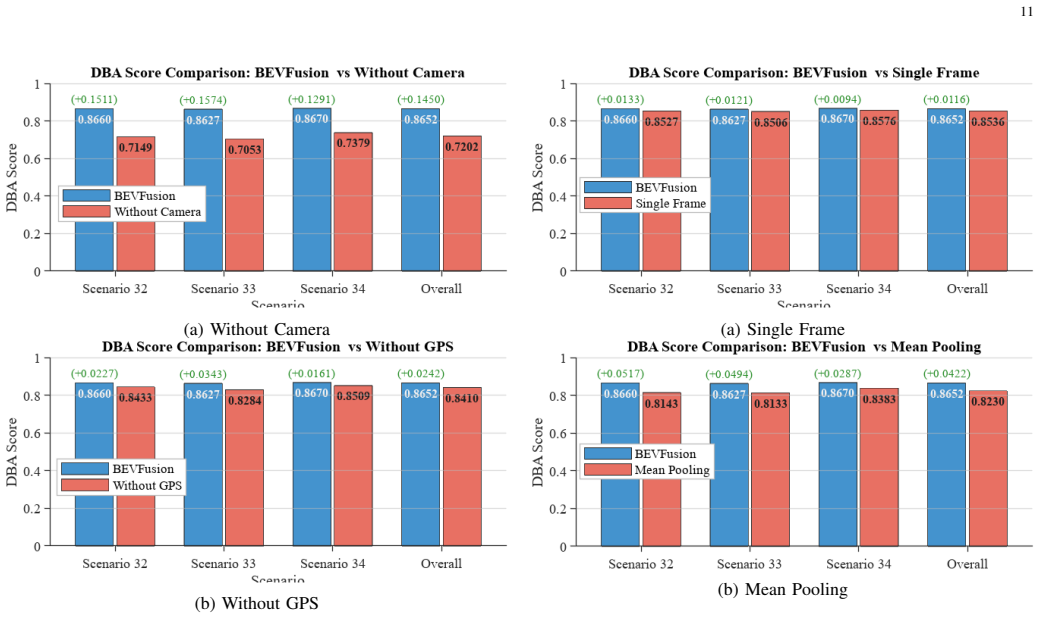
Beam prediction is critical for reducing beam-training overhead in millimeter-wave (mmWave) systems, especially in high-mobility vehicular scenarios. This paper presents a BEV-Fusion based framework that unifies camera, LiDAR, radar, and GPS modalities in a shared bird's-eye-view (BEV) representation for spatially consistent multi-modal fusion. Unlike priorapproaches that fuse globally pooled one-dimensional features, the proposed method performs fusion in BEV space to preservecross-modal geometric structure and visual semantic density. A learned camera-to-BEV module based on cross-attention is adopted to generate BEV-aligned visual features without relying on precise camera calibration, and a temporal transformer is used to aggregate five-step sequential observations for motion-aware beam prediction. Experiments on the DeepSense 6G benchmark show that BEV-Fusion achieves approximately 87% distance- based accuracy (DBA) on scenarios 32, 33 and 34, outperforming the TransFuser baseline. These results indicate that BEV-space fusion provides an effective spatial abstraction for sensing-assisted beam prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a BEV-Fusion framework for sequential multi-modal beam prediction in mmWave systems. It unifies camera, LiDAR, radar, and GPS modalities into a shared bird's-eye-view (BEV) representation, employs a learned cross-attention module to generate BEV-aligned visual features without precise extrinsic calibration, and uses a temporal transformer to aggregate five-step sequential observations. On scenarios 32, 33, and 34 of the DeepSense 6G benchmark, the method achieves approximately 87% distance-based accuracy (DBA) and outperforms the TransFuser baseline.
Significance. If the central performance claim holds under rigorous validation, the work would provide evidence that BEV-space fusion offers a useful spatial abstraction for preserving cross-modal geometric structure in sensing-assisted beam management, potentially aiding overhead reduction in high-mobility 6G vehicular scenarios. The reliance on a public benchmark and direct comparison to an established baseline (TransFuser) is a positive aspect that supports reproducibility and comparability.
major comments (2)
- [Proposed method (camera-to-BEV module description) and Experiments] The headline claim that BEV-space fusion preserves cross-modal geometric structure more effectively than global pooling of one-dimensional features rests on the learned camera-to-BEV cross-attention module. The manuscript reports end-to-end DBA gains but contains no ablation isolating this alignment module, no attention-map visualizations, and no proxy metric (e.g., reprojection consistency) confirming that the features respect spatial geometry rather than spurious correlations. This makes it impossible to attribute the reported 87% DBA specifically to the BEV abstraction.
- [Abstract and Experiments section] The abstract states a clear performance number (~87% DBA) on a public benchmark and names the baseline, but supplies no error bars, statistical tests, full experimental protocol details (e.g., exact handling of the five sequential steps, data splits, or hyperparameter settings), or ablation results. Without these, the data support for the central claim that BEV fusion is the key driver cannot be fully verified.
minor comments (2)
- [Abstract] The abstract contains typographical errors such as missing spaces in 'priorapproaches' and 'preservecross-modal'.
- [Method and Experiments] Notation for the temporal transformer and the exact definition of distance-based accuracy (DBA) should be introduced with equations or a clear reference to prior work for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each of the major comments below and outline the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Proposed method (camera-to-BEV module description) and Experiments] The headline claim that BEV-space fusion preserves cross-modal geometric structure more effectively than global pooling of one-dimensional features rests on the learned camera-to-BEV cross-attention module. The manuscript reports end-to-end DBA gains but contains no ablation isolating this alignment module, no attention-map visualizations, and no proxy metric (e.g., reprojection consistency) confirming that the features respect spatial geometry rather than spurious correlations. This makes it impossible to attribute the reported 87% DBA specifically to the BEV abstraction.
Authors: We agree that isolating the contribution of the camera-to-BEV cross-attention module would provide stronger evidence for the benefits of BEV-space fusion. While the overall performance improvement over TransFuser supports the framework's effectiveness, we acknowledge the lack of specific ablations for this component. In the revised manuscript, we will include an ablation study that compares the full model against a variant without the cross-attention alignment (e.g., using direct projection or global features). We will also add visualizations of the learned attention maps to illustrate the spatial alignment and discuss any proxy metrics if feasible. This will help attribute the gains more directly to the BEV abstraction. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states a clear performance number (~87% DBA) on a public benchmark and names the baseline, but supplies no error bars, statistical tests, full experimental protocol details (e.g., exact handling of the five sequential steps, data splits, or hyperparameter settings), or ablation results. Without these, the data support for the central claim that BEV fusion is the key driver cannot be fully verified.
Authors: We appreciate this observation regarding the experimental rigor. The current manuscript provides the core results on the DeepSense 6G benchmark, but we recognize the value of additional details for reproducibility and verification. In the revision, we will expand the Experiments section to include error bars from repeated experiments, specify the data splits and the exact protocol for handling the five sequential steps, list key hyperparameter settings, and incorporate more comprehensive ablation results. We will also consider adding statistical significance tests to support the performance comparisons. revision: yes
Circularity Check
No significant circularity; empirical evaluation on external benchmark is self-contained
full rationale
The paper proposes a BEV-fusion architecture for multi-modal beam prediction and reports DBA accuracy on the public DeepSense 6G dataset (scenarios 32-34). No equations, parameters, or predictions are shown to reduce by construction to quantities fitted inside the same experiment; the claimed performance is measured against external ground truth rather than being a renaming or self-definition of internal fits. Self-citations, if present, are not load-bearing for the central empirical result. The derivation chain consists of architectural choices followed by benchmark evaluation and is therefore independent.
Axiom & Free-Parameter Ledger
free parameters (1)
- Number of sequential observation steps =
5
axioms (1)
- domain assumption The DeepSense 6G dataset is representative of real mmWave vehicular beam-prediction conditions.
Reference graph
Works this paper leans on
-
[1]
Wireless communications and applications above 100 GHz: Opportunities and challenges for 6G and beyond,
T. S. Rappaport, Y . Xing, O. Kanhere, S. Ju, A. Madanayake, S. Mandal, A. Alkhateeb, and G. C. Trichopoulos, “Wireless communications and applications above 100 GHz: Opportunities and challenges for 6G and beyond,”IEEE Access, vol. 7, pp. 78 729–78 757, 2019
2019
-
[2]
An overview of signal processing techniques for millimeter wave MIMO systems,
R. W. Heath, N. Gonz ´alez-Prelcic, S. Rangan, W. Roh, and A. M. Sayeed, “An overview of signal processing techniques for millimeter wave MIMO systems,”IEEE J. Sel. Topics Signal Process., vol. 10, no. 3, pp. 436–453, 2016
2016
-
[3]
Channel estimation and hybrid precoding for millimeter wave cellular systems,
A. Alkhateeb, O. El Ayach, G. Leus, and R. W. Heath, “Channel estimation and hybrid precoding for millimeter wave cellular systems,” IEEE J. Sel. Topics Signal Process., vol. 8, no. 5, pp. 831–846, 2014
2014
-
[4]
Deep learning coordinated beamforming for highly-mobile millimeter wave systems,
A. Alkhateeb, S. Alex, P. Varkey, Y . Li, Q. Qu, and D. Tujkovic, “Deep learning coordinated beamforming for highly-mobile millimeter wave systems,”IEEE Access, vol. 6, pp. 37 328–37 348, 2018
2018
-
[5]
Reinforcement learning of beam codebooks in millimeter wave and terahertz MIMO systems,
Y . Zhang, M. Alrabeiah, and A. Alkhateeb, “Reinforcement learning of beam codebooks in millimeter wave and terahertz MIMO systems,” inProc. IEEE Int. Conf. Acoustics, Speech Signal Process. (ICASSP). IEEE, 2021, pp. 8138–8142
2021
-
[6]
Millimeter wave base stations with cameras: Vision-aided beam and blockage prediction,
M. Alrabeiah, A. Hredzak, and A. Alkhateeb, “Millimeter wave base stations with cameras: Vision-aided beam and blockage prediction,” in Proc. IEEE Veh. Technol. Conf. (VTC-Spring). IEEE, 2020, pp. 1–5
2020
-
[7]
Vision-aided 6G wireless communications: Blockage prediction and proactive handover,
Y . Zhang and A. Alkhateeb, “Vision-aided 6G wireless communications: Blockage prediction and proactive handover,”IEEE Trans. Veh. Technol., vol. 72, no. 3, pp. 3478–3493, 2023
2023
-
[8]
LiDAR aided future beam prediction in real-world millimeter wave V2I communications,
S. Jiang, G. Charan, and A. Alkhateeb, “LiDAR aided future beam prediction in real-world millimeter wave V2I communications,”IEEE Wireless Commun. Lett., vol. 11, no. 9, pp. 1975–1979, 2022
1975
-
[9]
Radar aided 6G beam prediction: Deep learning algorithms and real-world demonstration,
U. Demirhan and A. Alkhateeb, “Radar aided 6G beam prediction: Deep learning algorithms and real-world demonstration,” inProc. IEEE Wireless Commun. Netw. Conf. (WCNC). IEEE, 2022, pp. 2655–2660
2022
-
[10]
Position aided beam prediction in the real world: How useful GPS locations actually are?
J. Morais, A. Behboodi, H. Pezeshki, and A. Alkhateeb, “Position aided beam prediction in the real world: How useful GPS locations actually are?”arXiv preprint arXiv:2205.09054, 2022
-
[11]
Multimodal transformers for wireless communications: A case study in beam prediction,
Y . Tian, Q. Zhao, Z. e. a. Kherroubi, F. Boukhalfa, K. Wu, and F. Bader, “Multimodal transformers for wireless communications: A case study in beam prediction,” inIEEE GLOBECOM. IEEE, 2023, pp. 1–6
2023
-
[12]
Vision-position multi-modal beam prediction using real millimeter wave datasets,
G. Charan, T. Osman, A. Hredzak, N. Thawdar, and A. Alkhateeb, “Vision-position multi-modal beam prediction using real millimeter wave datasets,” inProc. IEEE Wireless Commun. Netw. Conf. (WCNC). IEEE, 2022, pp. 2727–2731
2022
-
[13]
Multi-modal fusion transformer for end-to-end autonomous driving,
A. Prakash, K. Chitta, and A. Geiger, “Multi-modal fusion transformer for end-to-end autonomous driving,” inProc. IEEE Conf. Computer Vision Pattern Recognit. (CVPR). IEEE, 2021, pp. 7077–7087
2021
-
[14]
PointPainting: Se- quential fusion for 3D object detection,
S. V ora, A. H. Lang, B. Helou, and O. Beijbom, “PointPainting: Se- quential fusion for 3D object detection,” inProc. IEEE Conf. Computer Vision Pattern Recognit. (CVPR). IEEE, 2020, pp. 4604–4612
2020
-
[15]
PointAugmenting: Cross-modal augmentation for 3D object detection,
C. Wang, C. Ma, M. Zhu, and X. Yang, “PointAugmenting: Cross-modal augmentation for 3D object detection,” inProc. IEEE Conf. Computer Vision Pattern Recognit. (CVPR). IEEE, 2021, pp. 11 794–11 803
2021
-
[16]
BEVFusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “BEVFusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA). IEEE, 2023, pp. 2774–2781
2023
-
[17]
BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y . Qiao, and J. Dai, “BEVFormer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” inProc. Euro- pean Conf. Computer Vision (ECCV). Springer, 2022, pp. 1–18
2022
-
[18]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. IEEE Conf. Computer Vision Pattern Recognit. (CVPR). IEEE, 2016, pp. 770–778
2016
-
[19]
Lift, splat, shoot: Encoding images from arbi- trary camera rigs by implicitly unprojecting to 3D,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbi- trary camera rigs by implicitly unprojecting to 3D,” inProc. European Conf. Computer Vision (ECCV). Springer, 2020, pp. 194–210
2020
-
[20]
DeepSense 6G: Large-scale real-world multi-modal sensing and communication datasets,
G. Charan, A. Alkhateeb, T. Osman, A. Hredzak, N. Srinivas, and M. Seth, “DeepSense 6G: Large-scale real-world multi-modal sensing and communication datasets,”IEEE Dataport, 2023, dOI: 10.21227/4002-r072
-
[21]
PointNet: Deep learning on point sets for 3D classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “PointNet: Deep learning on point sets for 3D classification and segmentation,” inProc. IEEE Conf. Computer Vision Pattern Recognit. (CVPR). IEEE, 2017, pp. 652–660
2017
-
[22]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” inProc. Int. Conf. Learning Represen- tations (ICLR), 2015
2015
-
[23]
V oxelNet: End-to-end learning for point cloud based 3D object detection,
Y . Zhou and O. Tuzel, “V oxelNet: End-to-end learning for point cloud based 3D object detection,” inProc. IEEE Conf. Computer Vision Pattern Recognit. (CVPR). IEEE, 2018, pp. 4490–4499
2018
-
[24]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[26]
EfficientNet: Rethinking model scaling for convolu- tional neural networks,
M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for convolu- tional neural networks,” inProc. Int. Conf. Machine Learning (ICML). PMLR, 2019, pp. 6105–6114
2019
-
[27]
DeepSense 6G: A large-scale real-world multi-modal sensing and com- munication dataset,
A. Alkhateeb, G. Charan, T. Osman, A. Hredzak, and N. Srinivas, “DeepSense 6G: A large-scale real-world multi-modal sensing and com- munication dataset,” Available: https://www.DeepSense6G.net, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.