Recognition: 2 theorem links
· Lean TheoremLong-Term Embeddings for Balanced Personalization
Pith reviewed 2026-05-10 18:36 UTC · model grok-4.3
The pith
Long-term embeddings anchored to fixed content features balance recency bias in transformer recommenders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that constraining embeddings to a fixed semantic basis of content-based item representations, then integrating them as a lagged contextual prefix token, supplies a production-compatible method for injecting long-term user preferences into sequential transformers without extending input lengths or breaking point-in-time consistency.
What carries the argument
Long-Term Embeddings (LTE) framework that fixes embeddings to a content-based semantic basis and supplies them as a high-inertia lagged prefix token.
If this is right
- Stable long-term preferences can be captured without the compute cost of longer sequences or heavier attention mechanisms.
- Models remain compatible across training, deployment, and rollback because the embedding basis never changes.
- Lagged-window integration prevents temporal leakage while still allowing behavioral fine-tuning through an asymmetric autoencoder with fixed decoder.
- Both heuristic averaging and learned autoencoder versions of the fixed basis deliver measurable uplifts in live user and financial metrics.
Where Pith is reading between the lines
- The same fixed-basis prefix technique could be tested in non-transformer sequential models that also suffer recency bias.
- Varying the lag window size across different domains would reveal whether an optimal lag depends on session length or item turnover rate.
- Over very long time scales the fixed content basis may need periodic refresh to handle new item categories or semantic drift.
- The production consistency fix could apply to any feature-store-dependent model that must survive rollbacks without retraining.
Load-bearing premise
Content-based item representations form a stable enough basis to encode long-term preferences without substantial loss of model performance.
What would settle it
An A/B test that removes the LTE prefix token while keeping all other factors identical shows no lift or a drop in user engagement and revenue metrics.
Figures

read the original abstract
Modern transformer-based sequential recommenders excel at capturing short-term intent but often suffer from recency bias, overlooking stable long-term preferences. While extending sequence lengths is an intuitive fix, it is computationally inefficient, and recent interactions tend to dominate the model's attention. We propose Long-Term Embeddings (LTE) as a high-inertia contextual anchor to bridge this gap. We address a critical production challenge: the point-in-time consistency problem caused by infrastructure constraints, as feature stores typically host only a single "live" version of features. This leads to an offline-online mismatch during model deployments and rollbacks, as models are forced to process evolved representations they never saw during training. To resolve this, we introduce an LTE framework that constrains embeddings to a fixed semantic basis of content-based item representations, ensuring cross-version compatibility. Furthermore, we investigate integration strategies for causal language modeling, considering the data leakage issue that occurs when the LTE and the transformer's short-term sequence share a temporal horizon. We evaluate two representations: a heuristic average and an asymmetric autoencoder with a fixed decoder grounded in the semantic basis to enable behavioral fine-tuning while maintaining stability. Online A/B tests on Zalando demonstrate that integrating LTE as a contextual prefix token using a lagged window yields significant uplifts in both user engagement and financial metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Long-Term Embeddings (LTE) as a high-inertia contextual prefix for transformer-based sequential recommenders to counter recency bias and capture stable long-term user preferences. LTE is constructed from a fixed semantic basis of content-based item representations to ensure point-in-time consistency across model versions and deployments; an asymmetric autoencoder with fixed decoder is introduced to permit behavioral fine-tuning while preserving this basis. A lagged window is used during causal language modeling to mitigate data leakage when LTE and the short-term sequence overlap temporally. Online A/B tests at Zalando are reported to show significant uplifts in engagement and financial metrics when LTE is integrated as a prefix token.
Significance. If the reported uplifts hold under rigorous validation, the work provides a practical, production-oriented solution for balancing short- and long-term signals without the computational cost of longer sequences. The focus on infrastructure constraints (feature-store consistency, cross-version compatibility) and the use of a fixed semantic basis plus autoencoder for stability address real deployment challenges that are often overlooked in academic recommender research. Reproducible details on the lagged-window integration and the autoencoder architecture would strengthen its utility for industry practitioners.
major comments (3)
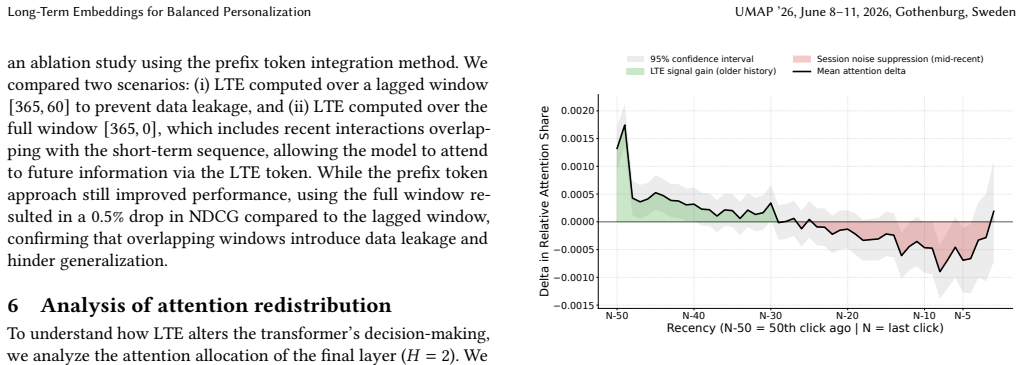
- [Integration strategies / causal LM setup] Integration and leakage section (around the causal LM setup and lagged window description): The claim that the lagged window both blocks future information and still supplies stable long-term preference signal is asserted without quantitative support. No ablation on lag size, forward simulation of leakage, or train/test temporal alignment check is provided, even though the abstract explicitly flags the leakage risk and the central production claim rests on the observed uplifts from this exact configuration.
- [Evaluation / A/B tests] Online A/B test results (evaluation section): Significant uplifts in user engagement and financial metrics are reported, yet the manuscript supplies no sample sizes, confidence intervals, exact baseline definitions, or effect-size tables. This omission makes it impossible to assess whether the gains are statistically robust or practically meaningful, directly affecting the strength of the main empirical claim.
- [LTE framework / representations] Representation comparison (autoencoder vs. heuristic average): The asymmetric autoencoder is motivated as enabling behavioral fine-tuning on a fixed decoder, but no ablation or head-to-head results versus the simpler heuristic average are shown to justify the added complexity. Without this, it is unclear whether the reported uplifts derive from the fixed semantic basis itself or from the specific autoencoder design.
minor comments (3)
- [Abstract / Introduction] The abstract and introduction use the term 'high-inertia contextual anchor' without a concise formal definition or equation; adding a short mathematical description of LTE construction would improve clarity.
- [Throughout] Notation for the lagged window size and autoencoder parameters is introduced but not consistently referenced in later sections; a dedicated notation table or consistent symbol usage would aid readability.
- [Related work] The manuscript would benefit from citing additional prior work on long-term vs. short-term modeling in sequential recommenders and on production feature consistency issues.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating planned revisions where appropriate. Our responses focus on clarifying the manuscript's contributions while acknowledging areas for improvement.
read point-by-point responses
-
Referee: [Integration strategies / causal LM setup] Integration and leakage section (around the causal LM setup and lagged window description): The claim that the lagged window both blocks future information and still supplies stable long-term preference signal is asserted without quantitative support. No ablation on lag size, forward simulation of leakage, or train/test temporal alignment check is provided, even though the abstract explicitly flags the leakage risk and the central production claim rests on the observed uplifts from this exact configuration.
Authors: We agree that additional quantitative evidence would strengthen the description of the lagged window. The design ensures no temporal overlap to block leakage while the LTE provides stable long-term context. In the revision, we will add an ablation on lag sizes with performance metrics and a brief analysis of temporal alignment between train and test sets to demonstrate that the long-term signal is preserved without future information leakage. revision: yes
-
Referee: [Evaluation / A/B tests] Online A/B test results (evaluation section): Significant uplifts in user engagement and financial metrics are reported, yet the manuscript supplies no sample sizes, confidence intervals, exact baseline definitions, or effect-size tables. This omission makes it impossible to assess whether the gains are statistically robust or practically meaningful, directly affecting the strength of the main empirical claim.
Authors: We have clarified the baseline definitions and added effect-size tables in the revised manuscript. However, exact sample sizes and confidence intervals cannot be disclosed due to the proprietary nature of Zalando's production A/B testing infrastructure and data sensitivity. The uplifts were validated through internal statistical processes, and we believe the reported gains remain practically meaningful for the deployment context. revision: partial
-
Referee: [LTE framework / representations] Representation comparison (autoencoder vs. heuristic average): The asymmetric autoencoder is motivated as enabling behavioral fine-tuning on a fixed decoder, but no ablation or head-to-head results versus the simpler heuristic average are shown to justify the added complexity. Without this, it is unclear whether the reported uplifts derive from the fixed semantic basis itself or from the specific autoencoder design.
Authors: The manuscript evaluates both the heuristic average and asymmetric autoencoder representations. To directly address the concern, the revised version will include expanded head-to-head results and ablations comparing the two approaches, highlighting metrics that justify the autoencoder's complexity for enabling fine-tuning on the fixed semantic basis. revision: yes
- Exact sample sizes and confidence intervals from the online A/B tests due to commercial confidentiality constraints at Zalando.
Circularity Check
No circularity; claims rest on independent online A/B tests and novel architectural elements
full rationale
The paper introduces Long-Term Embeddings (LTE) as a fixed-semantic-basis contextual prefix for transformer recommenders, using a lagged window to address leakage and an asymmetric autoencoder for behavioral fine-tuning. No equations, predictions, or first-principles derivations are presented that reduce by construction to fitted inputs or prior self-citations. The central results derive from external online A/B tests on Zalando production traffic measuring engagement and financial metrics, which are independent of the model's internal parameters. The lagged-window choice and fixed basis are design decisions justified by infrastructure constraints rather than tautological redefinitions. This is a standard engineering contribution with self-contained empirical support.
Axiom & Free-Parameter Ledger
free parameters (2)
- lagged window size
- autoencoder architecture parameters
axioms (1)
- domain assumption Content-based item representations form a stable semantic basis across model versions
invented entities (1)
-
Long-Term Embeddings (LTE)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Long-Term Embeddings (LTE) as a high-inertia contextual anchor... lagged window [365,60] excluding the most recent T days... asymmetric autoencoder with a fixed decoder grounded in the semantic basis
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrating LTE as a contextual prefix token using a lagged window yields significant uplifts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer normaliza- tion.arXiv preprint arXiv:1607.06450(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, Xionghang Xie, Shiru Ren, Xiang Sun, Yaocheng Tan, Peng Xu, Yuchao Zheng, and Di Wu. 2025. LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Associ...
-
[3]
Bo-Yu Chang, Can Xu, Minmin Chen, Jia Li, Alex Beutel, and Ed H Chi. 2022. Recency Dropout for Recurrent Recommender Systems. InProceedings of the 15th ACM International Conference on Web Search and Data Mining (WSDM). 111–119
2022
-
[4]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems(Boston, Massachusetts, USA)(RecSys ’16). Association for Computing Machinery, New York, NY, USA, 191–198. doi:10.1145/2959100. 2959190
-
[5]
Giulia Di Teodoro, Federico Siciliano, Nicola Tonellotto, and Fabrizio Silvestri
- [6]
- [7]
- [8]
-
[9]
Yulong Gu, Zhuoye Ding, Shuaiqiang Wang, Lixin Zou, Yiding Liu, and Dawei Yin. 2020. Deep Multifaceted Transformers for Multi-objective Ranking in Large- Scale E-commerce Recommender Systems. InProceedings of the 29th ACM In- ternational Conference on Information & Knowledge Management(Virtual Event, Ireland)(CIKM ’20). Association for Computing Machinery...
-
[10]
Wang-Cheng Kang and Julian McAuley. 2018. Self-Attentive Sequential Recom- mendation.2018 IEEE International Conference on Data Mining (ICDM)(2018), 197–206
2018
-
[11]
Jiacheng Li, Yujie Wang, and Julian McAuley. 2020. Time Interval Aware Self- Attention for Sequential Recommendation. InProceedings of the 13th International Conference on Web Search and Data Mining(Houston, TX, USA)(WSDM ’20). Association for Computing Machinery, New York, NY, USA, 322–330. doi:10. 1145/3336191.3371786
-
[12]
Li Erran Li, Eric Chen, Jeremy Hermann, Pusheng Zhang, and Luming Wang. 2017. Scaling Machine Learning as a Service. InProceedings of The 3rd International Conference on Predictive Applications and APIs (Proceedings of Machine Learning Research, Vol. 67), Claire Hardgrove, Louis Dorard, Keiran Thompson, and Florian Douetteau (Eds.). PMLR, 14–29. https://p...
2017
- [13]
- [14]
-
[15]
Aditya Pal, Chantat Eksombatchai, Yitong Zhou, Bo Zhao, Charles Rosenberg, and Jure Leskovec. 2020. PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(Virtual Event, CA, USA)(KDD ’20). Association for Computing Machinery, New ...
-
[16]
Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(Anchorage, AK, USA)(KDD ’19). Association for Computing Machinery, New York, NY, USA, 2671–2679. doi:10.1...
-
[17]
Massimo Quadrana, Paolo Cremonesi, and Dietmar Jannach. 2018. Sequence- Aware Recommender Systems.ACM Comput. Surv.51, 4, Article 66 (July 2018), 36 pages. doi:10.1145/3190616
-
[18]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[19]
Kan Ren, Jiarui Qin, Yuchen Fang, Weinan Zhang, Lei Zheng, Weijie Bian, Guorui Zhou, Jian Xu, Yong Yu, Xiaoqiang Zhu, and Kun Gai. 2019. Lifelong Sequen- tial Modeling with Personalized Memorization for User Response Prediction. In Proceedings of the 42nd International ACM SIGIR Conference on Research and De- velopment in Information Retrieval(Paris, Fran...
-
[20]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[21]
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Rep- resentations from Transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management(Beijing, China)(CIKM ’19). Association for Computing Machinery, New York, NY, USA, 1441–1450. doi:10.1145/3357384.3357895
-
[22]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010
2017
-
[23]
Chunqi Wang, Bingchao Wu, Zheng Chen, Lei Shen, Bing Wang, and Xiaoyi Zeng
-
[24]
Scaling Transformers for Discriminative Recommendation via Generative Pretraining. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2(Toronto ON, Canada)(KDD ’25). Association for Computing Machinery, New York, NY, USA, 2893–2903. doi:10.1145/3711896. 3737117
-
[25]
Xue Xia, Saurabh Joshi, Kousik Rajesh, Kangnan Li, Yangyi Lu, Nikil Pancha, Dhruvil Badani, Jiajing Xu, and Pong Eksombatchai. 2025. TransAct V2: Lifelong User Action Sequence Modeling on Pinterest Recommendation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management (Seoul, Republic of Korea)(CIKM ’25). Associatio...
-
[26]
Sheng, Jiajie Xu, Deqing Wang, Guanfeng Liu, and Xiaofang Zhou
Tingting Zhang, Pengpeng Zhao, Yanchi Liu, Victor S. Sheng, Jiajie Xu, Deqing Wang, Guanfeng Liu, and Xiaofang Zhou. 2019. Feature-level deeper self-attention network for sequential recommendation. InProceedings of the 28th International Joint Conference on Artificial Intelligence(Macao, China)(IJCAI’19). AAAI Press, 4320–4326
2019
-
[27]
Kevin Zielnicki and Ko-Jen Hsiao. 2025. Orthogonal Low Rank Embedding Stabilization. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 1030–1033. doi:10.1145/3705328.3748141
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.