Recognition: 2 theorem links
· Lean TheoremWeight-Informed Self-Explaining Clustering for Mixed-Type Tabular Data
Pith reviewed 2026-05-10 18:46 UTC · model grok-4.3
The pith
A unified unsupervised pipeline for clustering mixed numerical-categorical data that learns feature weights during grouping and produces matching additive explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By encoding heterogeneous features uniformly via Binary Encoding with Padding, sensing diverse weightings through Leave-One-Feature-Out trials, performing two-stage weight-aware clustering to combine semantic partitions, and applying Discriminative FreqItems to generate explanations with an additive decomposition guarantee, the framework produces clusters of higher quality than classical or neural baselines while ensuring the explanations remain faithful to the primitives that drove the clustering decisions.
What carries the argument
The two-stage weight-aware clustering procedure that aggregates alternative semantic partitions discovered via Leave-One-Feature-Out, paired with Discriminative FreqItems to deliver feature-level explanations that are consistent from instances to clusters.
If this is right
- Clustering quality improves consistently across real mixed-type datasets while computational cost stays comparable to baselines.
- Explanations are generated from the same feature primitives that determine cluster membership, ensuring they reflect the actual decision process.
- The additive property of the explanations allows decomposition of any cluster assignment into per-feature contributions.
- The pipeline remains fully unsupervised and transparent, eliminating the need for separate post-hoc explanation modules.
Where Pith is reading between the lines
- The same weighting and explanation primitives could be tested for stability when the data distribution shifts between training and new observations.
- Because explanations are additive and tied directly to weights, the method might support interactive refinement where a user adjusts a feature weight and immediately sees updated clusters and explanations.
- Extending the leave-one-feature-out view generation to other unsupervised objectives such as density estimation could produce interpretable alternatives to black-box dimensionality reduction on mixed tables.
Load-bearing premise
That leaving one feature out at a time will reliably surface multiple high-quality and diverse weighting views that can be combined unsupervised into partitions whose explanations remain consistent and additive.
What would settle it
If experiments on the six real-world datasets show that clustering quality metrics do not exceed those of the compared baselines or that the generated explanations do not align with the features actually used in the weight-aware assignments, the central claim would be refuted.
Figures




read the original abstract
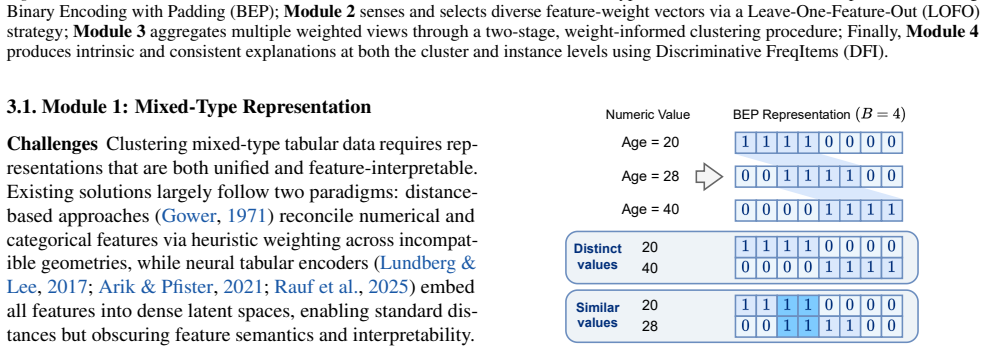
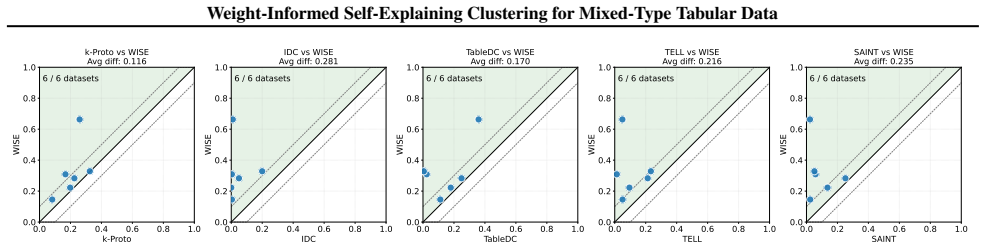
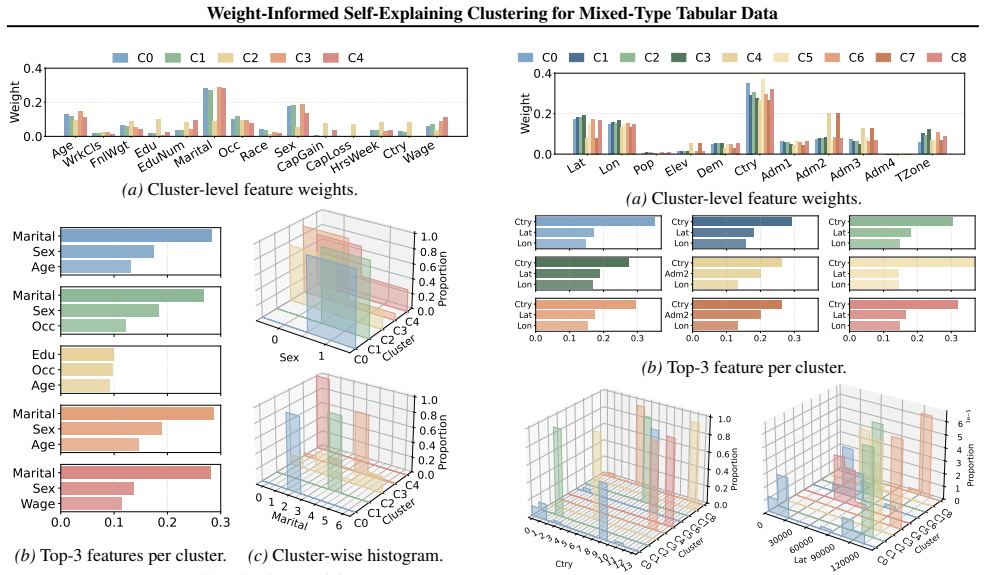
Clustering mixed-type tabular data is fundamental for exploratory analysis, yet remains challenging due to misaligned numerical-categorical representations, uneven and context-dependent feature relevance, and disconnected and post-hoc explanation from the clustering process. We propose WISE, a Weight-Informed Self-Explaining framework that unifies representation, feature weighting, clustering, and interpretation in a fully unsupervised and transparent pipeline. WISE introduces Binary Encoding with Padding (BEP) to align heterogeneous features in a unified sparse space, a Leave-One-Feature-Out (LOFO) strategy to sense multiple high-quality and diverse feature-weighting views, and a two-stage weight-aware clustering procedure to aggregate alternative semantic partitions. To ensure intrinsic interpretability, we further develop Discriminative FreqItems (DFI), which yields feature-level explanations that are consistent from instances to clusters with an additive decomposition guarantee. Extensive experiments on six real-world datasets demonstrate that WISE consistently outperforms classical and neural baselines in clustering quality while remaining efficient, and produces faithful, human-interpretable explanations grounded in the same primitives that drive clustering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WISE, a Weight-Informed Self-Explaining framework for clustering mixed-type tabular data. It introduces Binary Encoding with Padding (BEP) to unify heterogeneous features in a sparse space, a Leave-One-Feature-Out (LOFO) strategy to generate multiple feature-weighting views, a two-stage weight-aware clustering procedure to aggregate alternative semantic partitions, and Discriminative FreqItems (DFI) to produce feature-level explanations that are consistent from instances to clusters with an additive decomposition guarantee. Experiments on six real-world datasets are claimed to show consistent outperformance over classical and neural baselines in clustering quality, efficiency, and faithful human-interpretable explanations grounded in the same primitives as the clustering.
Significance. If the faithfulness and additive decomposition claims hold after the full pipeline, the work would provide a valuable unified unsupervised approach for exploratory analysis of mixed tabular data, addressing the common disconnect between clustering and post-hoc explanations. The introduction of BEP, LOFO, and DFI as integrated components could advance transparent clustering methods if the properties are rigorously established.
major comments (2)
- [DFI description and two-stage clustering procedure] The additive decomposition guarantee for DFI explanations is central to the self-explaining claim, yet the two-stage weight-aware clustering aggregates multiple LOFO-derived views; it is not shown that this aggregation preserves the instance-to-cluster consistency and additive property in a fully unsupervised mixed-type setting where no labels are available to verify faithfulness.
- [Experimental evaluation section] The experimental claims of consistent outperformance rely on six datasets, but the manuscript must provide full details on protocols, baseline implementations (including how classical and neural methods handle mixed types), statistical significance tests, and any hyperparameter or post-hoc choices to allow verification of the clustering quality and explanation results.
minor comments (2)
- [Abstract] The abstract introduces acronyms BEP, LOFO, and DFI without initial expansion, which reduces immediate readability; expand on first use.
- [Method sections on BEP and DFI] Notation for feature weights and frequency items in DFI should be defined more explicitly with respect to the BEP representation to avoid ambiguity in the additive decomposition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [DFI description and two-stage clustering procedure] The additive decomposition guarantee for DFI explanations is central to the self-explaining claim, yet the two-stage weight-aware clustering aggregates multiple LOFO-derived views; it is not shown that this aggregation preserves the instance-to-cluster consistency and additive property in a fully unsupervised mixed-type setting where no labels are available to verify faithfulness.
Authors: We thank the referee for highlighting the need to explicitly connect the two-stage aggregation to the DFI guarantees. The additive decomposition in DFI follows directly from its construction on the final BEP-encoded partition and the frequency-item primitives; it is a structural property of the explanation method that holds independently of how the clusters were obtained and does not require labels. Nevertheless, the manuscript does not contain a formal invariance argument under LOFO-view aggregation. We will add a concise mathematical derivation (new paragraph in Section 4.3) showing that the weighted aggregation of views preserves both instance-to-cluster consistency and additivity, because DFI is applied only after the final partition is formed and operates on the same feature primitives. revision: yes
-
Referee: [Experimental evaluation section] The experimental claims of consistent outperformance rely on six datasets, but the manuscript must provide full details on protocols, baseline implementations (including how classical and neural methods handle mixed types), statistical significance tests, and any hyperparameter or post-hoc choices to allow verification of the clustering quality and explanation results.
Authors: We agree that the current experimental section is insufficiently detailed for full reproducibility. In the revised manuscript we will expand the Experimental Evaluation section to include: complete dataset descriptions and preprocessing pipelines; explicit baseline implementations with mixed-type handling (e.g., one-hot or embedding strategies for neural methods and native mixed-type support for classical methods such as k-prototypes); all hyperparameter values together with selection criteria; the exact statistical tests performed (including test type and p-value reporting); and any post-hoc decisions made when computing or evaluating explanations. We will also release the full source code and experimental scripts as supplementary material. revision: yes
Circularity Check
No circularity: novel components introduced without reduction to fitted inputs or self-citations
full rationale
The paper defines BEP, LOFO, two-stage weight-aware clustering, and DFI as new constructions in a fully unsupervised pipeline. No equations or claims reduce a prediction to a quantity defined by the same fitted parameters, nor does any load-bearing step rely on self-citation chains or imported uniqueness theorems. The additive decomposition guarantee is asserted as a property of the newly developed DFI rather than derived by renaming or fitting from the clustering outputs themselves. Experiments provide external validation on real datasets, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
invented entities (3)
-
Binary Encoding with Padding (BEP)
no independent evidence
-
Leave-One-Feature-Out (LOFO) strategy
no independent evidence
-
Discriminative FreqItems (DFI)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Discriminative FreqItems (DFI) ... yields feature-level explanations that are consistent from instances to clusters with an additive decomposition guarantee.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scalable k-means++.arXiv preprint arXiv:1203.6402,
Bahmani, B., Moseley, B., Vattani, A., Kumar, R., and Vassilvitskii, S. Scalable k-means++.arXiv preprint arXiv:1203.6402,
-
[2]
TabTransformer: Tabular data modeling using contextual embeddings,
Huang, X., Khetan, A., Cvitkovic, M., and Karnin, Z. Tab- transformer: Tabular data modeling using contextual em- beddings.arXiv preprint arXiv:2012.06678,
-
[3]
URL https: //onlinelibrary.wiley.com/doi/abs/10.1002/nav.3800020109
doi: 10.1002/nav.3800020109. Lawless, C., Kalagnanam, J., Nguyen, L. M., Phan, D. T., and Reddy, C. Interpretable clustering via multi-polytope machines. InAAAI, volume 36, pp. 7309–7316,
-
[4]
Lundberg, S. M., Erion, G. G., and Lee, S.-I. Consistent in- dividualized feature attribution for tree ensembles.arXiv preprint arXiv:1802.03888,
-
[5]
URL https://doi.org/ 10.1016/j.dib.2019.104344
1016/j.dib.2019.104344. URL https://doi.org/ 10.1016/j.dib.2019.104344. Parsons, L., Haque, E., and Liu, H. Subspace clustering for high dimensional data: a review.Acm sigkdd explorations newsletter, 6(1):90–105,
-
[6]
SAINT: Improved neural networks for tabular data,
Somepalli, G., Goldblum, M., Schwarzschild, A., Bruss, C. B., and Goldstein, T. Saint: Improved neural networks for tabular data via row attention and contrastive pre- training.arXiv preprint arXiv:2106.01342,
-
[7]
2018 differential privacy synthetic data challenge datasets (match 3: Arizona pums) [dataset]
Urban Institute. 2018 differential privacy synthetic data challenge datasets (match 3: Arizona pums) [dataset]. Urban Data Catalog, 2020a. Urban Institute. 2018 differential privacy synthetic data challenge datasets (match 3: Vermont pums) [dataset]. Urban Data Catalog, 2020b. Vinh, N. X., Epps, J., and Bailey, J. Information theoretic measures for cluste...
2018
-
[8]
Implementation Details A.1
11 Weight-Informed Self-Explaining Clustering for Mixed-Type Tabular Data A. Implementation Details A.1. Binary Encoding with Padding BEP assigns a per-column bit budget B, but the within-column encoding depends on the semantic type of the feature. In particular, we explicitly distinguish ordinal from nominal categorical attributes. Numerical and ordinal ...
2009
-
[9]
local evaluator
to convert Leave-One-Feature-Out (LOFO) prediction models into feature weight vectors. For each target feature xj we construct a LOFO prediction problem with target y←x j and inputs X←X −j. We train a Random Forest (RF) model and view each tree with index u in the ensemble as a “local evaluator” of how other features contribute to predicting xj. We then u...
2017
-
[10]
Mode1”-style center (α= 0 ) and a very sparse “Mode2
P(S) +A(r;S) , enabling the marginal gain ∆Jj(r;S) =J j(S∪ {r})−J j(S) to be computed in O(k) time, hence the greedy process is done inO(k 2)time. A.4. Weightedk-FreqItems From mixed-type tabular data to sparse set dataAfter the BEP procedure, each recode is represented as a high- dimensional sparse binary vector x∈ {0,1} d, or equivalently, a set of acti...
2023
-
[11]
We use the wage attribute as ground truth and discretize it into four classes: 0 ( wage= 0 ), 1 ( 0<wage≤500 ), 2 (500<wage≤1,000), and 3 (wage>1,000)
• Vermont and Arizona:These datasets are drawn from Match 3 of the 2018 Differential Privacy Synthetic Data Challenge, corresponding to US Census Bureau PUMS files for Vermont and Arizona (Urban Institute, 2020b;a). We use the wage attribute as ground truth and discretize it into four classes: 0 ( wage= 0 ), 1 ( 0<wage≤500 ), 2 (500<wage≤1,000), and 3 (wa...
2018
-
[12]
• Credit:We use the UCI Credit Approval dataset (Quinlan, 1987), a mixed-attribute tabular dataset, with the target attributeA16serving as ground truth
Computational EfficiencyTime Total wall-clock time (Seconds) • Obesity:We use the Obesity Levels dataset introduced by Palechor and de la Hoz Manotas (Palechor & De la Hoz Manotas, 2019), which provides seven obesity-level categories as ground-truth labels. • Credit:We use the UCI Credit Approval dataset (Quinlan, 1987), a mixed-attribute tabular dataset,...
2019
-
[13]
Together, these metrics provide complementary perspectives on clustering correctness and label-level consistency
before measuring accuracy. Together, these metrics provide complementary perspectives on clustering correctness and label-level consistency. Intrinsic Structural QualityTo evaluate clustering structure independently of ground-truth labels, we additionally report the Silhouette Coefficient (SWC) (Rousseeuw, 1987), which jointly captures intra-cluster cohes...
1987
-
[14]
WISEWISE consists of (i) mixed-type conversion via BEP, (ii) LOFO-based weight sensing, (iii) two-stage weight-aware clustering, and (iv) DFI-based interpretation. In our implementation, most hyperparameters follow our released code defaults (or the defaults of the underlying libraries), and we report the key representation, sensing, and clustering hyperp...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.