Recognition: 2 theorem links
· Lean TheoremPixel-Translation-Equivariant Quantum Convolutional Neural Networks via Fourier Multiplexers
Pith reviewed 2026-05-10 19:16 UTC · model grok-4.3
The pith
Conjugation by the quantum Fourier transform diagonalizes pixel shifts, so every translation-equivariant quantum CNN layer reduces to a Fourier-mode multiplexer followed by its inverse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Conjugation by the quantum Fourier transform diagonalizes translations, therefore any unitary commuting with the pixel cyclic shift operator is realized by applying a product of independent unitaries to the Fourier modes and then applying the inverse transform.
What carries the argument
The Fourier-mode multiplexer: after the quantum Fourier transform conjugates the shift operator to a diagonal phase operator, the multiplexer applies an arbitrary unitary independently to each eigenmode before the inverse transform restores the original basis.
If this is right
- Deep PCS-QCNN architectures can be assembled using measurement-induced pooling and deferred conditioning.
- Inter-layer cancellation of the quantum Fourier transform reduces total circuit depth.
- The expected squared gradient norm remains bounded below by a positive constant independent of depth at random initialization.
Where Pith is reading between the lines
- The same diagonalization technique could be applied to other group symmetries by replacing the Fourier transform with the appropriate representation-theoretic transform.
- Because the construction separates frequency modes explicitly, it may allow selective regularization or pruning of high-frequency components during training.
- The absence of a depth-induced barren plateau in this regime suggests that scaling the network width rather than depth may be the more immediate bottleneck for expressivity.
Load-bearing premise
The data encoding produces an exact cyclic shift symmetry on the index register that every layer must preserve without approximation.
What would settle it
A direct matrix calculation on a two-qubit register showing that a constructed layer fails to commute with the shift operator, or a numerical sampling of the gradient variance at initialization that drops exponentially with added layers.
Figures




read the original abstract
Convolutional neural networks owe much of their success to hard-coding translation equivariance. Quantum convolutional neural networks (QCNNs) have been proposed as near-term quantum analogues, but the relevant notion of translation depends on the data encoding. For address/amplitude encodings such as FRQI, a pixel shift acts as modular addition on an index register, whereas many MERA-inspired QCNNs are equivariant only under cyclic permutations of physical qubits. We formalize this mismatch and construct QCNN layers that commute exactly with the pixel cyclic shift (PCS) symmetry induced by the encoding. Our main technical result is a constructive characterization of all PCS-equivariant unitaries: conjugation by the quantum Fourier transform (QFT) diagonalizes translations, so any PCS-equivariant layer is a Fourier-mode multiplexer followed by an inverse QFT (IQFT). Building on this characterization, we introduce a deep PCS-QCNN with measurement-induced pooling, deferred conditioning, and inter-layer QFT cancellation. We also analyze trainability at random initialization and prove a lower bound on the expected squared gradient norm that remains constant in a depth-scaling regime, ruling out a depth-induced barren plateau in that sense.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the mismatch between pixel cyclic shift (PCS) symmetry induced by address/amplitude encodings (e.g., FRQI) and standard qubit-permutation equivariance in QCNNs. It gives a constructive characterization of all PCS-equivariant unitaries: any such unitary is a QFT, followed by a Fourier-mode multiplexer, followed by an IQFT. Building on this, the authors construct a deep PCS-QCNN architecture that incorporates measurement-induced pooling with deferred conditioning and inter-layer QFT cancellation. They additionally prove a lower bound on the expected squared gradient norm at random initialization that remains constant with depth in a specified scaling regime, indicating the absence of a depth-induced barren plateau.
Significance. If the characterization and the extension to the full architecture hold, the work supplies a symmetry-principled design rule for QCNNs that respects the translation symmetry native to common quantum image encodings. The constructive nature of the unitary characterization (leveraging the diagonalizing action of the QFT on cyclic shifts) and the explicit gradient-norm lower bound are clear strengths that could guide future equivariant quantum models. These elements address both architectural consistency and trainability, which are central concerns for near-term quantum machine learning on structured data.
major comments (1)
- [§4.2] §4.2 (Measurement-Induced Pooling and Deferred Conditioning): The unitary characterization (Theorem 1) is internally consistent, but the central claim that the end-to-end PCS-QCNN remains equivariant requires an explicit argument that the non-unitary pooling step preserves the symmetry—i.e., that a PCS on the input produces a correspondingly shifted output distribution after measurement and conditioning. The manuscript invokes inter-layer QFT cancellation but does not supply a self-contained lemma or calculation showing commutation for the chosen measurement basis; this step is load-bearing for the deep-architecture claim.
minor comments (2)
- [§3.1] The definition of the 'Fourier-mode multiplexer' is introduced conceptually but would benefit from an explicit operator equation (e.g., as a diagonal gate in the Fourier basis with mode-dependent phases) to make the construction fully reproducible from the text.
- [§5] In the gradient analysis, the precise depth-scaling regime (number of layers relative to qubit count, and whether measurements are included in the random-initialization ensemble) should be stated more explicitly to allow direct verification of the constant lower bound.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for identifying a point that requires clarification to fully substantiate the end-to-end equivariance claim. We address the major comment below and have revised the manuscript to incorporate an explicit supporting argument.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Measurement-Induced Pooling and Deferred Conditioning): The unitary characterization (Theorem 1) is internally consistent, but the central claim that the end-to-end PCS-QCNN remains equivariant requires an explicit argument that the non-unitary pooling step preserves the symmetry—i.e., that a PCS on the input produces a correspondingly shifted output distribution after measurement and conditioning. The manuscript invokes inter-layer QFT cancellation but does not supply a self-contained lemma or calculation showing commutation for the chosen measurement basis; this step is load-bearing for the deep-architecture claim.
Authors: We agree that the equivariance of the full architecture, including the non-unitary measurement-induced pooling, requires an explicit verification beyond the unitary characterization in Theorem 1. In the revised manuscript we have added a self-contained Lemma 2 in §4.2 that directly addresses this gap. The lemma shows that, for the computational-basis measurement performed after the final IQFT and under the deferred-conditioning protocol, a PCS applied to the input state produces a correspondingly shifted distribution over the measured outcomes. The argument proceeds by (i) using the fact that the preceding Fourier-mode multiplexer is diagonal in the QFT basis, (ii) verifying that the inter-layer QFT/IQFT cancellation restores the computational-basis measurement to a PCS-equivariant operation, and (iii) confirming that the classical conditioning step, which depends only on the measured index, commutes with the residual shift. We have also updated the surrounding discussion in §4.2 and the architecture overview to reference Lemma 2 when asserting end-to-end PCS equivariance. This addition makes the load-bearing step fully rigorous while preserving the original construction. revision: yes
Circularity Check
No circularity: central characterization follows from standard QFT diagonalization of cyclic shifts
full rationale
The paper's main technical result is a constructive characterization of PCS-equivariant unitaries via QFT conjugation and Fourier-mode multiplexing. This is a direct application of the known fact that the quantum Fourier transform diagonalizes the cyclic shift operator on the index register (a standard result in quantum computing and group Fourier analysis, not derived from or fitted to the paper's own data or definitions). The subsequent construction of the deep PCS-QCNN (including measurement-induced pooling and inter-layer QFT cancellation) and the proof of the constant lower bound on expected squared gradient norm are presented as explicit derivations and proofs without reducing any claimed prediction or equivariance property to a fitted parameter, self-definition, or load-bearing self-citation. The end-to-end equivariance extension is claimed via the unitary characterization plus additional architectural choices, but does not collapse by construction to the inputs. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Address/amplitude encodings such as FRQI induce modular addition (pixel cyclic shift) on the index register.
- standard math The quantum Fourier transform diagonalizes the cyclic shift operator.
invented entities (1)
-
Fourier-mode multiplexer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Fourier-multiplexer form of PCS-equivariant unitaries). ... U = (F†_N ⊗ I) B (F_N ⊗ I), where B is block-diagonal in the Fourier basis
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_eq_pow unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The shift operator T is diagonal in the Fourier basis: F_N T F†_N = diag(ω^k)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
These histograms use the same trained model
and for several shot budgets. These histograms use the same trained model. For each epoch and shot budget, the 10,000-sample test set is split into 40 nonoverlapping batches of 250 images; each finite-shot histogram entry is one batch-mean cross-entropy under one of 100 indepen- dent resampling passes, giving 40×100 = 4000 entries per shot budget. The inf...
-
[2]
LeCun, B
Y. LeCun, B. E. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, Neural Compu- tation1, 541 (1989)
1989
-
[3]
Goodfellow, Y
I. Goodfellow, Y. Bengio, and A. Courville,Deep Learn- ing(MIT Press, 2016)
2016
-
[4]
Preskill, Quantum2, 79 (2018)
J. Preskill, Quantum2, 79 (2018)
2018
-
[5]
Vidal, Physical Review Letters99, 220405 (2007)
G. Vidal, Physical Review Letters99, 220405 (2007)
2007
-
[6]
I. Cong, S. Choi, and M. D. Lukin, Nature Physics15, 1273 (2019)
2019
-
[7]
S. Oh, J. Choi, J. K. Kim, and J. Kim, inProceedings of the 2021 International Conference on Information Net- working (ICOIN)(IEEE, 2021) pp. 50–52
2021
-
[8]
Y. Jing, X. Li, Y. Yang, C. Wu, W. Fu, W. Hu, Y. Li, and H. Xu, Quantum Information Processing21, 101 (2022)
2022
-
[9]
Huang, W.-J
S.-Y. Huang, W.-J. An, D.-S. Zhang, and N.-R. Zhou, Optics Communications533, 129287 (2023)
2023
-
[10]
Wei, Y.-H
S.-J. Wei, Y.-H. Chen, Z.-R. Zhou, and G.-L. Long, APL Photonics7, 056103 (2022)
2022
-
[11]
Li, R.-G
Y. Li, R.-G. Zhou, R. Xu, J. Luo, and W. Hu, Quantum Science and Technology5, 044003 (2020)
2020
-
[12]
Li, P.-C
W. Li, P.-C. Chu, G.-Z. Liu, Y.-B. Tian, T.-H. Qiu, and S.-M. Wang, Quantum Engineering2022, 5701479 (2022)
2022
-
[13]
Easom-McCaldin, A
P. Easom-McCaldin, A. Bouridane, A. Belatreche, and R. Jiang, IEEE Access9, 65127 (2021)
2021
-
[14]
Das and F
S. Das and F. Caruso, Quantum Science and Technology 10, 015030 (2024)
2024
-
[15]
Larocca, F
M. Larocca, F. Sauvage, F. M. Sbahi, G. Verdon, P. J. Coles, and M. Cerezo, PRX Quantum3, 030341 (2022)
2022
-
[16]
J. J. Meyer, M. Mularski, E. Gil-Fuster, A. A. Mele, F. Arzani, A. Wilms, and J. Eisert, PRX Quantum4, 010328 (2023)
2023
-
[17]
Schatzki, M
L. Schatzki, M. Larocca, Q. T. Nguyen, F. Sauvage, and M. Cerezo, npj Quantum Information10, 12 (2024)
2024
-
[18]
Chinzei, Q
K. Chinzei, Q. H. Tran, K. Maruyama, H. Oshima, and S. Sato, Physical Review Research6, 023042 (2024). 17
2024
-
[19]
P. Q. Le, F. Dong, and K. Hirota, Quantum Information Processing10, 63 (2011)
2011
-
[20]
Zhang, K
Y. Zhang, K. Lu, Y. Gao, and M. Wang, Quantum In- formation Processing12, 2833 (2013)
2013
-
[21]
Gong, J.-J
L.-H. Gong, J.-J. Pei, T.-F. Zhang, and N.-R. Zhou, Op- tics Communications550, 129993 (2024)
2024
-
[22]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, Nature Communications9, 4812 (2018)
2018
-
[23]
Pesah, M
A. Pesah, M. Cerezo, S. Wang, T. Volkoff, A. T. Sorn- borger, and P. J. Coles, Physical Review X11, 041011 (2021)
2021
-
[24]
R. M. Gray, Foundations and Trends in Communications and Information Theory2, 155 (2006)
2006
-
[25]
G. H. Golub and C. F. Van Loan,Matrix Computations, 4th ed. (Johns Hopkins University Press, 2013)
2013
-
[26]
Y. L¨ u, Q. Gao, J. L¨ u, M. Ogorza lek, and J. Zheng, inPro- ceedings of the 40th Chinese Control Conference (CCC) (IEEE, 2021) pp. 6329–6334
2021
-
[27]
M. A. Nielsen and I. L. Chuang,Quantum Computa- tion and Quantum Information: 10th Anniversary Edi- tion(Cambridge University Press, Cambridge, 2010)
2010
-
[28]
Cleve and J
R. Cleve and J. Watrous, inProceedings of the 41st An- nual Symposium on Foundations of Computer Science (IEEE, 2000) pp. 526–536
2000
-
[29]
Bergholm, J
V. Bergholm, J. J. Vartiainen, M. M¨ ott¨ onen, and M. M. Salomaa, Physical Review A71, 052330 (2005)
2005
-
[30]
V. V. Shende, S. S. Bullock, and I. L. Markov, IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems25, 1000 (2006)
2006
-
[31]
LeCun, C
Y. LeCun, C. Cortes, and C. J. C. Burges, MNIST hand- written digit database,http://yann.lecun.com/exdb/ mnist/(2010), accessed 2026-04-23
2010
-
[32]
Schuld and N
M. Schuld and N. Killoran, PRX Quantum3, 030101 (2022)
2022
-
[33]
Cerezo, G
M. Cerezo, G. Verdon, H.-Y. Huang, L. Cincio, and P. J. Coles, Nature Computational Science2, 567 (2022)
2022
-
[34]
Khoshaman, W
A. Khoshaman, W. Vinci, B. Denis, E. Andriyash, H. Sadeghi, and M. H. Amin, Quantum Science and Tech- nology4, 014001 (2018)
2018
-
[35]
I. V. Oseledets, SIAM Journal on Scientific Computing 33, 2295 (2011)
2011
-
[36]
D. Chirkov and I. Lobanov, Pixel-Translation- Equivariant Quantum Convolutional Neural Net- works via Fourier Multiplexers, Zenodo (2026), DOI: 10.5281/zenodo.19814130
- [37]
-
[38]
D. Mattern, D. Martyniuk, H. Willems, F. Bergmann, and A. Paschke, Variational quanvolutional neu- ral networks with enhanced image encoding (2021), arXiv:2106.07327 [cs.CV]
-
[39]
Huggins, P
W. Huggins, P. Patil, B. Mitchell, K. B. Whaley, and E. M. Stoudenmire, Quantum Science and Technology4, 024001 (2019)
2019
-
[40]
Zheng, Q
J. Zheng, Q. Gao, J. L¨ u, M. Ogorza lek, Y. Pan, and Y. L¨ u, Journal of the Franklin Institute360, 13761 (2023)
2023
-
[41]
T. Hur, L. Kim, and D. K. Park, Quantum Machine In- telligence4, 3 (2022)
2022
-
[42]
Huang, X
F. Huang, X. Tan, R. Huang, and Q. Xu, Physica A: Statistical Mechanics and its Applications605, 128067 (2022)
2022
-
[43]
B. Bamieh, Discovering transforms: A tutorial on cir- culant matrices, circular convolution, and the discrete fourier transform (2022), arXiv:1805.05533 [eess.SP]
- [44]
-
[45]
Lahoti, S
A. Lahoti, S. Karp, E. Winston, A. Singh, and Y. Li, inProceedings of the 12th International Conference on Learning Representations (ICLR)(2024)
2024
-
[46]
D. Coppersmith, An approximate fourier transform use- ful in quantum factoring (2002), arXiv:quant-ph/0201067 [quant-ph]. 18 Supplemental Material for “Pixel-Translation-Equivariant Quantum Convolutional Neural Networks via Fourier Multiplexers” This document includes a literature table for QCNN-style MNIST results (Sec. A), additional experiments and ana...
-
[47]
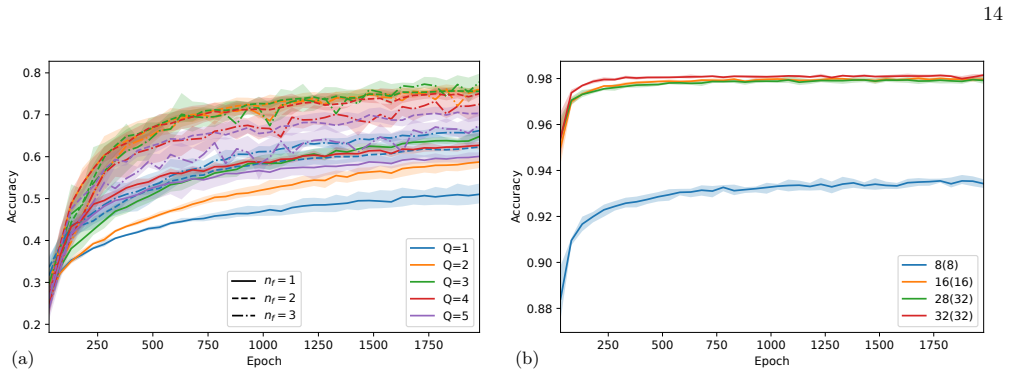
Hyperparameter sweep and parameter accounting The experiments reported here use two sweep families. Figure 5(a) is a translated-MNIST architecture sweep with digits resized to 16×16, placed on a 32×32 canvas, translated by at most 8 pixels along each axis, evaluated with full readout, and trained for 2000 epochs over 3 seeds, withQ∈ {1,2,3,4,5}andn f ∈ {1...
2000
-
[48]
The article-wide convention (a, b) = (0, π) was chosen a priori as a one-period real FRQI color-map convention and was not selected by optimizing this sweep
Brightness-range sensitivity sweep for encoder scaling Besides the main translated-MNIST architecture sweep and the full-MNIST size sweep, we ran a separate low-data sensitivity sweep for the encoder angle scale. The article-wide convention (a, b) = (0, π) was chosen a priori as a one-period real FRQI color-map convention and was not selected by optimizin...
-
[49]
2(a) are specified here for reproducibility (text Secs
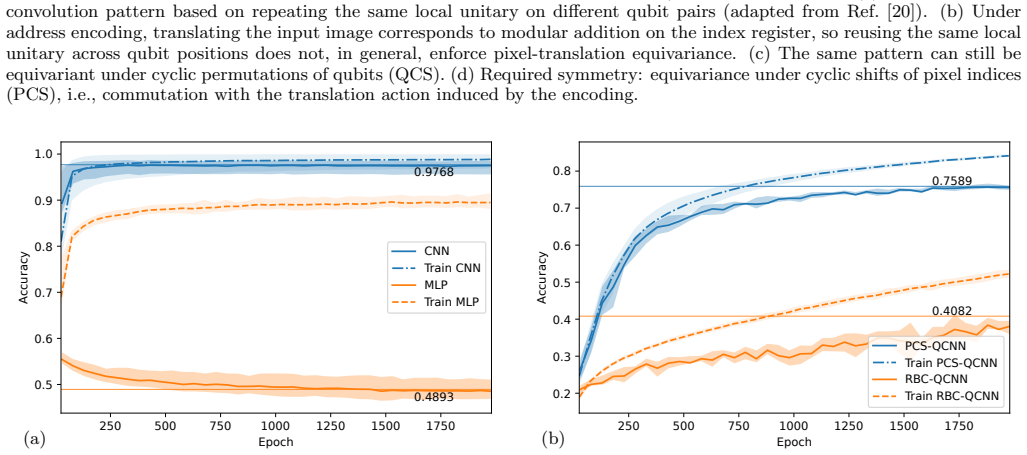
Classical baseline architectures for benchmark comparisons The classical reference models used in Fig. 2(a) are specified here for reproducibility (text Secs. V F and VI C). For the CNN baseline (Fig. S2(a)), the input is a 32×32 grayscale canvas produced by the shared preprocessing protocol. In Fig. 2(a), this architecture is evaluated on the translated ...
-
[50]
The model architectures were kept identical to those specified in Sec
Full-MNIST classical control without translations The same CNN and MLP baselines were also evaluated on the full standard MNIST split (60,000 training images and 10,000 test images) after resizing each digit directly to a 32×32 grayscale image, with no canvas translation. The model architectures were kept identical to those specified in Sec. B 3, so the c...
-
[51]
6, distinguishing the norm of the empirical-loss gradient from the per-sample RMS gradient norm
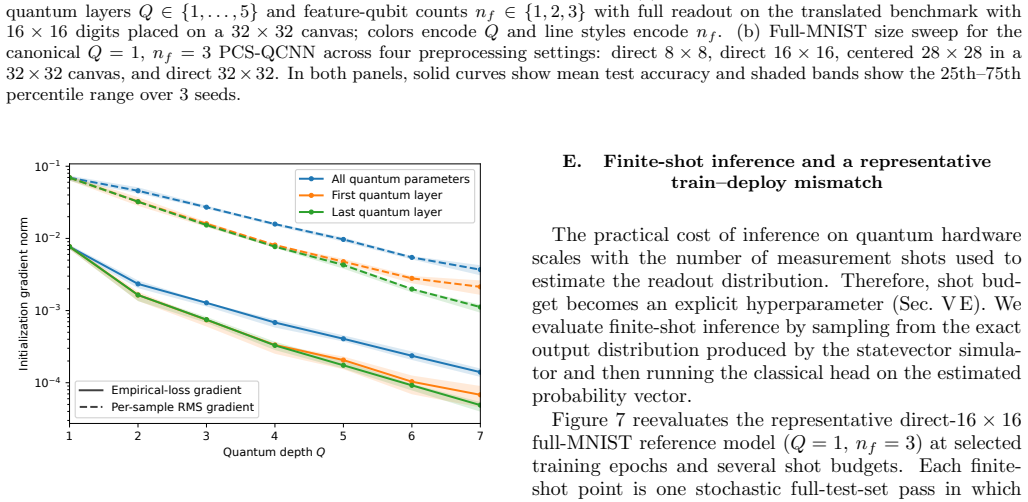
Readout entropy diagnostic The main text reports initialization-time quantum-gradient diagnostics in Fig. 6, distinguishing the norm of the empirical-loss gradient from the per-sample RMS gradient norm. The readout entropy diagnostic below checks how finite-shot sampling changes the classifier input. Figure S4 shows the Shannon entropy of the full readout...
2000
-
[52]
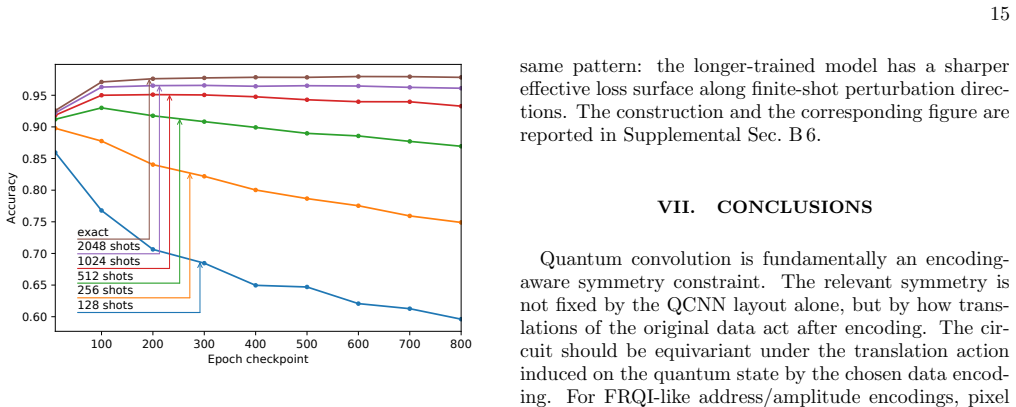
Geometric interpretation: local loss landscape in readout space The loss-landscape diagnostic probes the classical head under finite-shot perturbations expected from the multi- nomial readout model. Figure S5 uses the representative direct-16×16 full-MNIST reference PCS-QCNN after 100 and 800 training epochs, shot budgetN= 128, and an 81×81 grid of coordi...
2000
-
[53]
Qualitative error structure Figure S6 reports the remaining classification errors for the representative final direct-16×16 full-MNIST reference model after 2000 training epochs (confusion matrix and examples of misclassified digits). These errors are not dominated by a single failure mode; rather, they reflect the expected ambiguity between visually simi...
2000
-
[54]
In many spatial problems, the same local pattern is applied at every position: each output feature at locationkdepends on inputs in the same relative way at any location
Classical convolution and translation symmetry A classical feedforward network is a composition of layers of the formz=f(Ax), whereAis a linear operator andf is a non-linear activation. In many spatial problems, the same local pattern is applied at every position: each output feature at locationkdepends on inputs in the same relative way at any location. ...
-
[55]
[5] and used in several subsequent works
MERA-QCNN as a QCS-equivariant architecture Figure 1(a) shows a MERA-inspired QCNN, originally proposed in Ref. [5] and used in several subsequent works. The architecture consists of repeated local unitaries arranged in a multiscale pattern, interleaved with pooling that reduces the number of active qubits, typically implemented by measurements followed b...
-
[56]
Fourier cancellation at the interface of PCS-QCNN layers Figure 3 shows that consecutive PCS layers contain adjacent inverse and forward Fourier transforms on the index registers. In our architecture the pooling step is implemented after the inverse QFT of a layer: in the computational index basis we split the fine index asr= 2q+s, measure the parity bits...
-
[57]
We begin with the qubit count
Complexity analysis In the NISQ regime it is important to keep both qubit requirements and circuit depth in view. We begin with the qubit count. For anN×Nimage withN= 2 nidx, address encoding uses two index registers withn idx = log 2 N 32 qubits each. In addition, we use a feature register of sizen f qubits, with the grayscale/color qubit included inn f ...
-
[58]
Each axis initially hasn idx qubits
PCS-QCNN family and parameter count We work with an index register consisting ofdspatial axes. Each axis initially hasn idx qubits. A depth-QPCS- QCNN pools after the firstQ−1 layers, each time measuring and discarding one computational-index qubit per axis. After pooling, the remaining index register has nl :=n idx −Q+ 1 (S11) qubits per axis, hence Didx...
-
[59]
For head input dimensionD out, this means Waz ∼Unif −D−1/2 out , D−1/2 out , b a ∼Unif −D−1/2 out , D−1/2 out , a∈[M], z∈[D out],(S33) independently over all entries
Aggregate gradient-energy estimate The benchmark initialization samples every quantum Pauli coefficient independently as θ(ℓ) k,m,α ∼Unif(0,2π).(S32) Independently, the classical head uses fan-in uniform initialization. For head input dimensionD out, this means Waz ∼Unif −D−1/2 out , D−1/2 out , b a ∼Unif −D−1/2 out , D−1/2 out , a∈[M], z∈[D out],(S33) in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.