FlowAdam: Implicit Regularization via Geometry-Aware Soft Momentum Injection
Pith reviewed 2026-05-10 18:53 UTC · model grok-4.3
The pith
FlowAdam augments Adam with ODE gradient flow and soft momentum blending to regularize optimization on coupled parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowAdam augments Adam with continuous gradient-flow integration via an ordinary differential equation. When EMA-based statistics detect landscape difficulty, FlowAdam switches to clipped ODE integration. Our central contribution is Soft Momentum Injection, which blends ODE velocity with Adam's momentum during mode transitions. This prevents the training collapse observed with naive hybrid approaches. Across coupled optimization benchmarks, the ODE integration provides implicit regularization, reducing held-out error by 10-22% on low-rank matrix/tensor recovery and 6% on Jester (real-world collaborative filtering), also surpassing tuned Lion and AdaBelief, while matching Adam on well-posed,
What carries the argument
Soft Momentum Injection, which blends ODE velocity with Adam's momentum during transitions between adaptive-moment and continuous-flow modes.
Load-bearing premise
EMA-based statistics can reliably flag landscape difficulty in a way that makes ODE integration helpful, and the soft blending will prevent collapse without new instabilities or needing problem-specific retuning of thresholds.
What would settle it
Train the same low-rank matrix recovery benchmark with the soft momentum injection removed and observe whether accuracy falls from near 100 percent to 82.5 percent as reported in the ablation.
Figures

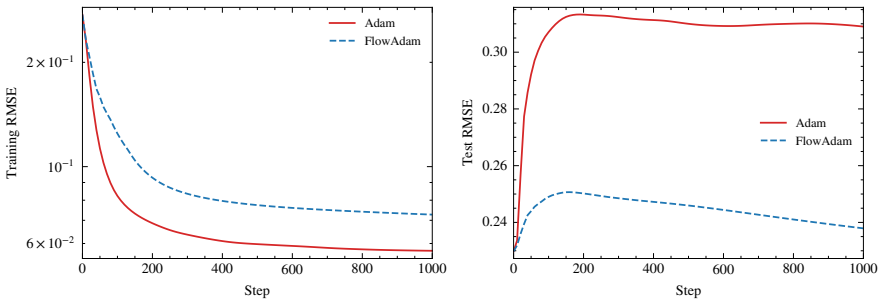
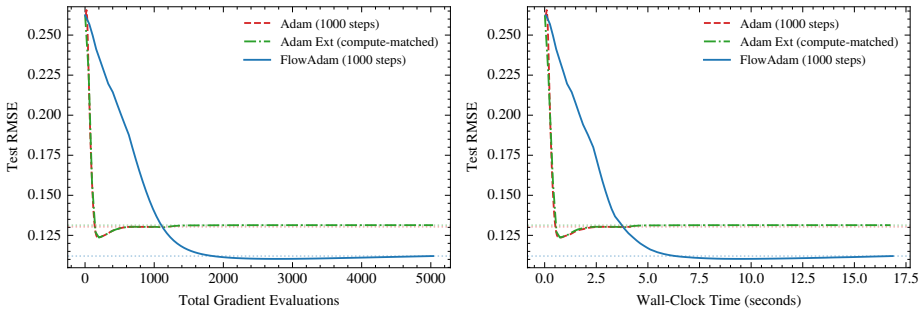
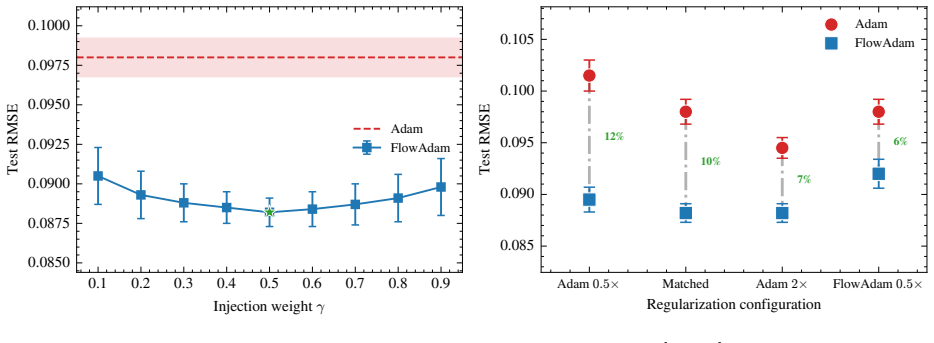
read the original abstract
Adaptive moment methods such as Adam use a diagonal, coordinate-wise preconditioner based on exponential moving averages of squared gradients. This diagonal scaling is coordinate-system dependent and can struggle with dense or rotated parameter couplings, including those in matrix factorization, tensor decomposition, and graph neural networks, because it treats each parameter independently. We introduce FlowAdam, a hybrid optimizer that augments Adam with continuous gradient-flow integration via an ordinary differential equation (ODE). When EMA-based statistics detect landscape difficulty, FlowAdam switches to clipped ODE integration. Our central contribution is Soft Momentum Injection, which blends ODE velocity with Adam's momentum during mode transitions. This prevents the training collapse observed with naive hybrid approaches. Across coupled optimization benchmarks, the ODE integration provides implicit regularization, reducing held-out error by 10-22% on low-rank matrix/tensor recovery and 6% on Jester (real-world collaborative filtering), also surpassing tuned Lion and AdaBelief, while matching Adam on well-conditioned workloads (CIFAR-10). MovieLens-100K confirms benefits arise specifically from coupled parameter interactions rather than bias estimation. Ablation studies show that soft injection is essential, as hard replacement reduces accuracy from 100% to 82.5%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowAdam, a hybrid optimizer that augments Adam with continuous gradient-flow integration via an ODE. When EMA-based statistics detect landscape difficulty, it switches to clipped ODE integration, with the central contribution being Soft Momentum Injection (a convex blend of ODE velocity and Adam momentum) during mode transitions to prevent collapse observed in naive hybrids. Experiments on coupled-parameter benchmarks (low-rank matrix/tensor recovery, Jester collaborative filtering) report 10-22% and 6% held-out error reductions respectively, outperforming tuned Lion/AdaBelief while matching Adam on well-conditioned tasks like CIFAR-10; ablations indicate soft injection is essential (hard replacement drops accuracy from 100% to 82.5%).
Significance. If the central claims hold after addressing verification gaps, the work would be moderately significant for adaptive optimization in machine learning. It targets a known weakness of diagonal preconditioners on dense couplings (matrix factorization, GNNs) and proposes a geometry-aware mechanism for implicit regularization without explicit penalties. Strengths include the ablation isolating soft blending and the MovieLens-100K control showing benefits tied to coupled interactions rather than bias estimation. However, the result is currently empirical rather than derived, limiting its immediate impact relative to purely theoretical or parameter-free contributions.
major comments (3)
- [Abstract and §4] Abstract and §4 (experiments): the reported 10-22% held-out error reductions on matrix/tensor recovery lack error bars, multiple random seeds, or statistical tests; without these, it is unclear whether the gains exceed variability from hyperparameter choices or initialization.
- [§3 and §5] §3 (Soft Momentum Injection) and §5 (ablations): the ablation tests only the extreme of hard replacement (dropping to 82.5% accuracy) but does not vary the blending coefficient or EMA threshold across landscapes, leaving open whether the soft schedule itself requires per-problem retuning as suggested by the free parameters (EMA detection threshold, soft blending coefficient).
- [§3] §3 (mode switching): the claim that EMA statistics reliably detect when coordinate-wise Adam fails due to couplings is presented as a practical heuristic without a supporting derivation or sensitivity analysis showing robustness to the choice of second-moment vs. gradient-norm statistic.
minor comments (2)
- [§3] Notation for the blending formula and clipping operation should be defined explicitly with an equation number rather than described in prose.
- [§4] The manuscript should include full hyperparameter tables (learning rates, EMA decay, switch threshold, clip value) for all baselines and FlowAdam variants to enable reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing clarifications and committing to revisions where the empirical presentation can be strengthened without misrepresenting the current results.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experiments): the reported 10-22% held-out error reductions on matrix/tensor recovery lack error bars, multiple random seeds, or statistical tests; without these, it is unclear whether the gains exceed variability from hyperparameter choices or initialization.
Authors: We agree that the current reporting of the 10-22% reductions would be strengthened by statistical validation. In the revised manuscript we will rerun all matrix/tensor recovery experiments with 5 independent random seeds, report mean held-out error together with standard deviation, and include paired statistical tests (Wilcoxon signed-rank) against the strongest baselines to confirm the improvements exceed initialization and hyperparameter variability. These additions will appear in §4 with a corresponding update to the abstract. revision: yes
-
Referee: [§3 and §5] §3 (Soft Momentum Injection) and §5 (ablations): the ablation tests only the extreme of hard replacement (dropping to 82.5% accuracy) but does not vary the blending coefficient or EMA threshold across landscapes, leaving open whether the soft schedule itself requires per-problem retuning as suggested by the free parameters (EMA detection threshold, soft blending coefficient).
Authors: The existing ablation isolates the necessity of soft versus hard injection. To address the concern about parameter sensitivity, the revised §5 will include additional sweeps of the blending coefficient (0.2, 0.5, 0.8) and EMA threshold on the same coupled benchmarks. These experiments will demonstrate that performance remains stable within the reported operating range and does not require extensive per-problem retuning beyond the defaults used throughout the paper. revision: yes
-
Referee: [§3] §3 (mode switching): the claim that EMA statistics reliably detect when coordinate-wise Adam fails due to couplings is presented as a practical heuristic without a supporting derivation or sensitivity analysis showing robustness to the choice of second-moment vs. gradient-norm statistic.
Authors: The EMA-based mode switch is introduced as an empirical heuristic motivated by observed second-moment behavior on coupled problems. A full theoretical derivation of its detection reliability lies outside the scope of this primarily empirical work. In the revision we will nevertheless add a sensitivity study in §3 that replaces the second-moment statistic with a gradient-norm alternative and reports performance on the same benchmarks, confirming robustness to this modeling choice. revision: partial
Circularity Check
No significant circularity; empirical claims rest on benchmarks
full rationale
The paper introduces FlowAdam as a hybrid optimizer using EMA-based switching to ODE integration with Soft Momentum Injection for mode transitions. Central claims of implicit regularization and performance gains (10-22% error reduction on matrix/tensor tasks, 6% on Jester) are supported by experimental results across benchmarks rather than any derivation chain. No equations, self-citations, fitted parameters renamed as predictions, or self-definitional steps are present in the abstract or described text that would reduce results to inputs by construction. The method and its benefits are presented as novel and externally validated via ablations and comparisons to Adam, Lion, and AdaBelief.
Axiom & Free-Parameter Ledger
free parameters (2)
- EMA detection threshold
- soft blending coefficient
Reference graph
Works this paper leans on
-
[1]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in3rd International Conference on Learning Representations (ICLR), 2015
work page 2015
-
[2]
The marginal value of adaptive gradient methods in machine learning,
A. C. Wilson, R. Roelofs, M. Stern, N. Srebro, and B. Recht, “The marginal value of adaptive gradient methods in machine learning,” Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
work page 2017
-
[3]
Adaptive subgradient methods for online learning and stochastic optimization,
J. Duchi, E. Hazan, and Y . Singer, “Adaptive subgradient methods for online learning and stochastic optimization,”Journal of Machine Learning Research, vol. 12, pp. 2121–2159, 2011
work page 2011
-
[4]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[5]
On the SDEs and scaling rules for adaptive gradient algorithms,
S. Malladi, K. Lyu, A. Panigrahi, and S. Arora, “On the SDEs and scaling rules for adaptive gradient algorithms,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[6]
AdaBelief optimizer: Adapting stepsizes by the belief in observed gradients,
J. Zhuang, T. Tang, Y . Ding, S. C. Tatikonda, N. Dvornek, X. Pa- pademetris, and J. Duncan, “AdaBelief optimizer: Adapting stepsizes by the belief in observed gradients,”Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 18 795–18 806, 2020
work page 2020
-
[7]
On the variance of the adaptive learning rate and beyond,
L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and J. Han, “On the variance of the adaptive learning rate and beyond,” inProceedings of the 8th International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[8]
Symbolic discovery of optimization algorithms,
X. Chen, C. Liang, D. Huang, E. Real, K. Wang, Y . Liu, H. Pham, X. Dong, T. Luong, C.-J. Hsieh, Y . Lu, and Q. V . Le, “Symbolic discovery of optimization algorithms,”Advances in Neural Information Processing Systems (NeurIPS), vol. 36, pp. 49 205–49 233, 2023
work page 2023
-
[9]
Shampoo: Preconditioned stochastic tensor optimization,
V . Gupta, T. Koren, and Y . Singer, “Shampoo: Preconditioned stochastic tensor optimization,” inInternational Conference on Machine Learning (ICML). PMLR, 2018, pp. 1842–1850
work page 2018
-
[10]
Sophia: A scalable stochastic second-order optimizer for language model pre-training,
H. Liu, Z. Li, D. Hall, P. Liang, and T. Ma, “Sophia: A scalable stochastic second-order optimizer for language model pre-training,” in International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[11]
On the limited memory BFGS method for large scale optimization,
D. C. Liu and J. Nocedal, “On the limited memory BFGS method for large scale optimization,”Mathematical Programming, vol. 45, no. 1, pp. 503–528, 1989
work page 1989
-
[12]
AdaHessian: An adaptive second order optimizer for machine learning,
Z. Yao, A. Gholami, S. Shen, M. Mustafa, K. Keutzer, and M. Mahoney, “AdaHessian: An adaptive second order optimizer for machine learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, 2021, pp. 10 665–10 673
work page 2021
-
[13]
Optimizing neural networks with Kronecker- factored approximate curvature,
J. Martens and R. Grosse, “Optimizing neural networks with Kronecker- factored approximate curvature,” inInternational Conference on Ma- chine Learning (ICML). PMLR, 2015, pp. 2408–2417
work page 2015
-
[14]
Matrix factorization techniques for recommender systems,
Y . Koren, R. Bell, and C. V olinsky, “Matrix factorization techniques for recommender systems,”Computer, vol. 42, no. 8, pp. 30–37, 2009
work page 2009
-
[15]
A differential equation for modeling Nesterov’s accelerated gradient method: Theory and insights,
W. Su, S. Boyd, and E. J. Cand `es, “A differential equation for modeling Nesterov’s accelerated gradient method: Theory and insights,”Journal of Machine Learning Research, vol. 17, no. 153, pp. 1–43, 2016
work page 2016
-
[16]
A variational perspective on accelerated methods in optimization,
A. Wibisono, A. C. Wilson, and M. I. Jordan, “A variational perspective on accelerated methods in optimization,”Proceedings of the National Academy of Sciences, vol. 113, no. 47, pp. E7351–E7358, 2016
work page 2016
-
[17]
Integration methods and optimization algorithms,
D. Scieur, V . Roulet, F. Bach, and A. d’Aspremont, “Integration methods and optimization algorithms,”Advances in Neural Information Process- ing Systems (NeurIPS), vol. 30, 2017
work page 2017
-
[18]
Learning by solving differential equations,
B. Dherin, M. Munn, H. Mazzawi, M. Wunder, S. Medapati, and J. Gonzalvo, “Learning by solving differential equations,”arXiv preprint arXiv:2505.13397, 2025
-
[19]
Neural ordinary differential equations,
R. T. Q. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differential equations,”Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
work page 2018
-
[20]
Lookahead optimizer:k steps forward, 1 step back,
M. R. Zhang, J. Lucas, G. Hinton, and J. Ba, “Lookahead optimizer:k steps forward, 1 step back,”Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
work page 2019
-
[21]
Eigentaste: A constant time collaborative filtering algorithm,
K. Goldberg, T. Roeder, D. Gupta, and C. Perkins, “Eigentaste: A constant time collaborative filtering algorithm,”Information Retrieval, vol. 4, no. 2, pp. 133–151, 2001
work page 2001
-
[22]
The MovieLens datasets: History and context,
F. M. Harper and J. A. Konstan, “The MovieLens datasets: History and context,”ACM Transactions on Interactive Intelligent Systems (TiiS), vol. 5, no. 4, pp. 1–19, 2015
work page 2015
-
[23]
Implicit regularization in matrix factorization,
S. Gunasekar, B. E. Woodworth, S. Bhojanapalli, B. Neyshabur, and N. Srebro, “Implicit regularization in matrix factorization,”Advances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
work page 2017
-
[24]
Implicit regularization in deep matrix factorization,
S. Arora, N. Cohen, W. Hu, and Y . Luo, “Implicit regularization in deep matrix factorization,”Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.