Recognition: unknown
A Proposed Framework for Advanced (Multi)Linear Infrastructure in Engineering and Science (FAMLIES)
Pith reviewed 2026-05-10 17:30 UTC · model grok-4.3
The pith
The FAMLIES framework vertically integrates BLIS and libflame to unify high-performance linear and tensor computations across CPU, GPU, and parallel systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Vertical integration of the existing dense linear and multi-linear software stacks produces a unified framework that delivers high-performance computations from node-level to massively parallel scales and across both CPU and GPU architectures, extending decades of work on systematic algorithm derivation and portable implementations.
What carries the argument
Vertical integration of the BLIS and libflame dense linear and multi-linear stacks, which unifies implementations for different hardware scales and types.
If this is right
- High-performance linear and tensor operations become available from node-level to massively parallel scales in one codebase.
- Both CPU and GPU architectures are supported without separate implementations for each.
- Key linear algebra and tensor primitives can be implemented once and reused across scientific and machine learning applications.
- Further extensions to new operations and hardware become easier due to the shared vertical stack.
Where Pith is reading between the lines
- Developers working on mixed linear-tensor models in machine learning could avoid maintaining separate library interfaces for different hardware.
- The unified stack might enable automatic cross-architecture optimizations that current separate libraries do not easily share.
- Porting existing scientific codes that rely on BLIS or libflame could become simpler if the new framework maintains backward compatibility.
Load-bearing premise
That the existing BLIS, libflame, and related projects can be successfully extended and vertically integrated into a single flexible framework without major performance or compatibility trade-offs.
What would settle it
A working prototype that matches or exceeds the performance of separate BLIS and libflame calls on both CPU and GPU while adding multi-node support without code duplication or slowdowns would support the claim; observed performance losses or architectural incompatibilities would refute it.
Figures



read the original abstract
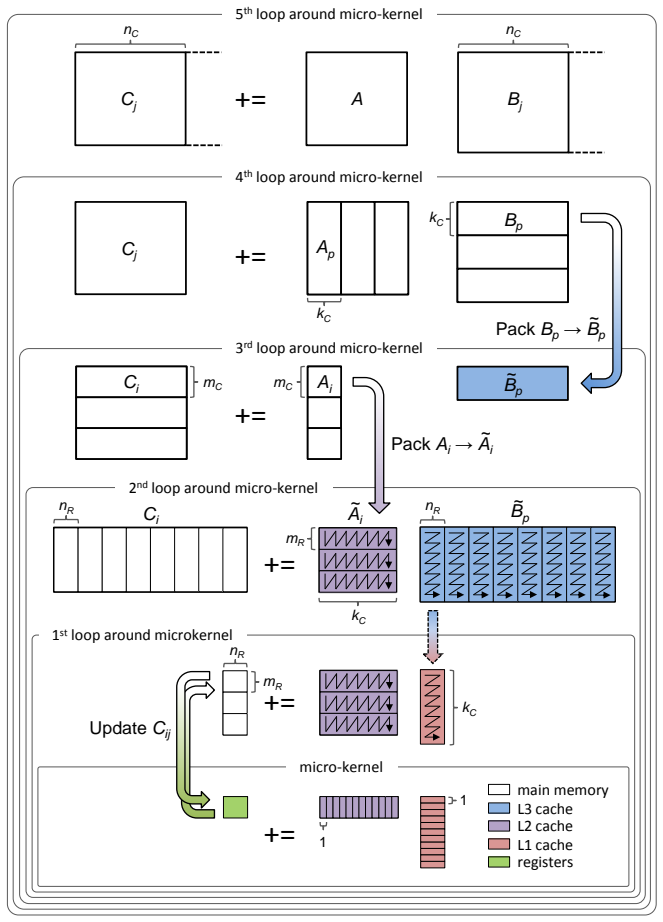
We leverage highly successful prior projects sponsored by multiple NSF grants and gifts from industry: the BLAS-like Library Instantiation Software (BLIS) and the libflame efforts to lay the foundation for a new flexible framework by vertically integrating the dense linear and multi-linear (tensor) software stacks that are important to modern computing. This vertical integration will enable high-performance computations from node-level to massively-parallel, and across both CPU and GPU architectures. The effort builds on decades of experience by the research team turning fundamental research on the systematic derivation of algorithms (the NSF-sponsored FLAME project) into practical software for this domain, targeting single and multi-core (BLIS, TBLIS, and libflame), GPU-accelerated (SuperMatrix), and massively parallel (PLAPACK, Elemental, and ROTE) compute environments. This project will implement key linear algebra and tensor operations which highlight the flexibility and effectiveness of the new framework, and set the stage for further work in broadening functionality and integration into diverse scientific and machine learning software.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FAMLIES, a new flexible framework for advanced linear and multilinear infrastructure, achieved by vertically integrating established dense linear algebra and tensor software stacks including BLIS, libflame, and related projects to enable high-performance computations from node-level to massively parallel systems across CPU and GPU architectures.
Significance. If realized, the proposed framework could provide a unified infrastructure for linear algebra and tensor operations in scientific computing and machine learning by extending decades of prior work on systematic algorithm derivation and multi-environment software implementations.
major comments (1)
- Abstract: The central claim that vertical integration will enable high-performance computations lacks any concrete details on integration architecture, specific operations to be implemented, or evaluation plans, reducing the proposal to a statement of intent without assessable technical substance.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our proposal for the FAMLIES framework. We agree that the abstract requires strengthening to better convey technical substance and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: The central claim that vertical integration will enable high-performance computations lacks any concrete details on integration architecture, specific operations to be implemented, or evaluation plans, reducing the proposal to a statement of intent without assessable technical substance.
Authors: We acknowledge the validity of this observation. The current abstract is intentionally high-level to emphasize the overarching vision, but it can be improved without altering the proposal character of the work. In the revised version we will expand the abstract to (1) briefly outline the vertical integration architecture that layers tensor operations atop the BLIS/libflame dense linear algebra foundation, (2) name representative operations (e.g., tensor contractions, higher-order SVD, and selected BLAS-3 equivalents for multilinear algebra) that will be implemented first, and (3) indicate the evaluation strategy, including node-level micro-benchmarks, multi-core scaling studies, and GPU/CPU heterogeneous performance comparisons drawn from our prior PLAPACK, Elemental, and SuperMatrix experience. These additions will make the central claim more concrete and assessable while remaining consistent with the manuscript's scope as a framework proposal. revision: yes
Circularity Check
No significant circularity: forward-looking proposal without derivations
full rationale
This is an explicit project proposal describing intended future integration of prior artifacts (BLIS, libflame, FLAME, PLAPACK, etc.). It contains no equations, no quantitative predictions, no fitted parameters, and no derivation chain that could reduce to its own inputs. Claims are statements of intent and historical context rather than asserted results whose truth value depends on internal consistency. Self-references to the authors' earlier work function as background, not as load-bearing justifications that close a loop. The document is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prior projects (BLIS, libflame, FLAME) provide a reliable foundation that can be extended to a new integrated framework.
invented entities (1)
-
FAMLIES framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anderson, Z
E. Anderson, Z. Bai, C. Bischof, L. S. Blackford, J. Demmel, Jack J. Dongarra, J. Du Croz, S. Hammarling, A. Greenbaum, A. McKenney, and D. Sorensen.LAPACK Users’ guide (third ed.). Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 1999
1999
-
[2]
Dongarra, Roldan Pozo, and David W
Jaeyoung Choi, Jack J. Dongarra, Roldan Pozo, and David W. Walker. ScaLAPACK: A scalable linear algebra library for distributed memory concurrent computers. InProceedings of the Fourth Symposium on the Frontiers of Massively Parallel Computation, pages 120–127. IEEE Comput. Soc. Press, 1992
1992
-
[3]
Dongarra, Mark Gates, Azzam Haidar, Jakub Kurzak, Piotr Luszczek, Stanimire Tomov, and Ichitaro Yamazaki
Jack J. Dongarra, Mark Gates, Azzam Haidar, Jakub Kurzak, Piotr Luszczek, Stanimire Tomov, and Ichitaro Yamazaki. Accelerating numerical dense linear algebra calculations with GPUs.Numerical Computations with GPUs, pages 1–26, 2014
2014
-
[4]
Jack J. Dongarra, Mark Gates, Azzam Haidar, Jakub Kurzak, Piotr Luszczek, Panruo Wu, Ichitaro Yamazaki, Asim Yarkhan, Maksims Abalenkovs, Negin Bagherpour, Sven Hammar- ling, Jakub ˇS´ ıstek, David Stevens, Mawussi Zounon, and Samuel D. Relton. PLASMA: Parallel Linear Algebra Software for Multicore using OpenMP.ACM Trans. Math. Softw., 45(2), May 2019
2019
-
[5]
Lawson, Richard J
Charles L. Lawson, Richard J. Hanson, David R. Kincaid, and Fred T. Krogh. Basic Linear Algebra Subprograms for Fortran usage.ACM Trans. Math. Soft., 5(3), Sept. 1979
1979
-
[6]
Dongarra, Jeremy Du Croz, Sven Hammarling, and Richard J
Jack J. Dongarra, Jeremy Du Croz, Sven Hammarling, and Richard J. Hanson. An extended set of FORTRAN Basic Linear Algebra Subprograms.ACM Trans. Math. Soft., 14(1), March 1988
1988
-
[7]
Dongarra, Jeremy Du Croz, Sven Hammarling, and Iain Duff
Jack J. Dongarra, Jeremy Du Croz, Sven Hammarling, and Iain Duff. A set of Level 3 Basic Linear Algebra Subprograms.ACM Trans. Math. Soft., 1990
1990
-
[8]
Dongarra, Iain S
Jack J. Dongarra, Iain S. Duff, Danny C. Sorensen, and Henk A. van der Vorst.Solving Linear Systems on Vector and Shared Memory Computers. SIAM, Philadelphia, PA, 1991
1991
-
[9]
Locality of reference in LU decomposition with partial pivoting.SIAM Journal on Matrix Analysis and Applications, 18(4):1065–1081, 1997
Sivan Toledo. Locality of reference in LU decomposition with partial pivoting.SIAM Journal on Matrix Analysis and Applications, 18(4):1065–1081, 1997
1997
-
[10]
Hong Jia-Wei and H. T. Kung. I/O complexity: The red-blue pebble game. InProceedings of the Thirteenth Annual ACM Symposium on Theory of Computing, STOC ’81, page 326–333, New York, NY, USA, 1981. Association for Computing Machinery
1981
-
[11]
Hoemmen, Nicholas Knight, and Oded Schwartz
Grey Ballard, Erin Carson, James Demmel, M. Hoemmen, Nicholas Knight, and Oded Schwartz. Communication lower bounds and optimal algorithms for numerical linear alge- bra.Acta Numerica, 23:1–155, 2014
2014
-
[12]
Communication-optimal par- allel and sequential cholesky decomposition: extended abstract
Grey Ballard, James Demmel, Olga Holtz, and Oded Schwartz. Communication-optimal par- allel and sequential cholesky decomposition: extended abstract. InProceedings of the Twenty- First Annual Symposium on Parallelism in Algorithms and Architectures, SPAA ’09, page 245–252, New York, NY, USA, 2009. Association for Computing Machinery
2009
-
[13]
Smith, Bradley Lowery, Julien Langou, and Robert A
Tyler M. Smith, Bradley Lowery, Julien Langou, and Robert A. van de Geijn. A tight I/O lower bound for matrix multiplication, 2019. arXiv:1702.02017 [cs.CC]
-
[14]
Boman, Erin Carson, Terry Cojean, Jack Don- garra, Mark Gates, Thomas Gr¨ utzmacher, Nicholas J
Ahmad Abdelfattah, Hartwig Anzt, Erik G. Boman, Erin Carson, Terry Cojean, Jack Don- garra, Mark Gates, Thomas Gr¨ utzmacher, Nicholas J. Higham, Sherry Li, Neil Lindquist, Yang Liu, Jennifer Loe, Piotr Luszczek, Pratik Nayak, Sri Pranesh, Siva Rajamanickam, Tobias Ribizel, Barry Smith, Kasia Swirydowicz, Stephen Thomas, Stanimire Tomov, Yaohung M. Tsai, ...
2020
-
[15]
Van Zee, Devangi N
Field G. Van Zee, Devangi N. Parikh, and Robert A. van de Geijn. Supporting mixed-domain mixed-precision matrix multiplication within the BLIS framework.ACM Trans. Math. Softw., 47(2), apr 2021
2021
-
[16]
Matthews
Devin A. Matthews. High-performance tensor contraction without transposition.SIAM J. Sci. Comput., 40(1):C1–C24, 2018
2018
-
[17]
Upasana Sridhar, Nicholai Tukanov, Elliott Binder, Tze Meng Low, Scott McMillan, and Martin D. Schatz. Small: Software for rapidly instantiating machine learning libraries.ACM Trans. Embed. Comput. Syst., jul 2023. Just Accepted
2023
-
[18]
High performance zero-memory overhead direct convolutions
Jiyuan Zhang, Franz Franchetti, and Tze Meng Low. High performance zero-memory overhead direct convolutions. InInternational Conference on Machine Learning, pages 5771–5780, 2018
2018
-
[19]
Gunnels and Robert A
John A. Gunnels and Robert A. van de Geijn. Formal methods for high-performance linear algebra libraries. In Ronald F. Boisvert and Ping Tak Peter Tang, editors,The Architecture of Scientific Software, pages 193–210. Kluwer Academic Press, 2001
2001
-
[20]
Gunnels, Fred G
John A. Gunnels, Fred G. Gustavson, Greg M. Henry, and Robert A. van de Geijn. FLAME: Formal Linear Algebra Methods Environment.ACM Trans. Math. Soft., 27(4):422–455, De- cember 2001
2001
-
[21]
Quintana, Gregorio Quintana, Xiaobai Sun, and Robert van de Geijn
Enrique S. Quintana, Gregorio Quintana, Xiaobai Sun, and Robert van de Geijn. A note on parallel matrix inversion.SIAM J. Sci. Comput., 22(5):1762–1771, 2001
2001
-
[22]
Gunnels, Greg M
John A. Gunnels, Greg M. Henry, and Robert A. van de Geijn. Formal Linear Algebra Methods Environment (FLAME): Overview. FLAME Working Note #1 CS-TR-00-28, Department of Computer Sciences, The University of Texas at Austin, Nov. 2000
2000
-
[23]
Gunnels, Margaret E
Paolo Bientinesi, John A. Gunnels, Margaret E. Myers, Enrique S. Quintana-Ort´ ı, and Robert A. van de Geijn. The Science of Deriving Dense Linear Algebra Algorithms.ACM Trans. Math. Soft., 31(1):1–26, March 2005
2005
-
[24]
Robert A. van de Geijn and Enrique S. Quintana-Ort´ ı.The Science of Programming Matrix Computations.http://www.lulu.com/content/1911788, 2008
-
[25]
van de Geijn
Paolo Bientinesi, Brian Gunter, and Robert A. van de Geijn. Families of algorithms related to the inversion of a symmetric positive definite matrix.ACM Trans. Math. Softw., 35(1):3:1– 3:22, July 2008
2008
-
[26]
van de Geijn and Maggie E
Robert A. van de Geijn and Maggie E. Myers.Applying Dijkstra’s Vision to Numerical Soft- ware, page 215–230. Association for Computing Machinery, 2022
2022
-
[27]
van de Geijn
Paolo Bientinesi and Robert A. van de Geijn. Goal-oriented and modular stability analysis. SIAM J. Matrix Anal. Appl., 32(1):286–308, March 2011
2011
-
[28]
van de Geijn
Paolo Bientinesi and Robert A. van de Geijn. Representing dense linear algebra algorithms: A farewell to indices. FLAME Working Note #17 TR-2006-10, The University of Texas at Austin, Department of Computer Sciences, 2006
2006
-
[29]
Xu, and Devin A
Robert van de Geijn, Maggie Myers, RuQing G. Xu, and Devin A. Matthews. Deriving algorithms for triangular tridiagonalization a (skew-)symmetric matrix, 2023
2023
-
[30]
libflame.https://github.com/flame/libflame, 2023
2023
-
[31]
Field Van Zee.libflame, The Complete Reference.lulu.com
-
[32]
Van Zee, Ernie Chan, Robert van de Geijn, Enrique S
Field G. Van Zee, Ernie Chan, Robert van de Geijn, Enrique S. Quintana-Ort´ ı, and Gregorio Quintana-Ort´ ı. The libflame library for dense matrix computations.IEEE Computation in Science & Engineering, 11(6):56–62, 2009
2009
-
[33]
UT Austin: Robert van de Geijn (PI), Don Batory (CoPI), Victor Eijkhout (CoPI), Maggie Myers (CoPI), John Stanton (CoPI)
Award ACI-1148125/1340293 (supplement): Collaborative Research: SI2-SSI: A Linear Alge- bra Software Infrastructure for Sustained Innovation in Computational Chemistry and other Sciences. UT Austin: Robert van de Geijn (PI), Don Batory (CoPI), Victor Eijkhout (CoPI), Maggie Myers (CoPI), John Stanton (CoPI). Univ. of Chicago: Jeff Hammond (PI). Funded Jun...
2012
-
[34]
van de Geijn, and Yuan-Jye J
Philip Alpatov, Greg Baker, Carter Edwards, John Gunnels, Greg Morrow, James Overfelt, Robert A. van de Geijn, and Yuan-Jye J. Wu. PLAPACK: Parallel Linear Algebra Package – Design Overview. InProceedings of SC97, 1997
1997
-
[35]
van de Geijn.Using PLAPACK: Parallel Linear Algebra Package
Robert A. van de Geijn.Using PLAPACK: Parallel Linear Algebra Package. The MIT Press, 1997
1997
-
[36]
van de Geijn, Jeff R
Jack Poulson, Bryan Marker, Robert A. van de Geijn, Jeff R. Hammond, and Nichols A. Romero. Elemental: A new framework for distributed memory dense matrix computations. ACM Trans. Math. Softw., 2013
2013
-
[37]
Schatz.Distributed Memory Tensor Computations: Formalizing Distributions, Re- distributions, and Algorithm Derivation
Martin D. Schatz.Distributed Memory Tensor Computations: Formalizing Distributions, Re- distributions, and Algorithm Derivation. PhD thesis, The University of Texas at Austin, Department of Computer Science, 2015
2015
-
[38]
Su- perMatrix out-of-order scheduling of matrix operations for SMP and multi-core architectures
Ernie Chan, Enrique Quintana-Ort´ ı, Gregorio Quintana-Ort´ ı, and Robert van de Geijn. Su- perMatrix out-of-order scheduling of matrix operations for SMP and multi-core architectures. InSPAA ’07: Proceedings of the Nineteenth ACM Symposium on Parallelism in Algorithms and Architectures, pages 116–126, 2007
2007
-
[39]
Igual, Enrique S
Gregorio Quintana-Ort´ ı, Francisco D. Igual, Enrique S. Quintana-Ort´ ı, and Robert van de Geijn. Solving dense linear systems on platforms with multiple hardware accelerators. InACM SIGPLAN 2009 symposium on Principles and practices of parallel programming (PPoPP’09), pages 121–129, 2009a
2009
-
[40]
Van Zee and Robert A
Field G. Van Zee and Robert A. van de Geijn. BLIS: A framework for rapidly instantiating BLAS functionality.ACM Trans. Math. Softw., 2015
2015
-
[41]
Van Zee, Tyler M
Field G. Van Zee, Tyler M. Smith, Bryan Marker, Tze Meng Low, Robert A. van de Geijn, Francisco D. Igual, Mikhail Smelyanskiy, Xianyi Zhang, Michael Kistler, Vernon Austel, John A. Gunnels, and Lee Killough. The BLIS framework: Experiments in portability.ACM Trans. Math. Softw., 2016
2016
-
[42]
Smith, Robert A
Tyler M. Smith, Robert A. van de Geijn, Mikhail Smelyanskiy, Jeff R Hammond, and Field G. Van Zee. Anatomy of high-performance many-threaded matrix multiplication. InIPDPS’2014, 2014
2014
-
[43]
Igual, Tyler M
Tze Meng Low, Francisco D. Igual, Tyler M. Smith, and Enrique S. Quintana-Orti. Analytical modeling is enough for high-performance blis.ACM Trans. Math. Softw., 43(2), Aug 2016
2016
-
[44]
Van Zee and Tyler M
Field G. Van Zee and Tyler M. Smith. Implementing high-performance complex matrix mul- tiplication via the 3M and 4M methods.ACM Trans. Math. Softw., 2017
2017
-
[45]
Field G. Van Zee. Implementing high-performance complex matrix multiplication via the 1m method.SIAM Journal on Scientific Computing, 42(5):C221–C244, Sept 2020
2020
-
[46]
Van Zee, Robert A
Field G. Van Zee, Robert A. van de Geijn, Maggie E. Myers, Devangi N. Parikh, and Devin A. Matthews. BLIS: BLAS and so much more.SIAM News, April 2021
2021
-
[47]
Van Zee, Robert A
Field G. Van Zee, Robert A. van de Geijn, Maggie E. Myers, Devangi N. Parikh, and Devin A. Matthews. BLIS: Extending BLAS functionality.SIAM News, September 2024
2024
-
[48]
https://github.com/flame/blis
BLAS-like library instantiation software framework (BLIS). https://github.com/flame/blis
-
[49]
https://www.siam.org/prizes-recognition/activity-group-prizes/detail/ siag-sc-best-paper-prize#Prize-History
SIAM Special Interest Group on Supercomputing Best Paper Prize. https://www.siam.org/prizes-recognition/activity-group-prizes/detail/ siag-sc-best-paper-prize#Prize-History
-
[50]
Wilkinson Prize for Numerical Software
J.H. Wilkinson Prize for Numerical Software. https://en.wikipedia.org/wiki/J. H. Wilkinson Prize for Numerical Software
-
[51]
UT Austin: Robert van de Geijn (PI), Don Batory (CoPI), Victor Eijkhout (CoPI), Maggie Myers (CoPI), John Stanton (CoPI)
Awards ACI-1550493/: Collaborative Research: SI2-SSI: Sustaining Innovation in the Linear Algebra Software Stack for Computational Chemistry and other Sciences. UT Austin: Robert van de Geijn (PI), Don Batory (CoPI), Victor Eijkhout (CoPI), Maggie Myers (CoPI), John Stanton (CoPI). CMU: Tze Meng Low (PI). Funded July 15, 2016 - June 30, 2018
2016
-
[52]
UT Austin: Robert van de Geijn (PI), Margaret E
Awards CSSI-2003921/2003931: Collaborative Research: Frameworks: Beyond the BLAS: A framework for accelerating computational and data science. UT Austin: Robert van de Geijn (PI), Margaret E. Myers (CoPI), Field Van Zee (CoPI), Devangi Parikh (CoPI). SMU: Devin Matthews (PI). Funded May. 1, 2020 - April 30, 2024
2020
-
[53]
Proposed consistent exception handling for the blas and lapack, 2022
James Demmel, Jack Dongarra, Mark Gates, Greg Henry, Julien Langou, Xiaoye Li, Piotr Luszczek, Weslley Pereira, Jason Riedy, and Cindy Rubio-Gonz´ alez. Proposed consistent exception handling for the blas and lapack, 2022
2022
-
[54]
TBLIS.https://github.com/devinamatthews/tblis
-
[55]
Performant Tridiagonal Factorization of Skew-Symmetric Matrices
Ishna Satyarth, Chao Yin, RuQing G. Xu, and Devin A. Matthews. Skew-symmetric matrix decompositions on shared-memory architectures, 2024. arXiv:2411.09859 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Smith, Greg M
Jianyu Huang, Tyler M. Smith, Greg M. Henry, and Robert A. van de Geijn. Strassen’s algo- rithm reloaded. InSC ’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 690–701, 2016
2016
-
[57]
Matthews, and Robert A
Jianyu Huang, Leslie Rice, Devin A. Matthews, and Robert A. van de Geijn. Generating families of practical fast matrix multiplication algorithms. In2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 656–667, 2017
2017
-
[58]
Matthews
Devin A. Matthews. MArray. http://github.com/devinamatthews/marray, 2024
2024
-
[59]
Linear algebra: Foundations to fronteirs.ulaff.net
-
[60]
Myers, Pierce M
Margaret E. Myers, Pierce M. van de Geijn, and Robert A. van de Geijn.Linear Algebra: Foundations to Frontiers - Notes to LAFF With. ulaff.net, 2015
2015
-
[61]
van de Geijn and Margaret E
Robert A. van de Geijn and Margaret E. Myers.LAFF-On Programming for Correctness. ulaff.net
-
[62]
van de Geijn and Margaret E
Robert A. van de Geijn and Margaret E. Myers.LAFF-On Programming for High Performance. ulaff.net
-
[63]
van de Geijn and Margaret E
Robert A. van de Geijn and Margaret E. Myers.Advanced Linear Algebra: Foundation to Frontiers.lulu.com, 2020
2020
-
[64]
2024 BLIS Retreat.https://www.cs.utexas.edu/users/flame/BLISRetreat2024
2024
-
[65]
BLIS Discord server.https://github.com/flame/blis/blob/master/docs/Discord.md
-
[66]
Code generation and optimization of distributed-memory dense linear algebra kernels
Bryan Marker, Don Batory, and Robert van de Geijn. Code generation and optimization of distributed-memory dense linear algebra kernels. InInternational Workshop on Automatic Performance Tuning (iWAPT’13), 2013
2013
-
[67]
Deep Learning Markov Random Field for Semantic Segmentation, August 2017
Ziwei Liu, Xiaoxiao Li, Ping Luo, Chen Change Loy, and Xiaoou Tang. Deep Learning Markov Random Field for Semantic Segmentation, August 2017. arXiv:1606.07230 [cs]
-
[68]
Creighton K. Thomas and A. Alan Middleton. Exact Algorithm for Sampling the 2D Ising Spin Glass.Physical Review E, 80(4), October 2009. arXiv:0906.5519 [cond-mat]
-
[69]
Electronic structure quantum Monte Carlo, August 2010
Michal Bajdich and Lubos Mitas. Electronic structure quantum Monte Carlo, August 2010. arXiv:1008.2369 [cond-mat, physics:physics]
-
[70]
Xu, Tsuyoshi Okubo, Synge Todo, and Masatoshi Imada
RuQing G. Xu, Tsuyoshi Okubo, Synge Todo, and Masatoshi Imada. Optimized implementa- tion for calculation and fast-update of Pfaffians installed to the open-source fermionic varia- tional solver mVMC.Computer Physics Communications, 277:108375, Aug 2022
2022
-
[71]
Algorithm 923: Efficient numerical computation of the Pfaffian for dense and banded skew-symmetric matrices.ACM Trans
Michael Wimmer. Algorithm 923: Efficient numerical computation of the Pfaffian for dense and banded skew-symmetric matrices.ACM Trans. Math. Softw., 38(4), Aug 2012
2012
-
[72]
Matthews, and Paolo Bientinesi
Paul Springer, Devin A. Matthews, and Paolo Bientinesi. Spin summations: A high- performance perspective.ACM Trans. Math. Softw., 45(1), March 2019
2019
-
[73]
Matthews, and Robert A
Jianyu Huang, Devin A. Matthews, and Robert A. van de Geijn. Strassen’s algorithm for tensor contraction.SIAM Journal on Scientific Computing, 40(3):C305–C326, 2018
2018
-
[74]
Schatz, Tze Meng Low, Robert A
Martin D. Schatz, Tze Meng Low, Robert A. van de Geijn, and Tamara G. Kolda. Exploiting symmetry in tensors for high performance: Multiplication with symmetric tensors.SIAM Journal on Scientific Computing, 36(5):C453–C479, 2014
2014
-
[75]
Matthews, Jeff Hammond, and James Demmel
Edgar Solomonik, Devin A. Matthews, Jeff Hammond, and James Demmel. Cyclops tensor framework: Reducing communication and eliminating load imbalance in massively parallel con- tractions. In2013 IEEE 27th International Symposium on Parallel and Distributed Processing, pages 813–824, 2013
2013
-
[76]
Towards an efficient use of the BLAS library for multilinear tensor contractions.Applied Mathematics and Computation, 235:454–468, May 2014
Edoardo Di Napoli, Diego Fabregat-Traver, Gregorio Quintana-Ort´ ı, and Paolo Bientinesi. Towards an efficient use of the BLAS library for multilinear tensor contractions.Applied Mathematics and Computation, 235:454–468, May 2014
2014
-
[77]
An Input- adaptive and In-place Approach to Dense Tensor-times-matrix Multiply
Jiajia Li, Casey Battaglino, Ioakeim Perros, Jimeng Sun, and Richard Vuduc. An Input- adaptive and In-place Approach to Dense Tensor-times-matrix Multiply. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’15, pages 76:1–76:12, New York, NY, USA, 2015. ACM
2015
-
[78]
Auer, Gerald Baumgartner, David E
Alexander A. Auer, Gerald Baumgartner, David E. Bernholdt, Alina Bibireata, Venkatesh Choppella, Daniel Cociorva, Xiaoyang Gao, Robert Harrison, Sriram Krishnamoorthy, Sand- hya Krishnan, Chi-Chung Lam, Qingda Lu, Marcel Nooijen, Russell Pitzer, J. Ramanujam, P. Sadayappan, and Alexander Sibiryakov. Automatic code generation for many-body elec- tronic str...
2006
-
[79]
Calvin, Cannada A
Justus A. Calvin, Cannada A. Lewis, and Edward F. Valeev. Scalable task-based algorithm for multiplication of block-rank-sparse matrices. InProceedings of the 5th Workshop on Irregular Applications: Architectures and Algorithms, IA¡sup¿3¡/sup¿ ’15, New York, NY, USA, 2015. Association for Computing Machinery
2015
-
[80]
Dmitry I. Lyakh. Domain-specific virtual processors as a portable programming and execu- tion model for parallel computational workloads on modern heterogeneous high-performance computing architectures.International Journal of Quantum Chemistry, 119(12):e25926, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.