Recognition: 2 theorem links
· Lean TheoremMining Electronic Health Records to Investigate Effectiveness of Ensemble Deep Clustering
Pith reviewed 2026-05-10 18:37 UTC · model grok-4.3
The pith
An ensemble deep clustering method combined with traditional techniques achieves the highest performance in grouping heart failure patients from electronic health records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
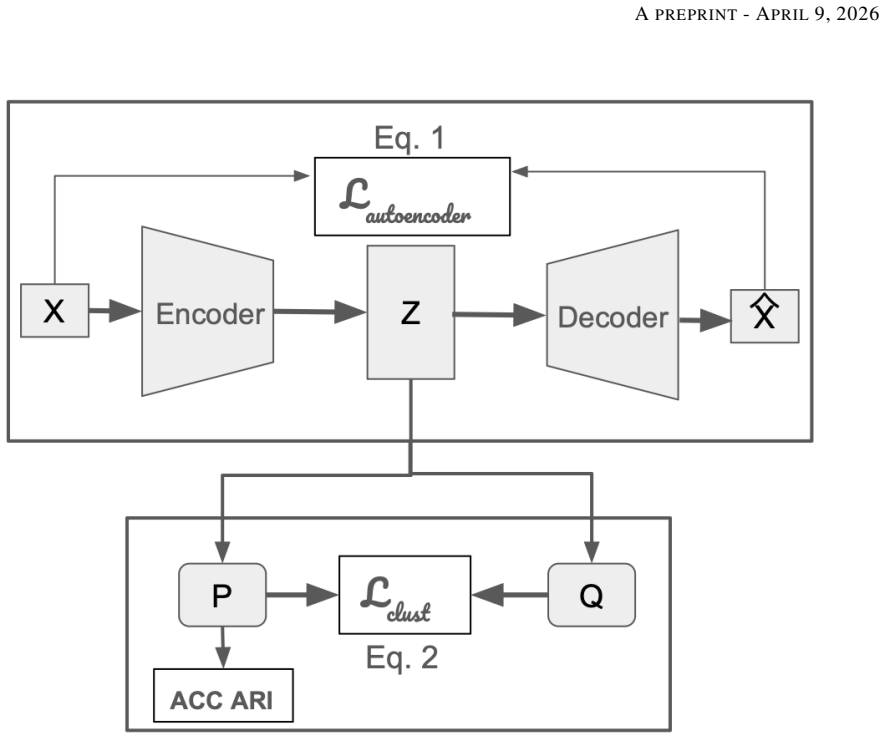
The paper establishes that traditional clustering methods perform robustly on tabular EHR data while deep learning approaches underperform due to their design for image clustering. It introduces an ensemble-based deep clustering approach that aggregates cluster assignments from multiple embedding dimensions. When combined with traditional clustering in a novel ensemble framework, this method delivers the best overall performance ranking across 14 diverse clustering methods and multiple patient cohorts. The findings highlight advantages of combining approaches and the importance of biological sex-specific clustering of EHR data.
What carries the argument
Ensemble embedding for deep clustering that aggregates cluster assignments obtained from multiple embedding dimensions rather than a single fixed embedding space, integrated with traditional clustering methods.
Load-bearing premise
Deep learning methods designed for image data inherently underperform on tabular EHR data, and aggregating assignments from multiple embedding dimensions reliably improves clustering quality without overfitting or selection bias.
What would settle it
A direct comparison showing that a single deep embedding space achieves equal or better clustering quality than the ensemble aggregation on the same heart failure EHR cohorts would falsify the advantage of the proposed method.
Figures


read the original abstract
In electronic health records (EHRs), clustering patients and distinguishing disease subtypes are key tasks to elucidate pathophysiology and aid clinical decision-making. However, clustering in healthcare informatics is still based on traditional methods, especially K-means, and has achieved limited success when applied to embedding representations learned by autoencoders as hybrid methods. This paper investigates the effectiveness of traditional, hybrid, and deep learning methods in heart failure patient cohorts using real EHR data from the All of Us Research Program. Traditional clustering methods perform robustly because deep learning approaches are specifically designed for image clustering, a task that differs substantially from the tabular EHR data setting. To address the shortcomings of deep clustering, we introduce an ensemble-based deep clustering approach that aggregates cluster assignments obtained from multiple embedding dimensions, rather than relying on a single fixed embedding space. When combined with traditional clustering in a novel ensemble framework, the proposed ensemble embedding for deep clustering delivers the best overall performance ranking across 14 diverse clustering methods and multiple patient cohorts. This paper underscores the importance of biological sex-specific clustering of EHR data and the advantages of combining traditional and deep clustering approaches over a single method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that traditional clustering methods perform robustly on tabular EHR data for heart failure patient cohorts from the All of Us program, while deep learning methods designed for images underperform. It introduces an ensemble deep clustering approach that aggregates cluster assignments from multiple embedding dimensions rather than a single fixed space. When combined with traditional clustering in a novel ensemble framework, this method is asserted to deliver the best overall performance ranking across 14 diverse clustering methods and multiple patient cohorts, while also highlighting the importance of biological sex-specific clustering.
Significance. If the empirical ranking holds under rigorous validation, the work could advance healthcare informatics by demonstrating practical benefits of hybrid ensemble strategies for patient subtyping in tabular EHR data, where pure deep clustering has seen limited success. It provides a concrete example of adapting embedding-based methods to non-image domains and emphasizes sex-specific analysis, which may inform more accurate pathophysiology studies and clinical decision support.
major comments (2)
- Abstract: The assertion that the proposed ensemble embedding for deep clustering 'delivers the best overall performance ranking' is presented without any quantitative metrics (e.g., ARI, NMI, silhouette scores), statistical tests, error bars, cohort sizes, or implementation details, leaving the central empirical claim unsupported by verifiable evidence.
- Introduction and Methods: The foundational assumption that deep learning methods 'are specifically designed for image clustering' and thus inherently limited on tabular EHR data requires explicit ablation studies or direct comparisons to confirm that multi-dimension aggregation improves quality without introducing selection bias or overfitting, as this premise drives the need for the ensemble framework.
minor comments (1)
- The 14 clustering methods should be explicitly enumerated in the methods section, and any tables reporting performance rankings should include full metric values and cohort descriptions for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: Abstract: The assertion that the proposed ensemble embedding for deep clustering 'delivers the best overall performance ranking' is presented without any quantitative metrics (e.g., ARI, NMI, silhouette scores), statistical tests, error bars, cohort sizes, or implementation details, leaving the central empirical claim unsupported by verifiable evidence.
Authors: We agree that the abstract would be strengthened by including supporting quantitative evidence. In the revised manuscript, we will update the abstract to report key metrics such as the overall performance ranking across the 14 methods, average ARI and NMI values, cohort sizes (number of heart failure patients per All of Us cohort), and references to statistical significance testing. Full details including error bars from repeated runs and implementation specifics remain in the Methods and Results sections. revision: yes
-
Referee: Introduction and Methods: The foundational assumption that deep learning methods 'are specifically designed for image clustering' and thus inherently limited on tabular EHR data requires explicit ablation studies or direct comparisons to confirm that multi-dimension aggregation improves quality without introducing selection bias or overfitting, as this premise drives the need for the ensemble framework.
Authors: The manuscript already contains direct empirical comparisons demonstrating that standard deep clustering methods underperform relative to traditional methods on this tabular EHR data. We also report results from the multi-dimension aggregation approach versus single-embedding baselines. To further validate the aggregation step and address concerns about selection bias or overfitting, we will add explicit ablation experiments in the revised version, including performance sensitivity to the number of embedding dimensions and consistency checks across independent cohorts. revision: partial
Circularity Check
No significant circularity
full rationale
The paper's central claim is an empirical performance ranking of clustering methods (including a proposed ensemble deep clustering approach) on real EHR data from the All of Us program across multiple cohorts and 14 baselines. No derivation chain, theorem, or first-principles result is presented that reduces to its own inputs by construction, self-definition, or fitted-parameter renaming. The abstract and described framework treat the ensemble aggregation as a methodological proposal whose quality is assessed via external data experiments rather than any self-referential equation or self-citation load-bearing premise. This is the expected non-circular outcome for an applied empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Deep learning clustering methods optimized for images are unsuitable for tabular EHR data without modification
- ad hoc to paper Aggregating cluster assignments from multiple embedding dimensions improves overall clustering quality
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearwe introduce an ensemble-based deep clustering approach that aggregates cluster assignments obtained from multiple embedding dimensions... KGG ensemble... best overall performance ranking across 14 diverse clustering methods
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTraditional clustering methods perform robustly because deep learning approaches are specifically designed for image clustering, a task that differs substantially from the tabular EHR data setting.
Reference graph
Works this paper leans on
-
[1]
M. D. Samad, A. Ulloa, G. J. Wehner, L. Jing, D. Hartzel, C. W. Good, B. A. Williams, C. M. Haggerty, B. K. Fornwalt, Predicting Survival From Large Echocardiography and Electronic Health Record Datasets, JACC: Cardiovascular Imaging 12 (4) (2018) 681–689. doi:10.1016/j.jcmg.2018.04.026
-
[2]
Y . Hu, H. Yan, M. Liu, J. Gao, L. Xie, C. Zhang, L. Wei, Y . Ding, H. Jiang, Detecting cardiovascular diseases using unsupervised machine learning clustering based on electronic medical records, BMC Medical Research Methodology 24 (1) (2024) 309
2024
-
[3]
S. R. Bhutto, M. Zeng, K. Niu, S. Khoso, M. Umar, G. Lalley, M. Li, Automatic icd-10-cm coding via lambda- scaled attention based deep learning model, Methods 222 (2024) 19–27
2024
-
[4]
J. H. B. Masud, C.-C. Kuo, C.-Y . Yeh, H.-C. Yang, M.-C. Lin, Applying deep learning model to predict diagnosis code of medical records, Diagnostics 13 (13) (2023) 2297
2023
-
[5]
S. B. Rabbani, I. V . Medri, M. D. Samad, Deep clustering of tabular data by weighted gaussian distribution learning, Neurocomputing 623 (2025) 129359
2025
-
[6]
Y . Wang, Y . Zhao, T. M. Therneau, E. J. Atkinson, A. P. Tafti, N. Zhang, S. Amin, A. H. Limper, S. Khosla, H. Liu, Unsupervised machine learning for the discovery of latent disease clusters and patient subgroups using electronic health records, Journal of biomedical informatics 102 (2020) 103364
2020
-
[7]
A. Aljohani, Optimizing patient stratification in healthcare: A comparative analysis of clustering algorithms for ehr data, International Journal of Computational Intelligence Systems 17 (1) (2024) 173
2024
-
[8]
Karac ¸am, B
M. Karac ¸am, B. K ¨ult¨ursay, D. Mutlu, S. Tanyeri, A. Kaya, S. C. Efe, C. Do ˘gan, G. S. Halil, ¨O. Y . Akbal, K. KIRAL˙I, et al., From patterns to prognosis: machine learning–derived clusters in advanced heart failure, Frontiers in Cardiovascular Medicine 12 (2025) 1669538
2025
-
[9]
Nichols, T
L. Nichols, T. Taverner, F. Crowe, S. Richardson, C. Yau, S. Kiddle, P. Kirk, J. Barrett, K. Nirantharakumar, S. Griffin, et al., In simulated data and health records, latent class analysis was the optimum multimorbidity clustering algorithm, Journal of clinical epidemiology 152 (2022) 164–175
2022
-
[10]
Manzini, B
E. Manzini, B. Vlacho, J. Franch-Nadal, J. Escudero, A. G´enova, E. Reixach, E. Andr´es, I. Pizarro, J.-L. Portero, D. Mauricio, et al., Longitudinal deep learning clustering of type 2 diabetes mellitus trajectories using routinely collected health records, Journal of biomedical informatics 135 (2022) 104218
2022
-
[11]
Bampa, I
M. Bampa, I. Miliou, B. Jovanovic, P. Papapetrou, M-clustehr: A multimodal clustering approach for electronic health records, Artificial Intelligence in Medicine 154 (2024) 102905. 11 APREPRINT- APRIL9, 2026
2024
- [12]
-
[13]
W. Shao, X. Luo, Z. Zhang, Z. Han, V . Chandrasekaran, V . Turzhitsky, V . Bali, A. R. Roberts, M. Metzger, J. Baker, et al., Application of unsupervised deep learning algorithms for identification of specific clusters of chronic cough patients from emr data, BMC bioinformatics 23 (Suppl 3) (2022) 140
2022
-
[14]
J. Qiu, Y . Hu, L. Li, A. M. Erzurumluoglu, I. Braenne, C. Whitehurst, J. Schmitz, J. Arora, B. A. Bartholdy, S. Gandhi, et al., Deep representation learning for clustering longitudinal survival data from electronic health records, Nature Communications 16 (1) (2025) 2534
2025
- [15]
-
[16]
X. Guo, L. Gao, X. Liu, J. Yin, Improved deep embedded clustering with local structure preservation, IJCAI International Joint Conference on Artificial Intelligence 0 (2017) 1753–1759. doi:10.24963/ijcai.2017/243
-
[17]
K. G. Dizaji, A. Herandi, C. Deng, W. Cai, H. Huang, Deep Clustering via Joint Convolutional Autoencoder Em- bedding and Relative Entropy Minimization, in: Proceedings of the IEEE International Conference on Computer Vision, V ol. 2017-Octob, 2017, pp. 5747–5756. arXiv:1704.06327, doi:10.1109/ICCV .2017.612
-
[18]
M. M. Fard, T. Thonet, E. Gaussier, Deep k-means: Jointly clustering with k-means and learning representations, Pattern Recognition Letters 138 (2020) 185–192
2020
-
[19]
Boubekki, M
A. Boubekki, M. Kampffmeyer, U. Brefeld, R. Jenssen, Joint optimization of an autoencoder for clustering and embedding, Machine learning 110 (7) (2021) 1901–1937
2021
-
[20]
N. Mrabah, N. M. Khan, R. Ksantini, Z. Lachiri, Deep clustering with a dynamic autoencoder: From reconstruc- tion towards centroids construction, Neural Networks 130 (2020) 206–228. doi:10.1016/j.neunet.2020.07.005. URLhttps://doi.org/10.1016%2Fj.neunet.2020.07.005
-
[21]
Abrar, A
S. Abrar, A. Sekmen, M. D. Samad, Effectiveness of deep image embedding clustering methods on tabular data, in: 2023 15th International Conference on Advanced Computational Intelligence (ICACI), IEEE, 2023, pp. 1–7
2023
-
[22]
Kowsar, S
I. Kowsar, S. B. Rabbani, K. F. B. Akhter, M. D. Samad, Deep clustering of electronic health records tabular data for clinical interpretation, in: 2023 IEEE International Conference on Telecommunications and Photonics (ICTP), IEEE, 2023, pp. 01–05
2023
- [23]
-
[24]
H. W. Kuhn, The hungarian method for the assignment problem, Naval Research Logistics Quarterly 2 (1955) 83–97. doi:10.1002/nav.3800020109. URLhttps://onlinelibrary.wiley.com/doi/10.1002/nav.3800020109
-
[25]
P. A. Est ´evez, M. Tesmer, C. A. Perez, J. M. Zurada, Normalized mutual information feature selection, IEEE Transactions on neural networks 20 (2) (2009) 189–201
2009
-
[26]
J. M. Santos, M. Embrechts, On the use of the adjusted rand index as a metric for evaluating supervised classifi- cation, in: International conference on artificial neural networks, Springer, 2009, pp. 175–184
2009
-
[27]
of Us Research Program Investigators, J
A. of Us Research Program Investigators, J. C. Denny, J. L. Rutter, D. B. Goldstein, A. Philippakis, J. W. Smoller, G. Jenkins, E. Dishman, The ”all of us” research program, New England Journal of Medicine 381 (2019) 668–
2019
-
[28]
doi:10.1056/NEJMsr1809937
-
[29]
P. L. Sankar, L. S. Parker, The precision medicine initiative’s all of us research program: an agenda for research on its ethical, legal, and social issues, Genetics in Medicine 19 (7) (2017) 743–750
2017
-
[30]
Griffiths, A
C. Griffiths, A. Brock, C. Rooney, The impact of introducing icd-10 on trends in mortality from circulatory diseases in england and wales, Health Statistics Quarterly (22) (2004) 14–20
2004
-
[31]
C. Luo, Y . Zhu, Z. Zhu, R. Li, G. Chen, Z. Wang, A machine learning-based risk stratification tool for in-hospital mortality of intensive care unit patients with heart failure, Journal of Translational Medicine 20 (1) (2022) 136. doi:10.1186/s12967-022-03340-8. 12 APREPRINT- APRIL9, 2026
- [32]
-
[33]
J. Zhu, L. Hong, S. Yuan, X. Xu, J. Wei, H. Yin, Association between glucocorticoid use and all-cause mor- tality in critically ill patients with heart failure: A cohort study based on the mimic-iii database, Frontiers in Pharmacology 14 (2023) 1118551. doi:10.3389/fphar.2023.1118551
-
[34]
A. A. Huang, S. Y . Huang, Dendrogram of transparent feature importance machine learning statistics to classify associations for heart failure: A reanalysis of a retrospective cohort study of the medical information mart for intensive care iii (mimic-iii) database, PLOS ONE 18 (7) (2023) e0288819. doi:10.1371/journal.pone.0288819
-
[35]
C. W. Tsao, A. W. Aday, Z. I. Almarzooq, C. A. Anderson, P. Arora, C. L. Avery, C. M. Baker-Smith, A. Z. Beaton, A. K. Boehme, A. E. Buxton, et al., Heart disease and stroke statistics—2023 update: a report from the american heart association, Circulation 147 (8) (2023) e93–e621
2023
-
[36]
L. v. d. Maaten, G. Hinton, Visualizing data using t-sne, Journal of machine learning research 9 (Nov) (2008) 2579–2605
2008
-
[37]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, J. Melville, Umap: Uniform manifold approximation and projection for dimension reduc- tion, arXiv preprint arXiv:1802.03426 (2018). 13
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.