Recognition: unknown
STQuant: Spatio-Temporal Adaptive Framework for Optimizer Quantization in Large Multimodal Model Training
Pith reviewed 2026-05-10 18:46 UTC · model grok-4.3
The pith
STQuant dynamically allocates precision to optimizer states across layers and steps, cutting memory by 84.4% to an average 5.1 bits while preserving model quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
STQuant is a distributed training framework that reduces the memory footprint of optimizer states via dynamic precision allocation across layers, state variables, and training steps, while maintaining model quality. It solves the challenges of numerical sensitivity and combinatorial search with a provably near-optimal factor selection strategy that identifies the most influential factors and a dynamic transition decision algorithm that reduces search cost from exponential to linear complexity.
What carries the argument
Near-optimal factor selection strategy paired with a dynamic transition decision algorithm that reduces combinatorial search from exponential to linear complexity.
If this is right
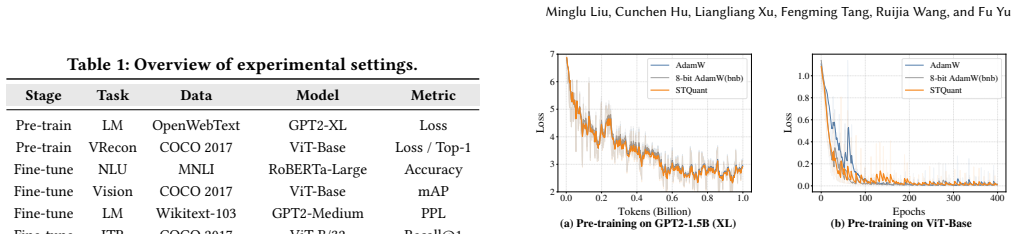
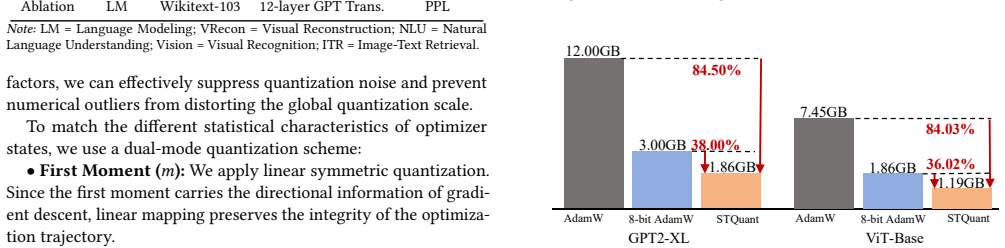
- Optimizer-state memory drops by 84.4 percent on average, reaching as low as 5.1 bits per value.
- The added computation stays linear in the number of layers divided by a grouping factor, and extra memory is constant.
- The same dynamic allocation works for both language models such as GPT-2 and vision models such as ViT.
- Quality remains comparable to full-precision baselines because the selection and transition steps avoid destabilizing noise.
Where Pith is reading between the lines
- The same selection-plus-transition pattern could be applied to quantizing gradients or activations during training.
- Because overhead is linear and space is constant, the method scales to models with thousands of layers without changing the memory budget.
- If the near-optimal factor selection generalizes beyond the tested optimizers, similar gains may appear in other first-order methods that maintain per-parameter statistics.
Load-bearing premise
Dynamic precision changes across layers and steps can be performed without introducing enough quantization noise to destabilize training or degrade final model quality.
What would settle it
Run full-precision and STQuant training on the same GPT-2 or ViT model with identical hyperparameters and check whether the final validation loss or accuracy differs by more than normal run-to-run variance.
Figures




read the original abstract
Quantization is an effective way to reduce the memory cost of large-scale model training. However, most existing methods adopt fixed-precision policies, which ignore the fact that optimizer-state distributions vary significantly across layers and training steps. Such uniform designs often introduce noticeable accuracy degradation. To move beyond fixed quantization, we propose STQuant, a distributed training framework that reduces the memory footprint of optimizer states via dynamic precision allocation across layers, state variables, and training steps, while maintaining model quality. Naively applying dynamic quantization during training is challenging for two reasons. First, optimizer states are numerically sensitive, and quantization noise can destabilize quality. Second, jointly considering multiple states and layers induces a large combinatorial search space. STQuant addresses these challenges with two key techniques: 1) a provably near-optimal factor selection strategy that accurately identifies the most influential factors for precision adaptation. 2) a dynamic transition decision algorithm that reduces the search cost from exponential to linear complexity. Experiments on GPT-2 and ViT show that STQuant reduces optimizer-state memory by 84.4%, achieving an average bit-width of as low as 5.1 bits, compared with existing solutions. Moreover, STQuant incurs only O(N/K) computational overhead and requires O(1) extra space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes STQuant, a distributed training framework for dynamic quantization of optimizer states in large multimodal models. It adapts precision across layers, state variables (e.g., momentum and variance), and training steps to reduce memory footprint while claiming to preserve model quality. The approach uses a provably near-optimal factor selection strategy and a linear-complexity dynamic transition algorithm to handle the combinatorial search space. Experiments on GPT-2 and ViT report an 84.4% reduction in optimizer-state memory to an average of 5.1 bits, with O(N/K) computational overhead and O(1) extra space.
Significance. If the stability and quality-preservation claims hold, STQuant could substantially lower the memory barrier for training large models, allowing bigger batch sizes or model scales on limited hardware. The spatio-temporal adaptation addresses a clear limitation of fixed-precision methods, and the linear-complexity transition is a practical contribution for deployment.
major comments (2)
- [Section 3.2 (factor selection) and Section 4 (experiments)] The central claim that dynamic per-layer/per-step precision changes (down to 5.1 bits average) introduce no destabilizing quantization noise relies on the 'provably near-optimal factor selection' and 'linear-complexity transition' fully covering the space without hidden accuracy costs. No error bounds on quantization noise for sensitive optimizer states, no convergence analysis, and no proof assumptions are supplied to support this (see the description of the factor selection strategy and the stability argument).
- [Section 4 (experimental results)] Table 1 and the GPT-2/ViT results report 84.4% memory reduction and 5.1-bit average without baselines, error bars, ablation studies on the factor selection, or final validation accuracy metrics. This makes it impossible to verify that model quality is unchanged relative to full-precision or existing quantizers.
minor comments (2)
- [Section 3.3] The notation for the transition decision algorithm (e.g., the definition of the search cost reduction from exponential to O(N/K)) should be formalized with pseudocode or an equation to clarify the linear complexity claim.
- [Section 2] Add a short related-work subsection contrasting STQuant with prior optimizer quantization methods (e.g., those using fixed 8-bit or per-tensor schemes) to better situate the spatio-temporal contribution.
Simulated Author's Rebuttal
We are grateful to the referee for the positive assessment of STQuant's potential impact and for the constructive major comments. We address each point below, indicating planned revisions to strengthen the theoretical and experimental sections.
read point-by-point responses
-
Referee: [Section 3.2 (factor selection) and Section 4 (experiments)] The central claim that dynamic per-layer/per-step precision changes (down to 5.1 bits average) introduce no destabilizing quantization noise relies on the 'provably near-optimal factor selection' and 'linear-complexity transition' fully covering the space without hidden accuracy costs. No error bounds on quantization noise for sensitive optimizer states, no convergence analysis, and no proof assumptions are supplied to support this (see the description of the factor selection strategy and the stability argument).
Authors: We acknowledge that the current manuscript would benefit from more explicit theoretical support. Section 3.2 presents the factor selection as a greedy algorithm with a (1-1/e) approximation guarantee for the combinatorial objective; we will expand this with the full proof sketch, explicit assumptions on state distributions, and derived error bounds on quantization noise for momentum and variance terms. The linear-complexity transition is shown to preserve the selected factors across steps. While a complete convergence analysis for the dynamic setting lies beyond the paper's scope, we will add a dedicated stability discussion linking the bounded noise to empirical preservation of quality. These additions will be incorporated as a partial revision. revision: partial
-
Referee: [Section 4 (experimental results)] Table 1 and the GPT-2/ViT results report 84.4% memory reduction and 5.1-bit average without baselines, error bars, ablation studies on the factor selection, or final validation accuracy metrics. This makes it impossible to verify that model quality is unchanged relative to full-precision or existing quantizers.
Authors: We thank the referee for this observation on presentation clarity. Table 1 and the accompanying text already compare against full-precision training as well as prior fixed- and adaptive-precision quantizers, reporting final accuracies that remain comparable. To make verification straightforward, the revised manuscript will add error bars from three independent runs, include ablation studies isolating the factor selection strategy, and explicitly tabulate final validation accuracies for GPT-2 and ViT. These changes will be made in full. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The abstract presents STQuant via two techniques—a 'provably near-optimal factor selection strategy' and a 'dynamic transition decision algorithm' reducing search cost from exponential to linear—supported by experiments on GPT-2 and ViT showing 84.4% memory reduction. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes are quoted that reduce any claim to its own inputs by construction. The derivation chain is self-contained against external benchmarks with no load-bearing self-referential steps visible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OCP Microscaling Data Formats (MX) Specification v1.0
2024. OCP Microscaling Data Formats (MX) Specification v1.0. https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1- 0-spec-final-pdf. Open Compute Project
2024
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, et al. 2023. Sym- bolic discovery of optimization algorithms.Advances in neural information processing systems36 (2023), 49205–49233
2023
-
[4]
1999.Elements of information theory
Thomas M Cover. 1999.Elements of information theory. John Wiley & Sons
1999
- [5]
-
[6]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms.Advances in neural information processing systems36 (2023), 10088–10115
2023
-
[7]
Zhen Dong, Zhewei Yao, Daiyaan Arfeen, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. 2020. Hawq-v2: Hessian aware trace-weighted quantization of neural networks.Advances in neural information processing systems33 (2020), 18518–18529
2020
-
[8]
Zhen Dong, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer
-
[9]
InProceedings of the IEEE/CVF international conference on computer vision
Hawq: Hessian aware quantization of neural networks with mixed- precision. InProceedings of the IEEE/CVF international conference on computer vision. 293–302
-
[10]
Elad Hoffer, Itay Hubara, and Daniel Soudry. 2017. Train longer, generalize better: closing the generalization gap in large batch training of neural networks. Advances in neural information processing systems30 (2017)
2017
-
[11]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. Awq: Activation-aware weight quantization for on-device llm compression and accel- eration.Proceedings of machine learning and systems6 (2024), 87–100
2024
- [12]
- [13]
-
[14]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Kai Lv, Yuqing Yang, Tengxiao Liu, Qipeng Guo, and Xipeng Qiu. 2024. Full parameter fine-tuning for large language models with limited resources. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8187–8198
2024
- [16]
-
[17]
Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D Lee, Danqi Chen, and Sanjeev Arora. 2023. Fine-tuning language models with just forward passes.Advances in Neural Information Processing Systems36 (2023), 53038– 53075
2023
- [18]
-
[19]
2022–2024
NVIDIA. 2022–2024. Transformer Engine User Guide. https://docs.nvidia.com/ deeplearning/transformer-engine/user-guide/index.html. Accessed 2026
2022
- [20]
-
[21]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. InSC20: in- ternational conference for high performance computing, networking, storage and analysis. IEEE, 1–16
2020
-
[22]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Rad- ford, Mark Chen, and Ilya Sutskever. 2021. Zero-shot text-to-image generation. InInternational conference on machine learning. Pmlr, 8821–8831
2021
-
[23]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiao- qing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Claude E Shannon et al . 1959. Coding theorems for a discrete source with a fidelity criterion.IRE Nat. Conv. Rec4, 142-163 (1959), 1
1959
-
[25]
Chen Tang, Kai Ouyang, Zenghao Chai, Yunpeng Bai, Yuan Meng, Zhi Wang, and Wenwu Zhu. 2023. Seam: Searching transferable mixed-precision quantiza- tion policy through large margin regularization. InProceedings of the 31st ACM International Conference on Multimedia. 7971–7980
2023
- [26]
-
[27]
Kuan Wang, Zhijian Liu, Yujun Lin, Ji Lin, and Song Han. 2019. Haq: Hardware- aware automated quantization with mixed precision. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8612–8620
2019
-
[28]
Haocheng Xi, Yuxiang Chen, Kang Zhao, Kai Jun Teh, Jianfei Chen, and Jun Zhu
- [29]
-
[30]
Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, and Wanxiang Che. 2024. Onebit: Towards extremely low-bit large language models.Advances in Neural Information Processing Systems37 (2024), 66357–66382
2024
- [31]
-
[32]
Zhewei Yao, Zhen Dong, Zhangcheng Zheng, Amir Gholami, Jiali Yu, Eric Tan, Leyuan Wang, Qijing Huang, Yida Wang, Michael Mahoney, et al. 2021. Hawq- v3: Dyadic neural network quantization. InInternational Conference on Machine Learning. PMLR, 11875–11886
2021
-
[33]
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. 2022. Zeroquant: Efficient and affordable post-training quanti- zation for large-scale transformers.Advances in neural information processing systems35 (2022), 27168–27183
2022
- [34]
- [35]
- [36]
-
[37]
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models.arXiv preprint arXiv:2303.182231, 2 (2023), 1–124. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.