Recognition: no theorem link
A hardware efficient quantum residual neural network without post-selection
Pith reviewed 2026-05-10 17:57 UTC · model grok-4.3
The pith
A quantum residual neural network implements skip connections deterministically to avoid post-selection and reduce gate count.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
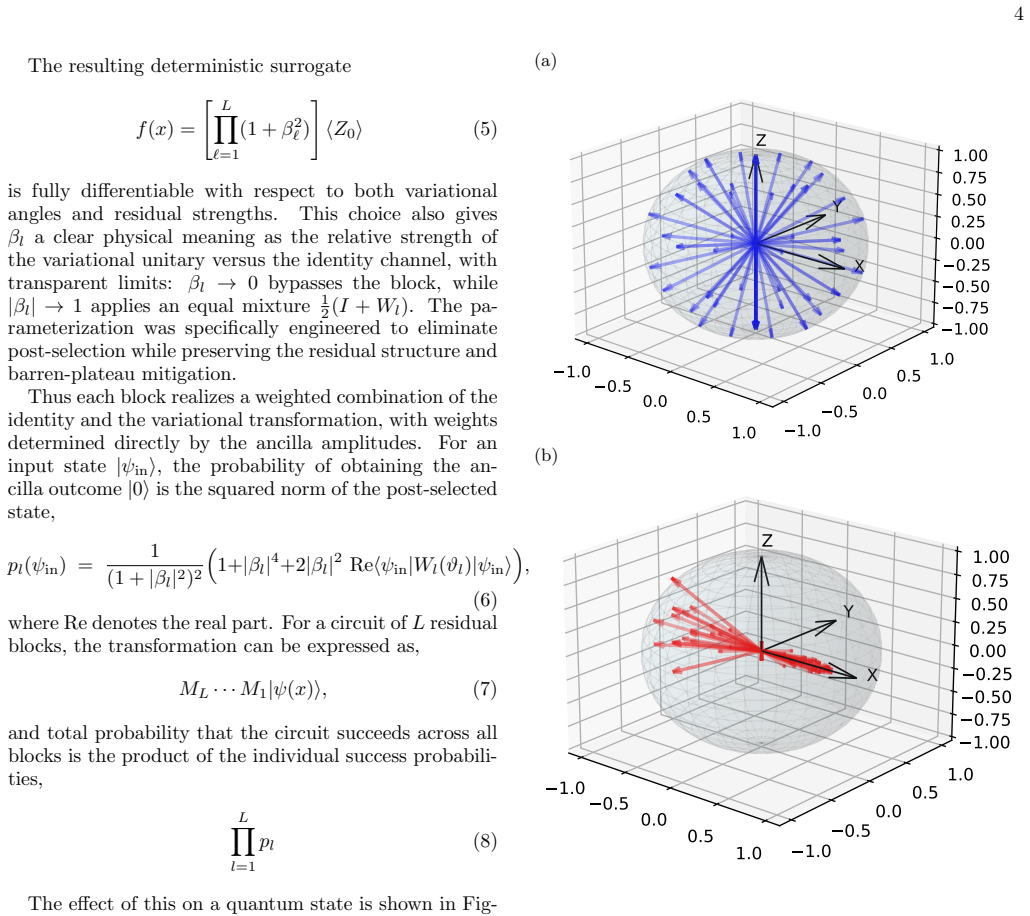
Core claim
We propose a hardware efficient quantum residual neural network which implements residual connections through a deterministic linear combination of identity and variational unitaries, enabling fully differentiable training. In contrast to the previous implementation of residual connections, our architecture avoids post-selection while preserving residual learning. Furthermore, we establish trainability of our model, mitigating barren plateaus which are considered as a major limitation of variational quantum learning models. The model achieves accuracies of 99% and 80% for binary and multi-class classifications on MNIST, CIFAR, and SARFish datasets while requiring 10x fewer gates and showing
What carries the argument
Deterministic linear combination of identity and variational unitaries that realizes residual connections inside the quantum circuit.
If this is right
- The model reaches 99 percent accuracy on binary image classification tasks such as MNIST.
- It attains 80 percent accuracy on multi-class tasks including CIFAR and SARFish.
- Gate count drops by a factor of approximately ten compared with standard variational models.
- The network exhibits adversarial robustness as an additional property of the architecture.
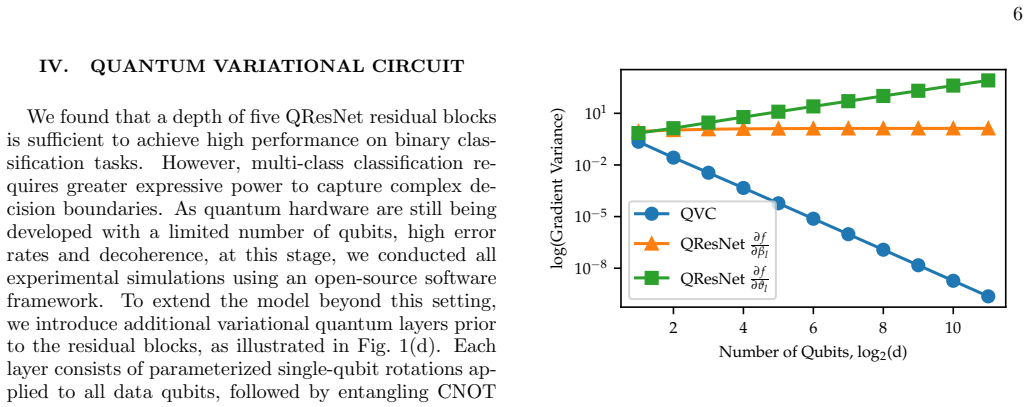
- Trainability is preserved, reducing the effect of barren plateaus on variational quantum learning.
Where Pith is reading between the lines
- The same deterministic residual construction could be applied to other variational quantum algorithms to improve gradient flow.
- Reduced gate overhead may allow deeper effective networks on noisy intermediate-scale quantum processors.
- The approach might generalize to hybrid quantum-classical pipelines for tasks beyond image classification.
- Empirical tests on actual quantum hardware would reveal how noise interacts with the linear combination step.
Load-bearing premise
The fixed linear combination of identity and variational unitaries transfers the gradient-flow and trainability benefits of classical residual connections into the quantum setting without creating new optimization barriers or noise problems.
What would settle it
Training the same architecture on circuits with significantly greater depth or on more complex multi-class datasets and checking whether barren plateaus return or accuracy falls well below reported levels would test whether the claimed trainability holds.
Figures






read the original abstract
We propose a hardware efficient quantum residual neural network which implements residual connections through a deterministic linear combination of identity and variational unitaries, enabling fully differentiable training. In contrast to the previous implementation of residual connections, our architecture avoids post-selection while preserving residual learning. Furthermore, we establish trainability of our model, mitigating barren plateaus which are considered as a major limitation of variational quantum learning models. In order to show the working of our model, we report its application to image classification tasks by training it for MNIST, CIFAR, and SARFish datasets, achieving accuracies of 99% and 80% for binary and multi-class classifications, respectively. These accuracies are comparable to previously achieved from the standard variational models, however our model requires 10x fewer gates making it better suited for resource constraint near-term quantum processors. In addition to high accuracies, the proposed architecture also demonstrates adversarial robustness which is another desirable parameter for quantum machine learning models. Overall our architecture offers a new pathway for developing accurate, robust, trainable and hardware efficient quantum machine learning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hardware-efficient quantum residual neural network that implements residual connections via a deterministic linear combination of the identity and variational unitaries. This is claimed to enable fully differentiable training without post-selection, mitigate barren plateaus, achieve 99% binary and 80% multi-class accuracy on MNIST/CIFAR/SARFish datasets with 10x fewer gates than standard variational models, and demonstrate adversarial robustness.
Significance. If the linear-combination construction is unitary and demonstrably preserves gradient flow without introducing new trainability or noise issues, the architecture could meaningfully address barren-plateaus and hardware constraints in variational quantum machine learning. The reported gate reduction and accuracies would then represent a practical advance for NISQ devices; however, the abstract provides no derivations, circuit diagrams, or quantitative evidence, so the significance cannot yet be assessed.
major comments (2)
- Abstract (and the architecture section): the residual connection is realized by a 'deterministic linear combination of identity and variational unitaries'. A general linear combination αI + βV with V unitary is not unitary unless α, β are specially chosen so that (αI + βV)†(αI + βV) = I. The manuscript must supply the explicit coefficients, prove unitarity (or show it is a valid CPTP map via ancilla without post-selection), and confirm that the construction remains hardware-efficient. This is load-bearing for every downstream claim (trainability, 10× gate reduction, accuracies, robustness).
- Trainability claim (abstract and barren-plateau section): the paper states it 'establishes trainability … mitigating barren plateaus' yet provides no theorem, gradient-variance scaling argument, or numerical ablation. A concrete derivation or plot showing that the residual structure prevents exponential gradient decay with depth is required; without it the central advantage over standard VQCs remains unverified.
minor comments (2)
- Abstract: accuracies are stated without error bars, dataset splits, circuit depths, or exact gate-count comparisons; these details are needed for reproducibility.
- The manuscript should include explicit circuit diagrams for the proposed residual block and a clear statement of the ansatz depth and parameter count.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and evidence.
read point-by-point responses
-
Referee: Abstract (and the architecture section): the residual connection is realized by a 'deterministic linear combination of identity and variational unitaries'. A general linear combination αI + βV with V unitary is not unitary unless α, β are specially chosen so that (αI + βV)†(αI + βV) = I. The manuscript must supply the explicit coefficients, prove unitarity (or show it is a valid CPTP map via ancilla without post-selection), and confirm that the construction remains hardware-efficient. This is load-bearing for every downstream claim (trainability, 10× gate reduction, accuracies, robustness).
Authors: We agree that the unitarity of the residual operator is essential and must be demonstrated explicitly. In the revised manuscript we will state the precise coefficients α and β, provide a short proof that the linear combination yields a unitary operator (or equivalently a valid CPTP map implementable without post-selection), include the corresponding circuit diagram, and confirm that the gate count remains hardware-efficient. These additions will be placed in the architecture section and referenced from the abstract. revision: yes
-
Referee: Trainability claim (abstract and barren-plateau section): the paper states it 'establishes trainability … mitigating barren plateaus' yet provides no theorem, gradient-variance scaling argument, or numerical ablation. A concrete derivation or plot showing that the residual structure prevents exponential gradient decay with depth is required; without it the central advantage over standard VQCs remains unverified.
Authors: We acknowledge that the current manuscript lacks a quantitative argument or numerical evidence for the claimed mitigation of barren plateaus. In the revision we will add either an analytic bound on the gradient variance as a function of depth for the residual architecture or a set of numerical ablations (gradient-variance versus depth plots) comparing the residual model to standard variational circuits. This material will be inserted into the barren-plateau section and summarized in the abstract. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a new architecture for quantum residual connections via a deterministic linear combination of identity and variational unitaries, then validates it empirically through training on MNIST, CIFAR, and SARFish datasets with reported accuracies and gate counts. No load-bearing claims reduce by construction to fitted parameters, self-citations, or renamed inputs; trainability and barren-plateau mitigation are asserted from the explicit design rather than tautological re-derivation. The contrast to prior residual implementations is contextual and does not carry the central results. The chain is self-contained against external benchmarks of circuit validity and performance.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An introduction to quantum machine learning.Contem- porary Physics, 56(2):172–185, 2015
Maria Schuld, Ilya Sinayskiy, and Francesco Petruccione. An introduction to quantum machine learning.Contem- porary Physics, 56(2):172–185, 2015
2015
-
[2]
Classification with Quantum Neural Networks on Near Term Processors
Edward Farhi and Hartmut Neven. Classification with quantum neural networks on near term processors.arXiv preprint arXiv:1802.06002, 2018
work page Pith review arXiv 2018
-
[3]
Supervised learning with quantum- enhanced feature spaces.Nature, 567(7747):209–212, 2019
Vojtˇ ech Havl´ ıˇ cek, Antonio D C´ orcoles, Kristan Temme, Aram W Harrow, Abhinav Kandala, Jerry M Chow, and Jay M Gambetta. Supervised learning with quantum- enhanced feature spaces.Nature, 567(7747):209–212, 2019
2019
-
[4]
Quantum machine learning in feature hilbert spaces.Physical review letters, 122(4):040504, 2019
Maria Schuld and Nathan Killoran. Quantum machine learning in feature hilbert spaces.Physical review letters, 122(4):040504, 2019
2019
-
[5]
Benchmarking adversarially robust quantum machine learning at scale.Physical Review Research, 5(2):023186, 2023
Maxwell T West, Sarah M Erfani, Christopher Leckie, Martin Sevior, Lloyd CL Hollenberg, and Muhammad Usman. Benchmarking adversarially robust quantum machine learning at scale.Physical Review Research, 5(2):023186, 2023
2023
-
[6]
Quantum transfer learning with adversarial robustness for classifi- cation of high-resolution image datasets.Advanced Quan- tum Technologies, 8(1):2400268, 2025
Amena Khatun and Muhammad Usman. Quantum transfer learning with adversarial robustness for classifi- cation of high-resolution image datasets.Advanced Quan- tum Technologies, 8(1):2400268, 2025
2025
-
[7]
Quantum generative learning for high-resolution medical image generation
Amena Khatun, K¨ ubra Yeter Aydeniz, Yaakov S We- instein, and Muhammad Usman. Quantum generative learning for high-resolution medical image generation. Machine Learning: Science and Technology, 6(2):025032, 2025
2025
-
[8]
Quantum computing for pattern classification
Maria Schuld, Ilya Sinayskiy, and Francesco Petruccione. Quantum computing for pattern classification. InPacific Rim International Conference on Artificial Intelligence, pages 208–220. Springer, 2014
2014
-
[9]
Yanqiu Wu, Eromanga Adermann, Chandra Thapa, Seyit Camtepe, Hajime Suzuki, and Muhammad Usman. Radio signal classification by adversarially robust quan- tum machine learning.arXiv preprint arXiv:2312.07821, 2023
-
[10]
The power of quantum neural networks.Nature computational sci- ence, 1(6):403–409, 2021
Amira Abbas, David Sutter, Christa Zoufal, Aur´ elien Lucchi, Alessio Figalli, and Stefan Woerner. The power of quantum neural networks.Nature computational sci- ence, 1(6):403–409, 2021
2021
-
[11]
Power of data in quantum machine learn- ing.Nature communications, 12(1):2631, 2021
Hsin-Yuan Huang, Michael Broughton, Masoud Mohseni, Ryan Babbush, Sergio Boixo, Hartmut Neven, and Jar- rod R McClean. Power of data in quantum machine learn- ing.Nature communications, 12(1):2631, 2021
2021
-
[12]
Classical au- toencoder distillation of quantum adversarial manipula- tions.Phys
Amena Khatun and Muhammad Usman. Classical au- toencoder distillation of quantum adversarial manipula- tions.Phys. Rev. Res., 7:L042054, Dec 2025
2025
-
[13]
Towards quantum en- hanced adversarial robustness in machine learning.Na- ture Machine Intelligence, 5(6):581–589, 2023
Maxwell T West, Shu-Lok Tsang, Jia S Low, Charles D Hill, Christopher Leckie, Lloyd CL Hollenberg, Sarah M Erfani, and Muhammad Usman. Towards quantum en- hanced adversarial robustness in machine learning.Na- ture Machine Intelligence, 5(6):581–589, 2023
2023
-
[14]
Barren plateaus in variational quantum com- puting.Nature Reviews Physics, pages 1–16, 2025
Martin Larocca, Supanut Thanasilp, Samson Wang, Ku- nal Sharma, Jacob Biamonte, Patrick J Coles, Lukasz Cincio, Jarrod R McClean, Zo¨ e Holmes, and Marco Cerezo. Barren plateaus in variational quantum com- puting.Nature Reviews Physics, pages 1–16, 2025
2025
-
[15]
Subtleties in the train- ability of quantum machine learning models.Quantum Machine Intelligence, 5(1):21, 2023
Supanut Thanasilp, Samson Wang, Nhat Anh Nghiem, Patrick Coles, and Marco Cerezo. Subtleties in the train- ability of quantum machine learning models.Quantum Machine Intelligence, 5(1):21, 2023
2023
-
[16]
Efficient estimation of trainability for variational quantum circuits.PRX Quan- tum, 4(4):040335, 2023
Valentin Heyraud, Zejian Li, Kaelan Donatella, Alexan- dre Le Boit´ e, and Cristiano Ciuti. Efficient estimation of trainability for variational quantum circuits.PRX Quan- tum, 4(4):040335, 2023
2023
-
[17]
Nonunitary quantum machine learning
Jamie Heredge, Maxwell West, Lloyd Hollenberg, and Martin Sevior. Nonunitary quantum machine learning. Phys. Rev. Appl., 23:044046, Apr 2025
2025
-
[18]
Training-efficient density quantum machine learning.npj Quantum Information, 11(1):172, Nov 2025
Brian Coyle, Snehal Raj, Natansh Mathur, El Amine Cherrat, Nishant Jain, Skander Kazdaghli, and Iordanis Kerenidis. Training-efficient density quantum machine learning.npj Quantum Information, 11(1):172, Nov 2025
2025
-
[19]
Nicholas S DiBrita, Jason Han, and Tirthak Patel. Resq: A novel framework to implement residual neural networks on analog rydberg atom quantum computers. arXiv preprint arXiv:2506.21537, 2025
-
[20]
A quantum residual attention neural network for high- precision material property prediction: Q
Qingchuan Yang, Wenjun Zhang, and Lianfu Wei. A quantum residual attention neural network for high- precision material property prediction: Q. yang et al. 10 Quantum Information Processing, 24(2):53, 2025
2025
-
[21]
Maria Kieferova, Ortiz Marrero Carlos, and Nathan Wiebe. Quantum generative training using r\’enyi di- vergences.arXiv preprint arXiv:2106.09567, 2021
-
[22]
Avoiding bar- ren plateaus with entanglement.Physical Review A, 111(2):022426, 2025
Yuhan Yao and Yoshihiko Hasegawa. Avoiding bar- ren plateaus with entanglement.Physical Review A, 111(2):022426, 2025
2025
-
[23]
Robust data encodings for quantum classifiers.Physical Review A, 102(3):032420, 2020
Ryan LaRose and Brian Coyle. Robust data encodings for quantum classifiers.Physical Review A, 102(3):032420, 2020
2020
-
[24]
Introduction to Haar Measure Tools in Quantum Information: A Beginner’s Tutorial.Quan- tum, 8:1340, May 2024
Antonio Anna Mele. Introduction to Haar Measure Tools in Quantum Information: A Beginner’s Tutorial.Quan- tum, 8:1340, May 2024
2024
-
[25]
Quantum adversarial machine learning.Physical Review Research, 2(3):033212, 2020
Sirui Lu, Lu-Ming Duan, and Dong-Ling Deng. Quantum adversarial machine learning.Physical Review Research, 2(3):033212, 2020
2020
-
[26]
Experimental quantum ad- versarial learning with programmable superconducting qubits.Nature Computational Science, 2(11):711–717, 2022
Wenhui Ren, Weikang Li, Shibo Xu, Ke Wang, Wenjie Jiang, Feitong Jin, Xuhao Zhu, Jiachen Chen, Zixuan Song, Pengfei Zhang, et al. Experimental quantum ad- versarial learning with programmable superconducting qubits.Nature Computational Science, 2(11):711–717, 2022
2022
-
[27]
Universal adversar- ial examples and perturbations for quantum classifiers
Weiyuan Gong and Dong-Ling Deng. Universal adversar- ial examples and perturbations for quantum classifiers. National Science Review, 9(6):nwab130, 2022
2022
-
[28]
Maximilian Wendlinger, Kilian Tscharke, and Pascal De- bus. A comparative analysis of adversarial robustness for quantum and classical machine learning models.arXiv preprint arXiv:2404.16154, 2024
-
[29]
Generating universal adversarial perturbations for quan- tum classifiers
Gautham Anil, Vishnu Vinod, and Apurva Narayan. Generating universal adversarial perturbations for quan- tum classifiers. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 10891–10899, 2024
2024
-
[30]
Quantum neural networks under depolarization noise: Exploring white-box attacks and defenses.Quan- tum Machine Intelligence, 6(2):83, 2024
David Winderl, Nicola Franco, and Jeanette Miriam Lorenz. Quantum neural networks under depolarization noise: Exploring white-box attacks and defenses.Quan- tum Machine Intelligence, 6(2):83, 2024
2024
-
[31]
Robustness verification of quantum classifiers
Ji Guan, Wang Fang, and Mingsheng Ying. Robustness verification of quantum classifiers. InComputer Aided Verification: 33rd International Conference, CAV 2021, Virtual Event, July 20–23, 2021, Proceedings, Part I 33, pages 151–174. Springer, 2021
2021
-
[32]
Vulnerability of quantum classification to adversarial perturbations.Physical Re- view A, 101(6):062331, 2020
Nana Liu and Peter Wittek. Vulnerability of quantum classification to adversarial perturbations.Physical Re- view A, 101(6):062331, 2020
2020
-
[33]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
Ville Bergholm, Josh Izaac, Maria Schuld, Christian Gogolin, Shahnawaz Ahmed, Vishnu Ajith, M Sohaib Alam, Guillermo Alonso-Linaje, B AkashNarayanan, Ali Asadi, et al. Pennylane: Automatic differentiation of hybrid quantum-classical computations.arXiv preprint arXiv:1811.04968, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[34]
Pytorch: An imperative style, high-performance deep learning li- brary.Advances in neural information processing sys- tems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zem- ing Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning li- brary.Advances in neural information processing sys- tems, 32, 2019
2019
-
[35]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[36]
Learning multi- ple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multi- ple layers of features from tiny images. 2009
2009
-
[37]
The sarfish dataset and challenge
Connor Luckett, Benjamin McCarthy, Tri-Tan Cao, and Antonio Robles-Kelly. The sarfish dataset and challenge. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 752–761, 2024. 11 X. APPENDIX A. Barren Plateau Calculations We show the calculations to demonstrate the lack of barren plateau for our cost function for QRes...
2024
-
[38]
=tr(I) =d, we get: V ar ∂f ∂βl = 4 3 β2 max dtr(ρ2 0)−1 d2 −1 ,(30) wheredis the dimension of the unitary matrix which is 2n fornqubits. As mentioned in the main text, for fixed βls, we do not take the integral and these terms have a barren plateau withV ar h ∂f 2 ∂βl i ∝ 1 d, however, if we pick the domain ofβ l to be √ d, then we get: V ar ∂f ∂βl = 4 3 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.