Recognition: no theorem link
Extraction of linearized models from pre-trained networks via knowledge distillation
Pith reviewed 2026-05-10 17:56 UTC · model grok-4.3
The pith
Integrating Koopman operator theory with knowledge distillation extracts linearized models from pre-trained networks that outperform standard approximations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
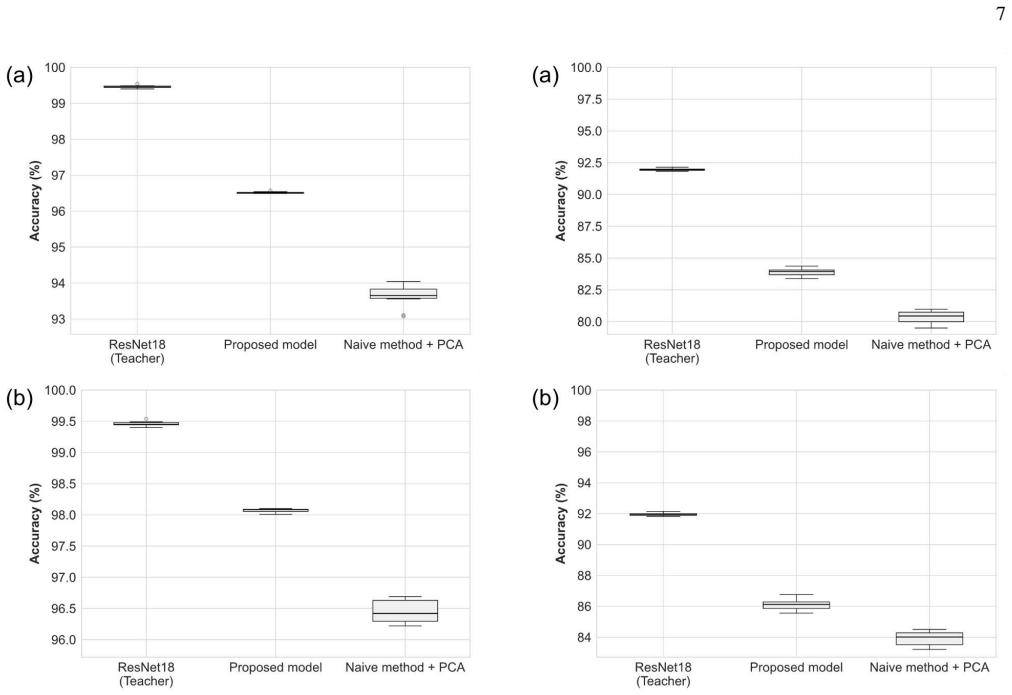
The paper establishes a framework that uses Koopman operator theory together with knowledge distillation to derive a linearized model from a pre-trained neural network for classification. This framework is demonstrated to achieve higher classification accuracy and better numerical stability than the conventional least-squares-based Koopman approximation method when tested on the MNIST and Fashion-MNIST datasets.
What carries the argument
The central mechanism is the fusion of the Koopman operator, which linearizes the system's dynamics, and knowledge distillation, which allows the linearized model to replicate the outputs of the pre-trained nonlinear network.
If this is right
- The resulting linearized models support efficient implementation on linear-operation hardware such as photonic circuits.
- Classification performance is preserved better than with direct least-squares Koopman fitting.
- The approach increases numerical stability for practical use of the models.
- It demonstrates a viable path to hybrid linear-nonlinear learning systems.
Where Pith is reading between the lines
- This technique might apply to other machine learning tasks beyond classification, such as regression or sequence prediction.
- Further work could test whether the method scales to larger, more complex networks and datasets.
- The success suggests distillation can recover nonlinear information lost in linear approximations.
Load-bearing premise
That the knowledge distillation process can transfer the necessary nonlinear classification capability into the linear Koopman model without substantial degradation.
What would settle it
If experiments on additional datasets show the proposed method no longer consistently exceeds the accuracy or stability of the least-squares Koopman baseline, the advantage would be called into question.
Figures


read the original abstract
Recent developments in hardware, such as photonic integrated circuits and optical devices, are driving demand for research on constructing machine learning architectures tailored for linear operations. Hence, it is valuable to explore methods for constructing learning machines with only linear operations after simple nonlinear preprocessing. In this study, we propose a framework to extract a linearized model from a pre-trained neural network for classification tasks by integrating Koopman operator theory with knowledge distillation. Numerical demonstrations on the MNIST and the Fashion-MNIST datasets reveal that the proposed model consistently outperforms the conventional least-squares-based Koopman approximation in both classification accuracy and numerical stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework to extract linearized models from pre-trained neural networks for classification by integrating Koopman operator theory with knowledge distillation. Motivated by hardware constraints favoring linear operations (e.g., photonic circuits), the method is demonstrated on MNIST and Fashion-MNIST, where it reportedly outperforms the standard least-squares Koopman approximation in both classification accuracy and numerical stability.
Significance. If the empirical results hold under rigorous validation, the work offers a practical bridge between nonlinear pre-trained models and linear computational hardware, leveraging two established techniques (Koopman linearization and distillation) without introducing obvious circularity. The numerical demonstrations on standard datasets provide a concrete starting point for hardware-aware model extraction, though extension to deeper networks or regression tasks would increase impact.
minor comments (3)
- The abstract states outperformance 'consistently' but provides no quantitative deltas, confidence intervals, or mention of multiple random seeds; adding these would improve clarity without altering the central claim.
- Notation for the combined loss (Koopman reconstruction plus distillation term) should be introduced with an explicit equation in the methods section to avoid ambiguity when comparing to the baseline least-squares formulation.
- Figure captions for the stability and accuracy plots would benefit from stating the exact network architectures, layer counts, and training epochs used, allowing readers to reproduce the setup more easily.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical integration of established methods
full rationale
The paper's derivation chain consists of applying standard Koopman operator theory for linearization combined with knowledge distillation to extract models from pre-trained networks. The central result is an empirical demonstration on MNIST and Fashion-MNIST that this combination yields higher classification accuracy and numerical stability than plain least-squares Koopman approximation. No step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the method is a novel but non-circular synthesis of two independent, externally validated techniques, with performance claims resting on direct numerical comparison rather than tautological renaming or internal fitting.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Koopman operator theory can approximate the nonlinear dynamics of a neural network via linear operators in a lifted function space
- domain assumption Knowledge distillation can transfer classification behavior from a pre-trained network to a linearized model
Reference graph
Works this paper leans on
-
[1]
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, May 2015. DOI:10.1038/nature14539
-
[2]
E. Strubell, A. Ganesh, and A. McCallum. “Energy and pol- icy considerations for deep learning in NLP ,” Proc. 57th Ann . Meeting Assoc. Comp. Linguistics, pp. 3645–3650, July 2019 . DOI:10.18653/v1/P19-1355
-
[3]
Energy and policy considerations for modern deep learning research,
E. Strubell, A. Ganesh, and A. McCallum. “Energy and policy considerations for modern deep learning research,” Proc. A AAI Conf. Artificial Intelligence, vol. 34, no. 09, pp. 13693–13 696, February 2020. DOI:10.1609/aaai.v34i09.7123
-
[4]
Pruning and quantization for deep neural network acceleration: A su r- vey,
T. Liang, J. Glossner, L. Wang, S. Shi, and X. Zhang, “Pruning and quantization for deep neural network acceleration: A su r- vey,” Neurocomputing, vol. 461, pp. 370–403, October 2021. DOI:10.1016/j.neucom.2021.07.045
-
[5]
A survey on deep neural network pruning: Taxonomy, comparison, analysis, and rec- ommendations,
H. Cheng, M. Zhang and J. Q. Shi, “A survey on deep neural network pruning: Taxonomy, comparison, analysis, and rec- ommendations,” IEEE Trans. Pattern Analysis & Machine In- telligence vol. 46, no. 12, pp. 10558–10578, December 2024. DOI:10.1109/TPAMI.2024.3447085
-
[6]
Deep learning with coherent nanophotonic c ir- cuits,
Y . Shen, N. C. Harris, S. Skirlo, M. Prabhu, T. Baehr-Jones, M. Hochberg, X. Sun, S. Zhao, H. Larochelle, D. Englund, and M. Soljaˇ ci´ c, “Deep learning with coherent nanophotonic c ir- cuits,” Nature Photon., vol. 11, no. 7, pp. 441–446, June 2017. DOI:10.1038/nphoton.2017.93
-
[7]
Infer- ence in artificial intelligence with deep optics and photon- ics,
G. Wetzstein, A. Ozcan, S. Gigan, S. Fan, D. Englund, M. Soljaˇ ci´ c, C. Denz, D. A. B. Miller, and D. Psaltis, “Infer- ence in artificial intelligence with deep optics and photon- ics,” Nature, vol. 588, no. 7836, pp. 39–47, December 2020. DOI:10.1038/s41586-020-2973-6
-
[8]
Roadmap on Neuromorphic Photonics,
B. J. Shastri, A. N. Tait, T. Ferreira de Lima, W. H. P . Per- nice, H. Bhaskaran, C. D. Wright, and P . R. Prucnal, “Pho- tonics for artificial intelligence and neuromorphic comput ing,” Nature Photon. , vol. 15, no. 2, pp. 102–114, January 2021. DOI:10.1038/s41566-020-00754-y
-
[9]
Fully nonlinear neu- romorphic computing with linear wave scattering,
C. C. Wanjura and F. Marquardt, “Fully nonlinear neu- romorphic computing with linear wave scattering,” Nature Phys., vol. 20, no. 9, pp. 1434–1440, September 2024. DOI:10.1038/s41567-024-02534-9
-
[10]
Single-chip photonic deep neural network with forward-only training,
S. Bandyopadhyay, A. Sludds, S. Krastanov, R. Hamerly, N. Harris, D. Bunandar, M. Streshinsky, M. Hochberg, and D. Englund, “Single-chip photonic deep neural network with forward-only training,” Nature Photon. , vol. 18, no. 12, pp. 1335–1343, December 2024. DOI:10.1038 /s41566-024-01567- z
2024
-
[11]
A sur- vey on silicon photonics for deep learning,
F. P . Sunny, E. Taheri, M. Nikdast, and S. Pasricha, “A sur- vey on silicon photonics for deep learning,” ACM J. Emerging Tech. Comp. System , vol. 17, no. 4, article no. 61, June 2021. DOI:10.1145/3459009
-
[12]
A r- tificial neural networks for photonic applications—from al go- rithms to implementation: tutorial,
P . Freire, E. Manuylovich, J. Prilepsky, and S. Turitsyn, “A r- tificial neural networks for photonic applications—from al go- rithms to implementation: tutorial,” Adv. Opt. Photon. vol. 15, no. 3, pp. 739–834 September 2023. DOI:10.1364 /AOP .484119
2023
-
[13]
S. Abreu, I. Boikov, M. Goldmann, T. Jonuzi, A. Lupo, S. Masaad, L. Nguyen, E. Picco, G. Pourcel, A. Skalli, L. Ta- landier, B. V ettelschoss, E. A. Vlieg, A. Argyris, P . Bienst - man, D. Brunner, J. Dambre, L. Daudet, J.D. Domenech, I. Fischer, F. Horst, S. Massar, C. R. Mirasso, B. J. O ffrein, A. Rossi, M. C. Soriano, S. Sygletos, and S. K. Turitsyn, “...
-
[14]
An optical neural network using less than 1 photon per multiplication,
T. Wang, S.-Y . Ma, L. G. Wright, T. Onodera, B. C. Richard, and P . L. McMahon, “An optical neural network using less than 1 photon per multiplication,” Nature Comm., vol. 13, no. 1, ar- ticle no. 123, January 2022. DOI:10.1038 /s41467-021-27774-8
2022
-
[15]
Integrated photonic en- coder for low power and high-speed image processing,
X. Wang, B. Redding, N. Karl, C. Long, Z. Zhu, J. Skowronek, S. Pang, D. Brady, and R. Sarma, “Integrated photonic en- coder for low power and high-speed image processing,” Na- ture Comm. , vol ˙15, no. 1, article no. 4510, May 2024. DOI:10.1038/s41467-024-48099-2
-
[16]
S. Sunada, T. Niiyama, K. Kanno, R. Nogami, A. R¨ ohm, T. Awano, and A. Uchida, “Blending optimal control and biolog- ically plausible learning for noise-robust physical neura l net- works,” Phys. Rev. Lett. , vol. 134, no. 1, article no. 017301, January 2025. DOI:10.1103/PhysRevLett.134.017301
-
[17]
All-optical no n- linear activation function for photonic neural networks,
M. Miscuglio, A. Mehrabian, Z. Hu, S. I. Azzam, J. George, A. V . Kildishev, M. Pelton, and V . J. Sorger, “All-optical no n- linear activation function for photonic neural networks,” Opt. Mater . Expressvol. 8, no. 12, pp. 3851–3863, December 2018. DOI:10.1364/OME.8.003851
-
[18]
All-optical neural network with nonli n- ear activation functions,
Y . Zuo, B. Li, Y . Zhao, Y . Jiang, Y .-C. Chen, P . Chen, G.-B. Jo, J. Liu, and S. Du, “All-optical neural network with nonli n- ear activation functions,” Optica, vol. 6, no. 9, pp. 1132–1137, September 2019. DOI:10.1364/OPTICA.6.001132
-
[19]
Experimental realization of any discrete unitary operato r,
M. Reck, A. Zeilinger, H. J. Bernstein, and P . Philip, “Experimental realization of any discrete unitary operato r,” Phys. Rev. Lett. , vol. 73, no. 1, pp. 58–61, July 1994. DOI:10.1103/PhysRevLett.73.58
-
[20]
Pho- tonic matrix multiplication lights up photonic accelerato r and beyond,
H. Zhou, J. Dong, J. Cheng, W. Dong, C. Huang, Y . Shen, Q. Zhang, M. Gu, C. Qian, H. Chen, Z. Ruan, and X. Zhang, “Pho- tonic matrix multiplication lights up photonic accelerato r and beyond,” Light Sci. Appl. vol. 11, no. 1, article no. 30, January
-
[21]
DOI:10.1038/s41377-022-00717-8
-
[22]
Integrated pho- tonic tensor processing unit for a matrix multiply: A review ,
N. Peserico, B. J. Shastri and V . J. Sorger, “Integrated pho- tonic tensor processing unit for a matrix multiply: A review ,” J. Lightwave Tech., vol. 41, no. 12, pp. 3704–3716, June, 2023. DOI:10.1109/JLT.2023.3269957
-
[23]
Universal photonic artificial intelligence a cceler- ation,
S. R. Ahmed, R. Baghdadi, M. Bernadskiy, N. Bowman, R. Braid, J. Carr, C. Chen, P . Ciccarella, M. Cole, J. Cooke, K. Desai, C. Dorta, J. Elmhurst, B. Gardiner, E. Greenwald, S. Gupta, P . Husbands, B. Jones, A. Kopa, H. J. Lee, A. Mad- havan, A. Mendrela, N. Moore, L. Nair, A. Om, S. Patel, R. Patro, R. Pellowski, E. Radhakrishnani, S. Sane, N. Sarkis, J...
-
[24]
Hamiltonian systems and transformation in Hilbert space,
B. O. Koopman, “Hamiltonian systems and transformation in Hilbert space,” Proc. Natl. Acad. Sci. , vol. 17, no. 5, pp. 315– 318, May 1931. DOI: 10.1073 /pnas.17.5.315
1931
-
[25]
Koopman operator, geometry, and learning of dy- namical systems,
I. Mezi´ c, “Koopman operator, geometry, and learning of dy- namical systems,” Notices of Amer . Math. Soc. , vol. 68, no. 6, pp. 1087–1105, August 2021. DOI: 10.1090 /noti2306
2021
-
[26]
Journal of Statistical Mechanics: Theory and Experiment , author =
N. Sugishita, K. Kinjo, and J. Ohkubo, “Extraction of non- linearity in neural networks with Koopman operator,” J. Stat. Mech., vol. 2024, no. 7, article no. 073401, July 2024. DOI:10.1088/1742-5468/ad5713
-
[27]
Represent- ing neural network layers as linear operations via Koop- man operator theory,
N. S. Aswani, S. Jabari and M. Shafique, “Represent- ing neural network layers as linear operations via Koop- man operator theory,” Proc. 3rd Workshop on Unify- ing Representations in Neural Models, December, 2025. https://openreview.net/forum?id=lksyVbX4qW
2025
-
[28]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledg e in a neural network,” arXiv preprint, arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Modern Koopman theory for dynamical systems,
S. L. Brunton, M. Budis ˇi´ c, E. Kaiser, and J. N. Kutz, “Modern Koopman theory for dynamical systems,” SIAM Rev., vol. 64, pp. 229–340, May 2022. DOI: 10.1137 /21M1401243
2022
-
[30]
A data- driven approximation of the Koopman operator: Extending dy - namic mode decomposition,
M. O. Williams, I. G. Kevrekidis, and C. W. Rowley, “A data- driven approximation of the Koopman operator: Extending dy - namic mode decomposition,” J. Nonlinear Sci. , vol. 25, no. 6, pp. 1307–1346, June (2015). DOI: 10.1007 /s00332-015-9258-5
2015
-
[31]
Dynamic mode decomposition of numerical and experimental data,
P . J. Schmid, “Dynamic mode decomposition of numerical and experimental data,” J. Fluid Mech. , vol. 656, pp. 5–28, July
-
[32]
DOI: 10.1017/S0022112010001217
-
[33]
Gradient-based learning applied to document recognition , journal =
Y . LeCun, L. Bottou, Y . Bengio, and P . Ha ffner, “Gradient- based learning applied to document recognition,” Proc. IEEE, vol. 86, no. 11, pp. 2278–2324, November, 1998. DOI: 10.1109/5.726791
-
[34]
MNIST handwritten digit database,
Y . LeCun, C. Cortes, and C. J. Burges, “MNIST handwritten digit database,” A TT Labs [Online]. Available: http://yann. lecun.com/exdb/mnist, 2, 2010
2010
-
[35]
Deep residual learning for image recognition
K. He, X. Zhang, S. Ren, and J. Sun. “Deep residual learn- ing for image recognition,” Proc. IEEE Conf. Comp. Vi- sion Pattern Recognition, pp. 770–778, June 2016. DOI: 10.1109/CVPR.2016.90
-
[36]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
H. Xiao, K. Rasul, and R. V ollgraf. “Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithm s,” arXiv preprint, arXiv:1708.07747
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.