Recognition: 2 theorem links
· Lean TheoremSeeing enough: non-reference perceptual resolution selection for power-efficient client-side rendering
Pith reviewed 2026-05-12 02:01 UTC · model grok-4.3
The pith
A non-reference neural network predicts the lowest resolution that remains perceptually identical to full resolution in rendered video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a neural network trained on labels from full-reference perceptual video quality metrics can operate without a reference to predict, from the rendered video alone, the lowest resolution that remains perceptually indistinguishable from the best available option, thereby enabling power-efficient client-side rendering with minimal infrastructure changes.
What carries the argument
A neural network that takes rendered video frames as input and outputs the minimal resolution level predicted to be perceptually indistinguishable from higher resolutions.
Load-bearing premise
A network trained on full-reference metric labels will accurately detect perceptual indistinguishability when run without a reference on new rendered content and will not introduce visible quality degradation.
What would settle it
A controlled viewing test on rendered scenes where the method selects a lower resolution yet viewers consistently detect a difference or prefer the full resolution.
Figures
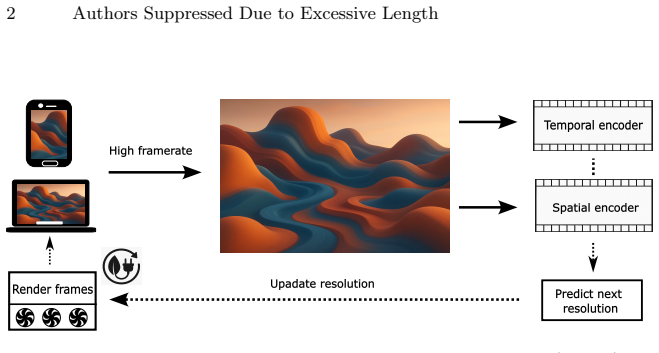







read the original abstract
Many client-side applications, especially games, render video at high resolution and frame rate on power-constrained devices, even when users perceive little or no benefit from all those extra pixels. Existing perceptual video quality metrics can indicate when a lower resolution is "good enough", but they are full-reference and computationally expensive, making them impractical for real-world applications and deployment on-device. In this work, we leverage the spatio-temporal limits of the human visual system and propose a non-reference method that predicts, from the rendered video alone, the lowest resolution that remains perceptually indistinguishable from the best available option, enabling power-efficient client-side rendering. Our approach is codec-agnostic and requires only minimal modifications to existing infrastructure. The network is trained on a large dataset of rendered content labeled with a full-reference perceptual video quality metric. The prediction significantly enhances perceptual quality while substantially reducing computational costs, suggesting a practical path toward perception-guided, power-efficient client-side rendering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a non-reference perceptual resolution selection method for power-efficient client-side rendering in applications such as games. A neural network is trained on a large dataset of rendered content labeled by a full-reference perceptual video quality metric; at inference the network predicts, from the rendered video alone, the lowest resolution that remains perceptually indistinguishable from higher-resolution options. The method is described as codec-agnostic and requiring only minimal infrastructure changes, with the goal of reducing computational cost while preserving perceived quality.
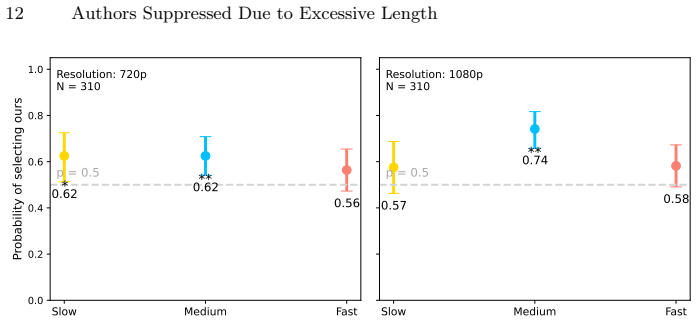
Significance. If the central claim holds, the work would offer a practical route to perception-guided resolution adaptation on power-constrained devices, avoiding the runtime cost of full-reference metrics. The codec-agnostic design and minimal infrastructure requirement are genuine strengths that could translate to deployable systems. However, the absence of any quantitative results, ablation studies, correlation metrics, or human-subject validation in the manuscript prevents assessment of whether the non-reference predictor actually preserves the indistinguishability guarantee across diverse rendered content.
major comments (2)
- [Abstract] Abstract: the claim that the prediction 'significantly enhances perceptual quality while substantially reducing computational costs' is unsupported; no error rates, PSNR/SSIM equivalents, perceptual metric correlations on held-out data, or power measurements are supplied to substantiate the central performance assertion.
- [Method] Training and inference description: the manuscript states that the network is trained on labels from a full-reference perceptual video quality metric yet supplies no definition of the indistinguishability threshold, no specification of the metric itself, no characterization of dataset diversity (motion, lighting, genres), and no transfer-validation experiment showing that non-reference predictions match full-reference decisions without introducing visible artifacts.
minor comments (2)
- The abstract and method sections would benefit from an explicit statement of the network architecture, input representation (e.g., spatio-temporal features), and inference latency on target hardware.
- Figure captions and table headings should be expanded to include the precise perceptual metric and threshold used for labeling so that the experimental protocol is reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important areas where the manuscript can be strengthened with additional details and evidence. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the prediction 'significantly enhances perceptual quality while substantially reducing computational costs' is unsupported; no error rates, PSNR/SSIM equivalents, perceptual metric correlations on held-out data, or power measurements are supplied to substantiate the central performance assertion.
Authors: We agree that the abstract asserts performance benefits without accompanying quantitative support in the current manuscript. The submission emphasizes the methodological contribution of the non-reference predictor. In the revised manuscript we will add a dedicated evaluation section reporting the non-reference network's agreement with full-reference decisions on held-out rendered sequences, including accuracy at the indistinguishability threshold, correlation with the underlying perceptual metric, and estimated power savings derived from the selected resolutions. These additions will directly substantiate the claims. revision: yes
-
Referee: [Method] Training and inference description: the manuscript states that the network is trained on labels from a full-reference perceptual video quality metric yet supplies no definition of the indistinguishability threshold, no specification of the metric itself, no characterization of dataset diversity (motion, lighting, genres), and no transfer-validation experiment showing that non-reference predictions match full-reference decisions without introducing visible artifacts.
Authors: We acknowledge the need for these missing specifications. The revised manuscript will explicitly name the full-reference perceptual metric, define the indistinguishability threshold used to generate training labels, and provide a characterization of the dataset (including motion statistics, lighting conditions, and genre coverage). We will also include transfer-validation results that quantify how closely the non-reference predictions align with full-reference decisions and report any observed discrepancies or potential artifacts on diverse test content. revision: yes
Circularity Check
No significant circularity; derivation relies on standard supervised training
full rationale
The paper's core proposal is a non-reference network trained on labels generated by a full-reference perceptual metric to predict the lowest perceptually indistinguishable resolution. This setup does not reduce any claimed prediction to its inputs by construction, nor does it involve self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations. The provided text contains no equations, uniqueness theorems, or ansatzes that collapse the output to the training labels. The method is self-contained as an empirical ML pipeline whose validity rests on generalization performance rather than tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights
axioms (1)
- domain assumption Spatio-temporal limits of the human visual system allow lower resolutions to remain perceptually indistinguishable from higher ones
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe network is trained on a large dataset of rendered content labeled with a full-reference perceptual video quality metric... lowest resolution whose JOD lies within 0.1 of the maximum... 0 JOD difference corresponds to the chance level (50% probability)
-
IndisputableMonolith/Foundation/ArrowOfTime.leanforward_accumulates unclearleverage the spatio-temporal limits of the human visual system... temporal masking effects... 120Hz
Reference graph
Works this paper leans on
-
[1]
AMD GPUOpen: Fidelityfx super resolution 3 (fsr 3).https://gpuopen.com/ fidelityfx-super-resolution-3/(2025), accessed: 2025-11-12
work page 2025
-
[2]
ACM Transactions on Graphics (TOG)39(6), 1–15 (2020)
Andersson, P.L., Nilsson, J., Akenine-Möller, T.: Flip: A difference evaluator for alternating images. ACM Transactions on Graphics (TOG)39(6), 1–15 (2020). https://doi.org/10.1145/3414685.3417836
-
[3]
Deep high dynamic range imaging of dynamic scenes
Bako, S., Vogels, T., McWilliams, B., Meyer, M., Novák, J., Harvill, A., Sen, P., DeRose, T., Rousselle, F.: Kernel-predicting convolutional networks for denoising monte carlo renderings. ACM Transactions on Graphics (TOG)36(4), 1–14 (2017). https://doi.org/10.1145/3072959.3073607
-
[4]
In: IEEE International Conference on Image Process- ing (ICIP)
Barman, N., Martini, M.G., Möller, S.: Vmaf revisited: towards a perceptually op- timized video quality metric. In: IEEE International Conference on Image Process- ing (ICIP). pp. 1914–1918 (2021).https://doi.org/10.1109/ICIP42928.2021. 9506628
-
[5]
In: ACM Multimedia Systems Confer- ence (MMSys)
Barman, N., Zadtootaghaj, S., Martini, M.G., Möller, S.: Gamingvideoset: A dataset for gaming video quality assessment. In: ACM Multimedia Systems Confer- ence (MMSys). pp. 261–271 (2019).https://doi.org/10.1145/3304109.3306215
-
[6]
Yoav Freund and Robert E Schapire
Bhat, G., Chen, Z., Bovik, A.C.: Adaptive bitrate streaming with perceptual qual- ity metrics. In: IEEE International Conference on Image Processing (ICIP). pp. 1416–1420 (2020).https://doi.org/10.1109/ICIP40778.2020.9190931
-
[7]
Binks, D.: Dynamic resolution rendering. Game Developers Conference (GDC) presentation / Intel whitepaper (2011),https://www.intel.cn/content/dam/ develop / external / us / en / documents / dynamicresolutionrendering - 183334 . pdf, describes dynamic resolution rendering as a technique to vary rendering res- olution to help maintain stable and appropriate...
work page 2011
-
[8]
In: IEEE International Con- ference on Image Processing (ICIP)
Bosse, S., Maniry, D., Muller, T., Wiegand, T.: Deep neural networks for no- reference and full-reference image quality assessment. In: IEEE International Con- ference on Image Processing (ICIP). pp. 2349–2353 (2018).https://doi.org/10. 1109/ICIP.2018.8451477
-
[9]
Deep high dynamic range imaging of dynamic scenes
Chaitanya, C.R.A., Kaplanyan, A.S., Schied, C., Salvi, M., Lefohn, A., Nowrouzezahrai, D., Aila, T.: Interactive reconstruction of monte carlo image se- quences using a recurrent denoising autoencoder. In: ACM SIGGRAPH. vol. 36, pp. 98:1–98:12 (2017).https://doi.org/10.1145/3072959.3073601
-
[10]
In: IEEE Conference on Virtual Reality and 3D User Interfaces (VR)
Denes, G., Gonzalez-Franco, M., Ofek, E., Steed, A.: Perceptual evaluation for foveated rendering in virtual reality. In: IEEE Conference on Virtual Reality and 3D User Interfaces (VR). pp. 893–902 (2020).https://doi.org/10.1109/ VR46266.2020.00062
-
[11]
Epic Games: Unreal engine 5.https://www.unrealengine.com/en-US/unreal- engine-5(2025), accessed: 2025-11-12
work page 2025
-
[12]
ACM Transactions on Graphics (TOG)31(6), 1–10 (2012).https://doi.org/10
Guenter, B., Finch, M., Drucker, S., Tan, D., Snyder, J.: Foveated 3d graphics. ACM Transactions on Graphics (TOG)31(6), 1–10 (2012).https://doi.org/10. 1145/2366145.2366183
-
[13]
In: Proceedings of the 21st Annual International Con- ference
He, S., Liu, Y., Zhou, H.: Optimizing smartphone power consumption through dynamic resolution scaling. In: Proceedings of the 21st Annual International Con- ference. ACM (2015).https://doi.org/10.1145/2789168.2790117, implements per-frame dynamic resolution scaling to trade off rendering load and performance, highlighting DRS usage in interactive real-tim...
-
[14]
Hladky, J., Stengel, M., Vining, N., Kerbl, B., Seidel, H.P., Steinberger, M.: Quad- Stream: A Quad-Based Scene Streaming Architecture for Novel Viewpoint Re- construction. ACM Transactions on Graphics41(6), 233:1–233:13 (Nov 2022). 16 Authors Suppressed Due to Excessive Length https://doi.org/10.1145/3550454.3555524,https://dl.acm.org/doi/10. 1145/355045...
-
[15]
In: IEEE Conference on Games (CoG)
Jindal, A., Lin, X., Kaeli, D.: Perceptual-based variable rate shading for foveated rendering in games. In: IEEE Conference on Games (CoG). pp. 52–59 (2021). https://doi.org/10.1109/CoG52621.2021.9619019
-
[16]
In: IEEE International Conference on Image Processing (ICIP)
Katsavounidis, I., Zhou, Z.L., Aaron, A., Dube, P.: Towards perceptually opti- mized end-to-end adaptive video streaming. In: IEEE International Conference on Image Processing (ICIP). pp. 1–5 (2018).https://doi.org/10.1109/ICIP.2018. 8451512
-
[17]
Li, Z.L., Aaron, A., Katsavounidis, I., Moorthy, A., Manohara, J.: Towards a practical perceptual video quality metric. In: Netflix Tech Blog (2016), online at:https://netflixtechblog.com/toward- a- practical- perceptual- video- quality-metric-653f208b9652
work page 2016
-
[18]
: Instant field-aligned meshes
Liu, H., Yu, L., Zhang, X., Zhou, K.: Adaptive rendering based on spatio-temporal sensitivity of human visual system. ACM Transactions on Graphics (TOG)34(6), 1–13 (2015).https://doi.org/10.1145/2816795.2818077
-
[19]
IEEE Transactions on Image Processing32, 1626–1640 (2023)
Liu, X., Zhang, L., Ma, K.: Temporal and spatial attention network for blind video quality assessment. IEEE Transactions on Image Processing32, 1626–1640 (2023). https://doi.org/10.1109/TIP.2023.3245600
-
[20]
IEEE Transactions on Multimedia21(6), 1499–1512 (2018)
Mackin, A., Zhang, F., Bull, D.R.: A study of high frame rate video formats. IEEE Transactions on Multimedia21(6), 1499–1512 (2018)
work page 2018
-
[21]
ACM Transactions on Graphics (TOG)43(4) (2024).https://doi.org/10.1145/3658166
Mantiuk, R., Ashraf, Y., Chapiro, A., Wuerger, S.: Colorvideovdp: A visual dif- ference predictor for image, video and display distortions. ACM Transactions on Graphics (TOG)43(4) (2024).https://doi.org/10.1145/3658166
-
[22]
Proceedings of SPIE8291(2012).https://doi
Mantiuk, R., Daly, S., Kerofsky, L.: Hdr-vdp-3: A model of visibility of differences in high dynamic range images. Proceedings of SPIE8291(2012).https://doi. org/10.1117/12.912416
-
[23]
ACM Transactions on Graphics (TOG)30(4), 1–14 (2011).https://doi.org/10
Mantiuk, R., Kim, K.J., Rempel, A.G., Heidrich, W.: Hdr-vdp-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. ACM Transactions on Graphics (TOG)30(4), 1–14 (2011).https://doi.org/10. 1145/2010324.1964935
-
[24]
ACM Transactions on Graphics (Proc
Mantiuk, R.K., Hanji, P., Ashraf, G., Wanat, R., Wernikowski, P., Mikhailiuk, A., Pérez, A., Mantiuk, R.: Fovvideovdp: A visible difference predictor for wide field- of-view video. ACM Transactions on Graphics (Proc. SIGGRAPH)40(4), 1–19 (2021)
work page 2021
-
[25]
Mao, H., Netravali, R., Alizadeh, M.: Neural adaptive video streaming with pen- sieve. In: ACM SIGCOMM. pp. 197–210 (2017).https://doi.org/10.1145/ 3098822.3098843
-
[26]
Mittal, A., Moorthy, A.K., Bovik, A.C.: No-reference image quality assessment in the spatial domain. IEEE Transactions on Image Processing21(12), 4695–4708 (2012).https://doi.org/10.1109/TIP.2012.2214050
-
[27]
ACM Transactions on Graphics , author =
Mueller, J.H., Voglreiter, P., Dokter, M., Neff, T., Makar, M., Steinberger, M., Schmalstieg, D.: Shading atlas streaming. ACM Transactions on Graphics37(6), 1–16 (Dec 2018).https://doi.org/10.1145/3272127.3275087,https://dl.acm. org/doi/10.1145/3272127.3275087
-
[28]
Patney, A., Salvi, M., Kim, J., Kaplanyan, A.S., Wyman, C., Benty, N., Luebke, D., Lefohn, A.: Towards foveated rendering for gaze-tracked virtual reality. In: ACM SIGGRAPH Asia. vol. 35, pp. 1–12 (2016).https://doi.org/10.1145/2980179. 2980246 Abbreviated paper title 17
-
[29]
ACM Computing Surveys57(12), 1–47 (2025)
Peroni, L., Gorinsky, S.: An end-to-end pipeline perspective on video streaming in best-effort networks: a survey and tutorial. ACM Computing Surveys57(12), 1–47 (2025)
work page 2025
-
[30]
Sawhney, H., Barman, N., Martini, M.G.: No-reference image and video quality assessment:Aclassificationandreviewofrecentapproaches.In:IEEEInternational Conference on Image Processing (ICIP). pp. 4584–4588 (2019).https://doi.org/ 10.1109/ICIP.2019.8803031
-
[31]
Sun, Q., Patney, A., Shirley, P., Ramamoorthi, R.: Perceptual temporal rendering: Improving quality and performance via temporal masking. In: ACM SIGGRAPH. vol. 40, pp. 1–15 (2021).https://doi.org/10.1145/3450626.3459786
-
[32]
In: IEEE International Conference on Communications (ICC)
Thammineni, P., Claypool, M., Kinicki, R.: Temporal adaptation for video stream- ing over wireless networks. In: IEEE International Conference on Communications (ICC). pp. 177–182 (2008).https://doi.org/10.1109/ICC.2008.68
-
[33]
Vetro, A., Christopoulos, C., Sun, H.: Dynamic frame skipping for joint source and channel video coding. IEEE Transactions on Circuits and Systems for Video Tech- nology12(6), 438–452 (2001).https://doi.org/10.1109/TCSVT.2002.800560
-
[34]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR)
Wang, H., Li, J., Ma, K.: Streamvqa: Adaptive video quality assessment for stream- ing scenarios. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 10460–10469 (2023).https://doi.org/10.1109/CVPR52729. 2023.01008
-
[35]
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Process- ing13(4), 600–612 (2004).https://doi.org/10.1109/TIP.2003.819861
-
[36]
In: IEEE International Conference on Multimedia and Expo (ICME)
Yan, J., Zhang, W., Ma, K.: Toward intelligent video streaming: A reinforcement learning approach. In: IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6 (2020).https://doi.org/10.1109/ICME46284.2020.9102839
-
[37]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Yılmaz, D., Wang, H., Takikawa, T., Ceylan, D., Akşit, K.: Learned single-pass multitasking perceptual graphics for immersive displays. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10719–10727 (2025)
work page 2025
-
[38]
IEEE Transactions on Image Processing (2020).https: //doi.org/10.1109/TIP.2020.3045875
Ying, Z., Mandal, M., Bovik, A.C.: Patch-vq: Patch-level vision transformer for video quality assessment. IEEE Transactions on Image Processing (2020).https: //doi.org/10.1109/TIP.2020.3045875
-
[39]
IEEE Transactions on Image Processing31, 4797– 4811 (2022).https://doi.org/10.1109/TIP.2022.3185593
Yu, M., Zhang, L., Ma, K.: Gamingvqa: Large-scale gaming video quality assess- ment dataset and benchmark. IEEE Transactions on Image Processing31, 4797– 4811 (2022).https://doi.org/10.1109/TIP.2022.3185593
-
[40]
In: IEEE Conference on Quality of Multi- media Experience (QoMEX)
Zadtootaghaj, S., Barman, N., Möller, S.: Modeling gaming video qoe: Towards a qoe model for gaming video streaming. In: IEEE Conference on Quality of Multi- media Experience (QoMEX). pp. 1–6 (2018).https://doi.org/10.1109/QoMEX. 2018.8463422
-
[41]
lowest resolution within 0.1 JOD of the optimum
Zhang, F., Rangrej, S.B., Aumentado-Armstrong, T., Fazly, A., Levinshtein, A.: Augmenting perceptual super-resolution via image quality predictors. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2311–2322 (2025) 18 Authors Suppressed Due to Excessive Length Supplementary Material Seeing Enough: Non-Refe...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.