Recognition: unknown
Have LLM-associated terms increased in article full texts in all fields?
Pith reviewed 2026-05-10 17:04 UTC · model grok-4.3
The pith
LLM-associated terms increased in prevalence in the full texts of scientific articles across many fields from 2021 to 2024.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
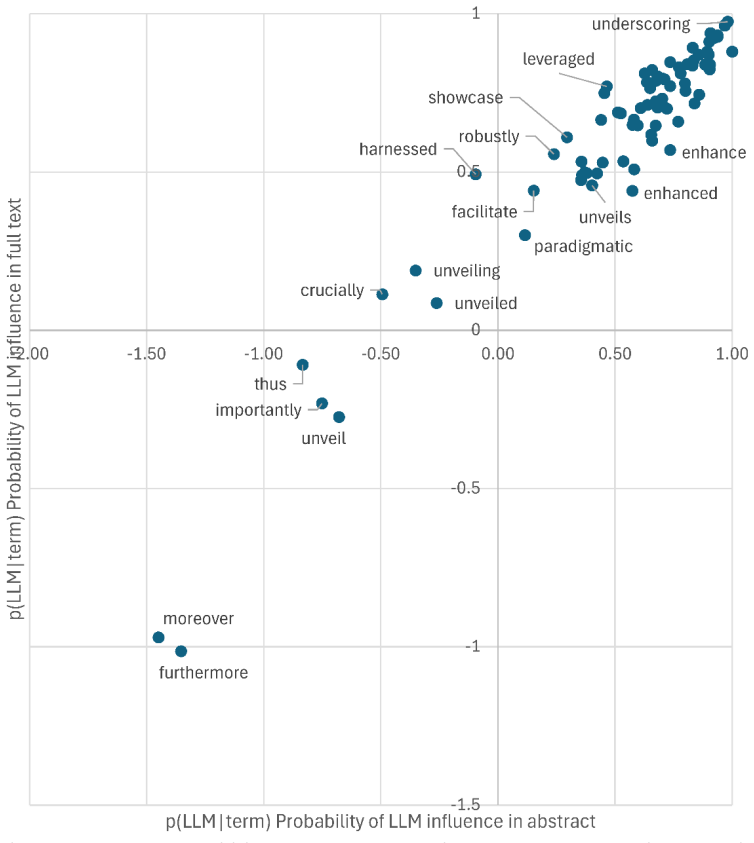
By examining the full texts of 1.25 million MDPI articles from 2021 to 2025, with special attention to the 73 journals that published at least 500 articles in 2021, the study demonstrates an overall rise in the prevalence of LLM-associated terms through 2024. Some terms then declined from 2024 to 2025 while others continued upward. LLMs appear to avoid certain words such as thus and moreover. A few terms associate more strongly with abstracts than full texts, and the opposite holds for others. The term family underscore showed the largest gain, reaching up to 29 times its earlier frequency. Uptake varies markedly by field and journal.
What carries the argument
The set of 80 potentially LLM-associated terms whose changing frequencies in full texts are used to infer shifts in writing assistance practices over time.
If this is right
- Some terms declined in frequency from 2024 to 2025 while others continued to increase.
- LLMs appear to avoid certain terms such as thus and moreover.
- A few terms show stronger associations with abstracts than with full texts, and the reverse holds for others.
- Substantial differences exist between journals and fields, with lower uptake in the life sciences and higher uptake in social sciences, electronic engineering, and environmental science.
- Fields with currently low uptake may require improved support for tasks such as translating complex formulae before automatic translation can deliver its full benefits.
Where Pith is reading between the lines
- Continued monitoring of these terms could reveal whether LLM use eventually produces more uniform writing styles across papers.
- Non-English-speaking researchers may face fewer publishing barriers, yet new stylistic patterns could emerge that affect how ideas are expressed.
- Similar term-frequency studies on other publishers would test whether the trends seen in MDPI data hold more broadly.
- Low-uptake fields might benefit from targeted tools that handle domain-specific elements like equations or technical notation.
Load-bearing premise
That the chosen 80 terms mainly signal LLM use for writing assistance rather than unrelated changes in scientific vocabulary or style.
What would settle it
A direct comparison of term frequencies in matched pairs of articles or drafts written with and without LLM assistance, or in a control corpus of purely human-written papers showing the same rate of increase.
Figures
read the original abstract
The use of Large Language Models (LLMs) like ChatGPT and DeepSeek for translation and language polishing is a welcome development, reducing the longstanding publishing barrier to non-English speakers. Assessing the uptake of this facility is useful to give insights into changing nature of scientific writing. Although the prevalence of LLM-associated terms has been tracked across science in abstracts and for full text biomedical research, their science-wide prevalence in full texts is unknown. In response, this article investigates an expanded set of 80 potentially LLM-associated terms during 2021-2025 in a science-wide full text collection from the publisher MDPI (1.25 million articles), partly focusing on the 73 journals that published at least 500 articles in 2021. The results demonstrate the increasing prevalence of LLM-associated terms science-wide in full texts to 2024, with some terms declining from 2024 to 2025 and others continuing to increase. LLMs seem to avoid some terms (e.g., thus, moreover) and a few terms have stronger associations with abstracts than full texts (e.g., enhanced) or the opposite (e.g., leveraged). The term family "underscore" had the biggest increase: up to 29-fold. There are substantial differences between journals in the apparent use of LLMs for writing, from lower uptake in the life sciences to higher uptake in social sciences, electronic engineering and environmental science. Fields in which there is currently low uptake may need improved or specialist support, such as for reliably translating complex formulae, before the full benefits of automatic translation can be realised.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the prevalence of an expanded set of 80 potentially LLM-associated terms in the full texts of 1.25 million MDPI articles from 2021-2025, with a focus on 73 journals that published at least 500 articles in 2021. It reports a general increase in these terms science-wide up to 2024, some declines from 2024 to 2025, field-specific variations in apparent LLM uptake (lower in life sciences, higher in social sciences, electronic engineering, and environmental science), and differential associations of certain terms with abstracts versus full texts.
Significance. If the term increases are accurately measured and the terms are reasonably linked to LLM assistance, the large-scale descriptive results (1.25 million articles, full-text focus) would provide useful evidence on evolving scientific writing practices and potential equity benefits for non-native English speakers, extending prior abstract-only or field-limited studies.
major comments (1)
- [Methods (term selection)] Methods section on term selection: The paper identifies an 'expanded set of 80 potentially LLM-associated terms' and reports large increases (e.g., 29-fold for the 'underscore' family) but provides no validation, such as frequency comparisons between LLM-generated/assisted texts and human-written baselines from the same 2021-2025 period or pre-2020 controls. Without this, the attribution of increases to LLM writing assistance (rather than unrelated shifts in academic vocabulary, non-native English styles, or journal conventions) rests on an untested premise, which is load-bearing for the abstract's claims about 'apparent use of LLMs' and 'LLMs seem to avoid some terms'.
minor comments (2)
- [Abstract and Results] Abstract and results: The description of how prevalence trends were quantified (e.g., any normalization by article length or statistical testing for increases) could be clarified to allow readers to assess robustness against stylistic confounders.
- [Methods] The manuscript could include a supplementary table listing all 80 terms with their rationale or source to improve reproducibility and transparency of the selection process.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation for minor revision. We address the single major comment below and outline the changes we will make to improve transparency and address the concern about term validation.
read point-by-point responses
-
Referee: Methods section on term selection: The paper identifies an 'expanded set of 80 potentially LLM-associated terms' and reports large increases (e.g., 29-fold for the 'underscore' family) but provides no validation, such as frequency comparisons between LLM-generated/assisted texts and human-written baselines from the same 2021-2025 period or pre-2020 controls. Without this, the attribution of increases to LLM writing assistance (rather than unrelated shifts in academic vocabulary, non-native English styles, or journal conventions) rests on an untested premise, which is load-bearing for the abstract's claims about 'apparent use of LLMs' and 'LLMs seem to avoid some terms'.
Authors: We agree that direct validation of the expanded term set against controlled LLM-generated versus human-written texts from the same period would strengthen causal attribution. The 80-term list is an expansion of vocabulary identified in prior studies that performed such comparisons (e.g., post-ChatGPT increases in terms like 'delve', 'underscore', 'crucial', and 'enhance'). Our study is observational and descriptive, focusing on prevalence trends in a large published corpus rather than new controlled experiments. We did not include pre-2020 baselines because the MDPI full-text dataset begins in 2021, though the timing of sharp rises after late 2022 is consistent with LLM availability. To address the referee's concern, we will revise the Methods section to explicitly describe the literature basis for term selection and add a dedicated limitations paragraph discussing alternative explanations (e.g., evolving academic conventions or non-native English styles) and the inferential nature of linking term increases to LLM assistance. We will also adjust abstract and discussion language to further emphasize 'potentially' and 'apparent' usage. This is a partial revision, as we cannot add new controlled validation experiments at this stage but can substantially improve transparency and caution. revision: partial
Circularity Check
No circularity: direct empirical term-frequency counts on external corpus
full rationale
The paper conducts straightforward frequency counts of a fixed list of 80 pre-chosen terms across 1.25 million MDPI full-text articles (2021-2025). The central finding—an observed rise in prevalence to 2024, with some terms declining afterward—is a direct tabulation of occurrences in an independent external dataset. No equations, fitted parameters, or derivations appear in the provided text. The list of terms is introduced as an 'expanded set of 80 potentially LLM-associated terms' drawn from prior literature for context; this selection is not derived from or validated against the current corpus, nor does any result reduce to it by construction. Self-references to earlier abstract or biomedical tracking serve only as background and are not load-bearing for the new science-wide measurements. The analysis therefore contains no self-definitional, fitted-input, or self-citation-chain circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 80 selected terms are valid indicators of LLM use for translation or language polishing.
Reference graph
Works this paper leans on
-
[1]
Alsudais, A. (2025). Exploring the change in scientific readability following the release of ChatGPT. Journal of Informetrics, 19(3), 101679 Angulo, E., Diagne, C., Ballesteros-Mejia, L., Adamjy, T., Ahmed, D. A., Akulov, E., & Courchamp, F. (2021). Non-English languages enrich scientific knowledge: the example of economic costs of biological invasions. S...
-
[2]
Jason Priem, Heather Piwowar, and Richard Orr
https://arxiv.org/pdf/2404.01268 Mishra, T., Sutanto, E., Rossanti, R., Pant, N., Ashraf, A., Raut, A., ... & Zeeshan, B. (2024). Use of large language models as artificial intelligence tools in academic research and publishing among global clinical researchers. Scientific Reports, 14(1), 31672. Mohammadi, E., Thelwall, M., Cai, Y., Collier, T., Tahamtan,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.