Recognition: 2 theorem links
· Lean TheoremLecture notes on Machine Learning applications for global fits
Pith reviewed 2026-05-10 17:06 UTC · model grok-4.3
The pith
Boosted decision trees can surrogate the log-likelihood to make global fits feasible for axion-like particles under Belle II constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The notes establish that boosted decision trees, trained via active learning and Gaussian processes, serve as reliable surrogates for the log-likelihood function in global fits. This surrogate enables efficient profile-likelihood minimization and Markov Chain Monte Carlo sampling of posterior distributions. When applied to axion-like particle models explaining the B± to K± νν̄ anomaly at Belle II, the two-stage ML model explores the relevant parameter space while automatically satisfying constraints on decay lengths and flavor-violating couplings.
What carries the argument
Boosted decision trees as surrogates for the log-likelihood function, trained on active-learning samples and combined with MCMC sampling.
If this is right
- Global fits with many parameters and expensive predictions become computationally practical.
- Constraints on ALP decay lengths and flavor-violating couplings are enforced automatically during the scan.
- Posterior distributions for ALP parameters can be obtained via MCMC on the fast surrogate model.
- SHAP values provide quantitative insight into which parameters and interactions dominate the fit.
Where Pith is reading between the lines
- The same surrogate workflow could be adapted to other rare-decay anomalies or to models with similar computational bottlenecks in flavor physics.
- Active-learning strategies for generating training data might generalize to reduce the simulation cost of fits in cosmology or neutrino oscillation analyses.
- Combining the boosted-tree surrogate with neural-network emulators could further improve speed or accuracy for even higher-dimensional spaces.
Load-bearing premise
The boosted decision tree surrogate must reproduce the true log-likelihood surface closely enough that the resulting parameter constraints and posteriors remain unbiased.
What would settle it
A direct numerical comparison in a simplified ALP model where both the full likelihood and the surrogate can be evaluated exhaustively shows that the best-fit values or credible intervals differ by more than the reported statistical uncertainty.
Figures



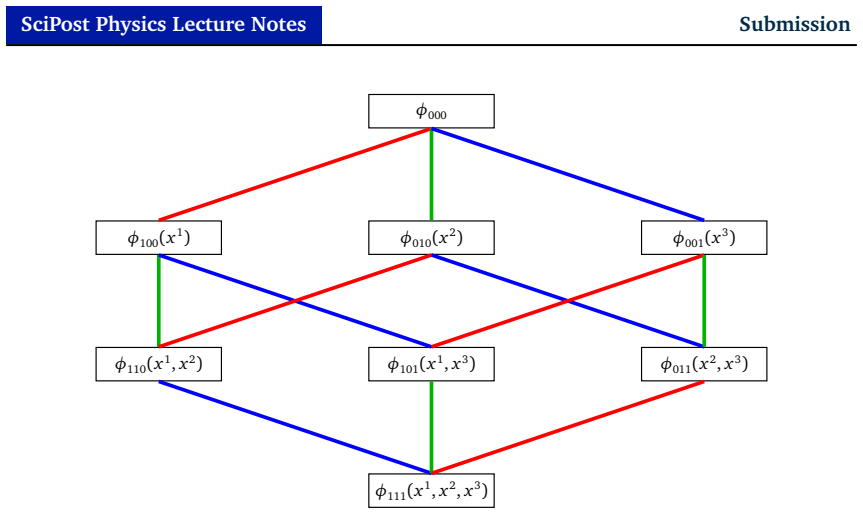
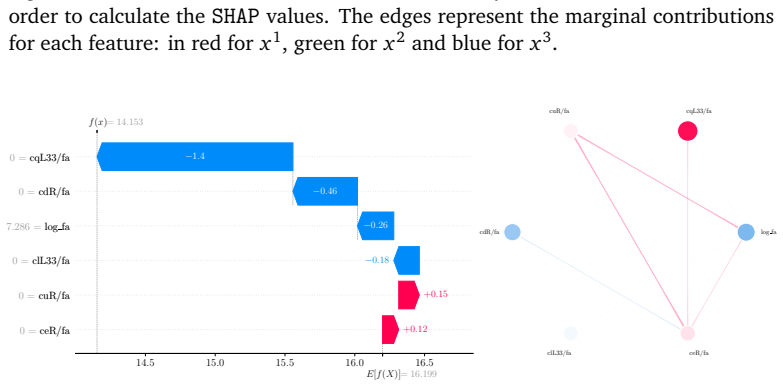
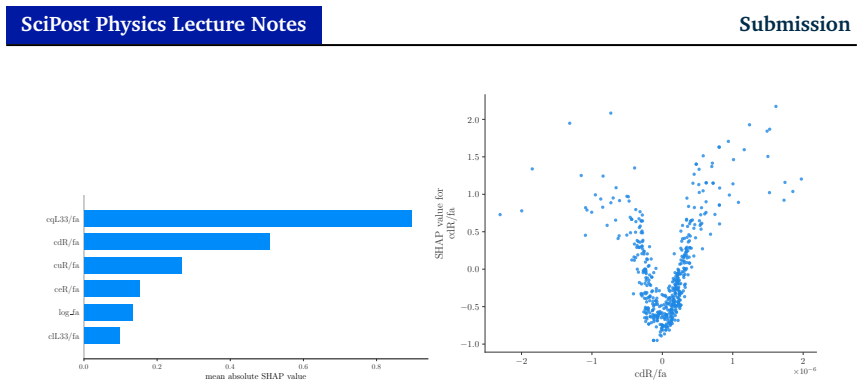

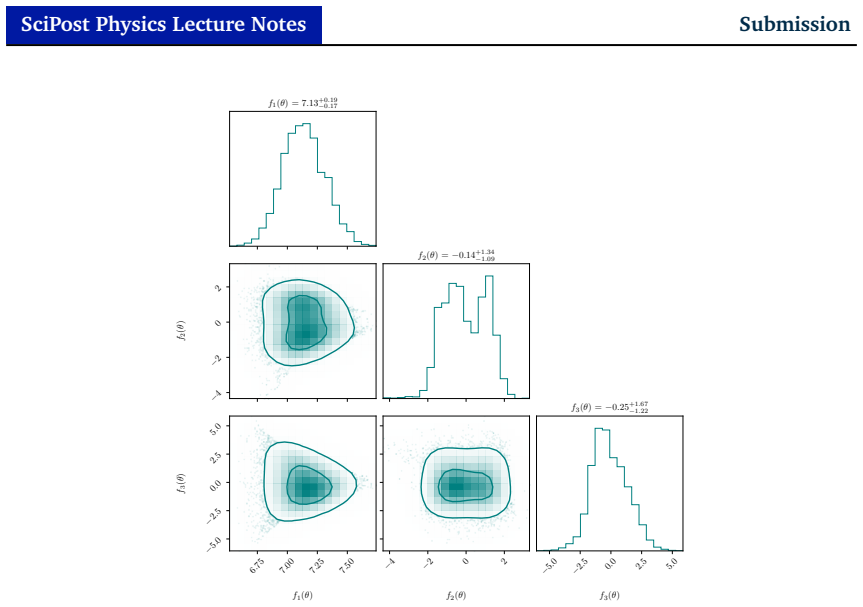

read the original abstract
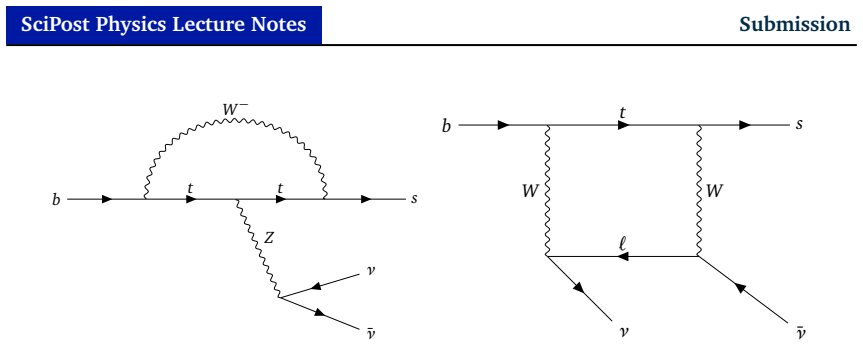
These lecture notes provide a comprehensive framework for performing global statistical fits in high-energy physics using modern Machine Learning (ML) surrogates. We begin by reviewing the statistical foundations of model building, including the likelihood function, Wilks' theorem, and profile likelihoods. Recognizing that the computational cost of evaluating model predictions often renders traditional minimization prohibitive, we introduce Boosted Decision Trees to approximate the log-likelihood function. The notes detail a robust ML workflow including efficient generation of training data with active learning and Gaussian processes, hyperparameter optimization, model compilation for speed-up, and interpretability through SHAP values to decode the influence of model parameters and interactions between parameters. We further discuss posterior distribution sampling using Markov Chain Monte Carlo (MCMC). These techniques are finally applied to the $B^\pm \to K^\pm \nu \bar{\nu}$ anomaly at Belle II, demonstrating how a two-stage ML model can efficiently explore the parameter space of Axion-Like Particles (ALPs) while satisfying stringent experimental constraints on decay lengths and flavor-violating couplings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. These lecture notes review the statistical foundations of global fits in high-energy physics and present a workflow for using Boosted Decision Trees (BDTs) as surrogates to approximate the log-likelihood function. The notes cover active learning for training data generation, Gaussian processes, hyperparameter optimization, model compilation, SHAP-based interpretability, and MCMC sampling for posteriors. The framework is applied to the B± → K± ν ν̄ anomaly at Belle II to constrain Axion-Like Particle (ALP) parameters while enforcing experimental constraints on decay lengths and flavor-violating couplings, claiming that a two-stage ML model enables efficient parameter space exploration.
Significance. If the BDT surrogates are shown to accurately reproduce the true log-likelihood surface, including near hard experimental boundaries, the approach would provide a practical method to accelerate computationally intensive global fits in HEP, particularly for models like ALPs with many parameters and constraints. The emphasis on interpretability via SHAP values and active learning for data efficiency strengthens the pedagogical value for practitioners.
major comments (1)
- [ALP application section] In the application to the B± → K± ν ν̄ anomaly and ALP constraints: the central claim that the two-stage BDT surrogate enables efficient exploration of parameter space while satisfying stringent decay-length and flavor-violation cuts requires that the surrogate faithfully reproduces the log-likelihood, including discontinuities at boundaries. No quantitative hold-out validation metrics, boundary-specific error tests, or comparisons to exact likelihood evaluations in excluded regions are reported, leaving open the possibility of biases in the MCMC-derived posteriors on flavor-violating couplings.
minor comments (1)
- [Abstract and application] The description of the 'two-stage ML model' in the abstract and application could be clarified with an explicit diagram or pseudocode showing how the stages interact with the active learning loop.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the pedagogical value of these lecture notes and for highlighting the importance of rigorous validation for the surrogate model in the ALP application. We address the major comment point by point below.
read point-by-point responses
-
Referee: [ALP application section] In the application to the B± → K± ν ν̄ anomaly and ALP constraints: the central claim that the two-stage BDT surrogate enables efficient exploration of parameter space while satisfying stringent decay-length and flavor-violation cuts requires that the surrogate faithfully reproduces the log-likelihood, including discontinuities at boundaries. No quantitative hold-out validation metrics, boundary-specific error tests, or comparisons to exact likelihood evaluations in excluded regions are reported, leaving open the possibility of biases in the MCMC-derived posteriors on flavor-violating couplings.
Authors: We agree that quantitative validation is essential to support the claim that the two-stage BDT surrogate faithfully reproduces the log-likelihood surface, particularly near the hard experimental boundaries. The current lecture notes emphasize the overall workflow, active learning strategy, and interpretability tools, with the ALP example serving primarily as an illustration rather than a fully benchmarked case study. To address this, we will add a dedicated subsection in the revised manuscript that reports hold-out validation metrics (such as RMSE and R² on a test set of exact log-likelihood evaluations) and performs boundary-specific tests by comparing surrogate predictions against exact evaluations in regions excluded by decay-length and flavor-violation constraints. These additions will directly assess whether the MCMC posteriors on flavor-violating couplings could be biased. revision: yes
Circularity Check
Methodological ML surrogate pipeline for global fits exhibits no circularity
full rationale
The lecture notes outline a standard workflow: statistical foundations (likelihood, Wilks' theorem), BDT approximation of log-likelihood, active learning with Gaussian processes for training data, hyperparameter tuning, SHAP interpretability, and MCMC sampling. This pipeline is applied to ALP parameter exploration under experimental constraints for the B± → K± νν̄ anomaly. No load-bearing step reduces by construction to its own inputs, fitted parameters renamed as predictions, or self-citation chains; the description relies on established ML and statistical techniques without self-definitional loops or ansatz smuggling. The central claim of efficient exploration is a practical methodology, not a derivation that collapses to tautology.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage ML model ... Boosted Decision Trees to approximate the log-likelihood function ... active learning and Gaussian processes ... SHAP values ... Markov Chain Monte Carlo (MCMC) ... ALP-aca for χ²
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
B± → K±νν̄ anomaly ... Axion-Like Particles ... decay lengths and flavor-violating couplings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. A. Bethe, Zur Theorie der Metalle. i. Eigenwerte und Eigenfunktionen der linearen Atomkette , Zeit. f \"u r Phys. 71 , 205 (1931), 10.1007\
1931
-
[2]
Ginsparg, It was twenty years ago today
P. Ginsparg, It was twenty years ago today... , http://arxiv.org/abs/1108.2700
-
[3]
, " * write output.state after.block =
ENTRY address archive author booktitle chapter doi edition editor eid eprint howpublished institution isbn journal key month note number organization pages publisher school series title type url volume year label INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 'af...
-
[4]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.