Recognition: no theorem link
A deep learning framework for jointly solving transient Fokker-Planck equations with arbitrary parameters and initial distributions
Pith reviewed 2026-05-10 18:07 UTC · model grok-4.3
The pith
A single deep learning model solves transient Fokker-Planck equations for arbitrary initial distributions, parameters, and times after one training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
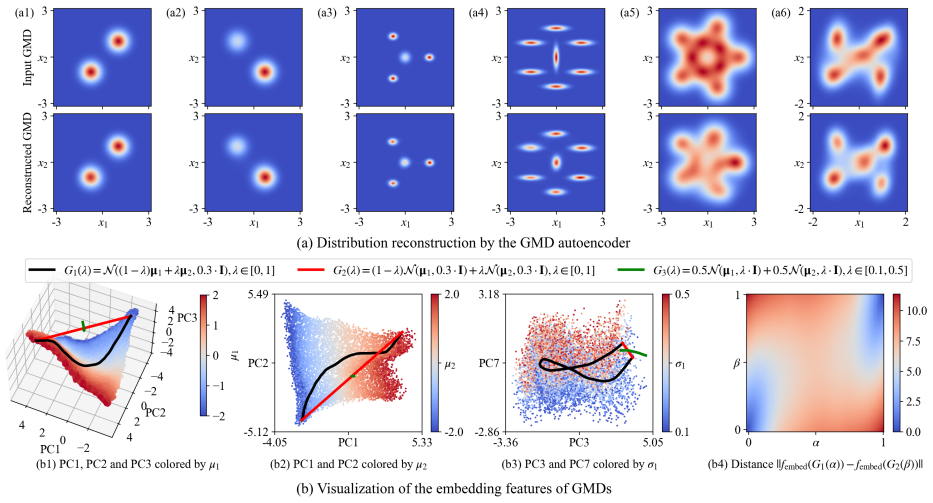
Via a single training process, the pseudo-analytical probability solution simultaneously resolves transient Fokker-Planck equation solutions for arbitrary multi-modal initial distributions, system parameters, and time points. The core idea is to unify initial, transient, and stationary distributions via Gaussian mixture distributions and develop a constraint-preserving autoencoder that bijectively maps constrained GMD parameters to unconstrained, low-dimensional latent representations. In this representation space, the panoramic transient dynamics across varying initial conditions and system parameters can be modeled by a single evolution network.
What carries the argument
The constraint-preserving autoencoder that bijectively maps constrained Gaussian mixture distribution parameters to unconstrained low-dimensional latent representations, allowing one evolution network to model all transient dynamics in a unified latent space.
If this is right
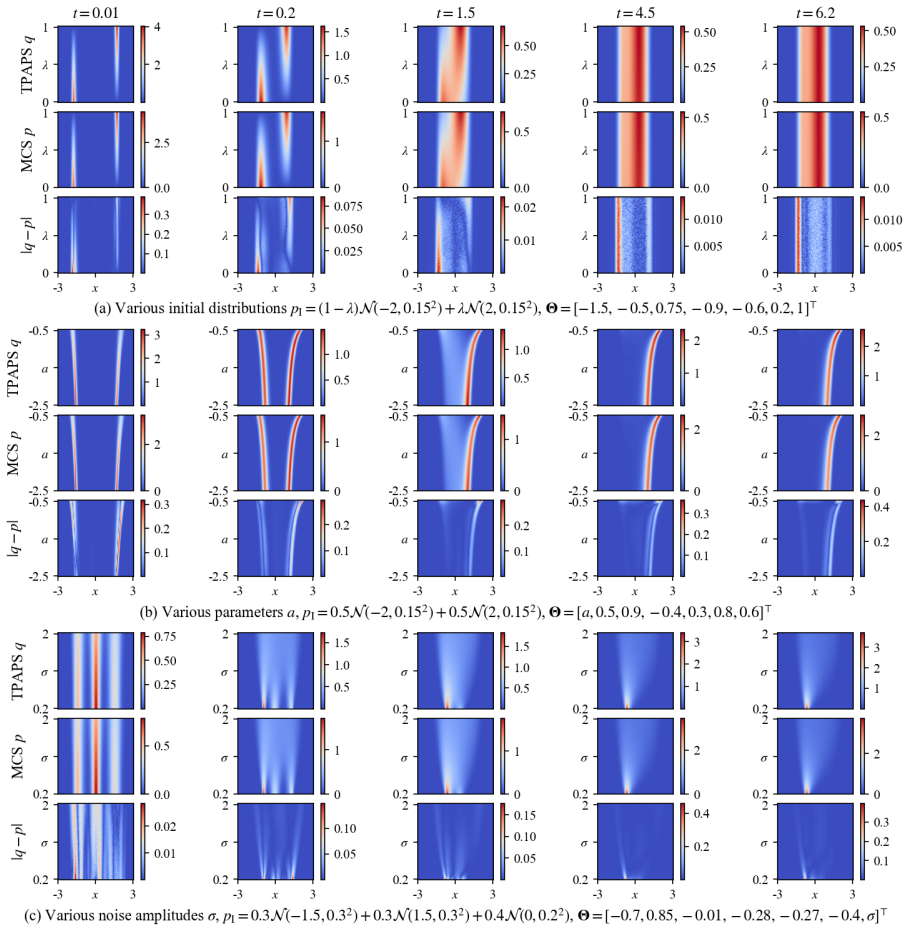
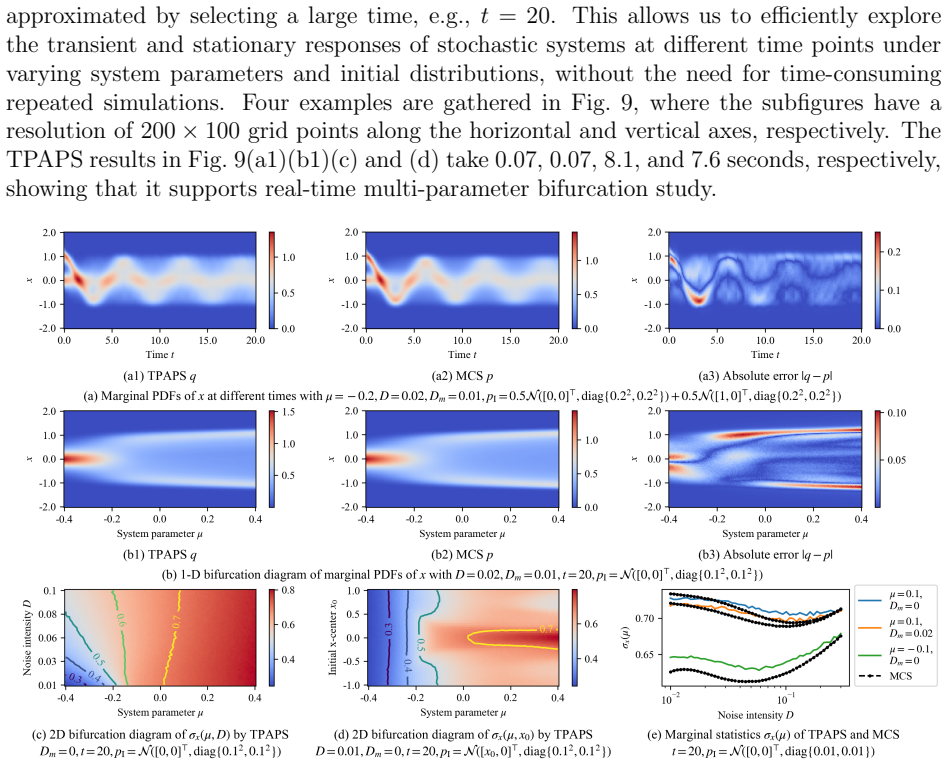
- The framework maintains high accuracy on paradigmatic systems while delivering inference speeds four orders of magnitude faster than GPU-accelerated Monte Carlo simulations.
- It enables real-time parameter sweeps and systematic investigations of stochastic bifurcations that were previously intractable.
- It creates a scalable route for probabilistic modeling of multi-dimensional parameterized stochastic systems by separating representation learning from the transient dynamics.
Where Pith is reading between the lines
- If the latent representation remains compact in higher dimensions, the same structure could be tested on stochastic systems with more variables such as those appearing in chemical reaction networks.
- The clean split between distribution encoding and dynamics learning might allow the evolution network to be trained on simulated data and then used for parameter recovery from measured distributions.
- Analogous autoencoder-plus-evolution pipelines could be applied to other time-dependent equations where the coefficients or source terms vary across runs.
Load-bearing premise
Gaussian mixture distributions plus the bijective autoencoder can faithfully represent every relevant initial, transient, and stationary distribution without loss of accuracy or failure outside the training cases.
What would settle it
Running the trained model on an initial distribution that cannot be well approximated by a small number of Gaussians or on a parameter value well outside the training range and finding large errors in the predicted probability densities would show the claim of arbitrary coverage is not holding.
Figures










read the original abstract
Efficiently solving the Fokker-Planck equation (FPE) is central to analyzing complex parameterized stochastic systems. However, current numerical methods lack parallel computation capabilities across varying conditions, severely limiting comprehensive parameter exploration and transient analysis. This paper introduces a deep learning-based pseudo-analytical probability solution (PAPS) that, via a single training process, simultaneously resolves transient FPE solutions for arbitrary multi-modal initial distributions, system parameters, and time points. The core idea is to unify initial, transient, and stationary distributions via Gaussian mixture distributions (GMDs) and develop a constraint-preserving autoencoder that bijectively maps constrained GMD parameters to unconstrained, low-dimensional latent representations. In this representation space, the panoramic transient dynamics across varying initial conditions and system parameters can be modeled by a single evolution network. Extensive experiments on paradigmatic systems demonstrate that the proposed PAPS maintains high accuracy while achieving inference speeds four orders of magnitude faster than GPU-accelerated Monte Carlo simulations. This efficiency leap enables previously intractable real-time parameter sweeps and systematic investigations of stochastic bifurcations. By decoupling representation learning from physics-informed transient dynamics, our work establishes a scalable paradigm for probabilistic modeling of multi-dimensional, parameterized stochastic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a deep learning framework (PAPS) for jointly solving transient Fokker-Planck equations across arbitrary parameters, multi-modal initial distributions, and time points. It unifies distributions via Gaussian mixture distributions (GMDs), employs a constraint-preserving autoencoder to obtain bijective low-dimensional latent representations, and trains a single evolution network to propagate the dynamics in latent space. Experiments on paradigmatic systems are reported to achieve high accuracy with inference speeds four orders of magnitude faster than GPU-accelerated Monte Carlo simulations.
Significance. If the representation and generalization claims hold, the work would enable previously intractable real-time parameter sweeps and systematic studies of stochastic bifurcations in multi-dimensional systems. The decoupling of representation learning from physics-informed dynamics modeling offers a scalable paradigm that could complement traditional numerical solvers for parameterized stochastic processes.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: the central claim of 'high accuracy' on paradigmatic systems with arbitrary distributions is not supported by quantitative error metrics (e.g., L2 or KL divergence values, maximum pointwise errors) or explicit validation protocols for post-training generalization outside the training distribution of GMD parameters and system parameters.
- [Methods (GMD unification and autoencoder)] Methods (GMD unification and autoencoder): the assumption that a fixed-cardinality Gaussian mixture family plus bijective latent mapping can faithfully represent the full manifold of initial, transient, and stationary densities is load-bearing for the 'arbitrary multi-modal initial distributions' claim, yet no error bounds, reconstruction-failure tests, or analysis for heavy tails, sharp peaks, or emergent modes beyond the chosen component count are provided.
- [Experiments] Experiments: details on the training data generation, the precise number of GMD components and latent dimension used, and how the evolution network was tested for simultaneous resolution across varying parameters and times are insufficient to evaluate whether the single-training-process unification actually generalizes without injected representation error.
minor comments (2)
- [Methods] Clarify the exact values chosen for the free parameters (number of Gaussian components, latent dimension) and any sensitivity analysis performed.
- [Experiments] Add explicit comparison tables or plots with quantitative differences (not just visual overlays) between PAPS solutions and reference Monte Carlo or finite-difference results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas where additional quantitative support and methodological transparency can strengthen the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim of 'high accuracy' on paradigmatic systems with arbitrary distributions is not supported by quantitative error metrics (e.g., L2 or KL divergence values, maximum pointwise errors) or explicit validation protocols for post-training generalization outside the training distribution of GMD parameters and system parameters.
Authors: We agree that the current presentation relies primarily on visual comparisons and qualitative statements of accuracy. While the experiments section includes error visualizations for the reported paradigmatic systems, we did not tabulate aggregate quantitative metrics such as mean L2 norms or KL divergences across test cases, nor did we explicitly describe a held-out validation protocol for GMD parameters and system parameters outside the training ranges. We will add a dedicated subsection and table in the Experiments section reporting these metrics (L2, KL, and max pointwise errors) for both in-distribution and out-of-distribution test sets, along with the precise validation protocol used to assess generalization of the unified model. revision: yes
-
Referee: [Methods (GMD unification and autoencoder)] Methods (GMD unification and autoencoder): the assumption that a fixed-cardinality Gaussian mixture family plus bijective latent mapping can faithfully represent the full manifold of initial, transient, and stationary densities is load-bearing for the 'arbitrary multi-modal initial distributions' claim, yet no error bounds, reconstruction-failure tests, or analysis for heavy tails, sharp peaks, or emergent modes beyond the chosen component count are provided.
Authors: The referee correctly identifies that the fixed-cardinality GMD (5 components) and the bijective autoencoder are central to the unification claim. The manuscript does not supply reconstruction error bounds, systematic failure-case analysis, or explicit tests for heavy-tailed distributions, very sharp peaks, or modes that emerge beyond the chosen component count. We will expand the Methods section with a new paragraph and supplementary figures that report reconstruction errors (L2 and Wasserstein) on both training and held-out GMDs, include targeted tests for sharp-peak and heavy-tail cases, and discuss the practical limitations when the true density lies outside the span of the chosen GMD family. revision: yes
-
Referee: [Experiments] Experiments: details on the training data generation, the precise number of GMD components and latent dimension used, and how the evolution network was tested for simultaneous resolution across varying parameters and times are insufficient to evaluate whether the single-training-process unification actually generalizes without injected representation error.
Authors: We acknowledge that the current Experiments section is concise on these implementation details. The manuscript states the use of 5 GMD components and a latent dimension of 10, but does not fully specify the sampling ranges and generation procedure for the training GMD parameters, nor the exact protocol for testing the evolution network on simultaneous variations of initial distributions, system parameters, and time. We will revise the Experiments section to include: (i) explicit ranges and sampling strategy for means, covariances, and weights; (ii) the total number of training trajectories; and (iii) a clear description of the generalization test protocol, including how representation error is monitored and whether the evolution network was evaluated on parameter-time combinations never seen during training. revision: yes
Circularity Check
No circularity: learned surrogate trained on external data
full rationale
The paper describes a deep-learning surrogate (PAPS) that represents distributions as Gaussian mixtures, encodes them via a constraint-preserving autoencoder into latent space, and evolves the latent dynamics with a single network. This is a modeling and training procedure whose inputs are external simulation trajectories; the output is an approximation learned from those trajectories rather than a mathematical derivation that reduces to its own fitted parameters or self-citations by construction. No equations are presented that equate a claimed prediction to a fitted input, no uniqueness theorem is imported from prior self-work, and the GMD representation is an explicit representational ansatz whose adequacy is left to empirical validation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of Gaussian components in GMD
- Latent dimension of autoencoder
axioms (2)
- domain assumption Gaussian mixture distributions can represent initial, transient, and stationary solutions of the Fokker-Planck equation
- domain assumption The constraint-preserving autoencoder provides a bijective map between constrained GMD parameters and unconstrained latent space
Reference graph
Works this paper leans on
-
[1]
Fisher information and shape-morphing modes for solving the Fokker-Planck equation in higher dimensions.Appl
William Anderson and Mohammad Farazmand. Fisher information and shape-morphing modes for solving the Fokker-Planck equation in higher dimensions.Appl. Math. Com- put., 467:128489, 2024
2024
-
[2]
Pablo Arenas-L´ opez and Mohamed Badaoui
J. Pablo Arenas-L´ opez and Mohamed Badaoui. A Fokker-Planck equation based ap- proach for modelling wind speed and its power output.Energy Convers. Manag., 222:113152, 2020
2020
-
[3]
Attar and Prakash Vedula
Peter J. Attar and Prakash Vedula. Direct quadrature method of moments solution of Fokker-Planck equations in aeroelasticity.AIAA Journal, 47(5):1219–1227, 2009
2009
-
[4]
FlowKac: An efficient neural Fokker-Planck solver using temporal normalizing flows and the Feynman-Kac formula, 2025
Naoufal El Bekri, Lucas Drumetz, and Franck Vermet. FlowKac: An efficient neural Fokker-Planck solver using temporal normalizing flows and the Feynman-Kac formula, 2025
2025
-
[5]
Modeling partially ob- served nonlinear dynamical systems and efficient data assimilation via discrete-time con- ditional Gaussian Koopman network.Comput
Chuanqi Chen, Zhongrui Wang, Nan Chen, and Jin-Long Wu. Modeling partially ob- served nonlinear dynamical systems and efficient data assimilation via discrete-time con- ditional Gaussian Koopman network.Comput. Methods Appl. Mech. Eng., 445:118189, 2025
2025
-
[6]
Parameterized physics-informed neural networks for parameter- ized PDEs
Woojin Cho, Minju Jo, Haksoo Lim, Kookjin Lee, Dongeun Lee, Sanghyun Hong, and Noseong Park. Parameterized physics-informed neural networks for parameter- ized PDEs. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machi...
2024
-
[7]
Coelho, M
C. Coelho, M. Fernanda P. Costa, and L. L. Ferr´ as. Enhancing continuous time series modelling with a latent ode-lstm approach.Appl. Math. Comput., 475:128727, 2024
2024
-
[8]
Brun- ton, and J
Paolo Conti, Jonas Kneifl, Andrea Manzoni, Attilio Frangi, J¨ org Fehr, Steven L. Brun- ton, and J. Nathan Kutz. Veni, vindy, vici: A generative reduced-order modeling framework with uncertainty quantification.Neural Netw., 198:108543, 2026. 39
2026
-
[9]
High-precision magnetic nanoparticle thermometry via analytical solutions of the Fokker-Planck equation.Meas., 265:120326, 2026
Zhongzhou Du, Wenze Zhang, Yi Sun, Na Ye, Yong Gan, Pengchao Wang, Xinwei Zhang, Yuanhao Zhang, Shijie Han, Haochen Zhang, Haozhe Wang, Wenzhong Liu, and Takashi Yoshida. High-precision magnetic nanoparticle thermometry via analytical solutions of the Fokker-Planck equation.Meas., 265:120326, 2026
2026
-
[10]
Multi-Gaussian closure method for randomly excited non-linear systems
Guo-Kang Er. Multi-Gaussian closure method for randomly excited non-linear systems. Int. J. Non-Linear Mech., 33(2):201–214, 1998
1998
-
[11]
Mapping conservative Fokker-Planck entropy in neural systems.J
Erik D Fagerholm, Gregory Scott, Robert Leech, Federico E Turkheimer, Karl J Friston, and Milan Br´ azdil. Mapping conservative Fokker-Planck entropy in neural systems.J. Phys. D: Appl. Phys., 58(14):145401, feb 2025
2025
-
[12]
On latent dy- namics learning in nonlinear reduced order modeling.Neural Netw., 185:107146, 2025
Nicola Farenga, Stefania Fresca, Simone Brivio, and Andrea Manzoni. On latent dy- namics learning in nonlinear reduced order modeling.Neural Netw., 185:107146, 2025
2025
-
[13]
Springer, Heidelberg, Berlin, 2005
Till Daniel Frank.Nonlinear Fokker-Planck Equations: Fundamentals and Applications. Springer, Heidelberg, Berlin, 2005
2005
-
[14]
Georgoulis
Emmanuil H. Georgoulis. Hypocoercivity-compatible finite element methods for the long-time computation of Kolmogorov’s equation.SIAM J. Numer. Anal., 59(1):173– 194, 2021
2021
-
[15]
Parameterized physics-informed neural networks for a transient thermal problem: A pure physics-driven approach.Int
Maysam Gholampour, Zahra Hashemi, Ming Chang Wu, Ting Ya Liu, Chuan Yi Liang, and Chi-Chuan Wang. Parameterized physics-informed neural networks for a transient thermal problem: A pure physics-driven approach.Int. Commun. Heat Mass Transf., 159:108330, 2024
2024
-
[16]
Adaptive deep density approximation for stochastic dynamical systems.J
Junjie He, Qifeng Liao, and Xiaoliang Wan. Adaptive deep density approximation for stochastic dynamical systems.J. Sci. Comput., 102(3):57, 2025
2025
-
[17]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, Las Vegas, NV, USA, 2016. IEEE
2016
-
[18]
Latent neural ODEs with sparse bayesian multiple shooting, 2023
Valerii Iakovlev, Cagatay Yildiz, Markus Heinonen, and Harri L¨ ahdesm¨ aki. Latent neural ODEs with sparse bayesian multiple shooting, 2023
2023
-
[19]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. ADAM: A method for stochastic optimization. In Proceedings of 3rd International Conference on Learning Representations, ICLR 2015, pages 8026–8037, San Diego, CA, USA, 2015. Conference Track Proceedings
2015
-
[20]
Narayanan
Pankaj Kumar and S. Narayanan. Solution of Fokker-Planck equation by finite element and finite difference methods for nonlinear systems.Sadhana - Acad. Proc. Eng. Sci., 31(4):445–461, 2006
2006
-
[21]
Kookjin Lee and Eric J. Parish. Parameterized neural ordinary differential equations: applications to computational physics problems.Proc. R. Soc. A: Math. Phys. Eng. Sci., 477(2253):20210162, 2021. 40
2021
-
[22]
G. M. Leonenko and T. N. Phillips. On the solution of the Fokker-Planck equation using a high-order reduced basis approximation.Comput. Methods Appl. Mech. Eng., 199(1):158–168, 2009
2009
-
[23]
G. M. Leonenko and T. N. Phillips. Numerical approximation of high-dimensional Fokker-Planck equations with polynomial coefficients.J. Comput. Appl. Math., 273:296– 312, 2015
2015
-
[24]
Artificial neural network solver for time-dependent Fokker- Planck equations.Appl
Yao Li and Caleb Meredith. Artificial neural network solver for time-dependent Fokker- Planck equations.Appl. Math. Comput., 457:128185, 2023
2023
-
[25]
Nair, Shivam Barwey, Pinaki Pal, Jonathan F
Ashish S. Nair, Shivam Barwey, Pinaki Pal, Jonathan F. MacArt, Troy Arcomano, and Romit Maulik. Understanding latent timescales in neural ordinary differential equa- tion models of advection-dominated dynamical systems.Phys. D: Nonlinear Phenom., 476:134650, 2025
2025
-
[26]
Evolutionary analysis of Fokker-Planck equation using multi-dimensional finite element method.Procedia Engineering, 199:735–740, 2017
Jiˇ r´ ı N´ aprstek and Radomil Kr´ al. Evolutionary analysis of Fokker-Planck equation using multi-dimensional finite element method.Procedia Engineering, 199:735–740, 2017
2017
-
[27]
Unique analytical scheme for Fokker-Planck equa- tion by the matching polynomials of complete graph.J
AN Nirmala and Kumbinarasaiah S. Unique analytical scheme for Fokker-Planck equa- tion by the matching polynomials of complete graph.J. Comput. Sci., 90:102657, 2025
2025
-
[28]
Springer, Heidelberg, Berlin, 1996
Hannes Risken.The Fokker-Planck Equation: Methods of Solution and Applications. Springer, Heidelberg, Berlin, 1996
1996
-
[29]
Yulia Rubanova, Ricky T. Q. Chen, and David Duvenaud.Latent ODEs for irregularly- sampled time series, pages 5320–5330. Curran Associates Inc., Red Hook, NY, USA, 2019
2019
-
[30]
Numerical solution of nonlinear stochastic processes under Gaussian white noise
Ihsane Salleh, Abdelaziz Ben Lahbib, and Lahcen Azrar. Numerical solution of nonlinear stochastic processes under Gaussian white noise. In2024 World Conference on Complex Systems (WCCS), pages 1–5, 2024
2024
-
[31]
A numerical solver for high dimensional transient Fokker- Planck equation in modeling polymeric fluids.J
Yifei Sun and Mrinal Kumar. A numerical solver for high dimensional transient Fokker- Planck equation in modeling polymeric fluids.J. Comput. Phys., 289:149–168, 2015
2015
-
[32]
Numerical solution of the Fokker-Planck equation using physics-based mixture models.Comput
Armin Tabandeh, Neetesh Sharma, Leandro Iannacone, and Paolo Gardoni. Numerical solution of the Fokker-Planck equation using physics-based mixture models.Comput. Methods Appl. Mech. Eng., 399:115424, 2022
2022
-
[33]
Solving high-dimensional Fokker-Planck equation with functional hierarchical tensor.J
Xun Tang and Lexing Ying. Solving high-dimensional Fokker-Planck equation with functional hierarchical tensor.J. Comput. Phys., 511:113110, 2024
2024
-
[34]
A transfer learning method to solve Fokker-Planck equation based on the equivalent linearization.Chaos, 35(8):083119, 2025
Gege Wang, Xiaolong Wang, Qi Liu, J¨ urgen Kurths, and Yong Xu. A transfer learning method to solve Fokker-Planck equation based on the equivalent linearization.Chaos, 35(8):083119, 2025
2025
-
[35]
Stochastic analysis of a predator- prey model with modified Leslie-Gower and holling type II schemes.Nonlinear Dyn., 101(2):1245–1262, 2020
Shenlong Wang, Zhi Xie, Rui Zhong, and Yanli Wu. Stochastic analysis of a predator- prey model with modified Leslie-Gower and holling type II schemes.Nonlinear Dyn., 101(2):1245–1262, 2020. 41
2020
-
[36]
Tensor neural networks for high-dimensional Fokker-Planck equations.Neural Netw., 185:107165, 2025
Taorui Wang, Zheyuan Hu, Kenji Kawaguchi, Zhongqiang Zhang, and George Em Kar- niadakis. Tensor neural networks for high-dimensional Fokker-Planck equations.Neural Netw., 185:107165, 2025
2025
-
[37]
A novel method for response prob- ability density of nonlinear stochastic dynamic systems.Nonlinear Dyn., 113(5):3981– 3997, 2025
Xi Wang, Jun Jiang, Ling Hong, and Jian-Qiao Sun. A novel method for response prob- ability density of nonlinear stochastic dynamic systems.Nonlinear Dyn., 113(5):3981– 3997, 2025
2025
-
[38]
The pseudo-analytical probability solution to parameterized Fokker-Planck equations via deep learning.En- gineering Applications of Artificial Intelligence, 157:111344, 2025
Xiaolong Wang, Jing Feng, Gege Wang, Tong Li, and Yong Xu. The pseudo-analytical probability solution to parameterized Fokker-Planck equations via deep learning.En- gineering Applications of Artificial Intelligence, 157:111344, 2025
2025
-
[39]
Deep learning-based state prediction of the Lorenz system with control parameters.Chaos, 34(3):033108, 2024
Xiaolong Wang, Jing Feng, Yong Xu, and J¨ urgen Kurths. Deep learning-based state prediction of the Lorenz system with control parameters.Chaos, 34(3):033108, 2024
2024
-
[40]
Adaptive normalizing flows for solving Fokker-Planck equation.Chaos, 35(8):083116, 2025
Wanting Xu, Jinqian Feng, Jin Su, Qin Guo, and Youpan Han. Adaptive normalizing flows for solving Fokker-Planck equation.Chaos, 35(8):083116, 2025
2025
-
[41]
Stochastic bifurcations in a bistable Duffing-Van der Pol oscillator with colored noise.Phys
Yong Xu, Rencai Gu, Huiqing Zhang, Wei Xu, and Jinqiao Duan. Stochastic bifurcations in a bistable Duffing-Van der Pol oscillator with colored noise.Phys. Rev. E, 83:056215, May 2011
2011
-
[42]
Solving Fokker-Planck equation using deep learning.Chaos, 30(1):013133, 2020
Yong Xu, Hao Zhang, Yongge Li, Kuang Zhou, Qi Liu, and J¨ urgen Kurths. Solving Fokker-Planck equation using deep learning.Chaos, 30(1):013133, 2020
2020
-
[43]
Structure preserving stochastic Galerkin methods for Fokker-Planck equations with background interactions.Math
Mattia Zanella. Structure preserving stochastic Galerkin methods for Fokker-Planck equations with background interactions.Math. Comput. Simul., 168:28–47, 2020
2020
-
[44]
Deep learning framework for solving Fokker-Planck equations with low-rank separation representation.Eng
Hao Zhang, Yong Xu, Qi Liu, and Yongge Li. Deep learning framework for solving Fokker-Planck equations with low-rank separation representation.Eng. Appl. Artif. Intell., 121:106036, 2023
2023
-
[45]
Solving Fokker- Planck equations using deep KD-tree with a small amount of data.Nonlinear Dyn., 108(4):4029–4043, 2022
Hao Zhang, Yong Xu, Qi Liu, Xiaolong Wang, and Yongge Li. Solving Fokker- Planck equations using deep KD-tree with a small amount of data.Nonlinear Dyn., 108(4):4029–4043, 2022
2022
-
[46]
Solving Fokker-Planck- Kolmogorov equation by distribution self-adaptation normalized physics-informed neu- ral networks.Physica A, 684:131251, 2026
Yi Zhang, Yiting Duan, Xiangjun Wang, and Zhikun Zhang. Solving Fokker-Planck- Kolmogorov equation by distribution self-adaptation normalized physics-informed neu- ral networks.Physica A, 684:131251, 2026. 42
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.