Recognition: 2 theorem links
· Lean TheoremHidden in the Multiplicative Interaction: Uncovering Fragility in Multimodal Contrastive Learning
Pith reviewed 2026-05-10 19:06 UTC · model grok-4.3
The pith
A single unreliable modality distorts cross-modal retrieval scores through the multilinear inner product in multimodal contrastive learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Symile extends pairwise contrastive objectives such as CLIP by using the multilinear inner product over embeddings from three or more modalities to capture higher-order dependencies. Because the product is multiplicative, a single poor-quality modality embedding multiplies through the entire interaction and distorts the contrastive scores used for retrieval. Gated Symile adds a contrastive, attention-based gating module that adapts each modality's contribution on a per-candidate basis by shifting problematic embeddings toward neutral learnable vectors or invoking an explicit NULL direction when reliable alignment is improbable.
What carries the argument
The attention-based per-candidate gating mechanism that interpolates embeddings toward neutral directions or a NULL option to suppress unreliable modalities inside the multilinear inner product.
If this is right
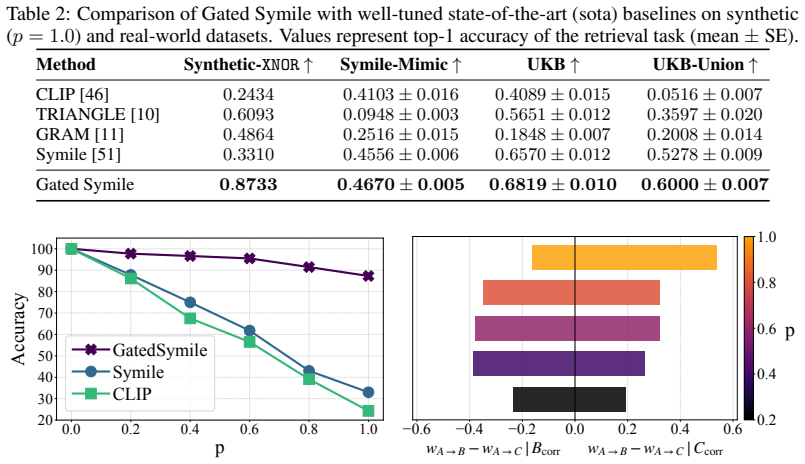
- Gated Symile reaches higher top-1 retrieval accuracy than well-tuned state-of-the-art baselines on synthetic and real trimodal datasets.
- The same fragility appears whenever the multilinear inner product is used in the presence of noise, misalignment, or missing inputs.
- Gating adapts modality contributions without requiring additional labels or global reweighting.
- The approach provides a concrete route toward robust contrastive learning for more than two modalities.
Where Pith is reading between the lines
- Similar per-candidate gating may improve robustness in other models that rely on multiplicative or higher-order feature interactions.
- The method suggests that reliability should be assessed example-by-example rather than with fixed modality weights.
- In sensor-fusion settings such as medical imaging or robotics, the gate could reduce errors caused by intermittently missing or degraded inputs.
- Extending the gate to variable numbers of modalities would test whether the same mechanism scales beyond trimodal cases.
Load-bearing premise
The attention-based gate can reliably detect and suppress unreliable modalities on a per-candidate basis without extra supervision and without harming alignment when every modality is informative.
What would settle it
A controlled experiment on a dataset where all modalities are verifiably informative and aligned, yet Gated Symile produces lower retrieval accuracy than plain Symile, showing the gate introduces unnecessary distortion.
Figures



read the original abstract
Contrastive learning has become a standard approach for unsupervised learning from paired data, as demonstrated by CLIP for image-text matching. However, many domains involve more than two modalities and require objectives that capture higher-order dependencies beyond pairwise alignment. Symile extends CLIP to this setting by replacing the dot product with the multilinear inner product (MIP) over modality embeddings. In this work, we show that there is a fragility which ishidden in the multiplicative interaction: a single weakly informative, misaligned, or missing modality can propagate through the objective and distort cross-modal retrieval scores. We propose Gated Symile, a contrastive gating mechanism that adapts modality contributions on an attention-based, per-candidate basis. The gate suppresses unreliable inputs by interpolating embeddings toward learnable neutral directions with an explicit NULL option when reliable cross-modal alignment is unlikely. Across a controlled synthetic benchmark that uncovers this fragility and three real-world trimodal datasets, Gated Symile achieves higher top-1 retrieval accuracy than well-tuned state-of-the-art (sota) baselines. More broadly, our results highlight gating as a step toward robust multimodal contrastive learning beyond two modalities in the presence of noise, misalignment, or missing inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends pairwise contrastive learning (e.g., CLIP) to trimodal settings by replacing the dot product with the multilinear inner product in Symile. It identifies a fragility in this multiplicative interaction whereby a single weakly informative, misaligned, or missing modality can distort cross-modal retrieval scores. To mitigate this, the authors propose Gated Symile, which introduces an attention-based gating network that, on a per-candidate basis, interpolates unreliable modality embeddings toward learnable neutral directions or an explicit NULL embedding. Experiments on a controlled synthetic benchmark and three real trimodal datasets report higher top-1 retrieval accuracy for Gated Symile compared with well-tuned baselines.
Significance. If the gating mechanism can be shown to selectively suppress unreliable modalities while remaining near-neutral on fully informative inputs, the work would provide a concrete step toward robust multimodal contrastive objectives beyond two modalities. The synthetic benchmark is a useful controlled testbed for isolating the fragility effect.
major comments (2)
- [Experimental results (synthetic benchmark and real datasets)] The central attribution of performance gains to fragility mitigation rests on the assumption that the learned gate remains close to the identity (or neutral) when all modalities are aligned and informative. No ablation isolating this clean-input regime is reported on either the synthetic benchmark or the real datasets; without it, the improvements over untuned Symile and other baselines could arise from the gating network acting as additional capacity or smoothing rather than targeted suppression.
- [Experiments] The experimental section provides insufficient detail on controls, baseline implementations, hyperparameter search procedures, number of random seeds, and statistical significance testing. This limits verification that the reported top-1 accuracy gains are robust and directly comparable.
minor comments (2)
- [Abstract] Abstract contains a typographical error: 'which ishidden' should be 'which is hidden'.
- [Method] The precise formulation of the attention-based gate (how queries/keys are formed from the three embeddings, how the NULL option is parameterized) should be stated explicitly with equations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the experimental validation needed to support our claims about fragility in multimodal contrastive learning. We address each major point below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The central attribution of performance gains to fragility mitigation rests on the assumption that the learned gate remains close to the identity (or neutral) when all modalities are aligned and informative. No ablation isolating this clean-input regime is reported on either the synthetic benchmark or the real datasets; without it, the improvements over untuned Symile and other baselines could arise from the gating network acting as additional capacity or smoothing rather than targeted suppression.
Authors: We agree that an explicit ablation on the clean-input regime is necessary to isolate the effect of targeted suppression from general capacity gains. In the revised manuscript, we will add this analysis on the synthetic benchmark by reporting gate interpolation weights and retrieval performance when all three modalities are fully informative and aligned, demonstrating that the gate remains near-neutral without degrading accuracy relative to ungated Symile. For the real datasets, we will include a similar per-modality reliability analysis on subsets where cross-modal alignment is strong, with quantitative metrics on gate behavior. revision: yes
-
Referee: The experimental section provides insufficient detail on controls, baseline implementations, hyperparameter search procedures, number of random seeds, and statistical significance testing. This limits verification that the reported top-1 accuracy gains are robust and directly comparable.
Authors: We acknowledge the need for greater experimental transparency. The revised version will expand the experimental section with: complete descriptions of baseline implementations (including any adaptations for trimodal settings), the full hyperparameter search procedure and ranges used for all methods, the number of random seeds (five seeds were used across all runs), standard deviations on reported metrics, and statistical significance tests (paired t-tests with p-values) comparing Gated Symile to baselines. These additions will ensure reproducibility and direct comparability. revision: yes
Circularity Check
No circularity; empirical proposal grounded in experiments
full rationale
The paper identifies fragility in the multilinear inner product of Symile via a controlled synthetic benchmark and proposes Gated Symile with attention-based per-candidate gating learned end-to-end from the contrastive loss. Improvements are shown through direct accuracy comparisons on synthetic and real trimodal datasets. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the claims rest on observable experimental outcomes rather than tautological equivalence to inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the gate interpolates embeddings toward learnable neutral directions nm ... ˜em = wt→m em + (1−wt→m)nm
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Symile replaces CLIP’s dot product with the multilinear inner product (MIP) ... g(x(1),…,x(M))=⟨e1,…,eM⟩/τMIP
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Julián N. Acosta, Guido J. Falcone, Pranav Rajpurkar, and Eric J. Topol. Multimodal biomedical ai.Nature Medicine, 28(9):1773–1784, September 2022. ISSN 1078-8956, 1546-170X. doi: 10.1038/s41591-022-01981-2
-
[2]
Sanity checks for saliency maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper_file...
2018
-
[3]
Abhijit Bendale and Terrance E. Boult. Towards open set deep networks. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, June 27-30, 2016, page 1563–1572. IEEE Computer Society, 2016. doi: 10.1109/CVPR.2016.173. URLhttps://doi.org/10.1109/CVPR.2016.173
-
[4]
Braunger, Benjamin Wild, Scott T
Thore Buergel, Jakob Steinfeldt, Greg Ruyoga, Maik Pietzner, Daniele Bizzarri, Dina V ojinovic, Julius Upmeier Zu Belzen, Lukas Loock, Paul Kittner, Lara Christmann, Noah Hollmann, Henrik Strangalies, Jana M. Braunger, Benjamin Wild, Scott T. Chiesa, Joachim Spranger, Fabian Klostermann, Erik B. Van Den Akker, Stella Trompet, Simon P. Mooijaart, Naveed Sa...
2022
-
[5]
Why do we need large batchsizes in contrastive learning? a gradient- bias perspective
Changyou Chen, Jianyi Zhang, Yi Xu, Liqun Chen, Jiali Duan, Yiran Chen, Son Tran, Belinda Zeng, and Trishul Chilimbi. Why do we need large batchsizes in contrastive learning? a gradient- bias perspective. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, page 33860–3...
2022
-
[6]
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, page 1597–1607. PMLR, 2020. URL http: //procee...
2020
-
[7]
Breaking the memory barrier: Near infinite batch size scaling for contrastive loss
Zesen Cheng, Hang Zhang, Kehan Li, Sicong Leng, Zhiqiang Hu, Fei Wu, Deli Zhao, Xin Li, and Lidong Bing. Breaking the memory barrier: Near infinite batch size scaling for contrastive loss. arXiv:2410.17243 [cs], October 2024. URLhttp://arxiv.org/abs/2410.17243
-
[8]
On the properties of neural machine translation: Encoder-decoder approaches
Kyunghyun Cho, Bart van Merrienboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder-decoder approaches. In Dekai Wu, Marine Carpuat, Xavier Carreras, and Eva Maria Vecchi, editors,Proceedings of SSST@EMNLP 10 2014, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 ...
-
[9]
C. Chow. On optimum recognition error and reject tradeoff.IEEE Transactions on Information Theory, 16(1):41–46, 1970. doi: 10.1109/TIT.1970.1054406
-
[10]
A triangle enables multi- modal alignment beyond cosine similarity
Giordano Cicchetti, Eleonora Grassucci, and Danilo Comminiello. A triangle enables multi- modal alignment beyond cosine similarity. InThe Thirty-ninth Annual Conference on Neu- ral Information Processing Systems, 2025. URL https://openreview.net/forum?id= 3Hjfzh5Eyk
2025
-
[11]
Gramian mul- timodal representation learning and alignment
Giordano Cicchetti, Eleonora Grassucci, Luigi Sigillo, and Danilo Comminiello. Gramian mul- timodal representation learning and alignment. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=ftGnpZrW7P
2025
-
[12]
Vision transformers need registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview. net/forum?id=2dnO3LLiJ1
2024
-
[13]
The road less scheduled
Aaron Defazio, Xingyu Yang, Ahmed Khaled, Konstantin Mishchenko, Harsh Mehta, and Ashok Cutkosky. The road less scheduled. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Ad- vances in Neural Information Processing Systems 38: Annual Conference on Neural In- formation Processing S...
2024
-
[14]
BERT: Pre- training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAAC...
-
[15]
Jesse Dodge, Suchin Gururangan, Dallas Card, Roy Schwartz, and Noah A. Smith. Show your work: Improved reporting of experimental results. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro...
-
[16]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, ICLR 2021, V...
2021
-
[17]
What to align in multimodal contrastive learning? InThe Thirteenth International Conference on Learning Representations, 2025
Benoit Dufumier, Javiera Castillo Navarro, Devis Tuia, and Jean-Philippe Thiran. What to align in multimodal contrastive learning? InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=Pe3AxLq6Wf
2025
-
[18]
On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(53):1605–1641, 2010
Ran El-Yaniv and Yair Wiener. On the foundations of noise-free selective classification.Journal of Machine Learning Research, 11(53):1605–1641, 2010
2010
-
[19]
Selectivenet: A deep neural network with an integrated reject option
Yonatan Geifman and Ran El-Yaniv. Selectivenet: A deep neural network with an integrated reject option. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 ofProceedings of Machine Learning Research, page 2151–2159. P...
2019
-
[20]
Imagebind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 15180–15190, June 2023
2023
-
[21]
Understanding the difficulty of training deep feedforward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Yee Whye Teh and Mike Titterington, editors,Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, volume 9 ofProceedings of Machine Learning Research, page 249–256, Chia Laguna Resort, Sardinia, Italy, ...
2010
-
[22]
Dahl, Justin Gilmer, Christopher J
Varun Godbole, George E. Dahl, Justin Gilmer, Christopher J. Shallue, and Zachary Nado. Deep learning tuning playbook, 2023. URL http://github.com/google-research/tuning_ playbook. Version 1.0
2023
-
[24]
Audioclip: Extending clip to image, text and audio
Andrey Guzhov, Federico Raue, Jörn Hees, and Andreas Dengel. Audioclip: Extending clip to image, text and audio. InICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), page 976–980, 2022. doi: 10.1109/ICASSP43922. 2022.9747631
-
[25]
Delving deep into rectifiers: Surpassing human-level performance on imagenet classification
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. InProceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), ICCV ’15, page 1026–1034, USA,
2015
-
[27]
Deep Residual Learning for Image Recognition , isbn =
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, Jun 27-30, 2016, page 770–778. IEEE Computer Society, 2016. doi: 10.1109/CVPR.2016.90. URLhttps://doi.org/10.1109/CVPR.2016.90
-
[28]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[29]
Large Language Models are Powerful Electronic Health Record Encoders
Stefan Hegselmann, Georg von Arnim, Tillmann Rheude, Noel Kronenberg, David Sontag, Gerhard Hindricks, Roland Eils, and Benjamin Wild. Large language models are powerful electronic health record encoders. arXiv:2502.17403 [cs], October 2025. URL http://arxiv. org/abs/2502.17403
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A baseline for detecting misclassified and out-of-distribution examples in neural networks
Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net,
2017
-
[31]
URLhttps://openreview.net/forum?id=Hkg4TI9xl
-
[32]
Geoffrey E. Hinton. Training products of experts by minimizing contrastive divergence.Neural Comput., 14(8):1771–1800, 2002. doi: 10.1162/089976602760128018
-
[33]
Long short-term memory.Neural Computation, 9 (8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9 (8):1735–1780, 1997
1997
-
[34]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
2018
-
[35]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991. doi: 10.1162/neco.1991.3.1. 79. 12
-
[36]
Sarthak Jain and Byron C. Wallace. Attention is not explanation. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), page 3543–3556, Minneapolis, Minnesota, June 2019. As...
-
[37]
Cr-moe: Consistent routed mixture-of-experts for scaling contrastive learning.Transactions on Machine Learning Research, 2024
Ziyu Jiang, Guoqing Zheng, Yu Cheng, Ahmed Hassan Awadallah, and Zhangyang Wang. Cr-moe: Consistent routed mixture-of-experts for scaling contrastive learning.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/ forum?id=qKIvn9xL1R
2024
-
[38]
Michael I. Jordan and Robert A. Jacobs. Hierarchical mixtures of experts and the em algorithm. Neural Computation, 6(2):181–214, 1994. doi: 10.1162/neco.1994.6.2.181
-
[39]
Reasoning models sometimes output illegible chains of thought
Arun Jose. Reasoning models sometimes output illegible chains of thought. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=w1TjXJk846
2025
-
[40]
Pieter-Jan Kindermans, Sara Hooker, Julius Adebayo, Maximilian Alber, Kristof T. Schütt, Sven Dähne, Dumitru Erhan, and Been Kim.The (Un)reliability of Saliency Methods, volume 11700 ofLecture Notes in Computer Science, page 267–280. Springer International Publishing, Cham, 2019. ISBN 978-3-030-28953-9. doi: 10.1007/978-3-030-28954-6_14. URL http: //link....
-
[41]
Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=H1VGkIxRZ
2018
-
[42]
Zachary C. Lipton. The mythos of model interpretability.Commun. ACM, 61(10):36–43, September 2018. ISSN 0001-0782. doi: 10.1145/3233231
-
[43]
Beyond global similarity: Towards fine-grained, multi-condition multimodal retrieval, 2026 c
Xuan Lu, Kangle Li, Haohang Huang, Rui Meng, Wenjun Zeng, and Xiaoyu Shen. Beyond global similarity: Towards fine-grained, multi-condition multimodal retrieval. arXiv:2603.01082 [cs], March 2026. URLhttp://arxiv.org/abs/2603.01082
-
[44]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/ 8a20a8621...
2017
-
[45]
Jian Meng, Li Yang, Jinwoo Shin, Deliang Fan, and Jae-Sun Seo. Contrastive dual gating: Learning sparse features with contrastive learning. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 12247–12255, 2022. doi: 10.1109/CVPR52688. 2022.01194
-
[46]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv:1807.03748 [cs], January 2019. URL http://arxiv.org/abs/ 1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[47]
In: McIlraith, S.A., Weinberger, K.Q
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), April 2018. ISSN 2374-3468, 2159-5399. doi: 10.1609/aaai.v32i1. 11671. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/11671
-
[48]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervi- sion. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machin...
2021
-
[49]
Leveraging cam algorithms for explaining medical semantic segmentation.Machine Learning for Biomedical Imaging, 2(iMIMIC 2023 special issue):2089–2102, 2024
Tillmann Rheude, Andreas Wirtz, Arjan Kuijper, and Stefan Wesarg. Leveraging cam algorithms for explaining medical semantic segmentation.Machine Learning for Biomedical Imaging, 2(iMIMIC 2023 special issue):2089–2102, 2024. ISSN 2766-905X. doi: https://doi.org/10. 59275/j.melba.2024-ebd3
2023
-
[50]
Fusion or Confusion? Multimodal Complexity Is Not All You Need
Tillmann Rheude, Roland Eils, and Benjamin Wild. Fusion or confusion? multimodal complexity is not all you need. arXiv:2512.22991 [cs], December 2025. URL http: //arxiv.org/abs/2512.22991
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Cohort-Based Active Modality Acquisition
Tillmann Rheude, Roland Eils, and Benjamin Wild. Cohort-based active modality acquisition. arXiv:2505.16791 [cs], December 2025. URLhttp://arxiv.org/abs/2505.16791
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nat
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.Nat. Mach. Intell., 1(5):206–215, 2019. doi: 10.1038/ S42256-019-0048-X
2019
-
[53]
Contrasting with symile: Simple model-agnostic representation learning for unlimited modalities
Adriel Saporta, Aahlad Puli, Mark Goldstein, and Rajesh Ranganath. Contrasting with symile: Simple model-agnostic representation learning for unlimited modalities. InAdvances in Neural Information Processing Systems, 2024. URLhttps://arxiv.org/pdf/2411.01053
-
[54]
Scheirer, Anderson de Rezende Rocha, Archana Sapkota, and Terrance E
Walter J. Scheirer, Anderson de Rezende Rocha, Archana Sapkota, and Terrance E. Boult. Toward open set recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(7):1757–1772, 2013. doi: 10.1109/TPAMI.2012.256
-
[55]
When explanations lie: Why many modified bp attributions fail
Leon Sixt, Maximilian Granz, and Tim Landgraf. When explanations lie: Why many modified bp attributions fail. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, page 9046–9057. PMLR, 2020. URL http://proceedings.mlr.press/v119/ sixt20a.html
2020
-
[56]
Prototypical networks for few-shot learning
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/2017/file/ cb8d...
2017
-
[57]
Jakob Steinfeldt, Benjamin Wild, Thore Buergel, Maik Pietzner, Julius Upmeier Zu Belzen, Andre Vauvelle, Stefan Hegselmann, Spiros Denaxas, Harry Hemingway, Claudia Langenberg, Ulf Landmesser, John Deanfield, and Roland Eils. Medical history predicts phenome-wide disease onset and enables the rapid response to emerging health threats.Nature Communications...
-
[58]
Cathie Sudlow, John Gallacher, Naomi Allen, Valerie Beral, Paul Burton, John Danesh, Paul Downey, Paul Elliott, Jane Green, Martin Landray, Bette Liu, Paul Matthews, Giok Ong, Jill Pell, Alan Silman, Alan Young, Tim Sprosen, Tim Peakman, and Rory Collins. Uk biobank: An open access resource for identifying the causes of a wide range of complex diseases of...
-
[59]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, page 3319–3328. PMLR, August 2017. URL https://proceedings.mlr.press/v70/sundararajan17a. html
2017
-
[60]
Garomsa, Anna Zapaishchykova, Tafadzwa L
Divyanshu Tak, Biniam A. Garomsa, Anna Zapaishchykova, Tafadzwa L. Chaunzwa, Juan Car- los Climent Pardo, Zezhong Ye, John Zielke, Yashwanth Ravipati, Suraj Pai, Sri Vajapeyam, Maryam Mahootiha, Mitchell Parker, Luke R. G. Pike, Ceilidh Smith, Ariana M. Familiar, Kevin X. Liu, Sanjay Prabhu, Omar Arnaout, Pratiti Bandopadhayay, Ali Nabavizadeh, Sabine Mue...
-
[61]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and koray kavukcuoglu. Neural discrete representation learning. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/paper/ 2017/f...
2017
-
[62]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference...
2017
-
[63]
Clamr: Contex- tualized late-interaction for multimodal content retrieval
David Wan, Han Wang, Elias Stengel-Eskin, Jaemin Cho, and Mohit Bansal. Clamr: Contex- tualized late-interaction for multimodal content retrieval. arXiv:2506.06144 [cs], June 2025. URLhttp://arxiv.org/abs/2506.06144
-
[64]
Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Zihao Wang, Xihui Liu, Hongsheng Li, Lu Sheng, Junjie Yan, Xiaogang Wang, and Jing Shao. Camp: Cross-modal adaptive message passing for text-image retrieval. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, page 5763–5772. IEEE, 2019. doi: 10.1109/ICCV .2019.00586. URL https://doi...
-
[65]
Information Theoretical Analysis of Multivariate Correlation
Satosi Watanabe. Information theoretical analysis of multivariate correlation.IBM Journal of Research and Development, 4(1):66–82, 1960. doi: 10.1147/rd.41.0066
-
[66]
Attention is not not explanation
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), page 11–20, Hong Kong, China, November 2019. A...
-
[67]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), page 11975–11986, October 2023
2023
-
[68]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv:2506.05176 [cs], June 2025. URLhttp://arxiv.org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Learning deep features for discriminative localization.2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), page 2921–2929, 2015
Bolei Zhou, Aditya Khosla, Àgata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization.2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), page 2921–2929, 2015
2016
-
[71]
uniform" 10optimizer.lr: 11min: 0.00001 12max: 0.01 13distribution:
URLhttps://arxiv.org/abs/2512.12678. 15 A Relation to the Cauchy-Schwarz Bound To quantify the sensitivity of the MIP critic to corruption in a single modality, we compare its score on a clean tuple and on a corrupted tuple and study the score deviation ∆g:=g corr −g clean. This difference isolates the effect of the corruption and admits a simple closed f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.