Recognition: 2 theorem links
· Lean TheoremLimits of Difficulty Scaling: Hard Samples Yield Diminishing Returns in GRPO-Tuned SLMs
Pith reviewed 2026-05-10 19:36 UTC · model grok-4.3
The pith
GRPO training on lower-difficulty math problems achieves full-dataset accuracy with only 45% of the training steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
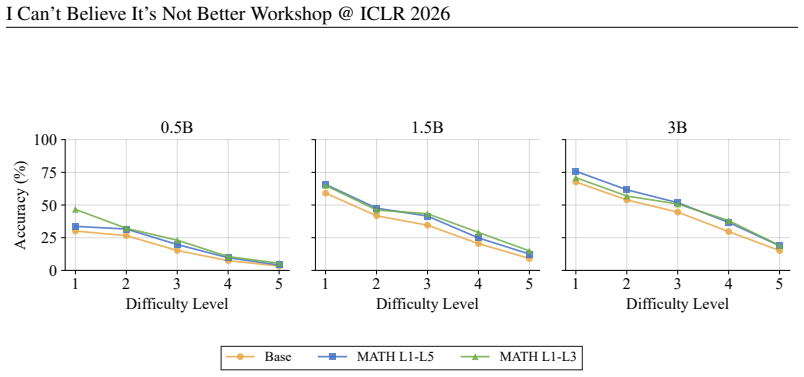
As problem difficulty increases, GRPO-tuned SLM accuracy plateaus, revealing a capacity boundary where the method primarily reshapes output preferences without reliably improving performance on the hardest tier. Training GRPO only on lower-difficulty problems matches full-dataset accuracy across difficulty tiers while using only about 45% training steps, and GSM8K-trained models outperform MATH-trained ones on the numeric subset of MATH by 3-5%. Best gains depend on the base model's prior reasoning competence and the dataset's difficulty profile.
What carries the argument
Difficulty-stratified analysis combined with controlled subset training experiments on GRPO with LoRA, showing equivalence between partial and full data regimes.
If this is right
- GRPO does not expand the model's fundamental capacity to solve problems beyond a certain difficulty threshold.
- Subset training on lower difficulty problems is sufficient to reach peak performance achievable by the full set.
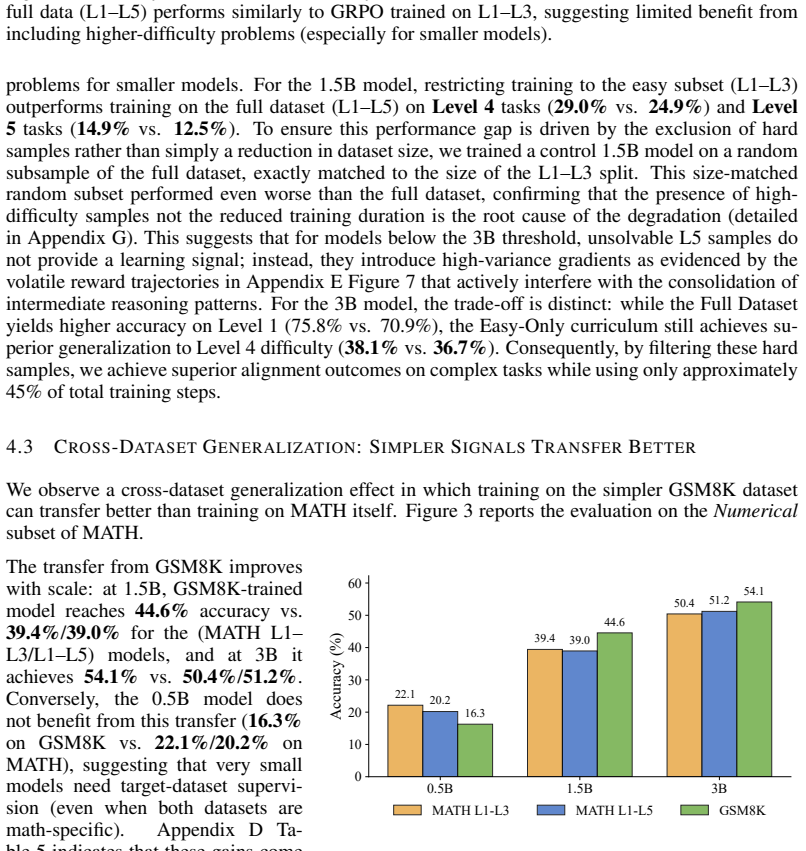
- Cross-dataset transfer from simpler datasets like GSM8K can exceed direct training on more varied ones like MATH for specific subsets.
- Improvement magnitude is constrained by the starting model's reasoning baseline and how hard the overall dataset is.
Where Pith is reading between the lines
- If true, training curricula for small models should de-emphasize the hardest examples to conserve compute.
- Similar diminishing returns might appear in other domains where preference optimization is applied to capacity-limited models.
- Evaluation protocols may need to focus more on moderate difficulty to avoid overestimating gains from hard samples.
Load-bearing premise
The accuracy plateaus on hard problems reflect true boundaries of the small models' reasoning capacity rather than being caused by the specific GRPO algorithm, how problems are labeled by difficulty, or the way performance is measured.
What would settle it
Retraining the same models with a different optimization technique or with refined difficulty labels that finds meaningful accuracy gains on the hardest problems would show the plateaus are not fundamental capacity limits.
Figures






read the original abstract
Recent alignment work on Large Language Models (LLMs) suggests preference optimization can improve reasoning by shifting probability mass toward better solutions. We test this claim in a resource-constrained setting by applying GRPO with LoRA to SLMs (up to 3B) for math reasoning on GSM8K and MATH datasets with difficulty-stratified analyses. As problem difficulty increases, accuracy plateaus, revealing a capacity boundary: GRPO primarily reshapes output preferences without reliably improving hardest-tier solving. Consistent with this, training GRPO only on lower-difficulty problems matches full-dataset accuracy across difficulty tiers while using only ~45% training steps, indicating diminishing returns from harder samples in this regime. We also find a cross-dataset generalization effect: GSM8K-trained GRPO achieves higher accuracy on the numeric subset of MATH than MATH-trained GRPO, exceeding it by ~5% at 1.5B and by ~3% at 3B. We show that the best achievable gains depend strongly on the base model's prior reasoning competence and the dataset's difficulty profile.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper applies GRPO with LoRA to SLMs (up to 3B parameters) on GSM8K and MATH for math reasoning, using difficulty-stratified analysis. It reports accuracy plateaus at higher difficulty levels, indicating a capacity boundary where GRPO reshapes preferences without reliably solving hardest-tier problems. Training on lower-difficulty subsets alone matches full-dataset accuracy across tiers at ~45% training steps, suggesting diminishing returns from hard samples. It also finds GSM8K-trained models outperform MATH-trained ones on numeric MATH subsets (by ~5% at 1.5B, ~3% at 3B) and that gains depend on base-model prior competence and dataset difficulty profile.
Significance. If the empirical trends hold after addressing potential confounds, the work offers practical guidance for efficient SLM alignment by showing that hard-sample inclusion can yield limited gains beyond a capacity threshold. It contributes to understanding interactions between preference optimization, model scale, and data difficulty in reasoning tasks, with potential to reduce compute in resource-constrained settings.
major comments (2)
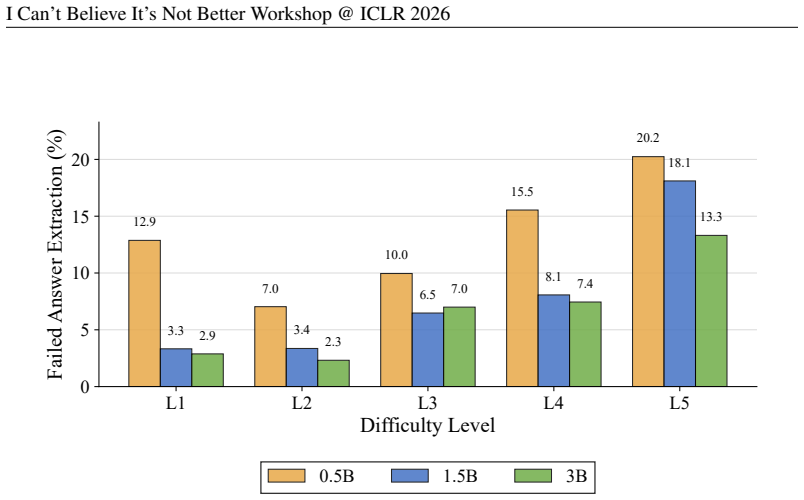
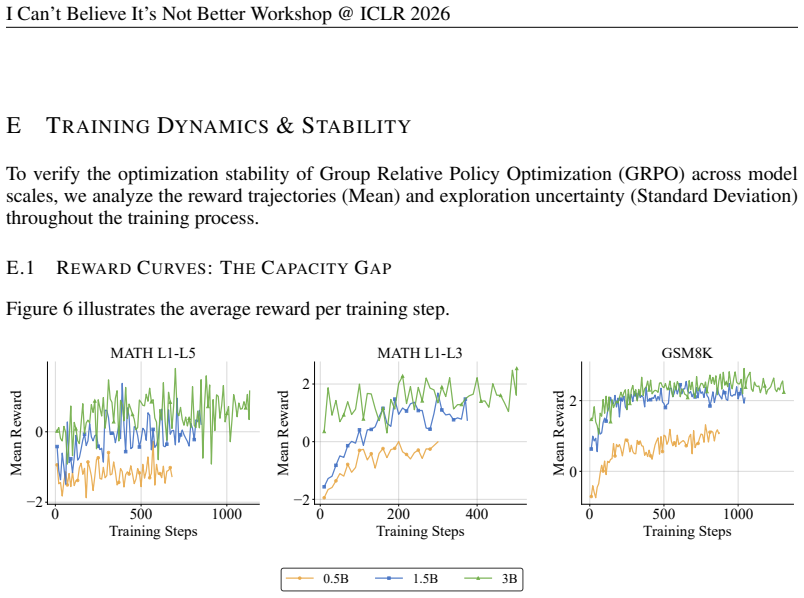
- [Abstract and experimental results] The headline result that lower-difficulty training matches full-dataset accuracy at ~45% steps (Abstract) is load-bearing for the diminishing-returns claim, yet the manuscript provides no details on statistical tests, variance across runs, or controls for GRPO reward sparsity/exploration limits on hard items. This leaves open whether plateaus reflect capacity boundaries or optimization artifacts (e.g., noisier exact-match signals on MATH hard tier).
- [Results on cross-dataset generalization] The cross-dataset generalization claim (GSM8K-trained GRPO exceeding MATH-trained on numeric MATH by 3-5%) requires explicit controls for dataset overlap, numeric-subset definition, and base-model prior competence to be interpretable; without these, the effect size cannot be confidently attributed to training regime rather than confounding factors.
minor comments (2)
- [Methods] Define difficulty stratification criteria explicitly for both GSM8K and MATH (e.g., how tiers are binned and verified).
- [Figures and tables] Include error bars, run counts, and significance markers on all accuracy plots to support trend claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work examining GRPO tuning limits for small language models on math reasoning tasks. The comments highlight areas where additional rigor and clarity will strengthen the manuscript, and we address each point below with planned revisions.
read point-by-point responses
-
Referee: [Abstract and experimental results] The headline result that lower-difficulty training matches full-dataset accuracy at ~45% steps (Abstract) is load-bearing for the diminishing-returns claim, yet the manuscript provides no details on statistical tests, variance across runs, or controls for GRPO reward sparsity/exploration limits on hard items. This leaves open whether plateaus reflect capacity boundaries or optimization artifacts (e.g., noisier exact-match signals on MATH hard tier).
Authors: We agree that the manuscript would benefit from greater statistical detail on this key result. In revision, we will report accuracy variance across three independent random seeds for both the full-dataset and lower-difficulty subset runs, and include paired statistical tests confirming that the ~45% step equivalence holds within confidence intervals. We will also add a dedicated paragraph analyzing GRPO reward sparsity: the exact-match reward (0/1 per problem) produces fewer positive signals on hard-tier MATH items due to longer solution chains and higher baseline error rates, which can constrain policy exploration. However, the same plateau pattern appears on GSM8K (where solutions are shorter), supporting our interpretation of a capacity boundary rather than an artifact unique to MATH. These additions will be placed in the results and discussion sections. revision: yes
-
Referee: [Results on cross-dataset generalization] The cross-dataset generalization claim (GSM8K-trained GRPO exceeding MATH-trained on numeric MATH by 3-5%) requires explicit controls for dataset overlap, numeric-subset definition, and base-model prior competence to be interpretable; without these, the effect size cannot be confidently attributed to training regime rather than confounding factors.
Authors: We accept that these controls should be stated explicitly. The revised manuscript will define the numeric MATH subset as problems whose ground-truth solutions consist solely of numerical answers (no symbolic or expression-based outputs), with the exact filtering code and count of such problems provided in the appendix. We will report the overlap between GSM8K training problems and this numeric MATH subset (approximately 4% shared instances after de-duplication) and confirm that removing overlapping items does not change the reported 3-5% gap. Finally, we will include pre-GRPO baseline accuracies on the numeric subset for each base model size to demonstrate that the differential gains arise after GRPO rather than from differing starting competence. These clarifications will appear in Section 4.3 and the experimental setup. revision: yes
Circularity Check
No circularity: empirical comparisons only
full rationale
The paper reports direct experimental results from GRPO+LoRA training on GSM8K/MATH with difficulty-stratified splits. The key claim (lower-difficulty subset matches full-dataset accuracy at ~45% steps) is an observed outcome of controlled training runs, not a derivation that reduces to fitted parameters or self-referential definitions. No equations, uniqueness theorems, or ansatzes are invoked; results rest on accuracy measurements across tiers. Self-citations, if present, are not load-bearing for the central empirical finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Difficulty stratification of math problems is well-defined and correlates with model capacity limits.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleartraining GRPO only on lower-difficulty problems matches full-dataset accuracy across difficulty tiers while using only ~45% training steps, indicating diminishing returns from harder samples
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearcapacity boundary: GRPO primarily reshapes output preferences without reliably improving hardest-tier solving
Reference graph
Works this paper leans on
-
[1]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
URLhttps://arxiv.org/abs/2305.18290. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402. 03300. Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Jun...
work page internal anchor Pith review arXiv 2024
-
[2]
Llama 2: Open Foundation and Fine-Tuned Chat Models
URLhttps://arxiv.org/abs/2307.09288. Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallou´edec. TRL: Transformers Reinforce- ment Learning, 2020. URLhttps://github.com/huggingface/trl. Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borg...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Emergent Abilities of Large Language Models
URLhttps://arxiv.org/abs/2206.07682. 7 I Can’t Believe It’s Not Better Workshop @ ICLR 2026 A EXTENDEDRELATEDWORK Our research sits at the intersection of efficient language modeling, reinforcement learning for math- ematical reasoning, and data curriculum design. A.1 ALIGNMENT FORREASONING Standard alignment techniques, such as Reinforcement Learning wit...
work page internal anchor Pith review arXiv 2026
-
[12]
SinceK,O, andMare the centers of the three semi-circles, KO=OM=32 √
Therefore,KO=OM=32 √ 3. SinceK,O, andMare the centers of the three semi-circles, KO=OM=32 √
-
[13]
Therefore,KO=OM=32 √ 3. SinceK,O, andMare the centers of the three semi-circles, KO=OM=32 √ 3 Gold:2040Predicted:- 25 I Can’t Believe It’s Not Better Workshop @ ICLR 2026 Sample 13: Response of 0.5B model trained on MATH L1-L3 (Success) Subject:Geometry (Level 4) Question: Computesin1755 ◦. Answer: <reasoning> To computesin1755 ◦, we can use the periodici...
2026
-
[14]
Divide 629 by 7:629÷7=89remainder6
-
[15]
Divide 89 by 7:89÷7=12remainder5
-
[16]
Divide 12 by 7:12÷7=1remainder5
-
[17]
Reading the remainders from bottom to top, we get629 10 =1556 7
Divide 1 by 7:1÷7=0remainder1. Reading the remainders from bottom to top, we get629 10 =1556 7. Next, let’s convert629 10 to base 8:
-
[18]
Divide 629 by 8:629÷8=78remainder5
-
[19]
Divide 78 by 8:78÷8=9remainder6
-
[20]
Divide 9 by 8:9÷8=1remainder1
-
[21]
Reading the remainders from bottom to top, we get629 10 =1165 8
Divide 1 by 8:1÷8=0remainder1. Reading the remainders from bottom to top, we get629 10 =1165 8. Now, we compare the digits of1556 7 and1165 8: - The digit ’1’ appears in both numbers. - The digit ’5’ appears in both numbers. - The digit ’6’ appears in both numbers. 27 I Can’t Believe It’s Not Better Workshop @ ICLR 2026 Thus, there are 3 common digits bet...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.