Recognition: 2 theorem links
· Lean TheoremMICA: Multivariate Infini Compressive Attention for Time Series Forecasting
Pith reviewed 2026-05-12 02:05 UTC · model grok-4.3
The pith
MICA adds a linear-scaling cross-channel attention mechanism to channel-independent Transformers, cutting multivariate forecast error by 5.4 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adapting compressive attention techniques from the sequence dimension to the channel dimension, MICA supplies an explicit cross-channel attention layer that scales linearly rather than quadratically, allowing channel-independent Transformer architectures to become channel-dependent without prohibitive cost and yielding lower forecast errors together with top ranking among deep multivariate baselines.
What carries the argument
Multivariate Infini Compressive Attention (MICA), which transplants efficient attention compression from the temporal axis to the channel axis so that inter-variable dependencies can be modeled explicitly while complexity remains linear in both channel count and context length.
If this is right
- Multivariate forecasting with Transformers becomes practical at higher channel counts without quadratic blow-up.
- Explicit cross-channel modeling produces measurable accuracy gains over purely channel-independent designs.
- Models equipped with MICA outperform both channel-independent Transformers and other deep multivariate MLP and Transformer baselines on standard benchmarks.
- Forecasting pipelines can scale context length and variable count more efficiently than architectures that attend jointly over time and channels.
Where Pith is reading between the lines
- The same compression principle could be ported to other attention-heavy multivariate sequence tasks such as multi-sensor signal processing or multi-speaker audio modeling.
- Combining MICA with existing temporal-efficiency techniques might further extend the feasible size of multivariate forecasting problems.
- The observed gains suggest that many real-world time series contain exploitable cross-channel structure that channel-independent models currently ignore.
Load-bearing premise
The compressive mechanism retains the inter-variable dependencies that actually matter for forecasting accuracy.
What would settle it
On a new high-dimensional dataset where full cross-channel attention is still computationally feasible, MICA either matches or underperforms the channel-independent baseline while a non-compressive full-attention model improves further.
Figures



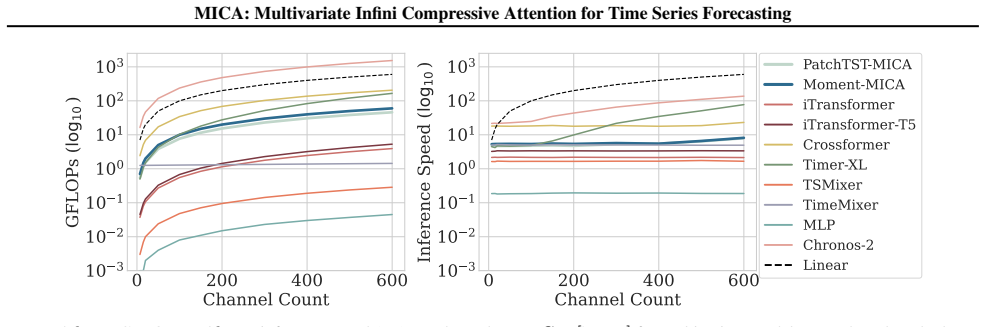
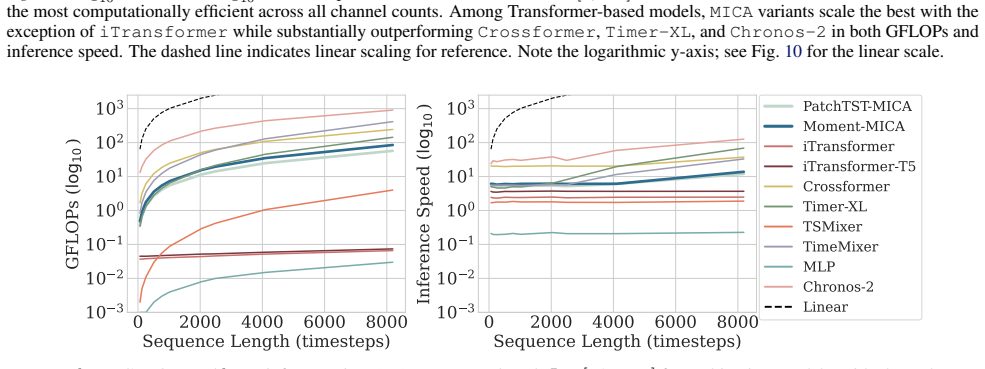





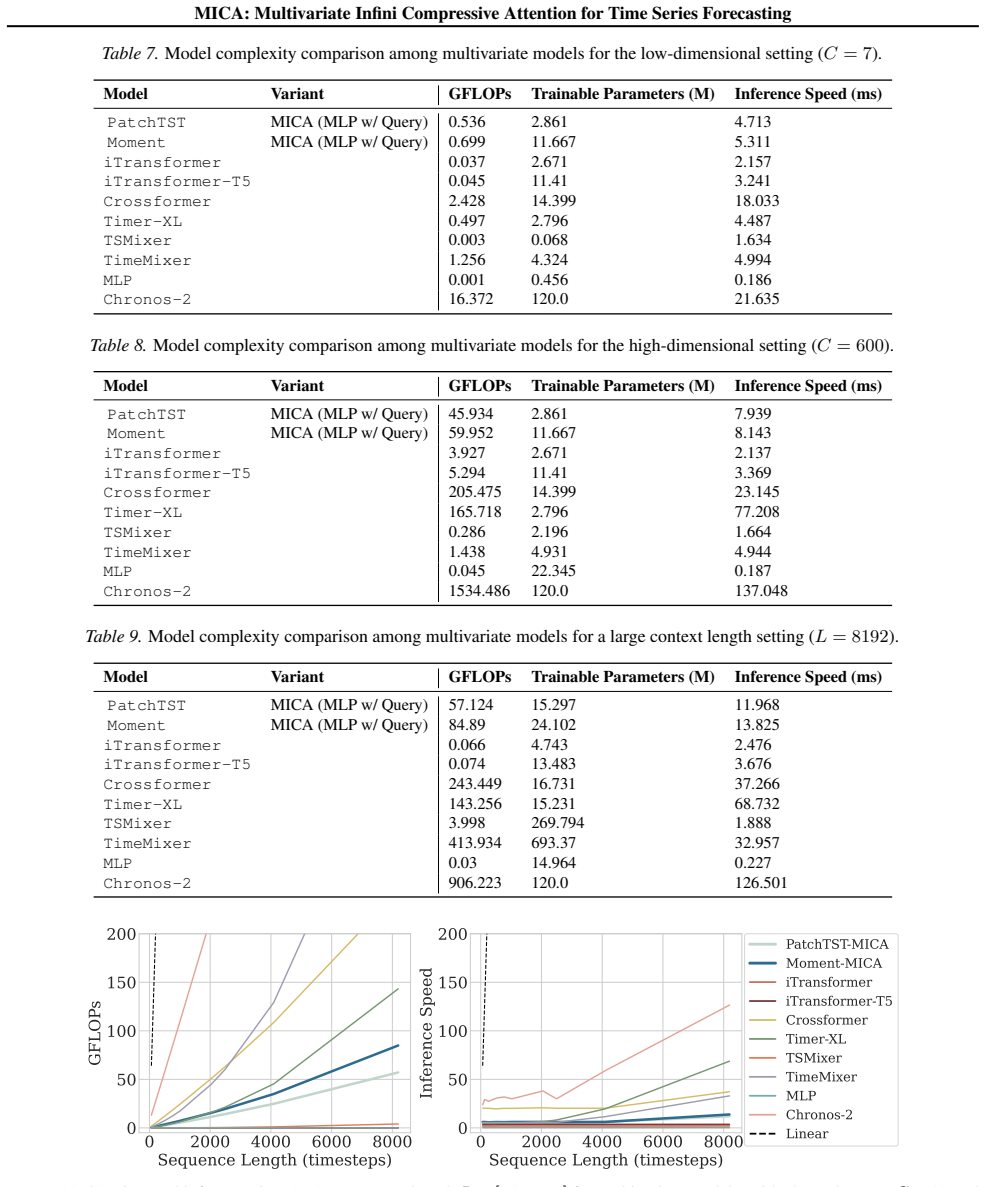
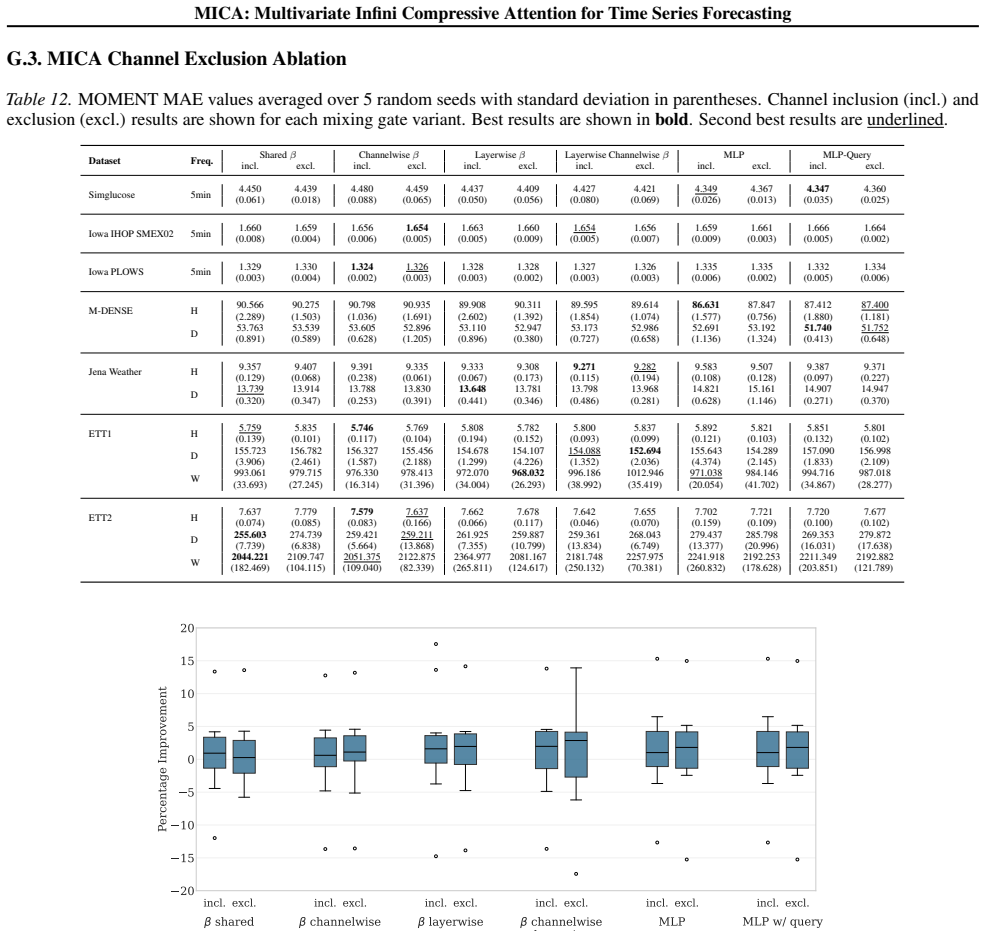




read the original abstract
Multivariate forecasting with Transformers faces a core scalability challenge: modeling cross-channel dependencies via attention compounds attention's quadratic sequence complexity with quadratic channel scaling, making full cross-channel attention impractical for high-dimensional time series. We propose Multivariate Infini Compressive Attention (MICA), an architectural design to extend channel-independent Transformers to channel-dependent forecasting. By adapting efficient attention techniques from the sequence dimension to the channel dimension, MICA adds a cross-channel attention mechanism to channel-independent backbones that scales linearly with channel count and context length. We evaluate channel-independent Transformer architectures with and without MICA across multiple forecasting benchmarks. MICA reduces forecast error over its channel-independent counterparts by 5.4% on average and up to 25.4% on individual datasets, highlighting the importance of explicit cross-channel modeling. Moreover, models with MICA rank first among deep multivariate Transformer and MLP baselines. MICA models also scale more efficiently with respect to both channel count and context length than Transformer baselines that compute attention across both the temporal and channel dimensions, establishing compressive attention as a practical solution for scalable multivariate forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Multivariate Infini Compressive Attention (MICA), an adaptation of efficient attention techniques to the channel dimension that enables linear-scaling cross-channel modeling within channel-independent Transformer backbones for multivariate time series forecasting. It claims that adding MICA yields 5.4% average forecast error reduction (up to 25.4% on individual datasets) over channel-independent counterparts, first-place ranking among deep multivariate Transformer and MLP baselines, and better scaling than full temporal+channel attention Transformers.
Significance. If the compressive cross-channel mechanism preserves relevant inter-variable dependencies, the work offers a practical route to scalable multivariate forecasting that avoids quadratic channel complexity. The empirical ranking results and scaling claims, if substantiated with full experimental controls, would strengthen the case for explicit but efficient cross-channel modeling over purely channel-independent designs.
major comments (2)
- [Experiments / Results] The central claim that MICA's linear compressive attention faithfully captures predictive cross-channel dependencies (without meaningful information loss relative to full quadratic attention) is load-bearing for attributing the 5.4% gains to cross-channel modeling rather than other design choices. No head-to-head forecast error comparison to full cross-channel attention is reported on any low-channel dataset where the quadratic version remains tractable.
- [Abstract and §4] Abstract and results sections report average and peak error reductions plus rankings but provide no details on statistical significance testing, error bars, exact data splits, or ablation controls isolating the compressive attention component. This prevents verification that the reported improvements are robust.
minor comments (2)
- [§3] Notation for the adapted efficient attention (e.g., definitions of key matrices or compression operators) could be made more explicit with an additional equation or diagram in the method section.
- [Tables in §4] Table captions should explicitly state the number of runs or seeds used for each reported metric to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and rigor of our manuscript. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Experiments / Results] The central claim that MICA's linear compressive attention faithfully captures predictive cross-channel dependencies (without meaningful information loss relative to full quadratic attention) is load-bearing for attributing the 5.4% gains to cross-channel modeling rather than other design choices. No head-to-head forecast error comparison to full cross-channel attention is reported on any low-channel dataset where the quadratic version remains tractable.
Authors: We agree that direct comparisons on low-channel datasets would provide stronger evidence that the compressive attention does not incur significant information loss compared to full attention. Although our paper focuses on scalability for high-dimensional series, we will conduct and report additional experiments on datasets with small numbers of channels (such as those with 5-20 variables) to compare MICA against full cross-channel attention, thereby isolating the effect of the compressive mechanism. revision: yes
-
Referee: [Abstract and §4] Abstract and results sections report average and peak error reductions plus rankings but provide no details on statistical significance testing, error bars, exact data splits, or ablation controls isolating the compressive attention component. This prevents verification that the reported improvements are robust.
Authors: We appreciate this feedback on the need for more detailed statistical reporting. In the revised version, we will add error bars representing standard deviations across multiple random seeds, specify the exact train/validation/test splits used, perform statistical significance tests (e.g., Wilcoxon signed-rank tests) on the improvements, and include more comprehensive ablations that isolate the compressive attention module from other design elements. revision: yes
Circularity Check
No circularity: empirical evaluation on external benchmarks
full rationale
The paper proposes an architectural extension (MICA) for multivariate time series forecasting and evaluates it empirically by measuring forecast error reductions on standard public benchmarks against channel-independent baselines and other multivariate models. No derivation chain, first-principles equations, or fitted-parameter predictions are claimed; the headline 5.4% average improvement is a direct experimental outcome on held-out test sets rather than a quantity forced by construction from the model's own inputs or self-citations. The compressive attention mechanism is presented as an engineering adaptation whose value is assessed externally, satisfying the criteria for a self-contained, non-circular result.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MICA adapts the linear attention mechanism from Infini-Attention ... M = Σ ϕ(K(c))⊤V(c) ... A_global = ϕ(Q)M / (ϕ(Q)z + ϵ) ... Amixed = σ(β) ⊙ A_global + (1−σ(β)) ⊙ A_local
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MICA models also scale more efficiently with respect to both channel count and context length than Transformer baselines that compute attention across both the temporal and channel dimensions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aksu, T., Woo, G., Liu, J., Liu, X., Liu, C., Savarese, S., Xiong, C., and Sahoo, D. Gift-eval: A benchmark for general time series forecasting model evaluation, 2024. URL https://arxiv.org/abs/2410.10393
-
[2]
C., Rangapuram, S., Salinas, D., Schulz, J., Stella, L., Türkmen, A
Alexandrov, A., Benidis, K., Bohlke-Schneider, M., Flunkert, V., Gasthaus, J., Januschowski, T., Maddix, D. C., Rangapuram, S., Salinas, D., Schulz, J., Stella, L., Türkmen, A. C., and Wang, Y. Gluonts: Probabilistic time series models in python. https://github.com/awslabs/gluonts, 2019
work page 2019
-
[3]
Chronos-2: From Univariate to Universal Forecasting
Ansari, A. F., Shchur, O., Küken, J., Auer, A., Han, B., Mercado, P., and et al. Chronos-2: From univariate to universal forecasting. arXiv preprint, 2025. URL https://arxiv.org/abs/2510.15821
work page internal anchor Pith review arXiv 2025
-
[4]
Arthur Harris, J. and Gano Benedict, F. A biometric study of basal metabolism in man. Carnegie institution of Washington, 21919
-
[5]
Cachay, S. R., Erickson, E., Bucker, A. F. C., Pokropek, E., Potosnak, W., Bire, S., Osei, S., and L \"u tjens, B. The world as a graph: Improving el ni \ n o forecasts with graph neural networks. arXiv preprint arXiv:2104.05089, 2021
-
[6]
Cao, D., Wang, Y., Duan, J., Zhang, C., Zhu, X., Huang, C., and et. al. Spectral temporal graph neural network for multivariate time-series forecasting. In 34th Conference on Neural Information Processing Systems, 2020
work page 2020
-
[7]
Chen, S.-A., Li, C.-L., Yoder, N. C., O . Arık, S., and Pfister, T. TSMixer : An all- MLP architecture for time series forecasting. In Published in Transactions on Machine Learning Research, 2023
work page 2023
-
[8]
Rethinking Attention with Performers
Choromanski, K., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., and et al. Rethinking attention with performers. In International Conference on Learning Representations, 2021. URL https://arxiv.org/abs/2009.14794
work page internal anchor Pith review arXiv 2021
-
[9]
Cui, Z., Ke, R., and Wang, Y. Deep bidirectional and unidirectional lstm recurrent neural network for network-wide traffic speed prediction. arXiv preprint arXiv:1801.02143, 2018
-
[10]
Cui, Z., Henrickson, K., Ke, R., and Wang, Y. Traffic graph convolutional recurrent neural network: A deep learning framework for network-scale traffic learning and forecasting. IEEE Transactions on Intelligent Transportation Systems, 2019
work page 2019
-
[11]
Y., Ermon, S., Rudra, A., and R \'e , C
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., and R \'e , C. Flash A ttention: Fast and memory-efficient exact attention with IO -awareness. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[12]
A decoder-only foundation model for time-series forecasting
Das, A., Kong, W., Sen, R., and Zhou, Y. A decoder-only foundation model for time-series forecasting. In Proceedings of the Forty-First International Conference on Machine Learning (ICML), 2024. URL https://arxiv.org/abs/2310.10688
-
[13]
de Medrano, R. and Aznarte, J. L. A spatio-temporal spot-forecasting framework for urban traffic prediction. Applied Soft Computing, 2020
work page 2020
-
[14]
H., Dayama, P., Reddy, C., Gifford, W
Ekambaram, V., Jati, A., Nguyen, N. H., Dayama, P., Reddy, C., Gifford, W. M., and Kalagnanam, J. TTMs : Fast multi-level tiny time mixers for improved zero-shot and few-shot forecasting of multivariate time series. arXiv preprint arXiv:2401.03955, 2024
-
[15]
M., Challú, C., and Olivares, K
Garza, F., Canseco, M. M., Challú, C., and Olivares, K. G. StatsForecast : Lightning fast forecasting with statistical and econometric models. PyCon Salt Lake City, Utah, US 2022, 2022. URL https://github.com/Nixtla/statsforecast
work page 2022
-
[16]
Godahewa, R. W., Bergmeir, C., Webb, G. I., Hyndman, R., and Montero-Manso, P. Monash time series forecasting archive. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/forum?id=wEc1mgAjU-
work page 2021
-
[17]
Gon c alves, J. N. C., Cortez, P., Carvalho, M. S., and Fraz \ a o, N. M. A multivariate approach for multi-step demand forecasting in assembly industries: Empirical evidence from an automotive supply chain. Decision Support Systems, 142, 2021
work page 2021
-
[18]
MOMENT : A family of open time-series foundation models
Goswami, M., Szafer, K., Choudhry, A., Cai, Y., Li, S., and Dubrawski, A. MOMENT : A family of open time-series foundation models. In International Conference on Machine Learning, 2024
work page 2024
-
[19]
Softs: Efficient multivariate time series forecasting with series-core fusion
Han, L., Chen, X.-Y., Ye, H.-J., and Zhan, D.-C. Softs: Efficient multivariate time series forecasting with series-core fusion. arXiv preprint arXiv:2404.14197, 2024
-
[20]
Timefilter: Patch-specific spatial-temporal graph filtration for time series forecasting
Hu, Y., Zhang, G., Liu, P., Lan, D., Li, N., Cheng, D., Dai, T., Xia, S.-T., and Pan, S. Timefilter: Patch-specific spatial-temporal graph filtration for time series forecasting. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=490VcNtjh7
work page 2025
-
[21]
Forecasting with exponential smoothing: the state space approach
Hyndman, R. Forecasting with exponential smoothing: the state space approach. Springer Berlin, Heidelberg, 2008
work page 2008
-
[22]
SMEX02: Automated Weather Observing System (AWOS) Iowa 1-min Data , 2005
Iowa State University . SMEX02: Automated Weather Observing System (AWOS) Iowa 1-min Data , 2005. URL https://doi.org/10.26023/SM2V-E9KY-EG10. Accessed: 26 December 2025
-
[23]
IHOP\_2002: Automated Weather Observing System (AWOS) Iowa 1-min Data , 2008
Iowa State University . IHOP\_2002: Automated Weather Observing System (AWOS) Iowa 1-min Data , 2008. URL https://doi.org/10.26023/ZM18-BQWR-0B11. Accessed: 26 December 2025
-
[24]
PLOWS: Iowa Automated Weather Observing System (AWOS) 1-minute Data , 2010
Iowa State University . PLOWS: Iowa Automated Weather Observing System (AWOS) 1-minute Data , 2010. URL https://doi.org/10.26023/Y9RJ-GH3F-FM01. Accessed: 26 December 2025
-
[25]
Transformers are RNNs : Fast autoregressive transformers with linear attention
Katharopoulos, A., Vyas, A., Pappas, N., and Fleuret, F. Transformers are RNNs : Fast autoregressive transformers with linear attention. In III, H. D. and Singh, A. (eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp.\ 5156--5165. PMLR, 13--18 Jul 2020. URL https://procee...
work page 2020
-
[26]
Kessy, A., Lewin, A., and Strimmer, K. Optimal whitening and decorrelation. The American Statistician, 72 0 (4): 0 309--314, 2018. doi:10.1080/00031305.2016.1277159
-
[27]
Modeling long- and short-term temporal patterns with deep neural networks
Lai, G., Chang, W.-C., Yang, Y., and Liu, H. Modeling long- and short-term temporal patterns with deep neural networks. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, 2018. URL https://api.semanticscholar.org/CorpusID:4922476
work page 2018
-
[28]
iTransformer : Inverted transformers are effective for time series forecasting
Liu, Y., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., and Long, M. iTransformer : Inverted transformers are effective for time series forecasting. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=JePfAI8fah
work page 2024
-
[29]
Timer-xl: Long-context transformers for unified time series forecasting
Liu, Y., Qin, G., Huang, X., Wang, J., and Long, M. Timer-xl: Long-context transformers for unified time series forecasting. In Proceedings of the Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[30]
Luo, D. and Wang, X. Moderntcn: A modern pure convolution structure for general time series analysis. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[31]
Ma, X., Ni, Z.-L., Xiao, S., and Chen, X. Timepro: Efficient multivariate long-term time series forecasting with variable- and time-aware hyper-state. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=s69Ei2VrIW
work page 2025
-
[32]
Munkhdalai, T., Faruqui, M., and Gopal, S. Leave no context behind: Efficient infinite context transformers with infini-attention. arXiv preprint arXiv:2404.07143, 2024
-
[33]
Nguyen, Q. M., Nguyen, L. M., and Das, S. Correlated attention in transformers for multivariate time series, 2023. URL https://arxiv.org/abs/2311.11959
-
[34]
H., Sinthong, P., and Kalagnanam, J
Nie, Y., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. arXiv preprint arXiv:2307.13787, 2023. URL https://arxiv.org/abs/2307.13787
-
[35]
G., Challu, C., Marcjasz, G., Weron, R., and Dubrawski, A
Olivares, K. G., Challu, C., Marcjasz, G., Weron, R., and Dubrawski, A. Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with nbeatsx. International Journal of Forecasting, 39 0 (2): 0 884--900, 2022 a
work page 2022
-
[36]
G., Challú, C., Garza, F., Canseco, M
Olivares, K. G., Challú, C., Garza, F., Canseco, M. M., and Dubrawski, A. NeuralForecast : User friendly state-of-the-art neural forecasting models. PyCon Salt Lake City, Utah, US 2022, 2022 b . URL https://github.com/Nixtla/neuralforecast
work page 2022
-
[37]
Multivariate time series forecasting using independent component analysis
Popescu, T. Multivariate time series forecasting using independent component analysis. In EFTA 2003. 2003 IEEE Conference on Emerging Technologies and Factory Automation. Proceedings (Cat. No.03TH8696), volume 2, pp.\ 782--789, 2003. doi:10.1109/ETFA.2003.1248778
-
[38]
Potosnak, W., Challu, C. I., Olivares, K. G., Dufendach, K. A., and Dubrawski, A. Global deep forecasting with patient-specific pharmacokinetics. In Proceedings of Machine Learning Research, 2025 a . URL https://raw.githubusercontent.com/mlresearch/v287/main/assets/potosnak25a/potosnak25a.pdf
work page 2025
-
[39]
W., Oreshkin, B., and Olivares, K
Potosnak, W., Wolff, M., Cao, M., Ma, R., Konstantinova, T., Efimov, D., Mahoney, M. W., Oreshkin, B., and Olivares, K. G. Forking-sequences, 2025 b . URL https://arxiv.org/abs/2510.04487
-
[40]
Qin, Z., Sun, W., Deng, H., Li, D., Wei, Y., Lv, B., and et al. cos F ormer: Rethinking softmax in attention. In International Conference on Learning Representations, 2022. URL https://arxiv.org/abs/2202.08791
-
[41]
The P erceptron: A probabilistic model for information storage and organization in the brain
Rosenblatt, F. The P erceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65 0 (6): 0 386–--408, 1958
work page 1958
-
[42]
Santos, A. A. P., Nogales, F. J., and Ruiz, E. Comparing univariate and multivariate models to forecast portfolio value-at-risk. Journal of Financial Econometrics, 11 0 (2): 0 400--441, 2013. doi:10.1093/jjfinec/nbs015
-
[43]
Retentive network: A successor to Transformer for large language models, 2023
Sun, Y., Dong, L., Huang, S., Ma, S., Xia, Y., Xue, J., Wang, J., and Wei, F. Retentive network: A successor to Transformer for large language models, 2023
work page 2023
-
[44]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., and Gomez, A. N. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, 2017
work page 2017
-
[45]
Visentin, R., Dalla Man, C., and Cobelli, C. One-day bayesian cloning of type 1 diabetes subjects: Toward a single-day uva/padova type 1 diabetes simulator. IEEE Transactions on Biomedical Engineering, 63 0 (11), 2016
work page 2016
-
[46]
Optimal transport for time series imputation
Wang, S., Li, J., Shi, X., Ye, Z., Mo, B., Lin, W., Ju, S., Chu, Z., and Jin, M. Timemixer++: A general time series pattern machine for universal predictive analysis. arXiv preprint arXiv:2410.16032, 2024 a
-
[47]
Wang, S., Wu, H., Shi, X., Hu, T., Luo, H., Ma, L., Zhang, J. Y., and ZHOU, J. Timemixer: Decomposable multiscale mixing for time series forecasting. In International Conference on Learning Representations (ICLR), 2024 b
work page 2024
-
[48]
Transformers: State-of-the-art natural language processing
Wolf, T., Debut, L., Sanh, V., et al. Transformers: State-of-the-art natural language processing. https://github.com/huggingface/transformers, 2020
work page 2020
-
[49]
Unified training of universal time series forecasting transformers
Woo, G., Liu, C., Kumar, A., Xiong, C., Savarese, S., and Sahoo, D. Unified training of universal time series forecasting transformers. In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 2024. International Conference on Machine Learning
work page 2024
-
[50]
Autoformer: Decomposition transformers with Auto-Correlation for long-term series forecasting
Wu, H., Xu, J., Wang, J., and Long, M. Autoformer: Decomposition transformers with Auto-Correlation for long-term series forecasting. In Advances in Neural Information Processing Systems, 2021
work page 2021
-
[51]
TimesNet : Temporal 2d-variation modeling for general time series analysis
Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., and Long, M. TimesNet : Temporal 2d-variation modeling for general time series analysis. In Proceedings of the 34th International Conference on Learning Representations, 2023
work page 2023
-
[52]
Wu, H., Hu, T., Liu, Y., Zhou, H., Wang, J., and Long, M. Time series library. https://github.com/thuml/Time-Series-Library, 2024
work page 2024
-
[53]
Simglucose v0.2.1 (2018), 2018
Xie, J. Simglucose v0.2.1 (2018), 2018. URL https://github.com/jxx123/simglucose
work page 2018
-
[54]
Zhang, Y. and Yan, J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[55]
Zhang, Y., Liu, M., Zhou, S., and Yan, J. UP2ME : Univariate pre-training to multivariate fine-tuning as a general-purpose framework for multivariate time series analysis. In Forty-first International Conference on Machine Learning, 2024
work page 2024
- [56]
-
[57]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, G., Xiong, H., Zhang, W., Lin, T.-J., Chu, X., Zhang, J., et al. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, 2021
work page 2021
-
[58]
FEDformer : Frequency enhanced decomposed transformer for long-term series forecasting
Zhou, T., Ma, Z., Wen, Q., Wang, X., Sun, L., and Jin, R. FEDformer : Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pp.\ 27268--27286. PMLR, 2022
work page 2022
-
[59]
Towards long-context time series foundation models
\.Z ukowska, N., Goswami, M., Wili \'n ski, M., Potosnak, W., and Dubrawski, A. Towards long-context time series foundation models. arXiv preprint arXiv:2409.13530, 2024
-
[60]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.